



July 20, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
El propósito de este artículo es educar al lector sobre cómo funcionan los precios de los modelos de lenguaje grande (LLM). Esto está motivado por nuestras conversaciones con varias empresas que utilizan los LLM con fines comerciales. En estas conversaciones nos dimos cuenta de que la economía de la LLM a menudo se malinterpreta, lo que deja un enorme margen de optimización.
¿Te das cuenta de que haciendo el la misma tarea puede llevar 3500$ con un modelo o 1 260 000$ con otro? Esto se produce a costa de la diferencia en el rendimiento, pero deja mucho espacio a la mitad para pensar en cuál es la compensación entre costo y rendimiento. ¿La tarea es tal que puedo usar algo que sea más barato?
Hemos descubierto que, una y otra vez, las empresas sobrestiman o subestiman su gasto en modelos lingüísticos de gran tamaño. En este caso, trataremos de entender el coste que supone utilizar algunos de los modelos lingüísticos más populares y entender cómo funcionan sus precios.
ℹ️
El propósito de este blog no es educar al lector sobre los LLM o sus actuaciones. Este es un blog intensivo en matemáticas centrado en entender los precios de los LLM. Para simplificar, no compararíamos el rendimiento entre estos modelos.
El muestra para el análisis de preciosPara entender cómo funcionan los precios de los LLM, compararíamos el costo incurrido en la misma tarea, es decir, resumir Wikipedia con la mitad de su tamaño.
Usaríamos algunas aproximaciones para simplificar los cálculos y hacerlos más fáciles de entender
❓
Fichas son subpartes de palabras que no dependen precisamente del principio o el final de las palabras. Es la unidad en la que las API de OpenAI dividen la entrada en fichas antes de que se procesen. Los símbolos pueden incluir espacios al final e incluso subpalabras.
Para esta tarea, asumimos que cada artículo se está comprimiendo a la mitad de su tamaño para simplificar. Por lo tanto, los resultados que esperamos serán los siguientes:

Comparar lo que costaría usar diferentes modelos para esta tarea
OpenAI y otras API de terceros suelen cobrar en función de dos palancas: si quieres inferir el uso de sus API
Este costo depende de la cantidad de tokens (explicados anteriormente) que se pasen como contexto/indicación/instrucción a la API.
El costo se basa en la cantidad de tokens que la API devuelve como respuesta.
En el caso de una tarea como la de resumir, dado que es necesario pasar al modelo todo el documento o extracto que se va a resumir, la cantidad de fichas que forman parte del mensaje puede llegar a ser significativa y, por lo tanto, el costo de los insumos.
Con los modelos autohospedados, el usuario debe administrar o aprovisionar la máquina necesaria para ejecutar el modelo. Si bien puede incluir el costo de administrar estos recursos, el precio es relativamente fácil de entender, ya que se basa únicamente en el costo de funcionamiento de la máquina (por lo general, lo que cobran los proveedores de la nube, a menos que tenga su propio clúster local)
Costo de aprovisionamiento de la máquina requerida para ejecutar o alojar el modelo. Dado que la mayoría de estos modelos más grandes son más grandes que lo que se puede ejecutar en un portátil o en un único dispositivo local, lo más común es utilizar un proveedor de nube para estas máquinas.
Los proveedores de nube ofrecen estas instancias, aunque los usuarios pueden tener problemas de disponibilidad de GPU, ya que estos modelos requieren GPU.
Costos de las instancias de AWS
Costos de Google Cloud Instance
Costos de las instancias de Microsoft Azure
Los proveedores de nube ofrecen su capacidad sobrante a un costo entre un 40 y un 90% más económico que las instancias bajo demanda
Costo = No. De fichas (por cada 1000 artículos) x número de artículos (en miles) x coste unitario (por millón de fichas)
Costo de la entrada
1000 (tokens/artículo) X 6000 000 (artículos) X 30$ (/millón de fichas) = 180.000 dólares
Coste de producción
0,5 K (tokens/artículo) X 6.000 K (artículos) X 60$ (/millón de fichas) = 180.000 dólares
Coste total
Costo de entrada + costo de salida
Costo de entrada (/Mn de tokens) Costo de salida (/Mn de tokens) $60 $120
Costo = No. De fichas (por cada 1000 artículos) x número de artículos (en miles) x coste unitario (por millón de fichas)
Costo de la entrada
1000 (tokens/artículo) X 6000 000 (artículos) X 60$ (/Mn de fichas) = 360.000 dólares
Coste de producción
0,5 K (tokens/artículo) X 6.000 K (artículos) X 120$ (/millón de fichas) = 360.000 dólares
Coste total
Costo de entrada + costo de salida
Costo = número de fichas (por 1000 artículos) x número de artículos (en miles) x costo unitario (por millón de fichas)
Costo de la entrada
1000 (tokens/artículo) X 6.000 (artículos) X 11$ (/millón de fichas) = 66.000 dólares
Coste de producción
0,5 K (tokens/artículo) X 6.000 K (artículos) X 60$ (/millón de fichas) = 96.000 dólares
Coste total
Costo de entrada + costo de salida
Costo = No. De fichas (por cada 1000 artículos) x número de artículos (en miles) x coste unitario (por millón de fichas)
Costo de la entrada
1000 (tokens/artículo) X 6000 000 (artículos) X 20$ (/Mn de fichas) = 120.000 dólares
Coste de producción
0,5 K (tokens/artículo) X 6.000 K (artículos) X 20$ (/Mn de fichas) = 60.000 dólares
Coste total
Costo de entrada + costo de salida
Costo = No. De fichas (por cada 1000 artículos) x número de artículos (en miles) x coste unitario (por millón de fichas)
Costo de la entrada
1000 (tokens/artículo) X 6000 000 (artículos) X 2$ (/millón de fichas) = 12.000 dólares
Coste de producción
0,5 K (tokens/artículo) X 6.000 K (artículos) X 60$ (/millón de fichas) = 6.000 dólares
Coste total
Costo de entrada + costo de salida
Costo de funcionamiento de la máquina (/hora para Spot A100-80 Gb) 10$
Costo = número de fichas (por 1000 artículos) x número de artículos (en miles) x costo unitario (por millón de fichas)
Costo de la entrada
1000 (tokens/artículo) X 6000 000 (artículos) X 30$ (/millón de fichas) = 180.000 dólares
Coste de producción
0,5 K (tokens/artículo) X 6.000 K (artículos) X 60$ (/millón de fichas) = 180.000 dólares
Coste total
Costo de entrada + costo de salida
En la mayoría de los casos de uso, las empresas las necesitan para ajustar modelos específicos para sus propios datos y para tareas particulares. Varias empresas han informado de que los modelos de código abierto perfeccionados están a la altura o, a veces, incluso son mejores que las API de terceros, como OpenAI, para una tarea específica.

Coste total
Costo de entrada + costo de salida

Coste total
Costo de entrada + costo de salida

Coste total
Costo de entrada + costo de salida
Aspectos a tener en cuenta en los precios:
Usamos el siguiente punto de referencia para analizar el efecto del ajuste fino de los modelos en el rendimiento de los modelos. Es interesante observar que:
Tipo de tarea Best 6B/7B OOTB Model Few-ShotMoveLM 7B Zero-Shot GPT-3.5 Turbo Zero-Shot GPT-3.5 Turbo Few-Shot GPT-4 Few-Shot Relevancia: conjunto de datos interno0,330,930,840,920,95Extracción: salida estructurada para consultas0.380,980,220.720.380.73Razonamiento: activación personalizada0,620,930.870.880.90.88Clasificación: dominio de la consulta del usuario0,210,790.60.730.70.76 Extracción: salida estructurada de la escritura de entidades0,830,870,90,890,890,89
Creemos en un estado de aplicaciones en el que las tareas más sencillas se gestionen mediante LLM livianos de código abierto, mientras que las tareas más complejas o las que requieren capacidades distintas (por ejemplo, búsqueda web, llamadas a API, etc.), que solo ofrecen los LLM comerciales de código cerrado, se les pueden delegar.
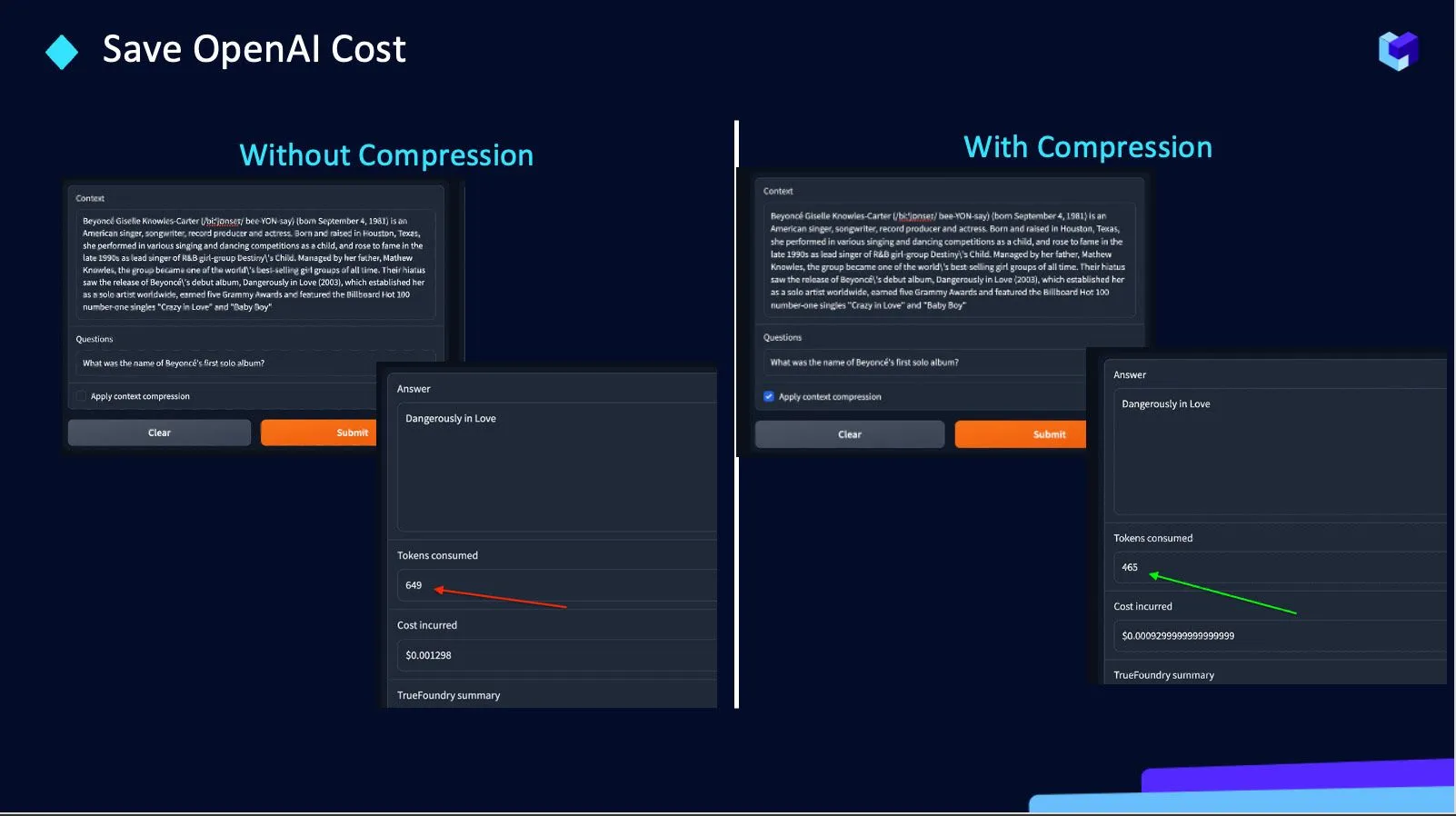
Ayudamos a reducir la cantidad de tokens enviados a las API de OpenAI. Por eso decidimos trabajar en esto porque:
Por lo tanto True Foundry está creando una API de compresión para ahorre el costo de OpenAI en un ~ 30%.
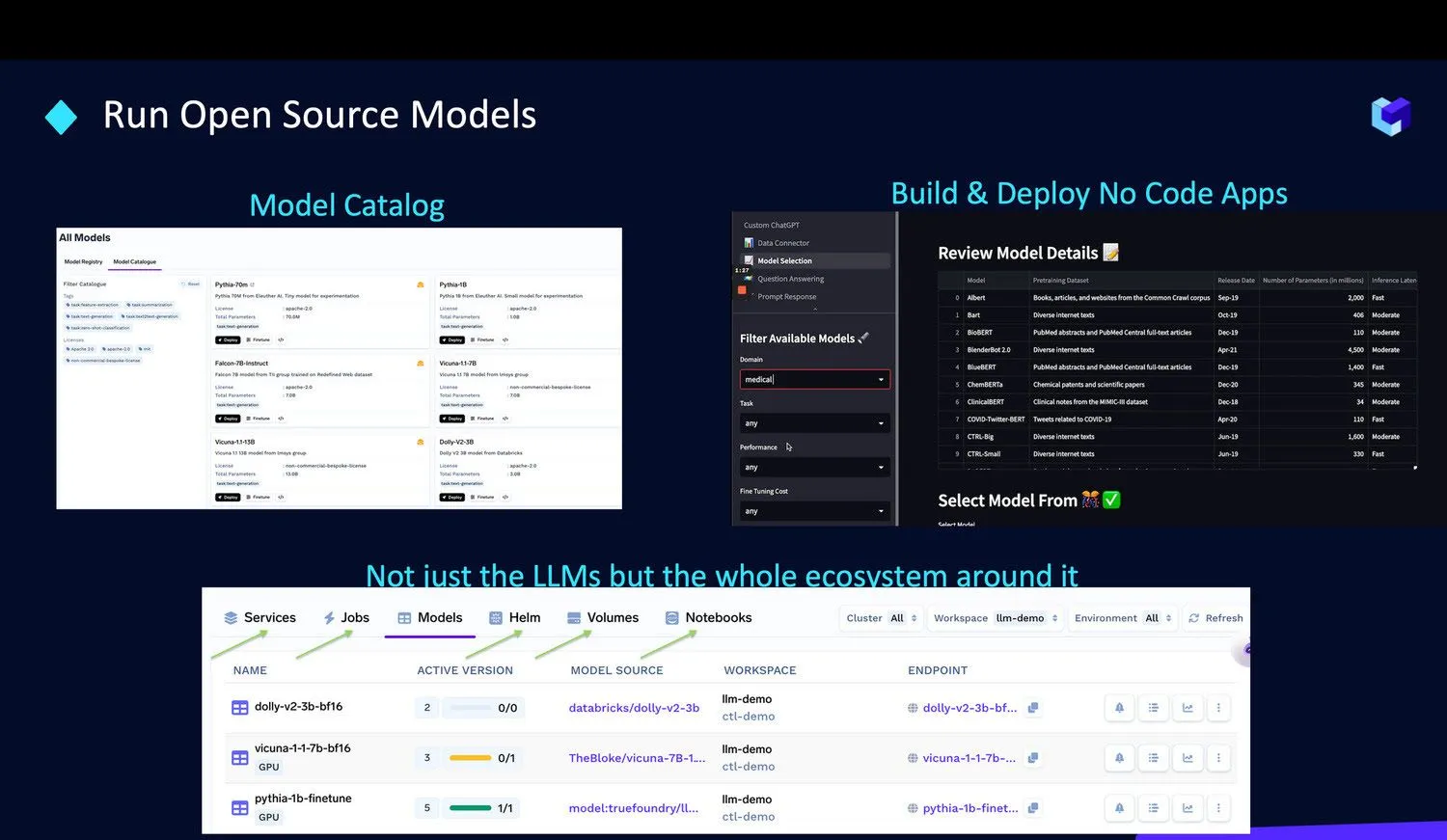
Simplificamos la ejecución de estos modelos dentro de su propia infraestructura a través de nuestras siguientes ofertas:
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


