

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En mi último trabajo, solíamos crear sistemas de recomendación de productos para empresas de comercio electrónico, lo que significa que nuestras API estaban activas en todas las páginas de su sitio web. Conseguimos un nuevo cliente, que fue nuestra primera oferta de 7 cifras, y fuimos tan cautelosos con ellos que inicialmente los incorporamos en marzo con recomendaciones basadas en reglas. No queríamos arriesgarnos a tener una mala experiencia de usuario con nuestros incipientes modelos de aprendizaje automático.
Más adelante, en abril, desarrollamos modelos de aprendizaje automático y realizamos extensas pruebas fuera de línea y una gran cantidad de control de calidad manual. Finalmente, confiamos en que nuestro modelo funcionaría bien y, luego, lo lanzamos y sucedieron dos cosas:
En general, esto se tradujo en muchos combates, mucha pérdida de credibilidad y casi pérdida de clientes. Tras una retrospectiva interna posterior, nos dimos cuenta de que, si bien el #1 era un error manual, era casi imposible detectar problemas como el #2 fuera de línea. Desde entonces, ¡hemos pasado al lado positivo de hacer lanzamientos oscuros!
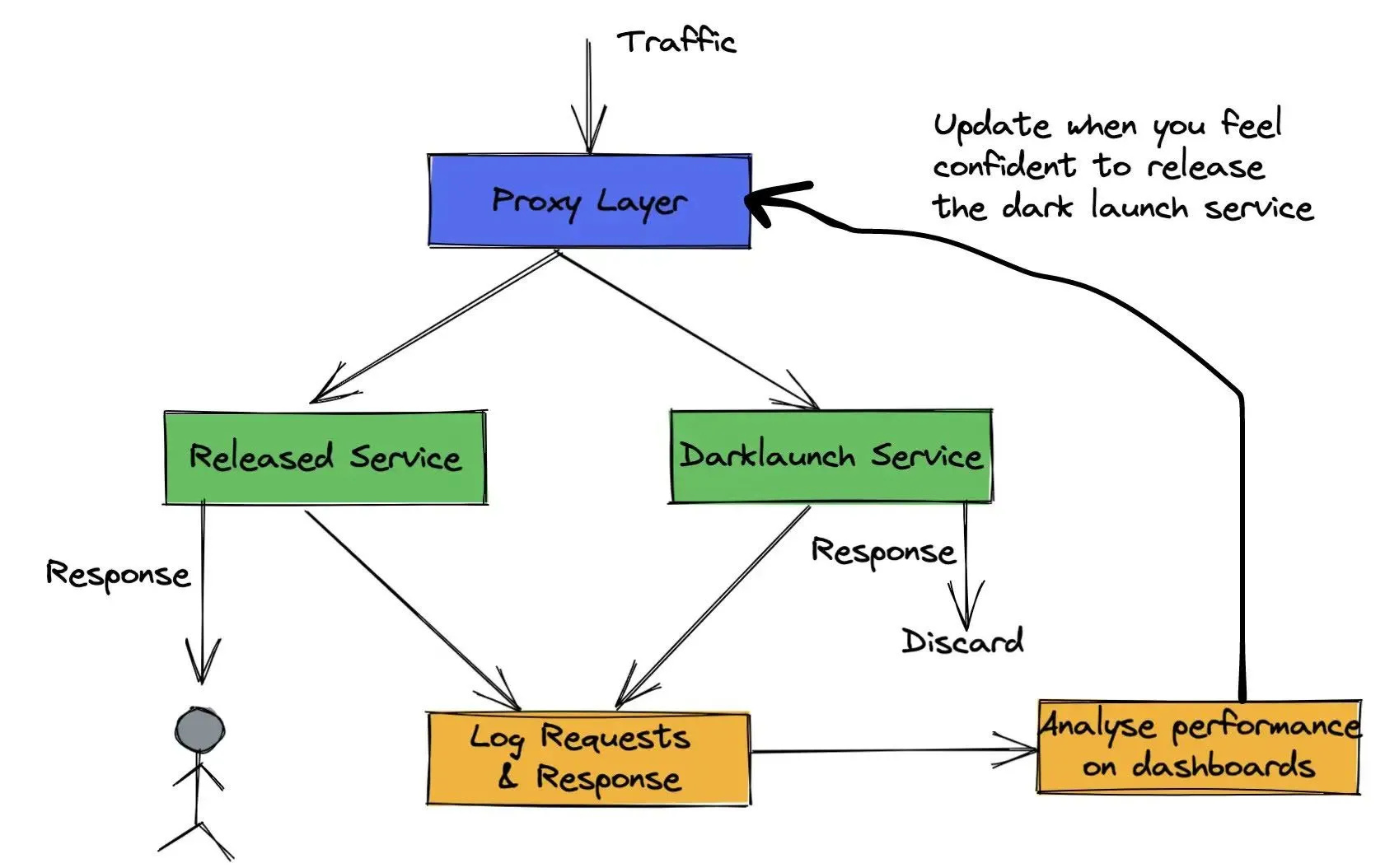
El lanzamiento oscuro es una estrategia de implementación que te permite reproducir tu tráfico de producción real en el servicio recién implementado y descartar la respuesta antes de devolverla al usuario. Se comporta como si el servicio estuviera realmente activo, pero no afecta en absoluto a los usuarios. Esto le permite verificar que su nuevo servicio no tiene ningún error, tiene un rendimiento comparable o mejor en comparación con el servicio anterior y puede gestionar la carga de producción. Una vez que se haya verificado todo esto, es casi trivial cambiar al nuevo servicio de forma gradual. Así que, en cierto modo,
El lanzamiento oscuro es una forma ligera de lanzar tus servicios.
con una desventaja mínima y un enorme potencial alcista.
El lanzamiento oscuro de sus servicios es una de las formas realistas de probar sus servicios y modelos en un sistema similar al de producción. Sin embargo, ejecutar un lanzamiento oscuro puede requerir una gran cantidad de preparación y madurez dentro de la organización desde el punto de vista del desarrollo, la supervisión y la infraestructura.
Las pruebas fuera de línea le permiten comprobar la comportamiento de su sistema, normalmente de forma aislada. Rara vez le permitiría probar el sistema de extremo a extremo junto con el estado de sistema circundante con configuraciones realistas de tráfico y red, como la producción? Puedes lograr el 70% de todo esto mediante un registro meticuloso y pruebas fuera de línea muy complicadas, pero Dark Launch resulta ser un sistema mucho más simple. Esto se debe a que, de todos modos, terminas realizando la mayoría de los pasos anteriores para iniciar y monitorear un servicio con normalidad. Una vez que hayas realizado un lanzamiento oscuro exitoso, el lanzamiento real del nuevo servicio es casi trivial, por lo que la relación entre esfuerzo y recompensa vale la pena.
Hay un par de casos en los que esto podría ser difícil de justificar en la práctica, por ejemplo, si su servicio tiene estado o si realmente cambia la base de datos entonces hacer un lanzamiento oscuro es mucho más complicado. Según mi experiencia personal, garantizar la corrección del sistema se vuelve tan difícil que ¡es casi mejor conformarse con las pruebas fuera de línea que con un lanzamiento oscuro!
Si sientes más curiosidad por los lanzamientos oscuros o quieres compartir algo de tu experiencia, ¡ponte en contacto conmigo en nikunj@truefoundry.com!
True Foundry es un PaaS de implementación de aprendizaje automático sobre Kubernetes para acelerar los flujos de trabajo de los desarrolladores y, al mismo tiempo, permitirles una flexibilidad total a la hora de probar e implementar modelos, al tiempo que garantiza una seguridad y un control totales para el equipo de Infra. A través de nuestra plataforma, permitimos a los equipos de aprendizaje automático implementar y supervisar modela en 15 minutos con un 100% de confiabilidad, escalabilidad y la capacidad de revertirse en segundos, lo que les permite ahorrar costos y lanzar los modelos a la producción más rápido, lo que permite obtener un verdadero valor empresarial.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


