

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En el mundo del aprendizaje automático (ML), la creación eficiente de imágenes de Docker no es solo un lujo, es una necesidad. La mayoría de las empresas ya tienen una cartera de Devops para crear y publicar imágenes de Docker en ordenadores portátiles locales o mediante canales de CI/CD. Sin embargo, a medida que los proyectos de aprendizaje automático aumentan en complejidad, con mayores dependencias e iteraciones más frecuentes, el proceso tradicional de creación de Docker puede convertirse en un importante obstáculo.
.webp)
Este artículo destaca cómo redujimos el tiempo de construcción en Truefoundry entre 5 y 15 veces en comparación con las canalizaciones de CI estándar.
Los proyectos de aprendizaje automático suelen implicar numerosas dependencias importantes: marcos de aprendizaje profundo (PyTorch, TensorFlow), bibliotecas de computación científica (NumPy, SciPy), controladores de GPU y kits de herramientas CUDA. Estas dependencias pueden hacer que las imágenes de Docker tengan un tamaño de varios gigabytes, lo que conlleva tiempos de compilación prolongados.
El desarrollo de ML implica cambios de código frecuentes que deben implementarse para probarlos. Los científicos de datos no suelen disponer del hardware necesario para ejecutar su código en sus ordenadores portátiles locales, lo que significa que el código debe ejecutarse en un clúster remoto, lo que suele implicar la creación de imágenes.
En Truefoundry, nuestro objetivo es permitir a los desarrolladores moverse a un ritmo de iteración rápido y, por eso, queríamos que nuestras compilaciones de Docker fueran muy rápidas. Para entender lo que hicimos para optimizar los tiempos de compilación, primero veamos cómo solíamos crear imágenes en Truefoundry.
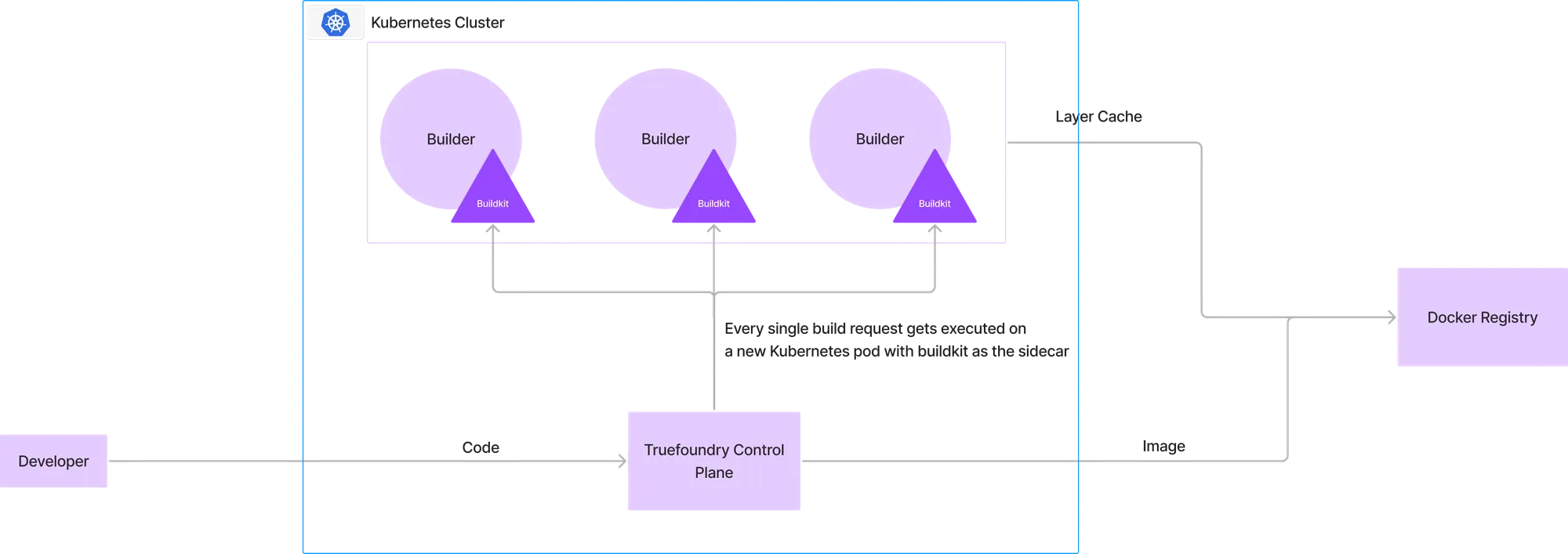
Cada vez que un desarrollador quería crear una imagen, el código se subía al plano de control, donde un nuevo pod comenzaba a crear la imagen con el kit de compilación ejecutándose en el sidecar. El registro de Docker de destino serviría como capa de almacenamiento en caché y la imagen final se enviaría al registro de Docker.
Esta configuración es idéntica a la mayoría de los constructores de CI y tiene las mismas ventajas y desventajas que las configuraciones de CI actuales.
Esto tenía las siguientes ventajas:
Sin embargo, este enfoque tenía algunas desventajas:
1. El pod del kit de compilación requiere una gran cantidad de recursos, lo que implica un tiempo de inicio elevado para el ejecutor de compilación.
2. Se necesita mucho tiempo para descargar la caché del registro de Docker, lo que reduce los tiempos de compilación.
3. No se reutiliza la caché en compilaciones de diferentes cargas de trabajo.
Queríamos ofrecer la misma (y quizás mejor) experiencia de creación de imágenes de forma remota en comparación con las construcciones locales
Decidimos alojar primero el pod buildkit como un servicio en Kubernetes que se pueda compartir entre varios compiladores y que pueda proporcionar almacenamiento en caché en disco local para que las compilaciones de Docker sean realmente rápidas.
Sin embargo, este enfoque tiene algunas limitaciones:
1. Buildkit tiene la restricción fundamental de que el el sistema de archivos de caché solo puede ser utilizado por una instancia de Buildkit. Qué significa que si ejecutamos varias instancias del kit de compilación para procesar varias compilaciones en paralelo, cada una de ellas tendrá su propia caché y no se podrá compartir.
2. Si ejecutamos varias instancias de buildkit y cada una tiene su propia caché, la misma carga de trabajo debe enrutarse a la misma máquina para que la caché se pueda usar de manera efectiva. Esto requiere una lógica de enrutamiento personalizada.
3. El escalado automático de los pods del kit de compilación en función del número de compilaciones en ejecución no es trivial. No podemos usar el uso de la CPU de los pods del kit de compilación como métrica de escalado automático, ya que es posible que Kubernetes termine una compilación pequeña en ejecución suponiendo que no se esté ejecutando nada en esa máquina.
Tener un número dinámico de pods de buildkit con las cargas de trabajo enrutadas a la misma instancia de caché no es un problema trivial. Adjuntar y eliminar volúmenes entre pods es bastante lento en Kubernetes, lo que hace que las compilaciones tarden mucho en iniciarse.
Para superar las limitaciones anteriores, hemos ideado un enfoque híbrido, de modo que la mayoría de las compilaciones se completan muy rápido, mientras que en algunos casos excepcionales de alta concurrencia de compilaciones paralelas, recurrimos a nuestro flujo anterior de ejecución del kit de compilación en un sidecar.
En la arquitectura que se describe en la imagen siguiente, configuramos una cierta concurrencia de compilación, por debajo de la cual todas las compilaciones irán al servicio buildkit. Para ilustrar esto, consideremos que asignamos una máquina con 4 CPU y 16 GB de RAM para el servicio buildkit. A partir de los datos de compilación históricos, podemos deducir que esta máquina puede soportar 2 compilaciones simultáneas. Por lo tanto, si ya hay una compilación en ejecución y aparece una nueva, se dirige al servicio buildkit. Sin embargo, si aparece una compilación más, la redirigiremos al modelo anterior, que usa la caché de capas almacenada en el registro de Docker y ejecuta buildkit como un sidecar.
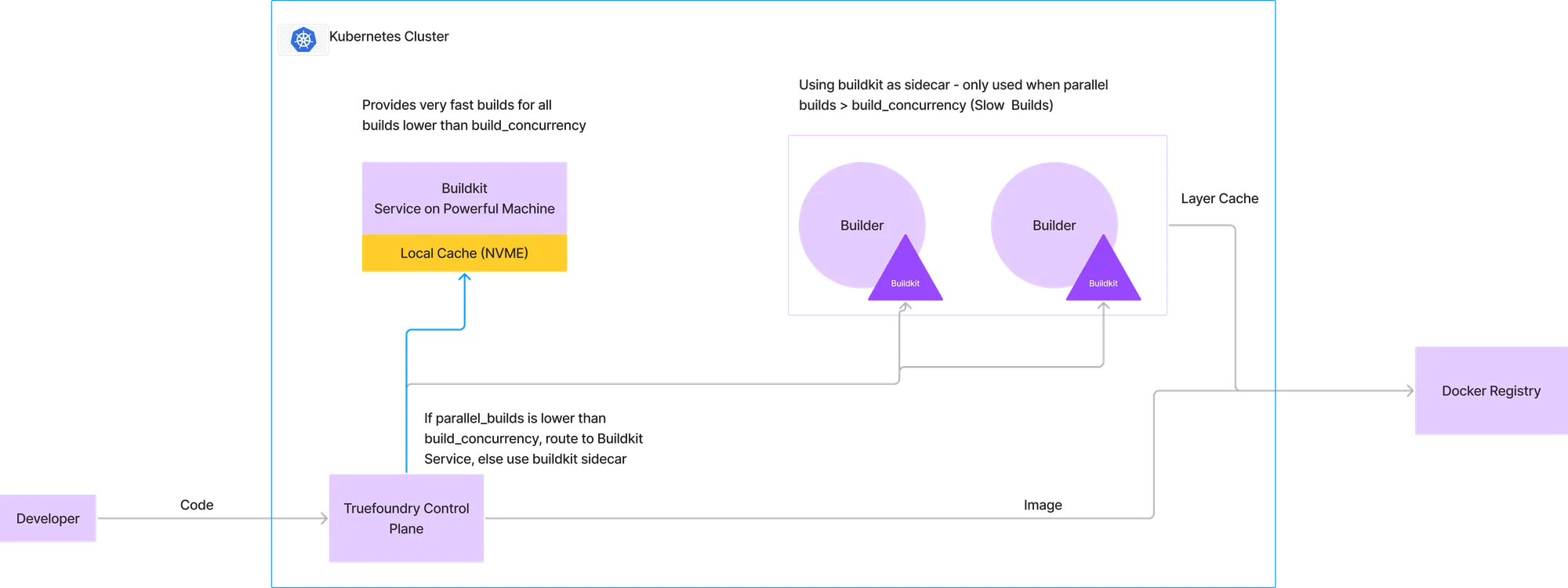
Esto nos permite ofrecer compilaciones ultrarrápidas para el 99% de las cargas de trabajo, mientras que, en muy pocos casos, la compilación termina tardando el tiempo que normalmente lleva en las canalizaciones de CI estándar.
Hay algunas otras mejoras que hicimos en el proceso de construcción para hacerlo más rápido. Algunas de ellas son:
Para comparar nuestros experimentos, tomamos un Dockerfile de muestra que representa el escenario más común para las cargas de trabajo de ML.
DESDE tfy.jfrog.io/tfy-mirror/python:3.10.2-slim
WORKDIR /aplicación
RUN echo «Iniciando la compilación»
COPIAR. /requirements.txt /app/requirements.txt
EJECUTE pip install -r requirements.txt
COPIAR. /app/
EXPONER 8000
CMD ["uvicorn», «aplicación: aplicación», «--host», «0.0.0.0", «--port», «8000"]
El archivo requirements.txt es el siguiente:
fastapi [estándar] ==0.109.1
abrazando la cara - hub == 0.24.6
volm==0.5.4
transformadores==4.43.3
Hicimos una evaluación comparativa de la construcción en 3 escenarios:
Los tiempos incluyen el tiempo necesario para crear y enviar la imagen al registro y la unidad está en segundos.
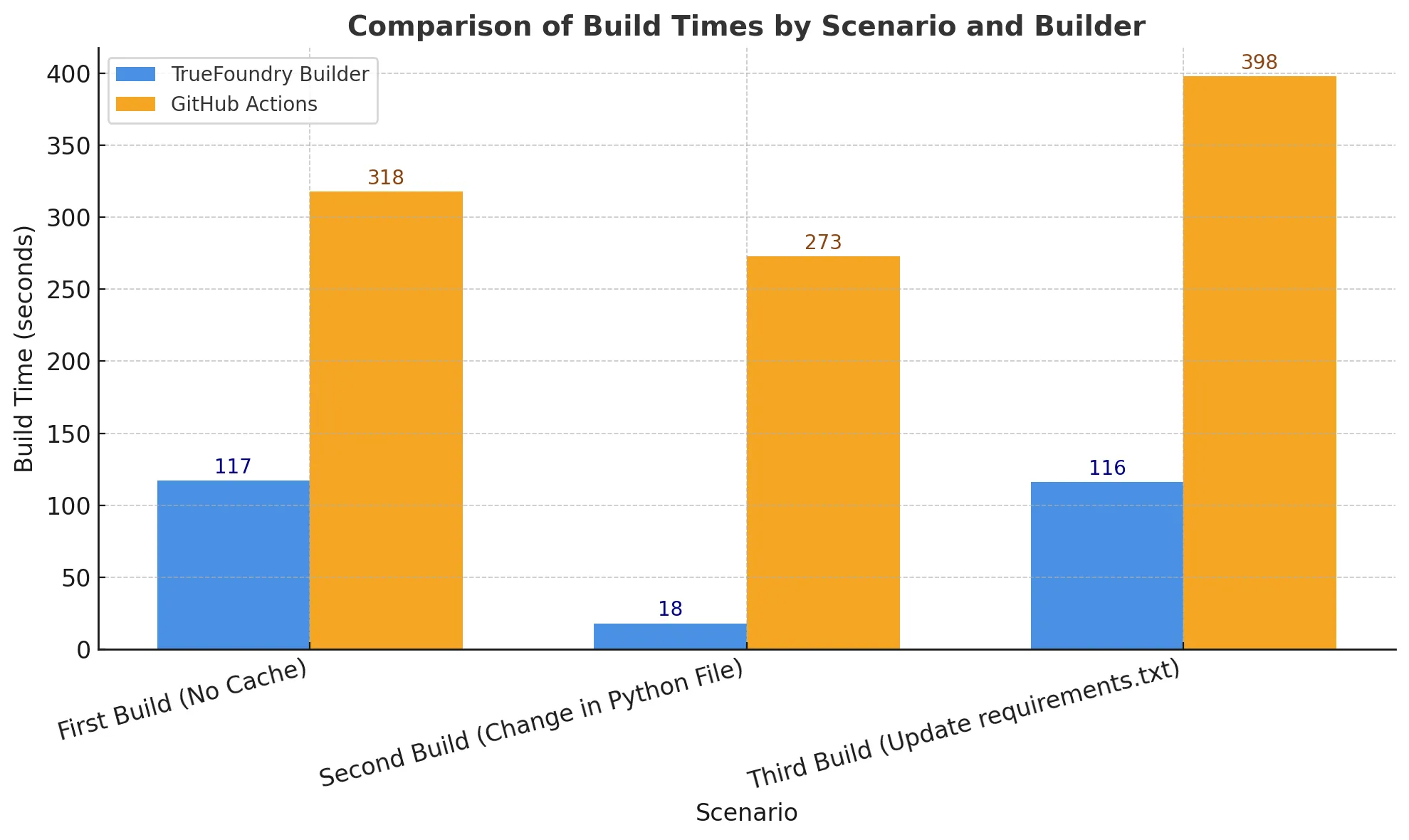
El segundo escenario con solo cambios de código es el escenario más común que encuentran los desarrolladores y, como podemos ver, es casi una mejora de 15 veces en los tiempos de compilación.
También comparamos un escenario con un archivo docker que contiene triton como imagen base, que es una imagen base mucho más grande.
DESDE nvcr.io/nvidia/tritonserver:24.09-py3
WORKDIR /aplicación
RUN echo «Iniciando la compilación»
COPIAR. /requirements2.txt /app/requirements.txt
EJECUTE pip install -r requirements.txt
RUN echo «Terminó la construcción»
Los resultados son los siguientes:
.webp)
En este caso, vemos una mejora de 3 veces en el tiempo de compilación para la primera compilación y una mejora de 9 veces para las posteriores.
Los cambios mencionados anteriormente han mejorado enormemente la experiencia de los desarrolladores y les permiten repetir sus ideas muy rápido sin dejar de mantener la paridad con la forma en que las cosas se implementarán eventualmente en producción.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


