

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En nuestra serie de blogs sobre Kubernetes, hablamos sobre edificios MLOps escalables en Kubernetes, arquitectura para MLOps, y resolver el desarrollo de aplicaciones. En este blog, hablaremos sobre el alojamiento de un servicio de GRPC en el clúster EKS de AWS. El proceso va a ser prácticamente el mismo para todos los clústeres de Kubernetes; sin embargo, tuvimos que realizar algunos ajustes específicos en el balanceador de cargas de AWS para que esto funcionara.
gRPC es un marco de RPC de código abierto que puede ejecutarse en cualquier entorno. Es capaz de conectar de manera eficiente los servicios dentro de los centros de datos y entre ellos, además de ofrecer soporte para equilibrar la carga, rastrear, comprobar el estado y la autenticación.
Our case: Hospedar modelos de Tensorflow como API que aceptaban una carga útil de alrededor de 100 MB. El GRPC funciona mucho mejor con cargas útiles más grandes, por lo que expusimos el puerto GRPC en el puerto 5000.
Alojamos el servicio en Kubernetes utilizando el YAML de implementación que se muestra a continuación:
Versión de API: aplicaciones/v1
type: Despliegue
metadatos:
name: ml-api
espacio de nombres: ml-services
especificación:
réplicas: 1
selector:
Etiquetas coincidentes:
truefoundry.com/component:ml-api
plantilla:
metadatos:
tags:
truefoundry.com/application: ml-api
especificación:
contenedores:
- name: ml-api
image: >-
xxxx.dkr. ecr.us-east-1.amazonaws.com /ml-services-ml-api:última
puertos:
- número: port-8500
Container Port: 8500
protocol: TCP
recursos:
limites:
CPU: '4'
almacenamiento efímero: 2G
memoria: 4G
solicitudes:
CPU: '1'
almacenamiento efímero: 1G
memoria: 500 M
Política de extracción de imágenes: si no está presente
Reinicio policy: always
Periodo de gracia de terminación en segundos: 30
Política de DNS: ClusterFirst
Contexto de seguridad: {}
Secretos de extracción de imágenes:
- name: ml-api-image-pull-secret
Nombre del planificador: programador predeterminado
estrategia:
tipo: RollingUpdate
Actualización continua:
Máximo no disponible: 25%
Sobretensión máxima: 0
Esto hará que aparezca la cápsula. Necesitamos crear el objeto de servicio usando el siguiente YAML:
Versión de API: networking.istio.io/v1alpha3
tipo: Puerta de enlace
metadatos:
tags:
argocd.argoproj.io/instance: tfy-istio-ingress
nombre: tfy-wildcard
espacio de nombres: istio-system
especificación:
selector:
sitio: tfy-istio-ingress
servidores:
- anfitriones:
- 'ml.example.com'
puerto:
name: http-tfy-wildcard
número: 80
protocol: HTTP
tls:
Redireccionamiento HTTPS: verdadero
- anfitriones:
- 'ml.example.com'
puerto:
nombre: https://tfy-wildcard
número: 443
protocol: HTTP
Estamos usando Istio como capa de entrada en Kubernetes. Istio aprovisiona un balanceador de carga cuando se instala el istio-ingress. La configuración del balanceador de cargas se puede personalizar mediante anotaciones en la puerta de enlace de istio. Las especificaciones para crear la puerta de enlace de Istio son las siguientes:
Versión de API: networking.istio.io/v1alpha3
tipo: Puerta de enlace
metadatos:
tags:
argocd.argoproj.io/instance: tfy-istio-ingress
nombre: tfy-wildcard
espacio de nombres: istio-system
especificación:
selector:
sitio: tfy-istio-ingress
servidores:
- anfitriones:
- 'ml.example.com'
puerto:
name: http-tfy-wildcard
número: 80
protocol: HTTP
tls:
Redireccionamiento HTTPS: verdadero
- anfitriones:
- 'ml.example.com'
puerto:
nombre: https://tfy-wildcard
número: 443
protocol: HTTP
Estamos finalizando el SSL en el balanceador de carga de AWS. Para ello tenemos que adjuntar el certificado al Load Balancer. Esto se puede lograr mediante las anotaciones que aparecen a continuación en el gráfico de pasarelas de istio (https://istio-release.storage.googleapis.com/charts).
«service.beta.kubernetes.io/aws-load-balancer-type»: «nlb»
«service.beta.kubernetes.io/aws-load-balancer-backend-protocol»: «tcp»
<certificate-arn>«service.beta.kubernetes.io/aws-load-balancer-ssl-cert»: «»
«service.beta.kubernetes.io/aws-load-balancer-ssl-ports»: «https»
«service.beta.kubernetes.io/aws-load-balancer-alpn-policy»: «Se prefiere HTTP 2»
Es importante especificar la política alpn para permitir el tráfico GRPC. Nuestro servicio ml-api se puede exponer creando un VirtualService que apunta al servicio de Kubernetes. El YAML del servicio virtual es el siguiente:
Versión de API: networking.istio.io/v1alpha3
tipo: VirtualService
metadatos:
tags:
argocd.argoproj.io/instancia: ml-services_ml-api
nombre: ml-apiport-8500-vs
espacio de nombres: ml-services
especificación:
pasarelas:
- istio-system/tfy-wildcard
anfitriones:
- ml.example.com
http:
- recorrido:
- destino:
anfitrión: ml-api
puerto:
número: 8500
Una vez que el servicio virtual esté expuesto, podemos hacer solicitudes a nuestro servicio en ml.example.com. Después, quisimos añadir una autenticación a la API para que todo el mundo no pudiera llamar a la API. Podríamos haber agregado la autenticación al código, pero decidimos agregarla en la capa istio para que pueda ser una capa unificada en todos los servicios.
Para añadir la autenticación en la capa istio-ingress, decidimos seguir adelante con un Plugin IstioWASM. El nombre del complemento tiene un aspecto similar a:
Versión de API: extensions.istio.io/v1alpha1
tipo: WASMPlugin
metadatos:
name: ml-services-ml-api-0
espacio de nombres: istio-system
especificación:
Fase: AUTHN
Configuration of the Plugin:
reglas básicas de autenticación:
- credenciales:
- nombre de usuario:contraseña
anfitriones:
- ml.example.com
prefijo:/
métodos de solicitud:
- OBTENER
- PONER
- PUBLICAR
- PARCHE
- ELIMINAR
selector:
Etiquetas coincidentes:
sitio: tfy-istio-ingress
url: oci: //ghcr.io/istio-ecosystem/wasm-extensions/basic_auth:1.12.0
Una vez que haya aplicado la especificación anterior al clúster, la aplicación le pedirá el nombre de usuario y la contraseña una vez que la abra en el navegador.
Para que el proceso anterior sea mucho más fácil, decidimos hacerlo realmente fácil en Verdadera fundición plataforma.
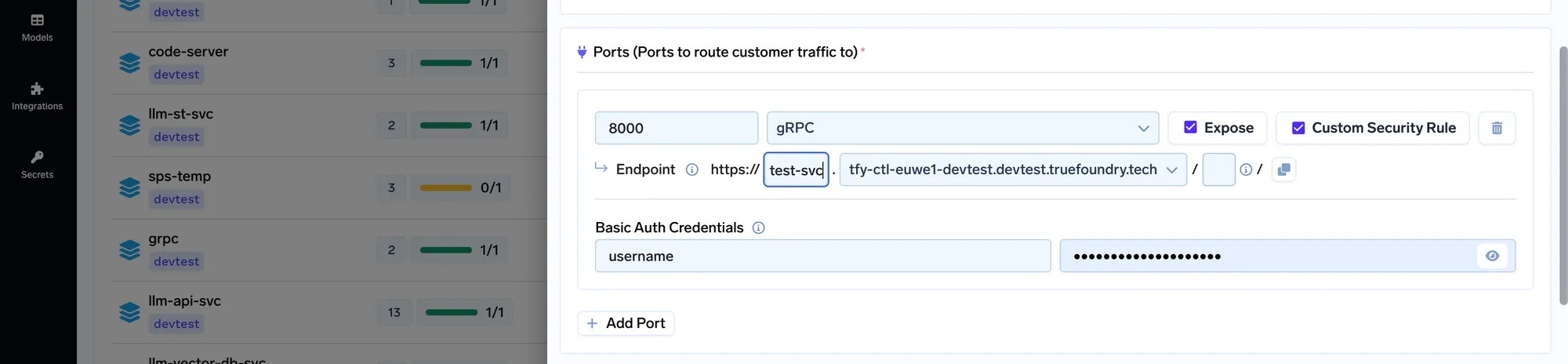
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


