




July 20, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
La implementación de modelos de lenguaje grande (LLM) de código abierto a escala y, al mismo tiempo, garantizar la confiabilidad, la baja latencia y la rentabilidad puede ser una tarea difícil. Basándome en nuestra amplia experiencia en la construcción de infraestructuras de LLM y en su implementación exitosa para nuestros clientes, he compilado una lista de los principales desafíos a los que suelen enfrentarse las personas en este proceso.
Hay varias opciones para que los servidores modelo alojen LLM y varios parámetros de configuración que se pueden ajustar para obtener el mejor rendimiento para su caso de uso. TGI, VOLM, Abrir LLM son algunos de los marcos más comunes para alojar estos LLM. Puedes encontrar un análisis detallado en este blog. Para elegir el marco adecuado para su alojamiento, es importante comparar el rendimiento de estos marcos para su caso de uso y elegir el que mejor se adapte a su caso de uso. Además, estos marcos tienen sus únicos parámetros ajustables que pueden ayudarte a obtener los mejores resultados de evaluación comparativa.
Las GPU son caras y difíciles de encontrar. Hay varios proveedores de GPU en la nube que van desde nubes prominentes como AWS, GCP y Azure hasta proveedores de nube a pequeña escala como Runpod, Fluidstack, Paperspace y Coreweave. Hay una gran variación en los precios y las ofertas de cada uno de estos proveedores. La confiabilidad también sigue siendo un problema para algunos de los nuevos proveedores de GPU en la nube.
En la práctica, esto es más difícil de lo que parece. Según nuestra experiencia en la ejecución de LLM en entornos de producción, deberías estar preparado para detectar errores puntuales y extraños en los servidores modelo que pueden provocar que tu proceso se interrumpa y que se agoten todas las solicitudes. Es muy importante disponer de gestores de procesos y de sondeos de disponibilidad y funcionamiento adecuados para que los servidores modelo puedan recuperarse de los errores o para que el tráfico pase sin problemas de una instancia en mal estado a otra en buen estado.
Al realizar una evaluación comparativa, es muy importante determinar el equilibrio entre la latencia y el rendimiento. A medida que aumentemos el número de solicitudes simultáneas al modelo, la latencia aumentará ligeramente hasta cierto punto, tras lo cual la latencia se deteriorará drásticamente. Encontrar el equilibrio correcto entre la latencia, el rendimiento y el coste puede llevar mucho tiempo y ser propenso a errores. Tenemos algunos blogs en los que se describen estos puntos de referencia para Llama 7B y Llama 13B.
Los modelos LLM tienen un tamaño enorme, desde 10 GB hasta 100 GB. Puede llevar mucho tiempo descargar el modelo una vez que el servidor modelo esté listo y, a continuación, cargarlo del disco a la memoria. Es esencial que guardes el modelo en caché en el disco para que no acabemos descargando el modelo nuevamente en caso de que el proceso se reinicie. Además, para ahorrar costes de red, es mejor descargar el modelo una vez y compartir el disco entre varias réplicas en lugar de que cada réplica descargue el modelo repetidamente a través de Internet.
El escalado automático es complicado en el caso del alojamiento de LLM debido al alto tiempo de inicio de otra réplica. Si la carga es muy alta, normalmente necesitamos aprovisionar la infraestructura de acuerdo con los picos de réplicas; sin embargo, si se espera que el pico llegue a ciertas horas del día, el escalado automático basado en el tiempo funciona bien.
Empezamos con el enfoque anterior, pero pronto migramos a la arquitectura que se muestra a continuación, lo que nos permite hospedar LLM con costos muy bajos y alta confiabilidad.
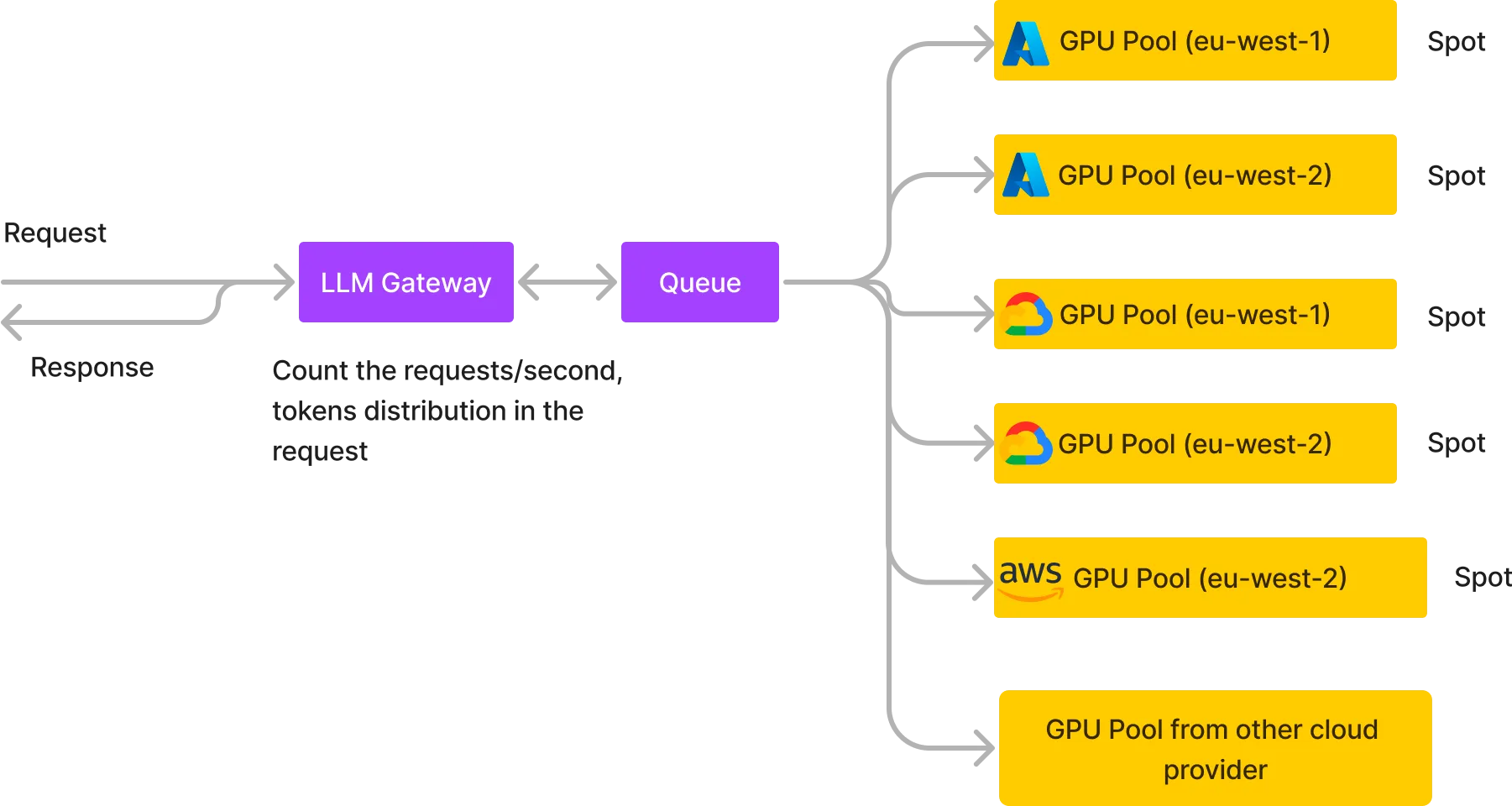
Básicamente, creamos varios grupos de GPU en diferentes proveedores de nube en diferentes regiones y, por lo general, utilizamos instancias puntuales si se trata de AWS, GCP o Azure, o nodos bajo demanda de los proveedores de nube más pequeños. También colocamos una cola en el medio que recibe todas las solicitudes y los distintos grupos de GPU que consumen de la cola y devuelve la respuesta a la cola desde la que se devuelve la respuesta HTTP al usuario. Algunas ventajas de esta arquitectura:
Tomemos un escenario en el que se aloja un LLM con 10 solicitudes por segundo en el pico y 7 solicitudes por segundo en promedio. Supongamos que, mediante una evaluación comparativa, calculamos que una máquina GPU A100 de 80 GB puede generar 0,5 RPS. Consideremos también que el tráfico es mayor durante 12 horas al día (alrededor de 9-10 RPS) y bajo durante las 12 horas restantes del día (7-8 RPS).
Basándonos en los datos anteriores, podemos encontrar la cantidad de máquinas GPU necesarias en el período pico de 12 horas y en el período de 12 horas no pico:
Periodo máximo de 12 horas: 20 GPU
Periodo no pico de 12 horas: 15 GPU
Compararemos el costo de ejecutar el LLM con Sagemaker, hospedar ingenuamente en máquinas bajo demanda en AWS, GCP y Azure y usar nuestra propia arquitectura con escalado automático.
Costo de hospedaje en Sagemaker (región us-east-1):
Costo de 8 máquinas A100 de 80 GB (ml.p4de.24xlarge) -> 47,11$ por hora
Necesitaremos 2 máquinas durante las horas no pico y 3 máquinas durante las horas pico.
Coste mensual total: 85 000$
Coste del alojamiento directo en los nodos de AWS:
Coste de 8 máquinas A100 de 80 GB (p4de.24xlarge) -> 40,966$ por hora
Necesitaremos 2 máquinas durante las horas no pico y 3 máquinas durante las horas punta:
Coste mensual total: 73 000$
Costo de alojamiento en Truefoundry
Con las instancias puntuales y otros proveedores de GPU, podemos reducir el precio promedio de las GPU a 2,5 USD por hora. Suponiendo 15 GPU durante las horas de menor actividad y 20 GPU durante las horas de mayor demanda, el coste total será de:
2,5$ * (15*12 + 20*12) * 30 (días al mes) = 31 MIL DÓLARES
Como podemos ver, podemos organizar el mismo LLM a casi un 30% del precio del Sagemaker con una alta confiabilidad. Sin embargo, será necesario realizar esfuerzos para construir y mantener esta arquitectura. True Foundry puede ayudarlo a alojarlo por usted o a alojarlo en su propia cuenta en la nube sin problemas y, al mismo tiempo, ahorrar costos.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


