



July 20, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Los modelos lingüísticos extensos (LLM) son cada vez más poderosos y se utilizan para una variedad de tareas, incluidos los chatbots, la generación de texto y la respuesta a preguntas. Sin embargo, la formación de los LLM puede resultar costosa y requerir muchos recursos. En esta entrada del blog, te mostraremos cómo ajustar un LLM más pequeño (7B) para que funcione mejor que ChatGPT.
El ajuste fino es un proceso de entrenamiento de un LLM en un conjunto de datos específico para mejorar su rendimiento en una tarea en particular. En este caso, ajustaremos un LLM de 7B para multiplicar dos números.
Empecemos por el rendimiento de diferentes modelos lingüísticos de gran tamaño en una simple tarea de multiplicación: 458*987 = 452046.
Al principio veremos el modelo Llama-2-7B lanzado recientemente por Meta. Implementamos Lllama-2 en TrueFoundry y lo probamos con las integraciones de Langchain de TrueFoundry. Este es el resultado de lo mismo.
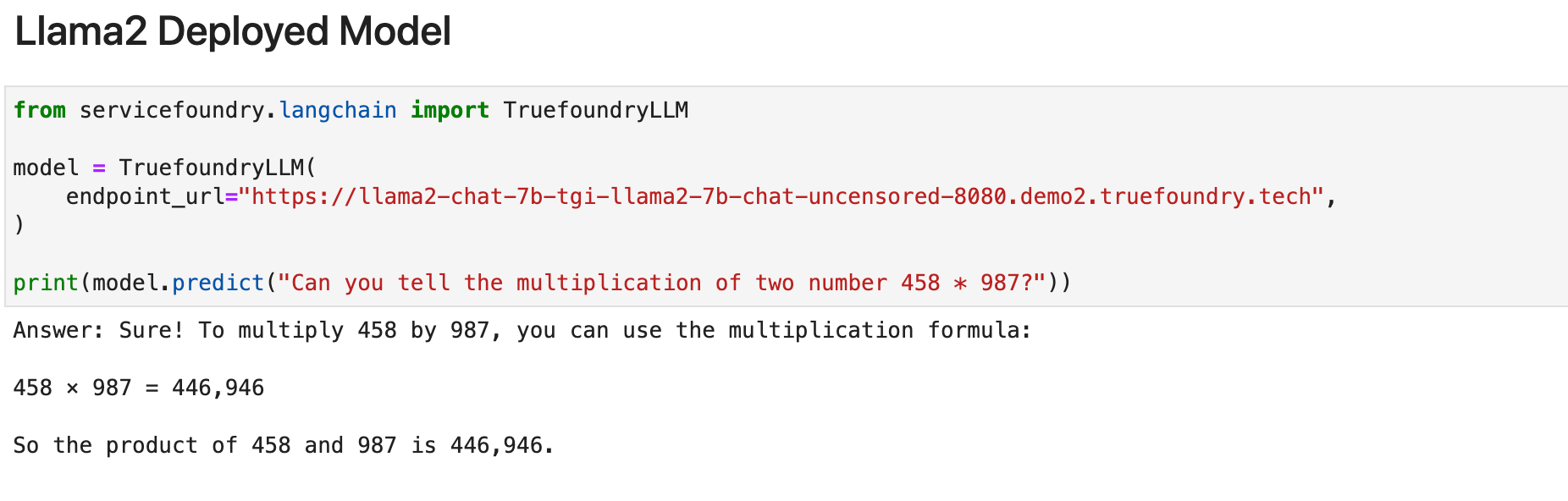
Como podemos ver claramente, esto no funciona bien en la tarea. (lo que también es normal dado el tamaño del modelo). Veamos cómo funcionan los modelos más avanzados en la misma tarea:
Veamos el resultado de ChatGPT (GPT3.5 Turbo):
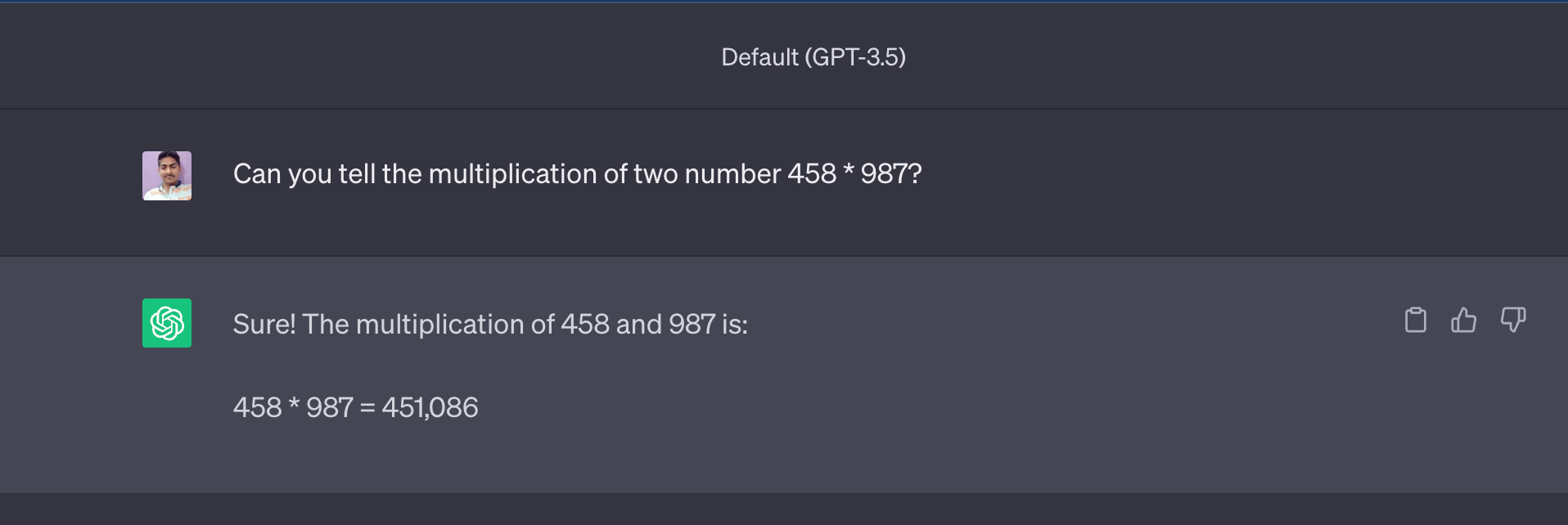
Ahora, la respuesta (451.086) está muy cerca de la respuesta real, que es 452.046, pero la respuesta no es correcta.
Probemos con un indicador diferente (para hacer un cálculo paso a paso y ver qué hace):
0:00 /1×
ChatGPT con mensaje personalizado para la multiplicación
Pero, de nuevo, llega a un resultado incorrecto: 450,606 🤨
Por último, probemos el estado del arte (GPT-4) y comprobemos cómo funciona en la tarea:

Está muy cerca de la respuesta correcta (452,046) y puede parecerle correcta a cualquiera. Pero está claro que la respuesta es incorrecta.
La respuesta a esta pregunta es muy sencilla. No están «entrenados» para ello.
Los LLM se entrenan en conjuntos de datos masivos de texto y código, pero estos datos no siempre están estructurados de una manera que sea útil para el razonamiento matemático. Por ejemplo, es posible que los datos no incluyan representaciones explícitas de conceptos matemáticos, como la suma, la resta, la multiplicación y la división. Esto puede dificultar que los LLM aprendan a realizar estas operaciones correctamente.
Entonces, ¿pensamos si es posible entrenar a un LLM para realizar operaciones matemáticas? ¡Hicimos un experimento y los resultados fueron bastante prometedores!
Para empezar, seleccionamos un conjunto de datos de 40 000 filas de indicaciones e instrucciones. Intentamos imitar los pasos exactos que se siguen en el método de multiplicación larga, que consiste en dividir el multiplicando y el multiplicador en sus dígitos individuales, luego multiplicar cada dígito del multiplicando por cada dígito del multiplicador y colocar los resultados en las posiciones apropiadas según sus valores posicionales. Por último, se suman todos los productos individuales para obtener el resultado final.
Este es un ejemplo de mensaje:
Eres un asistente útil que proporciona respuestas detalladas a las preguntas de multiplicación. Asegúrese de proporcionar una explicación completa utilizando el método de multiplicación larga para el problema matemático que se indica a continuación.
Si no sabes la respuesta a una pregunta, no compartas información falsa. ¿Qué es 5244 * 1932?
Y aquí hay un ejemplo de respuesta:
Estos son los pasos para multiplicar 5244 * 1932 usando el método de multiplicación larga.
Paso 1: Divida 5244 en sus dígitos individuales: 5 (lugar de miles), 2 (lugar de centenas), 4 (lugar de decenas) y 4 (lugar de unidades).
Paso 2: Del mismo modo, divide 1932 en sus dígitos individuales: 1 (lugar de miles), 9 (lugar de centenas), 3 (lugar de decenas) y 2 (lugar de unidades).
- 4 (desde 1 lugar del primer número) * 2 (desde 1 lugar del segundo número) = 8 -> Muévelo 0 lugares a la izquierda (porque estamos multiplicando por el lugar 1 del segundo número) para obtener 8
- 4 (desde 1 lugar del primer número) * 3 (desde 10 lugar del segundo número) = 12 -> Muévelo 1 lugar a la izquierda (porque estamos multiplicando por el lugar 10 del segundo número) para obtener 120
- 4 (desde 1 lugar del primer número) * 9 (desde 100 lugar del segundo número) = 36 -> Muévelo 2 lugares hacia la izquierda (porque estamos multiplicando por el lugar 100 del segundo número) para obtener 3600
- 4 (desde 1 lugar del primer número) * 1 (desde 1000 lugar del segundo número) = 4 -> Muévelo 3 lugares hacia la izquierda (porque estamos multiplicando por 1000 lugar del segundo número) para obtener 4000
- 4 (desde la posición 10 del primer número) * 2 (desde la posición 1 del segundo número) = 8 -> Muévelo 1 lugar a la izquierda (porque estamos multiplicando por la posición 1 del segundo número) para obtener 80
- 4 (desde el lugar 10 del primer número) * 3 (desde el lugar 10 del segundo número) = 12 -> Muévelo 2 lugares hacia la izquierda (porque estamos multiplicando por el lugar 10 del segundo número) para obtener 1200
- 4 (desde el lugar 10 del primer número) * 9 (desde el lugar 100 del segundo número) = 36 -> Muévelo 3 lugares a la izquierda (porque estamos multiplicando por el lugar 100 del segundo número) para obtener 36000
- 4 (desde el lugar 10 del primer número) * 1 (desde 1000 el lugar del segundo número) = 4 -> Muévelo 4 lugares hacia la izquierda (porque estamos multiplicando por el lugar 1000 del segundo número) para obtener 40000
- 2 (desde la posición 100 del primer número) * 2 (desde la posición 1 del segundo número) = 4 -> Muévelo 2 lugares a la izquierda (porque estamos multiplicando por el lugar 1 del segundo número) para obtener 400
- 2 (desde el lugar 100 del primer número) * 3 (desde el lugar 10 del segundo número) = 6 -> Muévelo 3 lugares a la izquierda (porque estamos multiplicando por el lugar 10 del segundo número) para obtener 6000
- 2 (del lugar 100 del primer número) * 9 (del lugar 100 del segundo número) = 18 -> Muévelo 4 lugares a la izquierda (porque estamos multiplicando por el lugar 100 del segundo número) para obtener 180000
- 2 (del lugar 100 del primer número) * 1 (del lugar 1000 del segundo número) = 2 -> Muévelo 5 lugares a la izquierda (porque estamos multiplicando por el lugar 1000 del segundo número) para obtener 200000
- 5 (del lugar 1000 del primer número) * 2 (del lugar 1 del segundo número) = 10 -> Muévelo 3 lugares a la izquierda (porque estamos multiplicando por el lugar 1 del segundo número) para obtener 10000
- 5 (del lugar 1000 del primer número) * 3 (del lugar 10 del segundo número) = 15 -> Muévelo 4 lugares a la izquierda (porque estamos multiplicando por el lugar 10 del segundo número) para obtener 150000
- 5 (desde 1000 lugar del primer número) * 9 (desde 100 lugar del segundo número) = 45 -> Muévelo 5 lugares hacia la izquierda (porque estamos multiplicando por el lugar 100 del segundo número) para obtener 4500000
- 5 (desde 1000 lugar del primer número) * 1 (desde 1000 lugar del segundo número) = 5 -> Muévelo 6 lugares hacia la izquierda (porque estamos multiplicando por 1000 lugar del segundo número) para obtener 5000000
Ahora, suma todos estos resultados:
La suma de 8 + 120 + 3600 + 4000 + 80 + 1200 + 36000 + 40000 + 400 + 6000 + 180000 + 200000 + 10000 + 150000 + 4500000 + 5000000 = 10131408.
Luego escribimos un script de Python que genera pares de pregunta-respuesta seleccionando aleatoriamente dos dígitos para la multiplicación. Hemos seleccionado un conjunto de datos con 40 000 filas.
Ahora, una vez que el conjunto de datos esté listo, necesitamos ajustar el modelo.
Estamos utilizando la variante de chat perfeccionada de Meta (7 mil millones de parámetros) de Llama 2 como modelo base.
Realizamos el ajuste fino usando Ajuste fino de QLoRa usando BitsAndBytes y la biblioteca Peft. Esta es la configuración de lora que utilizamos:
Configuración de Lora (
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="ninguno»,
TASK_TYPE="CAUSAL_LM»,
modules_objetivo = [
«q_proj»,
«k_proj»,
«v_proj»,
«o_proj»,
],
)
Se necesitaron alrededor de 8 horas para entrenar en una máquina GPU A100 de 40 GB para un conjunto de datos de 40 000 filas.
Finalmente, implementamos el modelo perfeccionado en True Foundry nuevamente y aquí están los resultados:
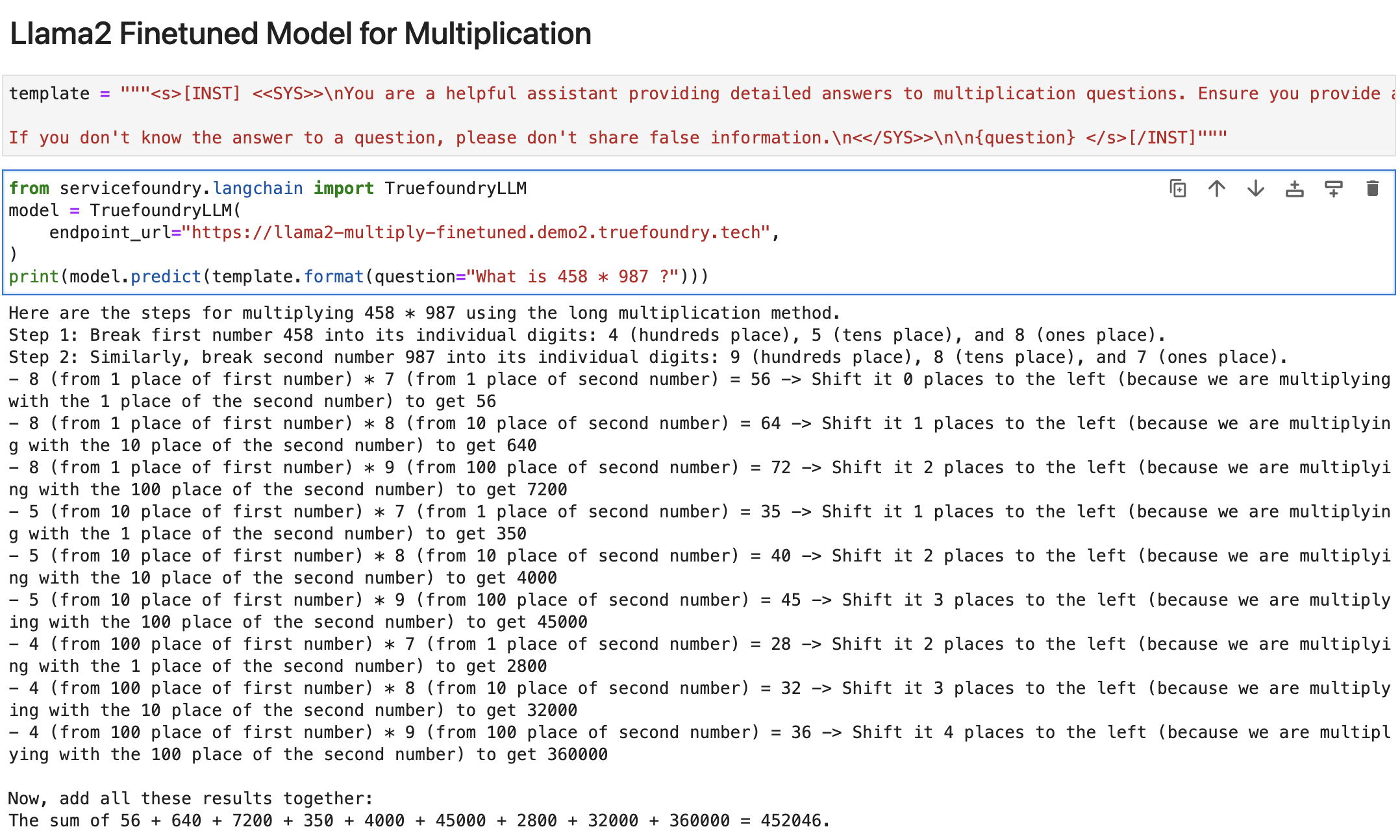
¡¡Así que finalmente!! Podemos ver que el modelo afinado es capaz de calcular el resultado correctamente.
Aunque la aritmética no es una tarea para la que usemos el LLM, este ejemplo demuestra cómo un LLM «pequeño» (7B de parámetros) ajustado correctamente para una tarea específica puede superar a los LLM «grandes» (como los parámetros GPT3.5 turbo, 175B y GPT-4) en una tarea específica.
Los modelos más pequeños, los modelos más ajustados, son baratos en inferencias, mejores en las tareas especializadas y se pueden implementar fácilmente en la nube.
Escribimos un blog detallado sobre cómo ajustar Llama 2
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


