

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Crear un modelo para resolver un caso de uso empresarial nos parece una gran idea a todos. Parece intuitivo pensar que si podemos aumentar la participación en un 5% mediante la personalización en un sitio web determinado mediante el aprendizaje automático, los ingresos aumentarán un porcentaje.
Sin embargo, lo que a menudo se pasa por alto son dos factores que pueden poner en peligro este proyecto:
Bueno, ¿no debería ser sencillo probar las dos cosas? Bueno, analicemos en profundidad lo que se necesita para pasar de la idea de construir un modelo a ponerlo finalmente en producción y evaluar el impacto empresarial. Consideremos el caso en el que una aplicación de entrega de alimentos quiere mostrar la hora prevista de entrega una vez que un cliente hace un pedido en la aplicación. Como no conocemos el tiempo de entrega de antemano, tendremos que crear un modelo de aprendizaje automático que pueda hacer la predicción en función de ciertos factores, como la ciudad, el restaurante, la hora del día, la distancia del cliente al restaurante, etc.
Mostrar el tiempo de entrega estimado al usuario para una aplicación de entrega de alimentos
El flujo de trabajo para sacar este modelo implicará a los siguientes equipos:
El gerente de producto elaborará el proyecto para estimar el tiempo de entrega. La expectativa es que si el tiempo de entrega es decentemente preciso, brinde una mejor experiencia a los usuarios. Habrá menos consultas por parte de los clientes en relación con los tiempos de entrega y la puntuación general de satisfacción del cliente debería aumentar. Luego, el equipo empresarial pedirá al equipo de ciencia de datos que elabore este modelo.
Los científicos de datos comienzan a recopilar los datos históricos de todos los pedidos realizados y sus tiempos de entrega.
El científico de datos será entonces analizar los datos para ver si todo parece correcto - sin valores nulos o falsos y si todos los datos requeridos están ahí. Muchas veces, el DS detecta algunos errores en el conjunto de datos, o tal vez hay algunos días en los que los datos son incorrectos debido a algunos errores transitorios. Tendremos que eliminar los datos falsos, ya que solo así podremos construir un buen modelo. Esto puede llevar a algunas iteraciones con el equipo de ingeniería de datos y productos.
Una vez que los datos se ven bien, en algunos casos, los científicos de datos querrán tener una canalización para calcular las entidades y almacenarlas, de modo que no haya ningún sesgo en la capacitación y sea más fácil obtener los valores de las características durante la inferencia.
Sin embargo, este es un paso opcional y se omite cuando los datos o la cantidad de modelos creados en el mismo conjunto de datos son pequeños. En caso de que un equipo decida dedicarse a la ingeniería de funciones, necesitaremos un sistema de organización de canalizaciones, como Airflow, Prefect, y una base de datos o caché para almacenar las funciones y recuperarlas (por ejemplo, Feast). La creación de una tienda de funcionalidades es en sí misma una tarea enorme y requiere un esfuerzo considerable.
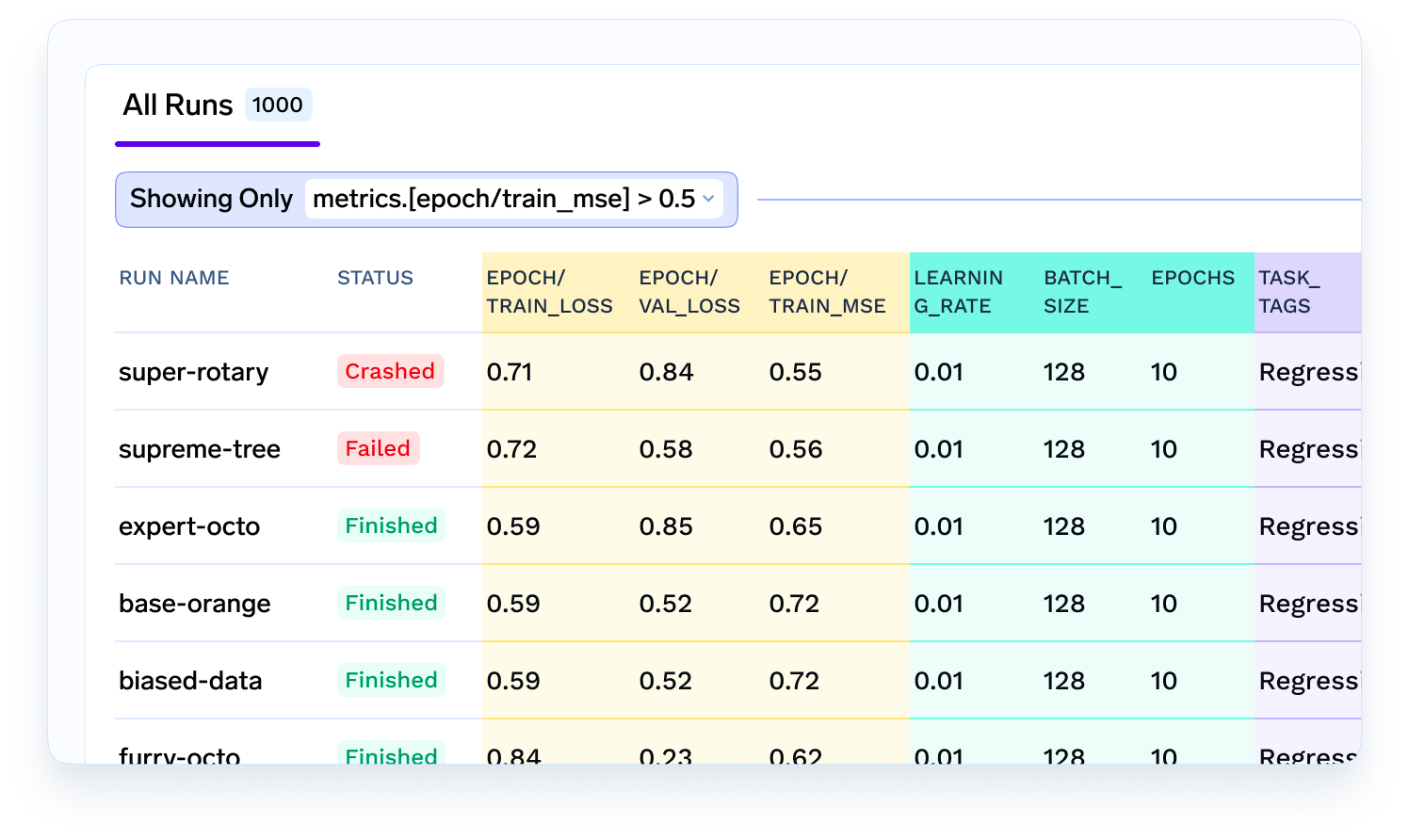
Una vez que los datos estén listos, el científico de datos experimentará con diferentes algoritmos, funciones y modelos para descubrir cuál funciona mejor. Querrán registrar todas las métricas, parámetros y modelos para poder consultarlos más adelante o compartirlos con otros miembros del equipo. Aquí es donde entran en juego el seguimiento de experimentos y un almacén de metadatos modelo..
Una vez creado el modelo, el modelo debe hospedarse como un microservicio o como un trabajo de inferencia por lotes. En nuestro caso de predicción del tiempo de entrega, es necesario que se trate de un servicio online en tiempo real, por lo que probablemente tenga sentido implementarlo como un servicio de escalado automático. En este caso, interviene un ingeniero de aprendizaje automático que toma el modelo, lo empaqueta en un servicio de Flask o FastAPI y crea la imagen de Docker. A continuación, el ingeniero de aprendizaje automático, con la ayuda del equipo de Devops, lo implementará como un microservicio en la infraestructura.
Una vez alojada la API modelo, el equipo de producto o de backend tendrá que llamar a la API en su código para utilizar el tiempo de entrega previsto y mostrarlo en la aplicación. Esto requerirá la colaboración entre los equipos de científicos de datos, de productos y de ingeniería de aprendizaje automático. Durante este tiempo, es posible que el director de producto quiera probar las predicciones y sería fantástico que pudiera probar rápidamente el modelo con algunos datos de muestra. Esto puede requerir la creación de una demostración rápida del modelo.
Una vez que el modelo esté implementado y se esté utilizando en el producto, necesitaremos métricas sobre el modelo implementado.
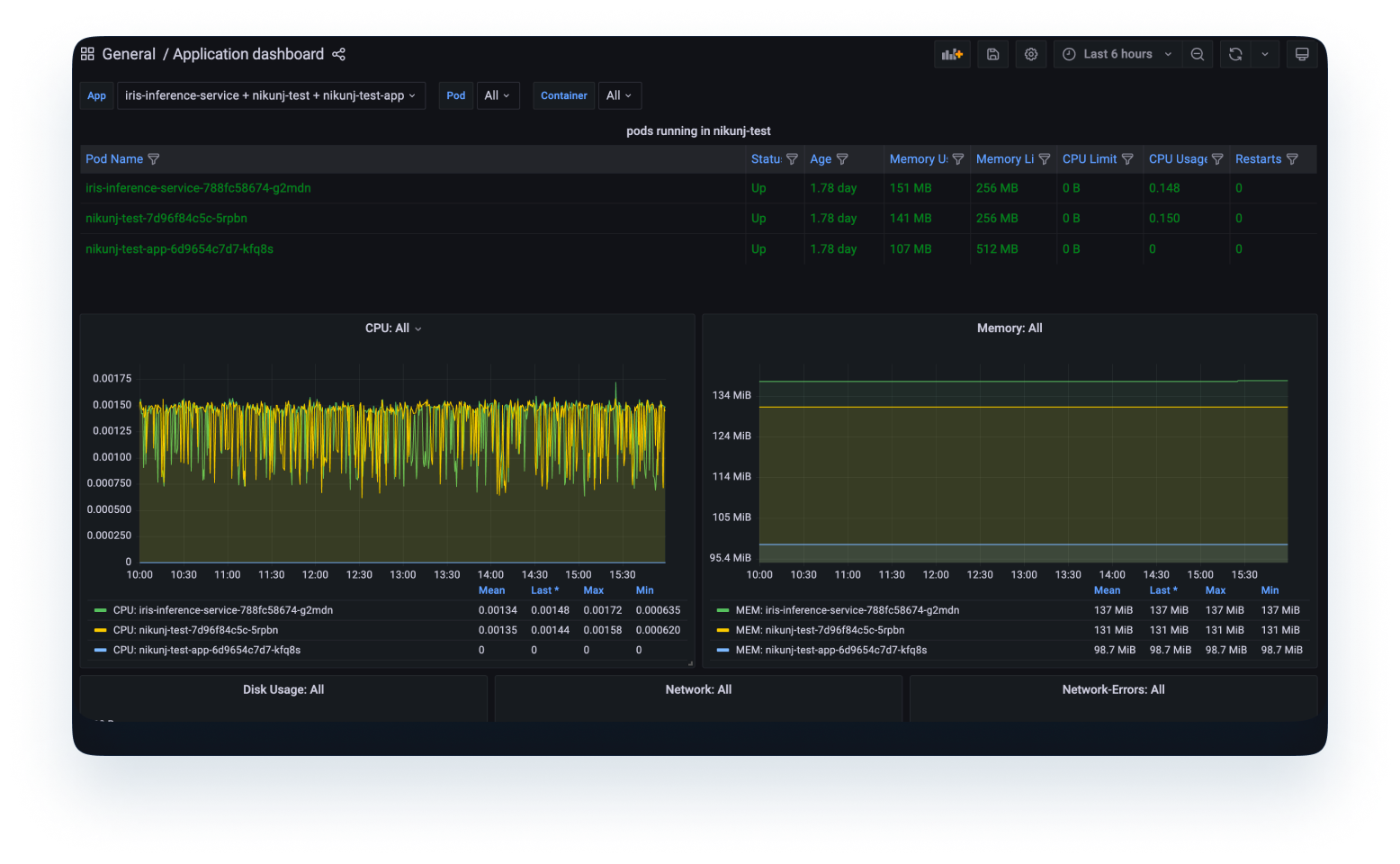
2. Monitoreo de modelos: Esto incluye las métricas relacionadas con la predicción del modelo en los datos de producción entrantes. Se trata de datos que interesarán principalmente al científico de datos e incluyen métricas como la precisión del modelo, la desviación de las características, la desviación de las predicciones, etc. Esto ayuda al científico de datos a decidir si el modelo se comporta de forma similar a como lo hacía durante el entrenamiento, si las distribuciones de los datos de entrada externos no han cambiado y si no hay errores en ninguna otra parte del sistema.

Para lograr un monitoreo completo del modelo, se requerirán esfuerzos significativos por parte de los equipos de ciencia de datos, ingeniería y Devops.
Una vez que se haya ordenado todo el monitoreo, lo ideal es que el científico de datos automatice todo el ciclo de reentrenamiento. Esto requerirá un marco de orquestación de canalizaciones como Kubeflow o Airflow.
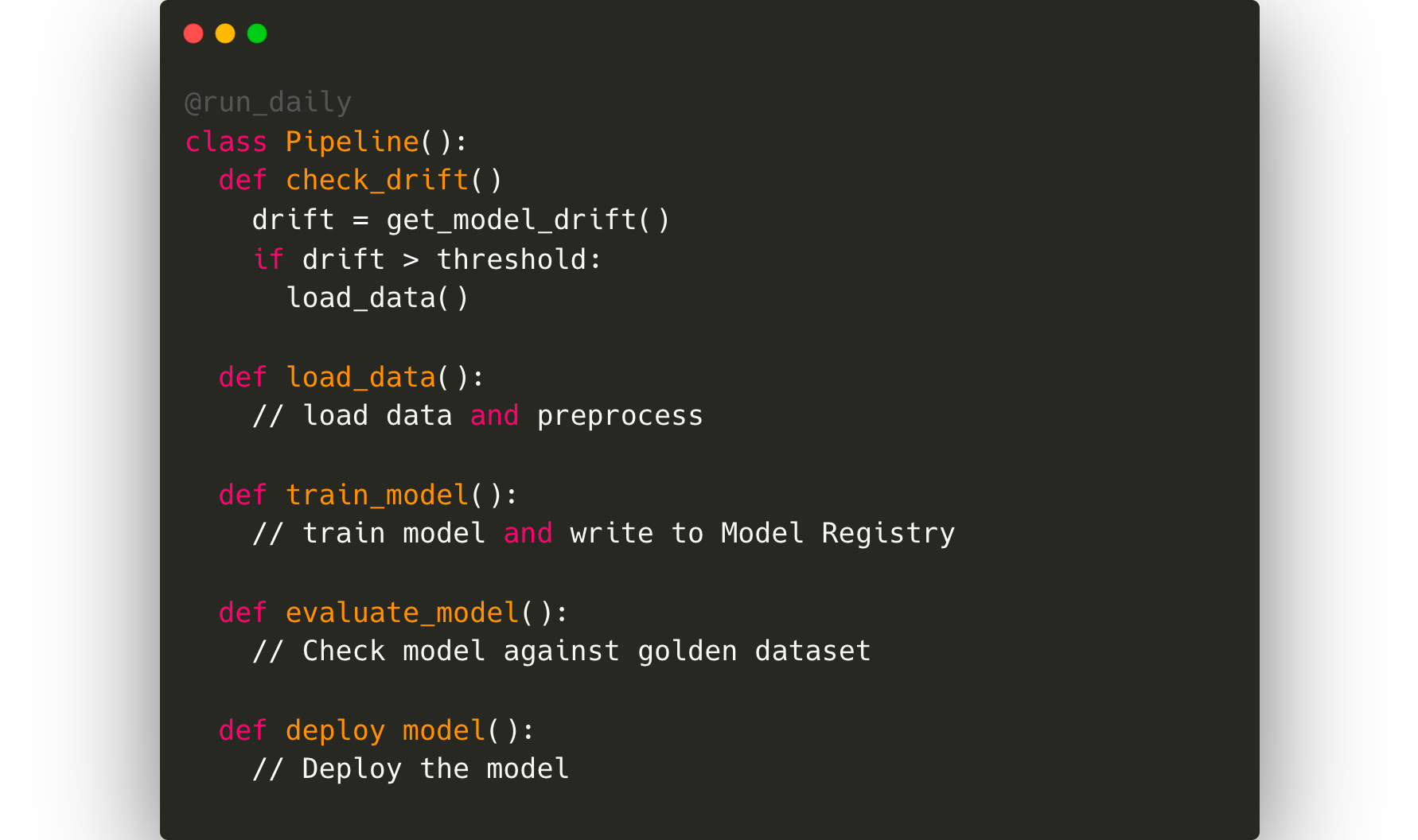
Luego, también debemos estimar el impacto de este modelo en las métricas reales de satisfacción de los usuarios. En este caso, algunas métricas indirectas serán el número de consultas de los clientes relacionadas con los tiempos de entrega y la puntuación general de satisfacción de los clientes con respecto a un pedido. Será necesario combinar las métricas empresariales con las métricas del modelo y es probable que el equipo de ingeniería de datos elabore un proceso de ETL para obtener estos datos y plasmarlos en una herramienta de control interna para que los líderes empresariales puedan observarlos.
En resumen, esto implica a 5 partes interesadas:

Los procesos generales llevan fácilmente más de 2 a 3 meses en cualquier empresa y, a veces, pueden durar hasta 6 meses para los primeros modelos. Gracias a la participación de múltiples partes interesadas y a los múltiples conjuntos de habilidades involucrados, hacer que el aprendizaje automático tenga un impacto requiere tanto tiempo y una inversión inicial inicial.
Aún no hemos hablado de algunos de los aspectos de escalabilidad y confiabilidad involucrados en el proceso. Esperamos tratar algunos de los siguientes aspectos en un artículo futuro.
La solución aquí es automatizar las partes que se pueden automatizar y proporcionar la autonomía al científico de datos/ingeniero de aprendizaje automático para realizar la mayoría de los pasos sin aprender todas las herramientas necesarias. Se está trabajando mucho en este campo y, con suerte, dentro de unos años, crear un modelo de aprendizaje automático impactante sea tan fácil como crear una página de destino hoy en día.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


