

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Amazon SageMaker se ha convertido de hecho en el sistema operativo predeterminado para el aprendizaje automático dentro del perímetro de AWS. Lanzado en 2017, prometía industrializar lo que entonces era un ecosistema fragmentado de scripts personalizados y aprovisionamiento manual de servidores. Al resumir la configuración subyacente de EC2 y la organización de contenedores, permitió a las organizaciones estandarizar sus procesos de aprendizaje automático.
Sin embargo, estamos en 2026 y la propuesta de valor de un servicio gestionado de código cerrado y una sola nube está siendo objeto de escrutinio. Las quejas que recibimos de los equipos de ingeniería son consistentes: modelos de precios opacos que provocan sorpresas a fin de mes, curvas de aprendizaje pronunciadas para quienes no son nativos de AWS y una arquitectura «amurallada» que penaliza las estrategias de nube múltiple.
Esta revisión técnica considera SageMaker no como un folleto de marketing, sino como una pieza de infraestructura. Examinamos la economía de la unidad, la fricción operativa y las desventajas arquitectónicas basándonos en los datos de G2, Gartner Peer Insights y en la experiencia operativa directa. También evaluaremos si los planos de control desacoplados, como True Foundry ofrecen un camino viable para evitar la dependencia de un solo proveedor.
En esencia, Amazon SageMaker es un paquete de servicios gestionados que abarca la informática (EC2), el almacenamiento (S3/EBS) y la orquestación de contenedores (EKS/ECS) de AWS. Proporciona un entorno de desarrollo (IDE) integrado de extremo a extremo y un plano de control para el ciclo de vida del aprendizaje automático.
Las actualizaciones recientes, como el «Unified Studio» y la integración con Data Lakehouses, intentan cerrar la brecha entre la ingeniería de datos y las operaciones de aprendizaje automático. Sin embargo, para el ingeniero de plataformas, SageMaker es básicamente un conjunto de API patentadas que se utilizan para proporcionar procesamiento efímero para el entrenamiento y procesamiento persistente para la inferencia.
Público objetivo:
Alcance operativo:
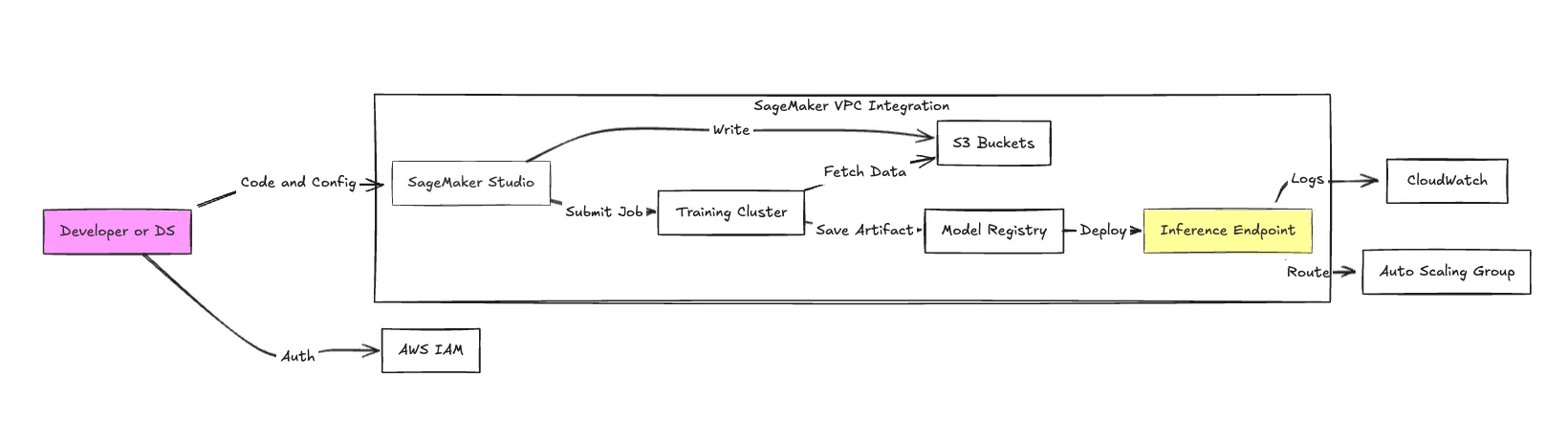
SageMaker es un monolito. Si bien ofrece docenas de subservicios, los siguientes componentes constituyen el conjunto operativo principal.
Studio es un IDE basado en la web basado en JupyterLab. Si bien centraliza el acceso, introduce latencia. La puesta en marcha de una aplicación «KernelGateway» puede tardar varios minutos. Crea una capa de abstracción sobre la instancia EC2 subyacente, lo que simplifica el acceso pero complica la utilización de los recursos del sistema local para la depuración.
SageMaker permite el entrenamiento distribuido entre clústeres. HyperPod de SageMaker es la característica más destacada aquí, diseñada para resistir las fallas de hardware durante los trabajos de capacitación de LLM de larga duración. Detecta y reemplaza automáticamente las instancias defectuosas, algo fundamental cuando se alquilan costosos clústeres de GPU, en los que un fallo de un solo nodo puede hacer perder días de tiempo de procesamiento.
SageMaker ofrece inferencia en tiempo real, inferencia sin servidor e inferencia asincrónica.
Una solución de AutoML que recorre algoritmos en iteración para encontrar el mejor modelo. Si bien es útil para la creación rápida de prototipos con datos tabulares, los ingenieros experimentados suelen encontrar que el código generado es difícil de refactorizar u optimizar para tener en cuenta las restricciones de inferencia de producción.
Esta es la capa de «pegamento». SageMaker Pipelines es un servicio de CI/CD específico para el aprendizaje automático. Se integra perfectamente con el Model Registry (control de versiones) y con el Model Monitor (detección de desviaciones). La contrapartida es la fuerte combinación de proveedores: la migración de un SageMaker Pipeline a Flujo de aire o Flujos de trabajo de Argo normalmente requiere una reescritura completa.
Data Wrangler proporciona una interfaz de usuario para la limpieza de datos y genera código python. La Feature Store actúa como un repositorio centralizado de funciones. Tenga en cuenta que el Feature Store cuenta con el respaldo de Glue y DynamoDB, lo que significa que las lecturas de alto rendimiento pueden generar importantes costos secundarios para la base de datos.
El precio es el punto de fricción más común. SageMaker se basa en un modelo basado en el consumo, con un margen sobre los precios sin procesar de EC2. No hay comisiones iniciales, pero la previsibilidad de los costes es baja debido a la gran cantidad de vectores facturables.
Se le facturará por:
1. Instancias de portátiles:
Una instancia de portátil mediana estándar ml.t3. cuesta aproximadamente **0,05 dólares/hora**. Sin embargo, los desarrolladores suelen dejarlas funcionando de un día para otro. Un equipo de 10 desarrolladores que deja las instancias encendidas durante un mes se traduce en unos 360$ de «desperdicio», sin incluir los costes de almacenamiento.
2. Puntos finales de inferencia (el asesino silencioso del presupuesto):
La inferencia es donde los costos se disparan. A diferencia de la formación (que finaliza), los terminales funcionan 24 horas al día, 7 días a la semana.
3. Instancias puntuales y de capacitación:
Managed Spot Training puede ofrecer hasta un 90% de descuento en comparación con las tarifas bajo demanda. Sin embargo, AWS puede reemplazar (interrumpir) las instancias puntuales en cualquier momento. Si su lógica de puntos de control de entrenamiento no es sólida, perderá el progreso.
Escenario del mundo real:
Una empresa emergente de tamaño mediano que esté capacitando un LLM personalizado y que aloje 5 modelos en producción puede recibir fácilmente facturas que superen los 25 000$ al mes. Según Precios de AWS, los cargos por procesamiento de datos para funciones como Data Wrangler comienzan en 0,14 USD por nodo por hora, lo que aumenta de forma lineal con el volumen de datos.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Analizamos los comentarios de G2, Gartner Peer Insights y los foros de desarrolladores para identificar el consenso.
Los usuarios aprecian la naturaleza de «cumplimiento integral» de la plataforma.
El sentimiento negativo se centra en la experiencia del desarrollador (DX) y en la opacidad de la facturación.
Nota sobre «SageMaker Gateway»: A menudo hay confusión con respecto a este término. Hace referencia a la integración de Amazon API Gateway con los puntos de enlace de SageMaker para exponer los modelos como API REST públicas. Si bien es potente, introduce otro nivel de latencia y coste (API Gateway cobra por millón de solicitudes) que los desarrolladores deben gestionar.
La decisión depende de la filosofía arquitectónica y la elasticidad del presupuesto de su organización.
Cuando SageMaker tiene sentido:
Cuándo considerar las alternativas:
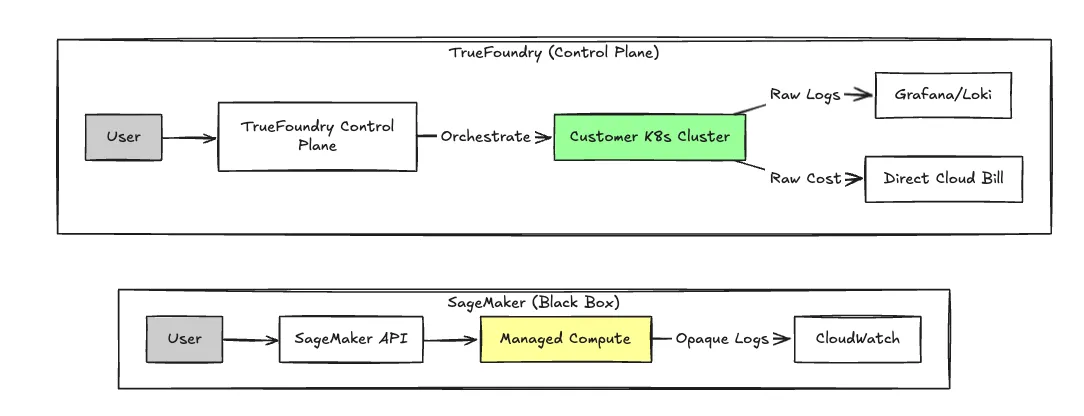
Para los equipos que consideran que SageMaker es demasiado rígido o caro, True Foundry opera en una arquitectura fundamentalmente diferente. Es un plano de control que se encuentra en la parte superior de su propia cuenta en la nube (AWS, GCP, Azure), en lugar de un servicio gestionado en forma de caja negra.
Este enfoque de «traiga su propia nube» (BYOC) permite a TrueFoundry organizar el procesamiento dentro de su VPC. Obtienes la experiencia de desarrollador de una plataforma gestionada como Heroku, pero la economía unitaria subyacente de las instancias EC2/GKE/AKS sin procesar.
La diferencia fundamental es dónde se lleva a cabo la computación. En SageMaker, usted alquila las capacidades informáticas de la plataforma. En TrueFoundry, la plataforma organiza sus funciones informáticas.
Whatfix, que prestaba servicios a más de 80 empresas de la lista Fortune 500, necesitaba modernizar su ciclo de vida de lanzamiento en diversos entornos locales y en la nube. Al adoptar TrueFoundry para administrar sus microservicios basados en Kubernetes, eliminaron la fricción de las implementaciones monolíticas. Esta transición redujo el tiempo de implementación local de tres meses a solo dos semanas.
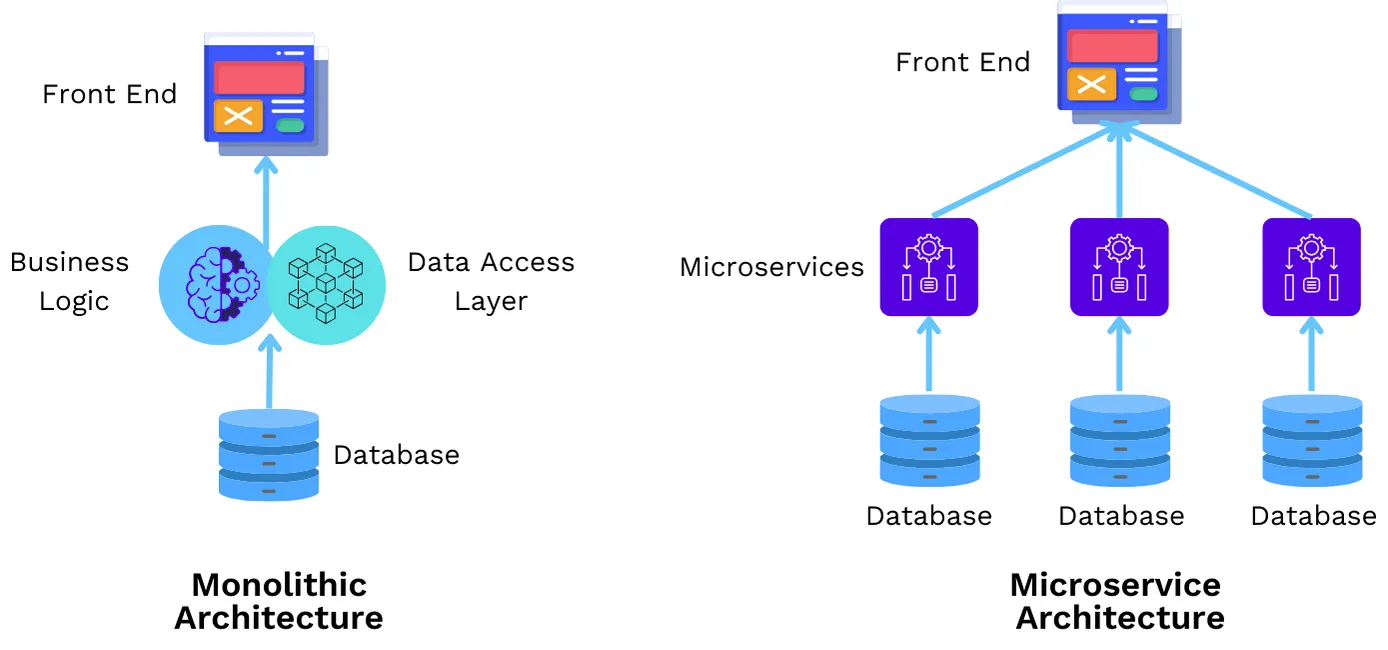
Whatfix logró un ciclo de lanzamiento 6 veces más corto, lo que permitió a un pequeño equipo de DevOps apoyar a más de 150 desarrolladores con un único panel de control para la administración de múltiples clústeres.
Lea la historia completa: Caso práctico de migración e implementación local de Whatfix Kubernetes
Amazon SageMaker es un conjunto de herramientas sólido de nivel empresarial. Si su organización está vinculada legal o técnicamente a AWS y cuenta con un equipo de DevOps dedicado a gestionar las complejidades de facturación y configuración, se trata de una opción estándar y segura.
Sin embargo, para los equipos que crean aplicaciones GenAI modernas en las que la escasez de GPU y la economía de las unidades representan riesgos existenciales, el «impuesto AWS» es difícil de justificar.
TrueFoundry ofrece la evolución lógica: la usabilidad de un servicio gestionado con la libertad económica y arquitectónica de ser propietario de su infraestructura. Si necesitas implementar un LLM en AWS y GCP para encontrar las GPU más baratas, o si simplemente quieres un panel que hable el lenguaje de los desarrolladores y no de los contables, TrueFoundry es la mejor opción arquitectónica.
Reserve una demostración con TrueFoundry para ver cómo puede reducir los costos de inferencia en un 40% y, al mismo tiempo, recuperar el control de su infraestructura.
TrueFoundry es la alternativa ideal a AWS SageMaker porque proporciona un control total de la infraestructura sin los precios de caja negra. A diferencia de un servicio típico totalmente gestionado, permite a los científicos de datos alojar modelos de aprendizaje automático mediante PyTorch o TensorFlow con un mínimo esfuerzo. El Puerta de enlace de IA TrueFoundry elimina el pesado trabajo de la orquestación y, al mismo tiempo, proporciona la escalabilidad requerida para la IA generativa.
SageMaker es técnicamente maduro y fiable para el aprendizaje automático tradicional. Destaca en cuanto a seguridad y cumplimiento, pero tiene una mala puntuación en cuanto a usabilidad, experiencia de depuración y transparencia de costes en comparación con las plataformas MLOps modernas.
Depende de los datos. Databricks (plataforma unificada de análisis de datos) es superior para las cargas de trabajo con alto contenido de Spark y el aprendizaje automático basado en la ingeniería de datos. Por lo general, se prefiere SageMaker para tareas de inferencia y aprendizaje profundo en las que los datos ya están preparados en S3.
Sí, tiene la mayor cuota de mercado entre los servicios de aprendizaje automático en la nube pública simplemente debido al dominio de AWS. Sin embargo, la cuota de mercado está cambiando a medida que la «independencia de la nube» se ha convertido en una prioridad para GenAI Stacks.
No. OpenAI proporciona modelos como servicio (API). SageMaker proporciona la infraestructura necesaria para entrenar y alojar sus propios modelos (incluidas las alternativas de código abierto a OpenAI, como Llama 3 o Mistral).
Son funcionalmente similares. Por lo general, se considera que Azure ML tiene una interfaz de usuario más intuitiva y una mejor integración con VS Code, mientras que SageMaker ofrece un control más detallado de la infraestructura de bajo nivel para los usuarios avanzados.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


