

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 23, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Los cuadernos Jupyter son una herramienta potente y popular que proporciona un entorno informático interactivo, que combina código, visualización de datos y texto explicativo, lo que facilita el trabajo con datos y el intercambio de conocimientos. Los científicos de datos utilizan los cuadernos de Jupyter para diversas tareas a lo largo del ciclo de vida del análisis de datos y el aprendizaje automático, como el análisis exploratorio de datos (EDA), el preprocesamiento de datos, la visualización, el desarrollo de modelos, la evaluación y la validación, etc. En muchos de estos casos de uso, instalar Jupyter Notebook en tu portátil es suficiente para empezar. Sin embargo, para muchas empresas y organizaciones, esta no es una opción y necesitamos cuadernos Jupyter alojados.
Estas son las opciones que una empresa puede tener hoy para proporcionar acceso a Jupyter Notebook a sus ingenieros:
Los DS/MLE pueden configurar el entorno y ejecutar un servidor Jupyter en una máquina virtual que se puede usar para ejecutar las cargas de trabajo. Esta es una guía sencilla sobre cómo puede ejecute jupyterlab en una instancia ec2.
👍 Ventajas:
- Proporciona un control total de la máquina en manos de un DS
- Todo el entorno es persistente. La máquina virtual se puede detener y reiniciar en el mismo estado.
👎 Contras:
- Gran costo de computación en la nube: no habrá función de parada automática. DS puede iniciar una máquina virtual y dejarla sin utilizar durante gran parte del tiempo, lo que aumenta los costes.
- Es difícil administrar y rastrear una gran cantidad de máquinas virtuales de forma centralizada.
- DS necesita configurar muchas cosas para configurar la mesa de trabajo necesaria para iniciar la experimentación.
- Dificultad de reproducibilidad: es posible que DS haya instalado un montón de paquetes que ya no se rastrean y lleva mucho tiempo producir el código que se ejecuta en esa máquina virtual.
Otra opción puede ser usar una solución gestionada como AWS Sagemaker, Vertex AI Notebooks o Azure ML Notebooks. Si bien cada uno de estos métodos tiene ventajas, aquí hay algunas ventajas y desventajas de los mismos en general.
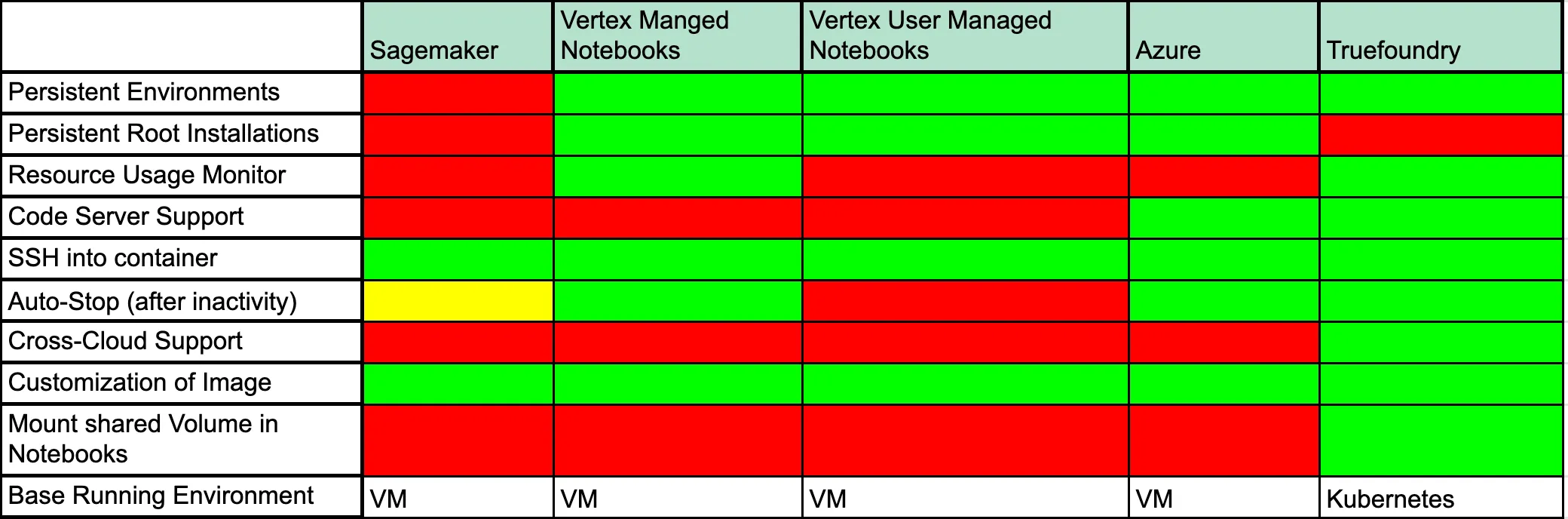
Analicemos lo que significa cada uno de estos campos:
Otra opción puede ser alojar cuadernos en Kubernetes, pero conlleva sus propios desafíos, ya que los científicos de datos no pueden interactuar directamente con Kubernetes y necesitan un software intermedio que proporcione una interfaz sencilla para lanzar los cuadernos Jupyter. Veamos cuáles son las opciones disponibles en este caso:
Operador de portátil Kubeflow:
Kubeflow ayuda a que las implementaciones de flujos de trabajo de aprendizaje automático (ML) en Kubernetes sean simples, portátiles y escalables. Cuenta con un cuaderno función que ayuda a administrar y ejecutar cuadernos fácilmente.
Si bien Kubeflow es un gran proyecto de código abierto que proporciona muchas funciones para los casos de uso del aprendizaje automático, es muy difícil instalar y administrar Kubeflow por ti mismo.
👍 Ventajas:
- Notebooks fáciles de lanzar y gestionar para DS
- Directorio principal persistente respaldado por un disco
- Opción de imágenes predefinidas para sklearn, pytorch y tensorflow que viene con todas las dependencias instaladas.
- Código base de código abierto
- Obtenga una función de selección que detiene los cuadernos después de un tiempo de inactividad.
👎 Contras:
- Es difícil configurar Kubeflow en Kubernetes. La instalación y el mantenimiento de Kubeflow llevan mucho tiempo
- Para proporcionar cuadernos en varias regiones, es necesario crear diferentes clústeres de Kubernetes y Kubeflow debe instalarse en todos los clústeres - lo que lleva a altos costes de infraestructura y mantenimiento.
- Los paquetes de Python no son persistentes por defecto, lo que significa que debe instalar los paquetes cada vez que reinicie
- No hay forma directa de obtener acceso root al contenedor [puede ser útil para múltiples casos de uso]
- La detención de ordenadores portátiles no se puede configurar a nivel de cada portátil y es un escenario global.
Aloja JupyterHub en Kubernetes:
JupyterHub es una excelente configuración para casos de uso multiusuario que ayuda a utilizar los recursos de forma óptima. La implementación de JupyterHub en Kubernetes se puede realizar con un proyecto de código abierto llamado Zero a JupyterHub con Kubernetes:
👍 Ventajas:
- Varios usuarios pueden trabajar juntos fácilmente gracias a la compatibilidad con la autenticación
- Configure fácilmente la parada automática para ordenadores portátiles
- Gestión sencilla de los entornos
👎 Contras:
- Difícil de configurar y gestionar. Debemos configurar las redes, los volúmenes persistentes, el escalado y el equilibrio de carga para que JupyterHub funcione correctamente.
- Es difícil ejecutar cargas de trabajo de GPU en diferentes tipos de GPU en Jupyterhub. Por ejemplo, lee esto.
- Los entornos no son persistentes
Si bien hay muchas soluciones disponibles en este momento, cada solución tiene su propio conjunto de limitaciones. En Truefoundry hemos intentado cerrar esta brecha y hemos intentado crear una solución portátil que satisfaga todas las necesidades de un DS y que, además, mantenga los costos bajo control. En la siguiente sección, describiremos nuestro enfoque para crear la solución portátil y los desafíos a los que nos enfrentamos para crear la misma.
Verdadera fundición es una plataforma de desarrolladores para equipos de aprendizaje automático que ayuda a implementar modelos, servicios, trabajos y, ahora, cuadernos en Kubernetes. Puedes obtener más información sobre lo que hacemos aquí. Nuestra motivación para crear una solución portátil era simplemente permitir la experimentación y el desarrollo en nuestra plataforma. Tras estudiar todas las soluciones disponibles, decidimos resolver los puntos débiles y las funciones que faltaban en las demás plataformas para que los científicos de datos pudieran disfrutar de la mejor experiencia sin incurrir en grandes costes. Algunas de las cosas que queríamos habilitar son:
Kubeflow admite la ejecución de cuadernos en Kubernetes. Proporciona una serie de funciones en las libretas listas para usar. Sin embargo, queríamos abordar los problemas que destacamos anteriormente en los cuadernos de Kubeflow y ofrecer una experiencia perfecta a los científicos y desarrolladores de datos.
Por lo tanto, tuvimos que hacer cambios en el controlador del portátil, integrarlo con el backend de Truefoundry y mostrar los portátiles en nuestra interfaz de usuario.
Instalamos el controlador del portátil, pero tuvimos algunos problemas, por lo que tuvimos que hacer cambios en el controlador kubeflow-notebook-controller:
Resolvimos los dos problemas anteriores y lanzamos el controlador de portátil tfy
y lo publicó como un repositorio de gráficos públicos de Truefoundry. Puedes encontrar el gráfico aquí.
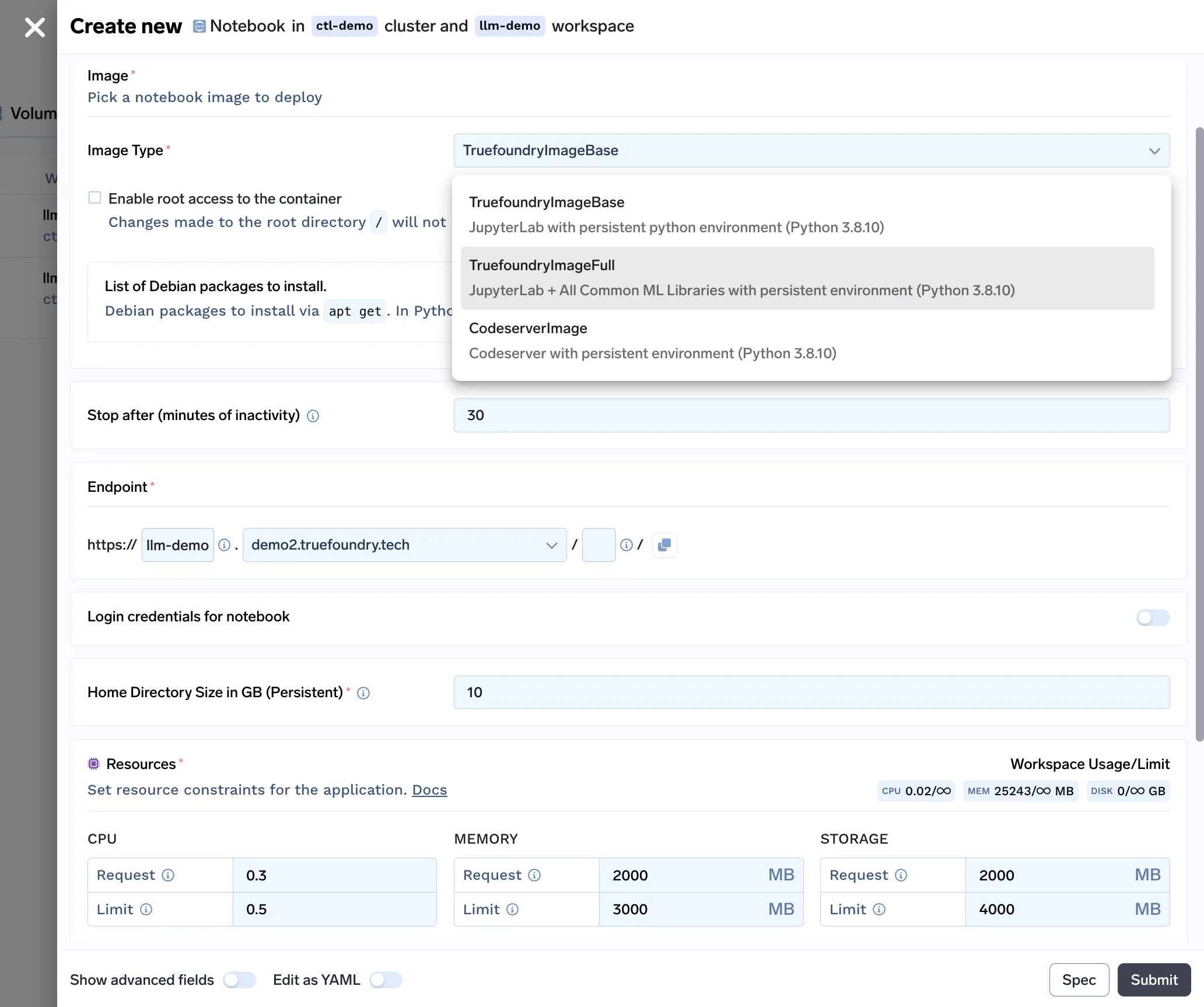
Hemos creado una interfaz de usuario fácil de entender para que los científicos de datos puedan utilizar notebooks. El usuario puede personalizar el tiempo de espera de inactividad (tiempo de inactividad tras el cual el portátil se detiene), el tamaño del volumen persistente (tamaño del disco que almacena el conjunto de datos y los archivos de código), los recursos (requisitos de CPU, memoria y GPU), ¡y poner en marcha el portátil!
Con todos estos cambios, lanzamos el v0 de nuestros cuadernos.
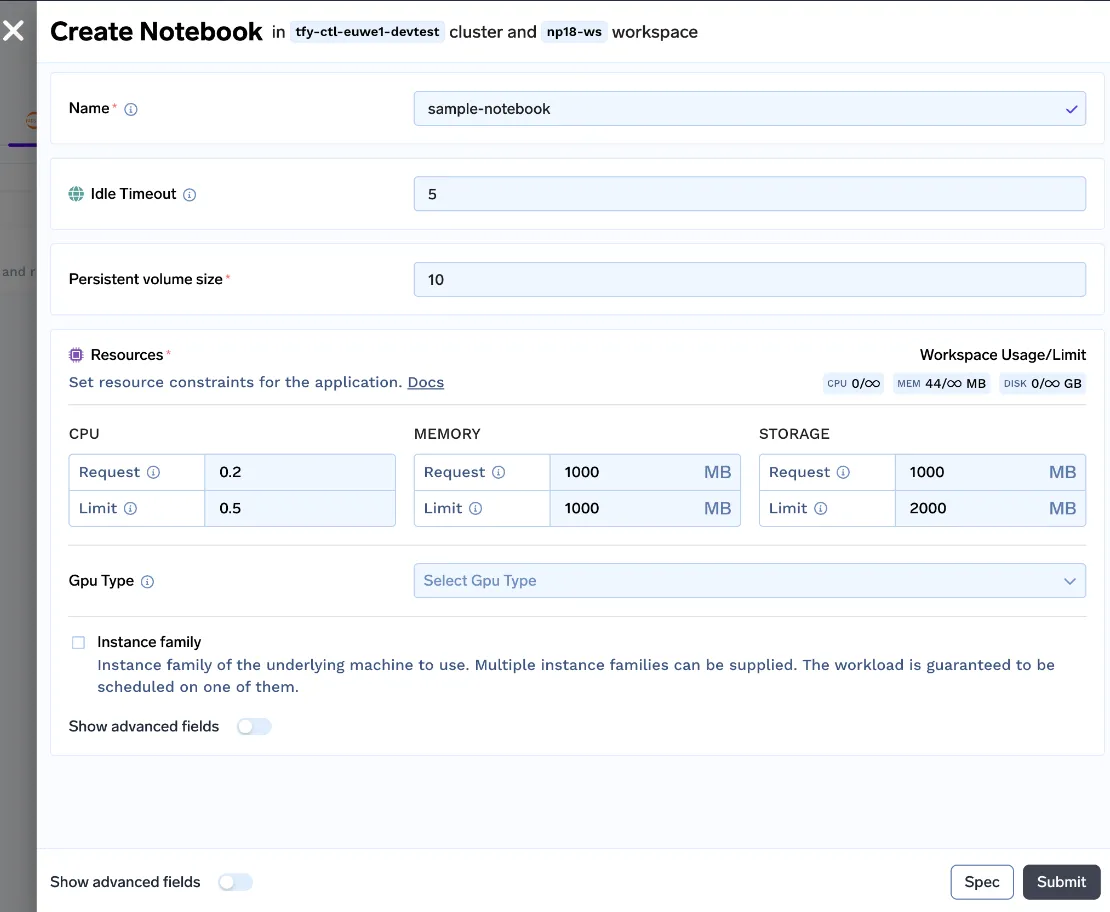
Aun así, estamos muy lejos de una buena experiencia de usuario, veamos los pros y los contras de este enfoque:
👍 Ventajas:
- Directorio principal persistente [se conservarán todos los archivos y paquetes]
- Se puede configurar el tiempo de espera de inactividad (tiempo de espera completo) por portátil
- Inicie el cuaderno con unos pocos clics
- Lanza fácilmente un portátil con GPU
👎 Limitaciones:
- El entorno Python no es persistente (todos los paquetes instalados desaparecen al reiniciar el pod)
- No hay forma de instalar paquetes que requieren acceso root
- No hay una forma adecuada de gestionar varios entornos para la experimentación
- No se puede configurar un punto final para el portátil [agregado en la próxima versión]
Ahora bien, es fundamental resolver estas limitaciones, ya que bloquean muchos flujos de trabajo de los científicos de datos, que pueden ser tan sencillos como instalar «paquetes de aplicaciones» como ffmpeg.
Hasta este punto, utilizábamos el imágenes prediseñadas para Jupyterlab proporcionado por Kubeflow. Pero ya que necesitamos resolver el problema de los entornos no persistentes, permitir el acceso de root e instalar paquetes apt. Necesitamos tener nuestro propio conjunto de imágenes de Docker.
¡Así que veamos cómo hemos resuelto estos problemas!
- Modificó el script de inicio de la imagen de Docker y clonó el entorno conda base en el directorio principal y asígnele un nombre base de Júpiter
- Agregue un archivo.condarc y configúrelo $HOGAR directorio como ruta de entorno predeterminada
- Modifique el archivo.bashrc para activar el base de Júpiter entorno por defecto
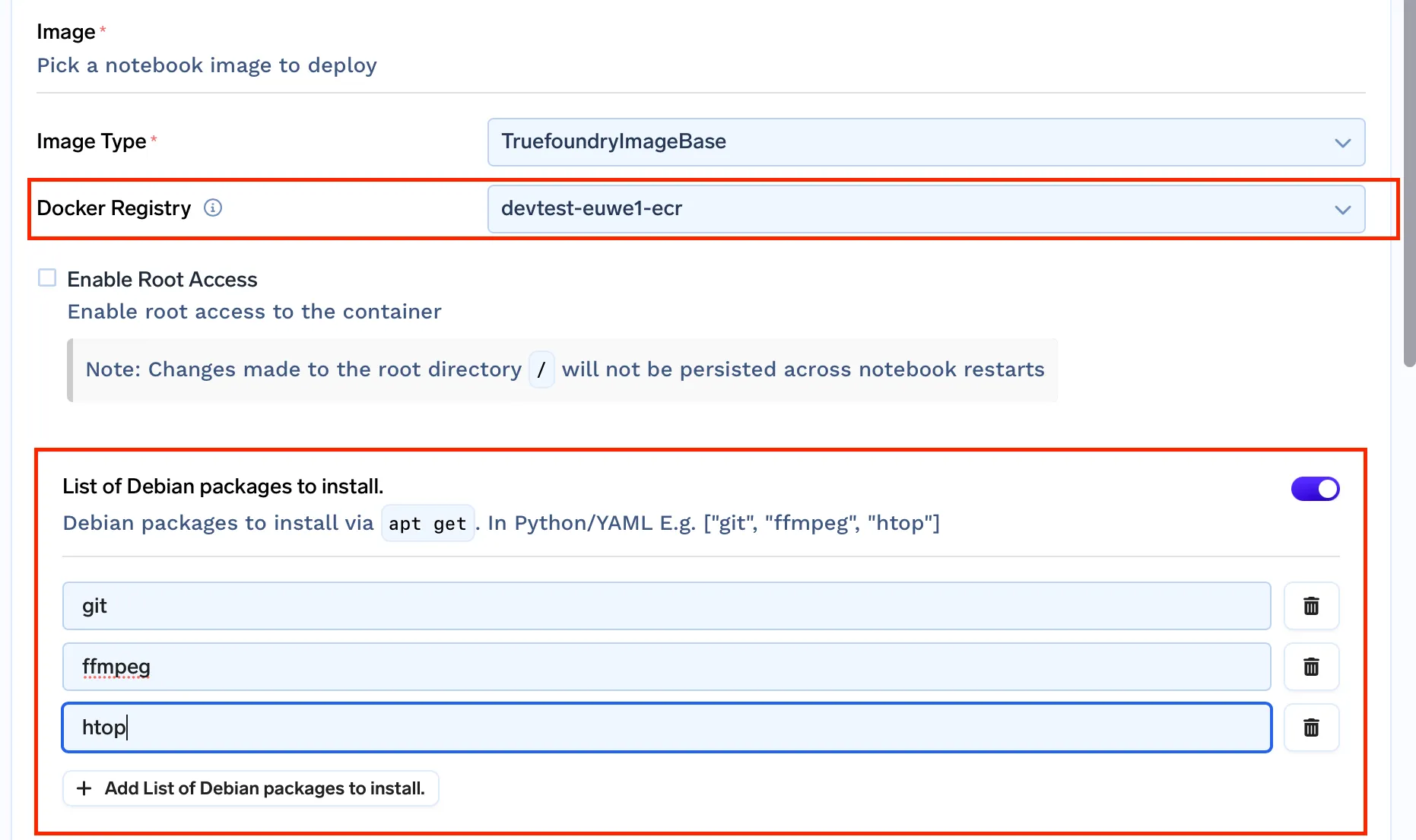
truefoundrycloud/jupyter: más reciente y truefoundrycloud/jupyter: lo último en sudo. Donde las imágenes con sudo proporcionan acceso a sudo sin contraseña al usuario.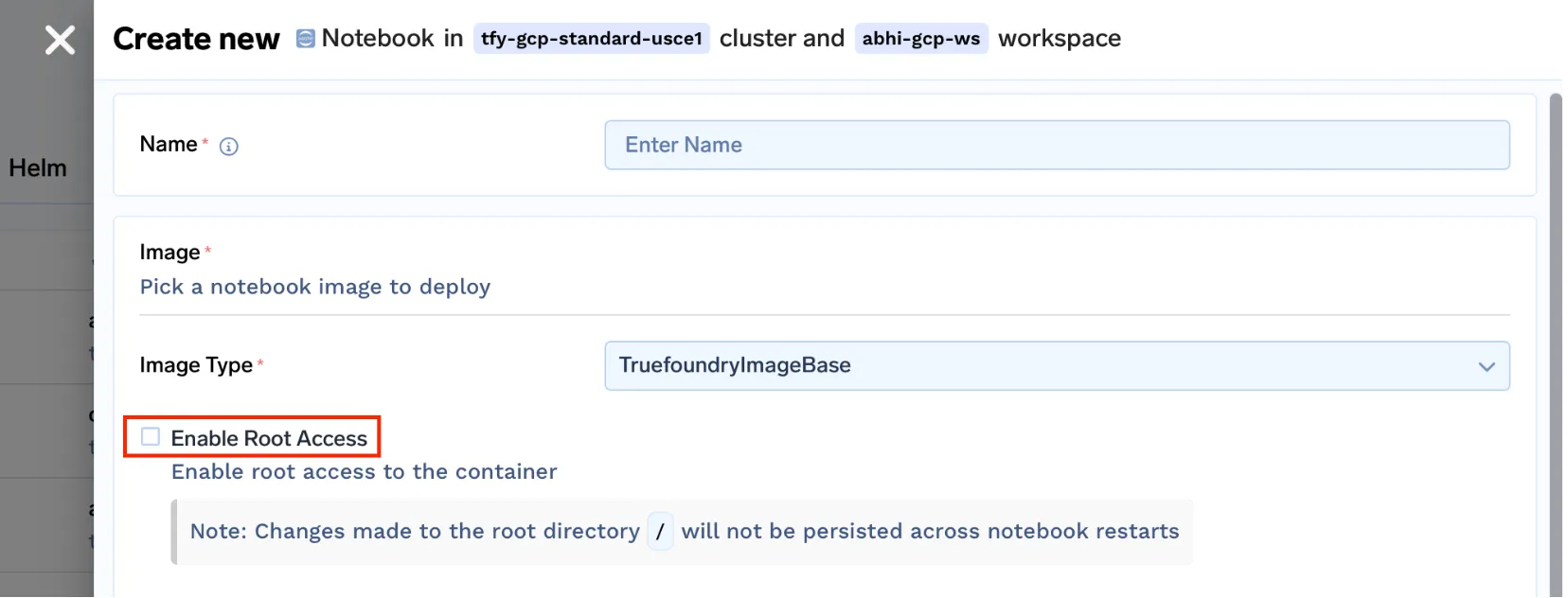
Nota: Dado que estamos ejecutando cuadernos en kubernetes con el directorio principal montado, solo el directorio principal será persistente. Las instalaciones de los paquetes raíz no serán persistentes cuando se reinicie el pod. Por favor, lea esto para obtener una mejor comprensión de la misma.
Al resolver estos problemas, resolvimos la mayoría de los problemas a los que se enfrentaba un usuario y proporcionamos una experiencia decente con los ordenadores portátiles. Pero con el tiempo vimos que los usuarios se enfrentaban a algunos desafíos que describiremos en la siguiente sección.
Júpiter Lab el paquete. Dado que el entorno es persistente, el portátil no se inicia (una vez que se detiene el portátil actual)especificación del núcleo y garantizar que especificación del núcleo está configurado correctamente, lo que puede causar problemas.
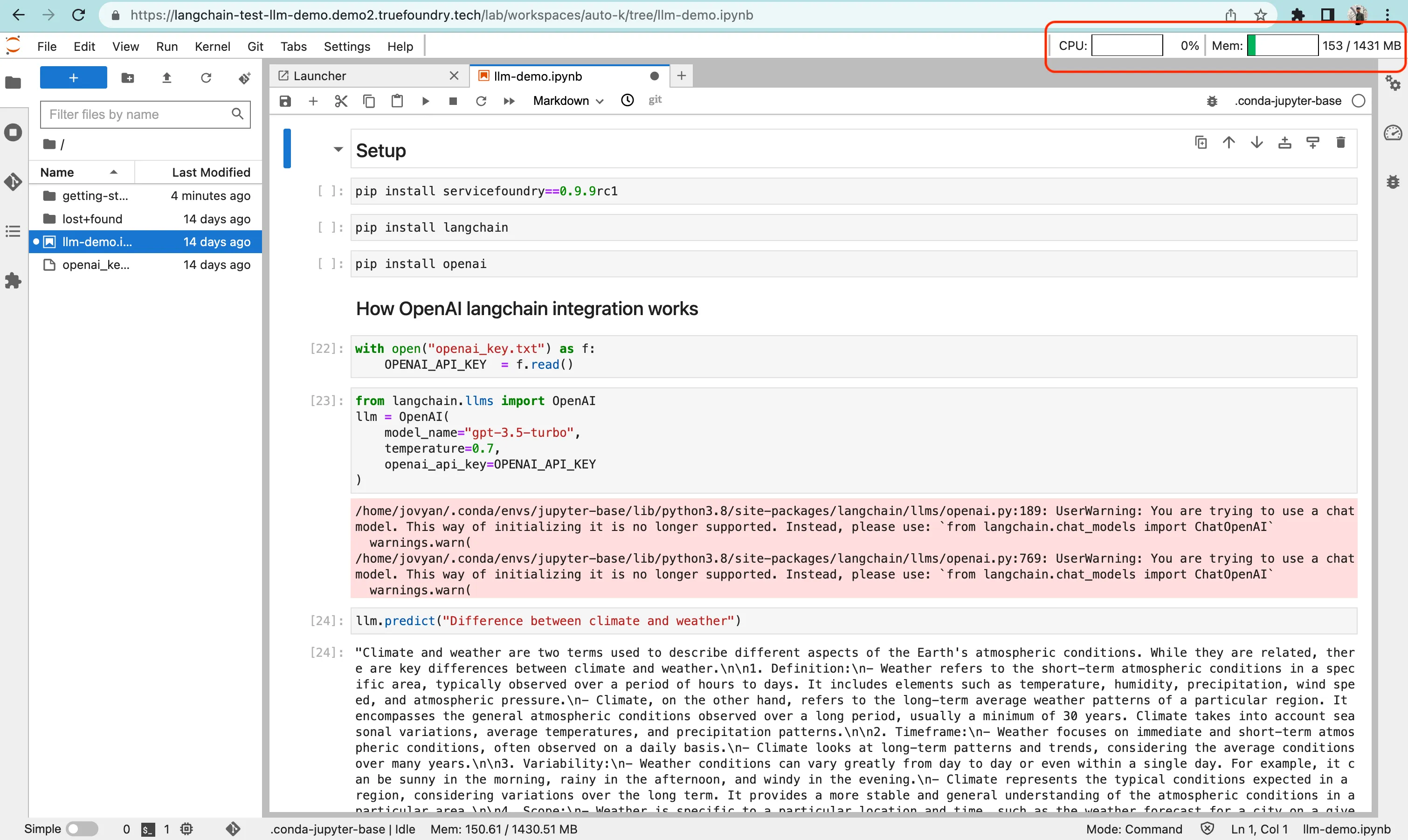
Agregar métricas de uso de recursos al cuaderno:
Hemos agregado las métricas de uso de recursos al portátil mediante la instalación de la extensión monitor de sistema jupyterlab==0.8.0 y configuró sus ajustes en el script de inicio pasando argumentos al iniciar el servidor Jupyterlab.
...
laboratorio de Júpiter\
...
--resourceUseDisplay.mem_limit=$ {mem_limit}\
--resourceUseDisplay.cpu_limit=$ {cpu_limit}\
--ResourceUseDisplay.track_CPU_percent=Verdadero\
--ResourceUseDisplay.MEM_WARNING_THRESHOLD = 0.8
Así es como se ve en la interfaz de usuario:
Separar el núcleo que ejecuta el servidor Jupyterlab del núcleo de ejecución
Debemos asegurarnos de que, independientemente de los cambios que realice el usuario en el directorio de inicio, el portátil siempre se reinicie sin ningún problema. Para ello, utilizamos el entorno anaconda «base» de /opt/conda el directorio para iniciar el servidor Jupyterlab.
Junto con esto, creamos un entorno independiente en el $HOGAR directorio, pero esto añade un núcleo del base del entorno conda a las listas de Kernels.
Para solucionar esto, instalamos nb_conda_kernels para administrar los núcleos de Jupyter. Hemos configurado el script de inicio para asegurarnos de que solo los entornos Python persistentes aparezcan en la lista del kernel.
laboratorio de Júpiter\
...
--condaKernelSpecManager.conda_only=Verdadero\
--condaKernelSpecManager.name_format= {entorno}\
--condaKernelSpecManager.env_filter=/opt/conda/*»
Con esto, tenemos la garantía de que el servidor portátil siempre se iniciará con los cambios que haga un usuario dentro del portátil.
También facilita la administración de varios núcleos. Simplemente necesita crear un nuevo entorno de conda usando el comando conda creó -n myenv y empieza a aparecer en la lista de núcleos.
Mientras que los cuadernos Jupyter resuelven una serie de problemas. Hay una serie de tareas en las que deja de ayudar:
Teniendo en cuenta estas limitaciones, decidimos resolver lo mismo. Añadimos la compatibilidad con servidores de código para ofrecer una experiencia IDE completa a los usuarios del navegador.
Al agregar la compatibilidad con VS Code, permitimos a los usuarios hacer lo siguiente:
host local: 8000 puede estar disponible en $ {NOTEBOOK_URL} /proxy/8000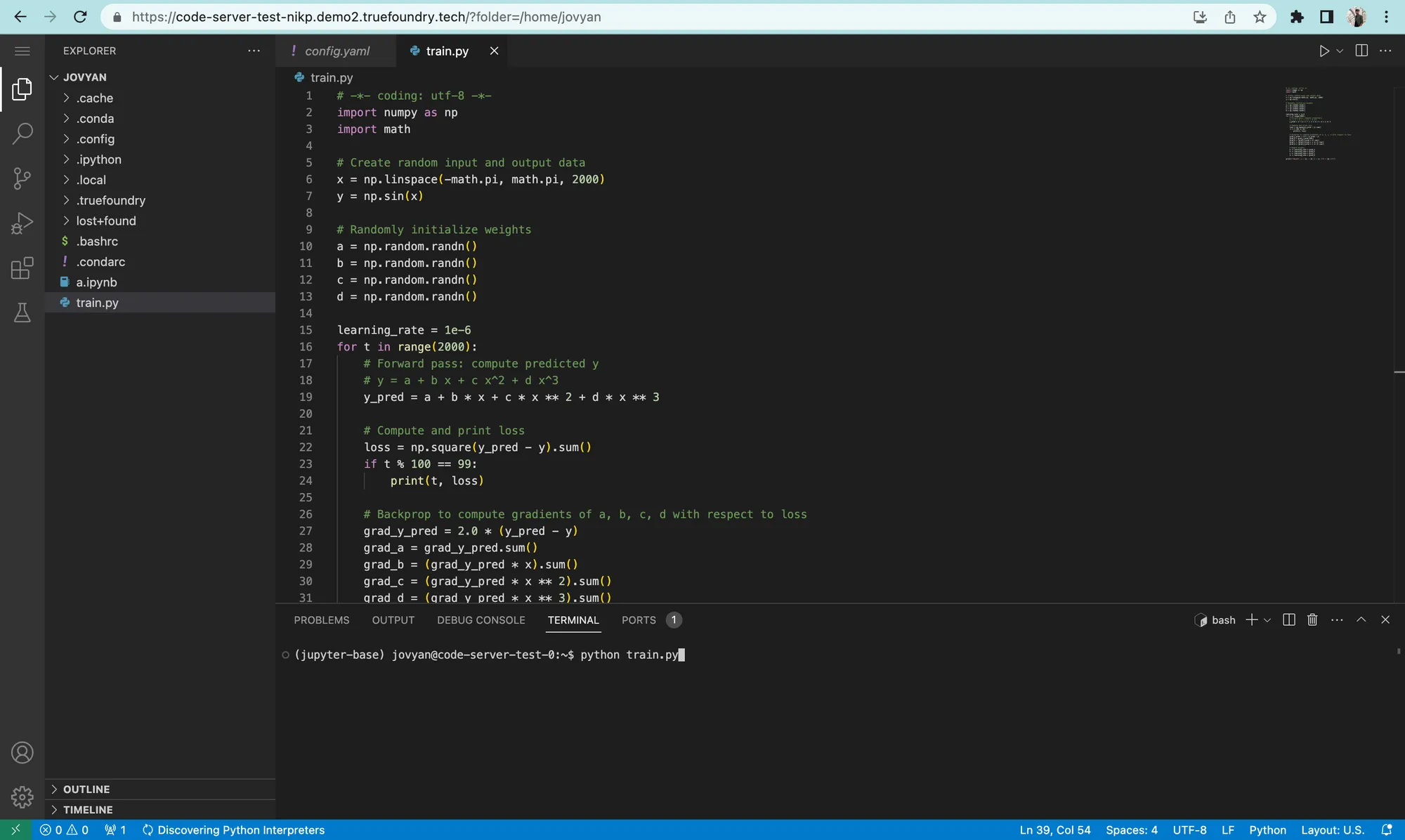
Esto se hizo añadiendo otra imagen de Docker. Este es un diagrama que muestra las imágenes de Docker de Truefoundry.
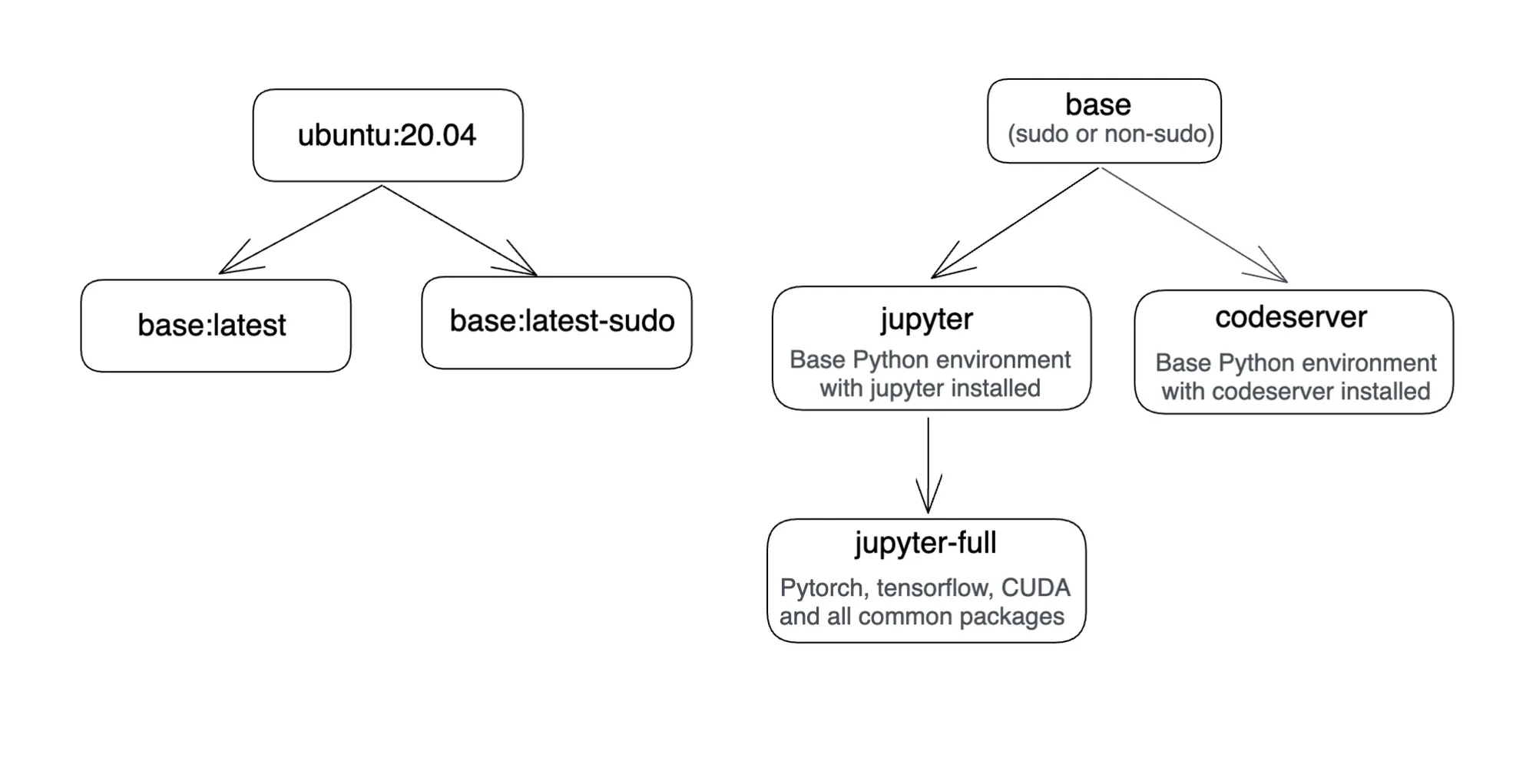
Acceso SSH a su ordenador portátil o VSCode:
Si bien en la mayoría de los casos, Hosted VS Code puede resolver el problema. Pero puede haber casos (especialmente en el caso de Jupyter Notebooks) en los que el usuario se quede atascado y necesite acceder directamente al contenedor en el que se encuentra su Jupyter Notebook/VS Code Server.
Así que lo hemos simplificado instalando un servidor ssh en cada uno de los cuadernos y, para conectarse a su contenedor, debe ejecutar un comando simple e ingresar su contraseña:
ssh -p 2222 jovyan@test-notebook.ctl.truefoundry.tech

La potencia de esta herramienta se puede mejorar con su extensión VS Code llamada Explorador remoto ¡donde puede abrir directamente todos los archivos dentro de su VS Code!
Haga clic aquí para leer más sobre esto
Con todas las funciones incluidas en nuestra solución para portátiles, así es como se presenta nuestro formulario de implementación de portátiles:
Por último, comparemos los precios de cada una de las soluciones gestionadas con los de Truefoundry.
Dado que Truefoundry funciona mediante la implementación en la nube del cliente conectando su clúster de Kubernetes, estos son los precios de Truefoundry que se ejecuta en diferentes proveedores de nube.
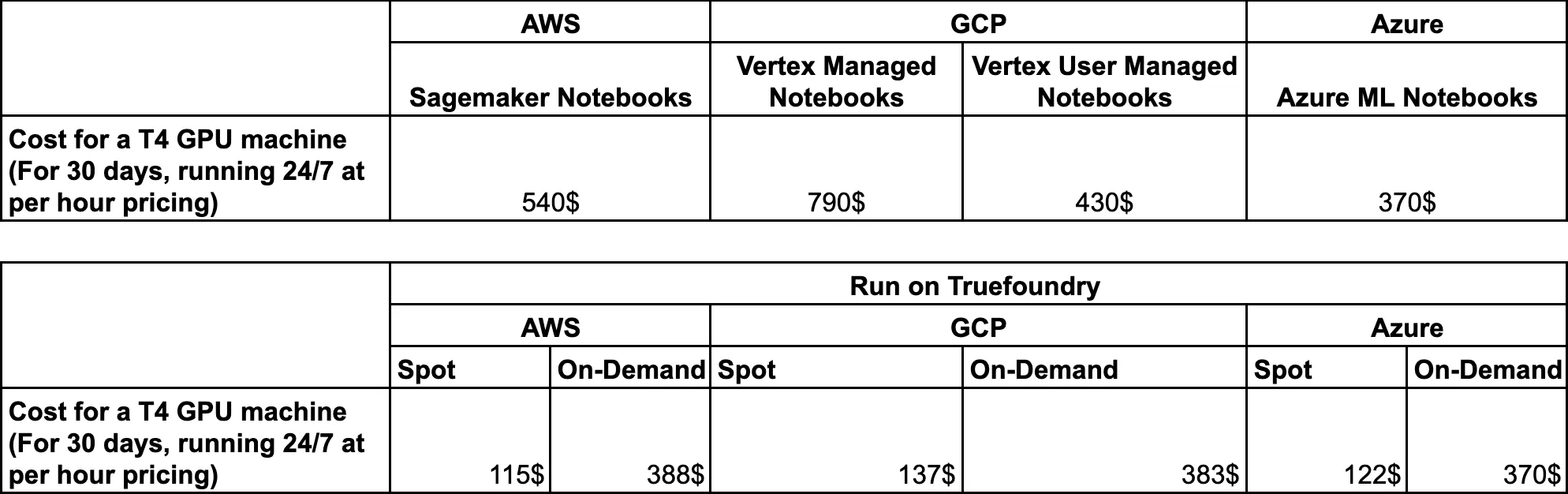
En el caso de Truefoundry, puedes ahorrar muchos costos, ya que:
Este fue un resumen sobre nuestro esfuerzo por crear la solución para ordenadores portátiles. Puedes unirte a nuestro Amigos de Truefoundry Canal de Slack si quieres hablar en profundidad sobre nuestro enfoque o si tienes alguna sugerencia.
Si quieres probar nuestra plataforma puedes registrarte ¡aquí!
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


