Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
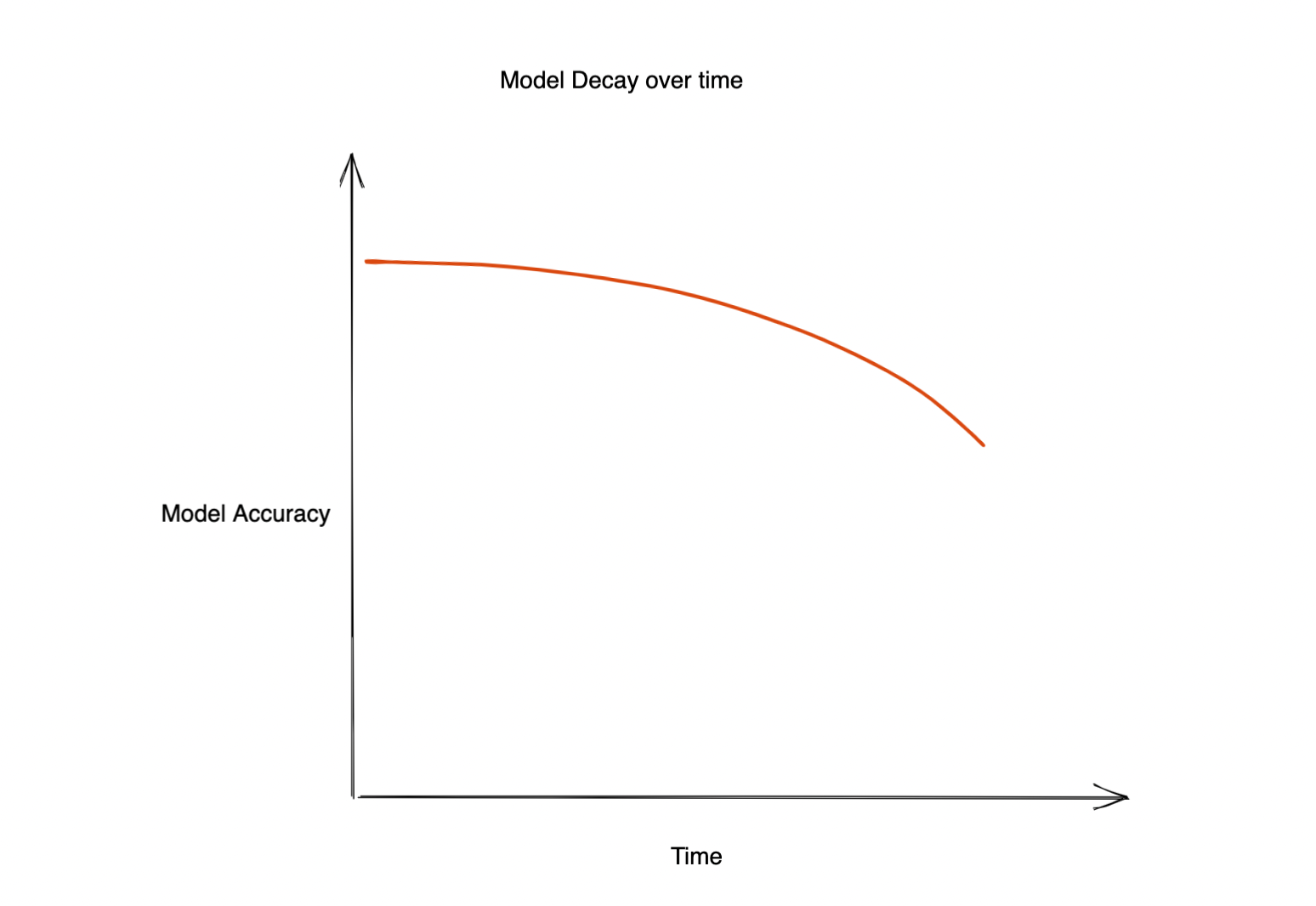
El aprendizaje automático tiene un impacto significativo en casi todos los aspectos del negocio. Sin embargo, con frecuencia, la precisión del modelo implementado comienza a decaer, lo que provoca una mala experiencia para el cliente y repercute negativamente en la empresa. Por lo tanto, la pregunta es: ¿por qué disminuye la precisión de este modelo? Puede deberse a múltiples motivos. Por ejemplo:
Un modelo de detección de spam no puede detectar correctamente los correos electrónicos no deseados después de un tiempo, ya que los «spammers» actualizan las palabras y sus patrones de correo electrónico que son «desconocidos» para el modelo.
Un modelo de recomendación para comprar puede verse afectado significativamente por los principales acontecimientos mundiales, como el brote de la COVID-19, que cambia las preferencias de los clientes.
Un modelo de predicción de abandono se deteriorará con el tiempo a medida que los comportamientos de los clientes y los patrones de gasto cambien lentamente con el tiempo.
El modelo se deteriora con el tiempo
Entonces, ¿cómo nos aseguramos de que el rendimiento de nuestro modelo no disminuya con el tiempo? ¿Cómo saber cuándo debemos volver a entrenar nuestro modelo para evitar que disminuya la precisión?
La respuesta es «deriva». Hay que detectar la «desviación» de manera oportuna y «precisa» y tomar las medidas adecuadas en consecuencia.
¿Qué es Model Drift?
La deriva del modelo se refiere al cambio en la distribución de los datos durante un período de tiempo. En el contexto del aprendizaje automático, por lo general nos referimos a las desviaciones en las características, las predicciones o los datos reales del modelo con respecto a una línea de base determinada.
Se utilizan varios métodos para el seguimiento de la deriva, incluida la estadística de Kolmogorov-Smirnov, la distancia de Wasserstein y la divergencia de Kullback-Leibler. Estas métricas se utilizan con frecuencia en escenarios de aprendizaje en línea, en los que el sistema objetivo evoluciona continuamente y el modelo debe adaptarse en tiempo real para mantener su precisión. Por ejemplo, un modelo de recomendación para películas puede variar con el tiempo a medida que el comportamiento de los clientes cambia con el tiempo, y un modelo de predicción de abandono puede variar con los cambios en las condiciones económicas.
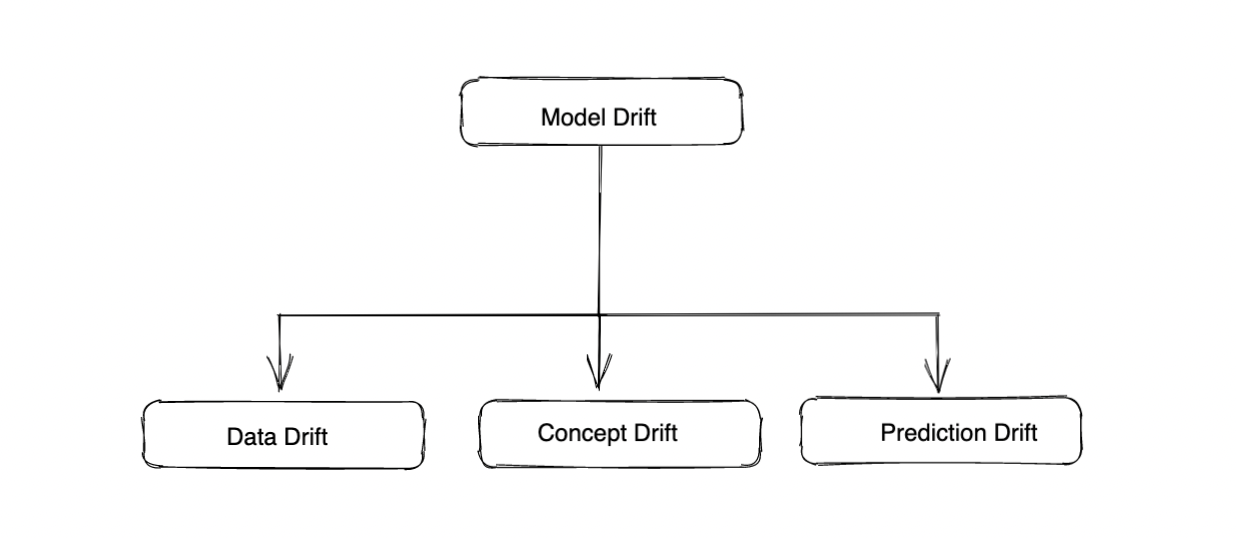
Diferentes tipos de deriva del modelo:
Deriva de datos: Esto se refiere al cambio en las distribuciones de diferentes características o a los cambios en las relaciones entre diferentes características a lo largo del tiempo. Esto puede deberse a cambios en las propias entradas. Por ejemplo, en el caso de un modelo que determine la solvencia crediticia basándose en los datos de un año, el ingreso promedio variaría debido a los cambios económicos o a la recesión.
Concepto Drift: La deriva conceptual se refiere a la deriva en los valores de verdad fundamentales del modelo. Esto indica un cambio en la distribución de los valores reales para los que se utiliza el modelo. La deriva conceptual no depende del modelo, sino únicamente de los valores reales sobre el terreno. La desviación de los valores reales indica que puede haber un cambio en la relación entre las características y los valores reales (en comparación con el conjunto de datos de entrenamiento o los marcos temporales anteriores), lo que pone de manifiesto la necesidad de volver a entrenar el modelo.
Deriva de predicción: La deriva de predicción se refiere a la desviación en la distribución de los valores pronosticados en comparación con los valores pronosticados de los datos de entrenamiento o los datos de un período anterior. La deriva de la predicción suele indicar una desviación de los datos subyacentes, ya que las predicciones son una función del modelo y de las características, y el modelo permanece inalterado. La desviación de la predicción puede ayudarnos a detectar la desviación de los datos y la disminución de la precisión del modelo.
Modelo Drift
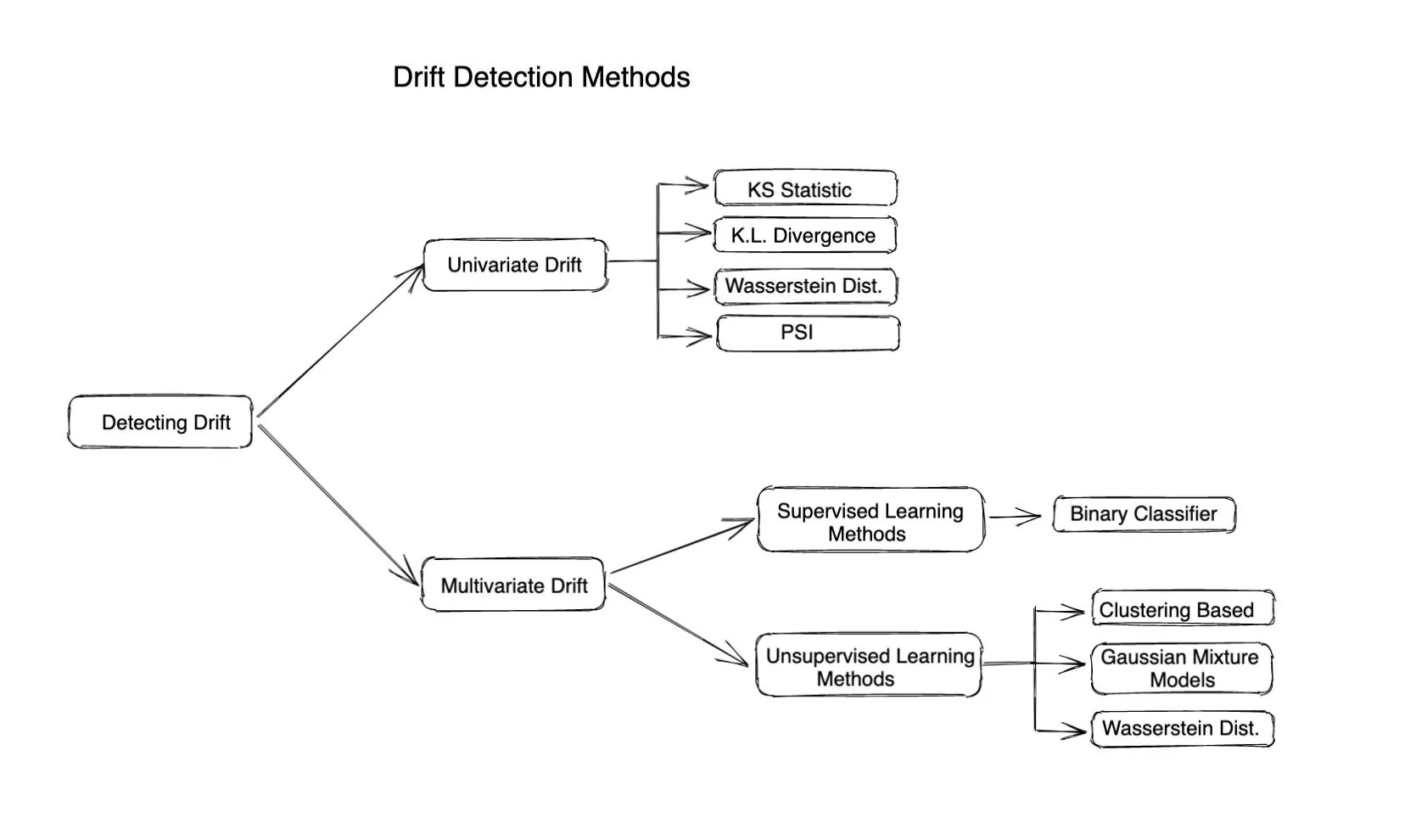
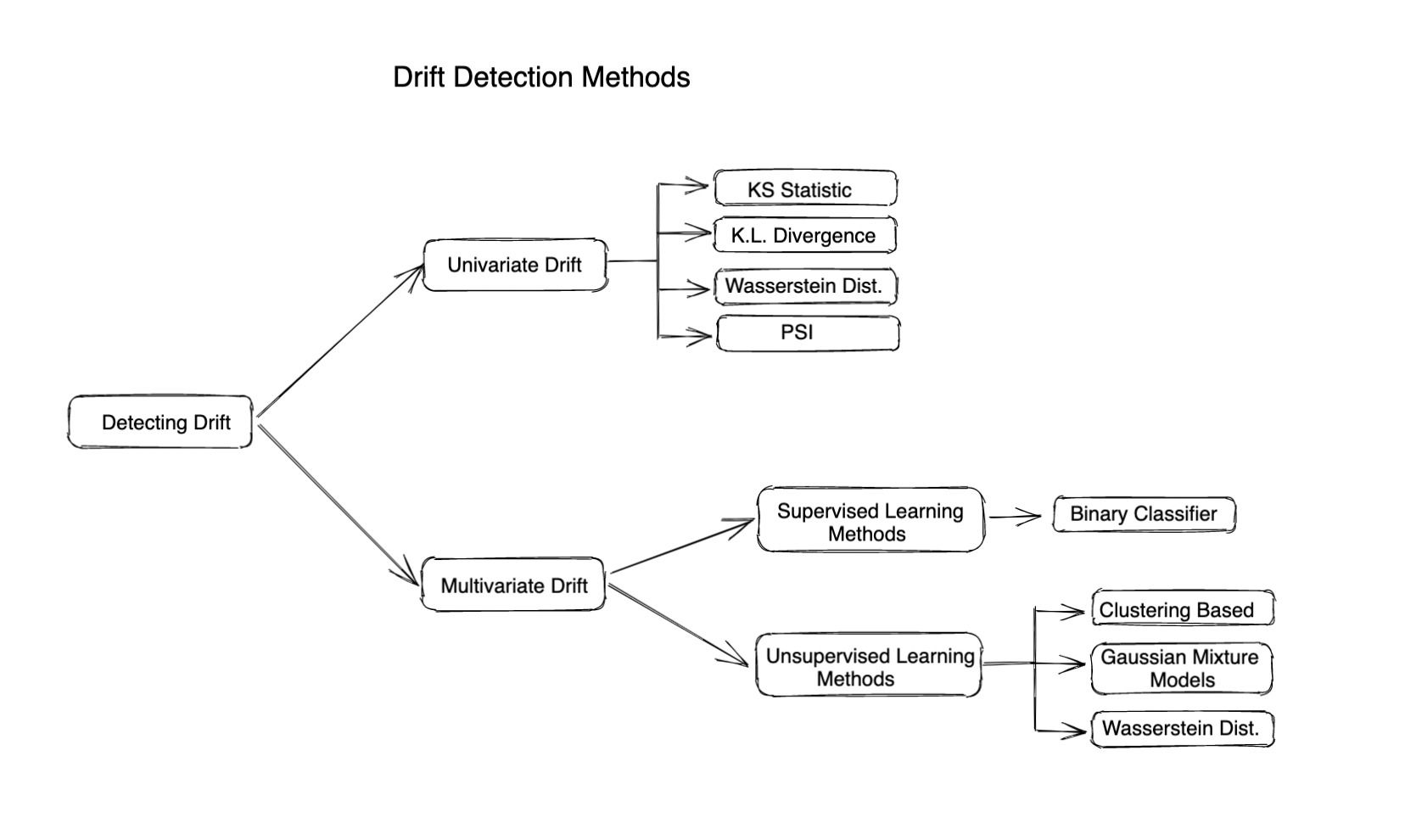
Diferentes métodos de monitoreo de la deriva
Métodos estadísticos
Los métodos estadísticos se utilizan para medir la diferencia entre la distribución dada y la distribución de referencia. Las métricas o divergencias basadas en la distancia se utilizan con frecuencia para calcular la desviación de una característica o un valor real. Los métodos estadísticos pueden ser útiles para detectar valores atípicos o cambios en la distribución de los datos de entrada y son muy sencillos de calcular e interpretar. No tienen en cuenta el cambio en la correlación entre las diferentes entidades, por lo que solo describen la evolución completa cuando las entidades de entrada son independientes.
Estas son algunas métricas famosas basadas en la distancia para calcular la deriva
Estadística de Kolmogorov-Smirnov: Mide la diferencia máxima entre dos funciones de distribución acumulativas. Es una prueba no paramétrica que no asume una distribución específica para los datos. Se usa ampliamente en la detección de desviaciones debido a su capacidad para detectar cambios en la distribución de los datos.
Distancia de Wasserstein: También se conoce como distancia de movimiento de tierras (EMD). Mide la cantidad de «trabajo» necesaria para transformar una distribución en otra. Tiene la capacidad de capturar cambios sutiles en la distribución de los datos que pueden no ser capturados por otras métricas de distancia.
La distancia de Wasserstein ha ganado popularidad recientemente debido a su capacidad para manejar datos ruidosos y de alta dimensión.
Divergencia Kullback-Leibler: Es una medida de la diferencia entre dos distribuciones de probabilidad, también conocida como entropía relativa o divergencia de información. Es una métrica no simétrica, lo que significa que la divergencia KL de la distribución A a la distribución B no es igual a la divergencia KL de la distribución B a la distribución A.
Es una de las métricas más utilizadas para el seguimiento de la deriva, pero la cardinalidad de la característica/predicción que se está rastreando no debe ser muy alta.
PSI (índice de estabilidad de la población): El PSI mide cuánto ha cambiado una población a lo largo del tiempo o entre dos muestras diferentes de una población en un solo número. Para ello, divide las dos distribuciones por grupos y compara los porcentajes de los elementos de cada uno de los grupos, lo que da como resultado un número único que puede usar para comprender qué tan diferentes son las poblaciones. Las interpretaciones más comunes del resultado del PSI son:
PSI < 0,1: sin cambios significativos en la población
PSI < 0.2: cambio demográfico moderado
PSI >= 0.2: cambio significativo en la población
Por lo tanto, se pueden configurar monitores para evaluar el valor de desviación de las características que afectan a la precisión del modelo y tomar las medidas pertinentes en función de ello.
Deriva a nivel de modelo (detección de deriva multivariante)
La detección de desviaciones multivariantes ayuda a detectar cambios o desviaciones en múltiples variables o características juntas. A diferencia de la detección de desviaciones univariadas, que solo se centra en detectar cambios en una sola variable, la detección de desviaciones multivariante considera la relación entre varias entidades y no presupone que todas las entidades sean independientes entre sí.
Por lo tanto, los métodos de detección de desviaciones multivariantes pueden detectar cambios en la distribución de los datos, cambios en la relación entre las variables y cambios en la relación funcional entre las variables. Estos métodos son particularmente útiles en sistemas complejos en los que los cambios en una variable pueden tener un impacto significativo en el comportamiento de otras variables. Por lo tanto, la deriva multivariante ayuda a los usuarios a comprender mejor los cambios en los datos de inferencia. También es más fácil de monitorear, ya que solo es necesario realizar un seguimiento de una métrica en comparación con el seguimiento de cada función por separado. Pero, al mismo tiempo, es complicado calcularlo desde el punto de vista computacional y puede resultar excesivo para los sistemas más simples.
Los algoritmos de detección de deriva multivariante suelen depender de un modelo de aprendizaje automático para calcular la deriva. Por lo tanto, estos algoritmos se pueden clasificar de la siguiente manera:
Uso de métodos supervisados: Por lo general, se basan en el entrenamiento de un modelo de clasificador binario para adivinar si un punto de datos proviene del marco de datos de referencia. Un valor más alto de la precisión del modelo indica una deriva más alta.
Para averiguar qué características se han desviado, se utiliza la importancia de las características de este modelo de clasificación binaria.
Métodos de aprendizaje no supervisados: Estos son algunos métodos: Agrupación: Utilice K-means, DBSCAN o cualquier otro algoritmo de agrupamiento para buscar clústeres en el conjunto de datos de referencia y en el conjunto de datos actual y, a continuación, encontrar las diferencias entre los clústeres para determinar si los datos se han desviado o no.
Modelos de mezclas gaussianas (GMM): GMM representa nuestros datos como una mezcla de distribuciones gaussianas. El GMM se puede usar para detectar la deriva multivariante comparando los parámetros de las distribuciones gaussianas del conjunto de datos actual con el conjunto de datos de referencia.
Análisis de componentes principales (PCA): Utilice el PCA para reducir las dimensiones del conjunto de datos y, a continuación, utilice algoritmos de detección de desviaciones univariados habituales, teniendo en cuenta que las características son únicas.
En resumen, la detección de desviaciones multivariantes es útil en sistemas complejos y es más fácil de monitorear, ya que solo hay un KPI que monitorear.
Detección de la deriva del modelo
Conclusión:
Con el tiempo, el rendimiento de un modelo implementado en producción disminuirá. El tiempo necesario para este deterioro dependerá del caso de uso. En algunos casos, es posible que los modelos no vayan a la deriva hasta dentro de un año, ¡mientras que algunos modelos pueden necesitar un nuevo entrenamiento cada hora! Por lo tanto, comprender la causa de esta degradación y detectarla es extremadamente importante. Aquí es donde la «detección temprana de la deriva» puede ayudar.
En conclusión, los modelos en producción deben tener mecanismos adecuados de seguimiento o monitoreo de deriva y canalizaciones de reentrenamiento configuradas para generar el mejor valor a partir de un modelo de aprendizaje automático.
True Foundry es un PaaS de implementación de aprendizaje automático sobre Kubernetes para acelerar los flujos de trabajo de los desarrolladores y, al mismo tiempo, permitirles una flexibilidad total a la hora de probar e implementar modelos, al tiempo que garantiza una seguridad y un control totales para el equipo de Infra. A través de nuestra plataforma, permitimos a los equipos de aprendizaje automático implementar y supervisar modela en 15 minutos con un 100% de confiabilidad, escalabilidad y la capacidad de revertirse en segundos, lo que les permite ahorrar costos y lanzar los modelos a la producción más rápido, lo que permite obtener un verdadero valor empresarial.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga
































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


