

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 27, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
A medida que los equipos trasladan las aplicaciones de LLM y los agentes de IA a la producción, el costo se convierte rápidamente en uno de los problemas más difíciles de analizar. A diferencia de las cargas de trabajo en la nube tradicionales, los costos de la IA dependen de patrones de uso dinámicos, no deterministas y, a menudo, ocultos detrás de múltiples capas de abstracción.
Una sola solicitud de usuario puede desencadenar múltiples llamadas de modelo, reintentos, invocaciones de herramientas y bucles de agentes. Los pequeños cambios en las solicitudes, la lógica de enrutamiento o el comportamiento de los agentes pueden aumentar considerablemente el uso y el costo de los tokens, a menudo sin señales obvias hasta que llegan los informes de facturación.
Esta es la razón Observabilidad de costos de IA es fundamental en los sistemas de producción. Va más allá del seguimiento del recuento de fichas o de las facturas de los proveedores. La observabilidad de los costes mediante la IA se centra en atribuir los costes a las unidades reales de los sistemas de IA, como las solicitudes, las solicitudes, los agentes, las herramientas y los usuarios, al tiempo que permite a los equipos detectar y controlar los problemas de costes de forma temprana.
En este blog, explicaremos qué significa la observabilidad de los costos de la IA en la práctica, por qué los costos de la IA son difíciles de rastrear y cómo los equipos utilizan las arquitecturas basadas en pasarelas para monitorear y controlar el gasto de LLM en producción.
La observabilidad de costos de la IA es la capacidad de mida, atribuya y analice el costo de las cargas de trabajo de IA entre modelos, agentes y flujos de trabajo en tiempo real.
En los sistemas de producción, esto suele incluir:
En la práctica, esto se extiende más allá de los simples paneles de facturación y pasa a ser estructurado Solución de seguimiento de costos LLM, donde el uso de los tokens, los reintentos, las decisiones de enrutamiento y el comportamiento de los agentes están directamente relacionados con los flujos de trabajo reales de las aplicaciones.
A diferencia del monitoreo de costos de infraestructura tradicional, la observabilidad de costos de la IA debe operar en la capa de aplicación e inferencia. Las herramientas de facturación en la nube pueden indicar a los equipos cuánto han gastado en total, pero no explican por qué los costos aumentaron o qué parte del sistema lo causó.
La observabilidad efectiva de los costos de la IA brinda a los equipos el contexto necesario para responder preguntas como:
Al hacer visibles los costos a este nivel, los equipos pueden tratar el gasto en IA como una métrica operativa y no como un gasto sorpresa.
Los costos de la IA son difíciles de rastrear no porque los precios sean opacos, sino porque el costo es una propiedad emergente del comportamiento del sistema. En los entornos de producción, el uso de la LLM depende de la lógica de enrutamiento, los reintentos, los agentes y las llamadas a las herramientas, todos los cuales interactúan de formas poco obvias.
Varios factores hacen que la observabilidad de los costos de la IA sea un desafío para los equipos.
La mayoría de los proveedores de LLM cobran en función de los tokens, pero el uso de los tokens es muy sensible al comportamiento del tiempo de ejecución. Los pequeños cambios en las solicitudes, el tamaño del contexto o las restricciones de salida pueden aumentar significativamente el recuento de tokens. Dado que estos cambios suelen producirse en la capa de aplicación o de aviso, son difíciles de detectar utilizando únicamente la facturación a nivel de proveedor.
Los sistemas de producción rara vez se basan en un solo modelo. Los equipos envían las solicitudes a varios modelos y proveedores para equilibrar el costo, la latencia y la calidad. Sin una visión centralizada, los datos de costos se fragmentan entre los proveedores, lo que dificulta la comparación u optimización del gasto de manera integral.
Los fallos son caros en los sistemas de IA. Los reintentos y la lógica de respaldo pueden multiplicar silenciosamente los costos, especialmente cuando las solicitudes varían de un modelo a otro. Al no poder observarlos a nivel de solicitud, los equipos suelen pasar por alto estos multiplicadores de costes ocultos hasta que aparecen en las facturas agregadas.
Los sistemas basados en agentes amplifican la complejidad de los costos. La ejecución de un solo agente puede implicar varias llamadas a modelos, pasos de planificación e invocaciones de herramientas. Si un agente entra en un ciclo o hace un uso excesivo de las herramientas, los costos pueden aumentar rápidamente. El seguimiento de este comportamiento requiere conocer paso a paso la forma en que los agentes lo ejecutan.
Las herramientas de costos de la nube y los paneles de proveedores informan sobre el uso a nivel de cuenta o proyecto. No atribuyen el costo a las solicitudes, los agentes, los usuarios o los flujos de trabajo. Esto dificulta que los equipos de plataformas hagan cumplir los presupuestos o que los equipos de aplicaciones optimicen su propio uso.
En la práctica, estos desafíos significan que los problemas de costos de la IA a menudo se detectan tarde y se abordan de forma reactiva. Esta es la razón por la que los equipos que ejecutan cargas de trabajo de IA de producción necesitan incorporar la capacidad de observación de los costos Puerta de enlace de IA y ruta de ejecución, por donde pasan todas las solicitudes.
Para controlar el gasto de IA en la producción, los equipos necesitan más que una factura mensual total. Tienen que entender de dónde proviene el costo y por qué. La observabilidad de los costos se basa en Observabilidad del LLM vinculando el uso y el gasto de los tokens a las solicitudes, los agentes y los flujos de trabajo. La observabilidad efectiva de los costos de la IA desglosa el gasto en dimensiones que se corresponden con la forma en que se construyen y operan realmente los sistemas de IA.
Entre las dimensiones de coste más útiles se incluyen las siguientes.
Esta es la base. El seguimiento del costo por solicitud ayuda a los equipos a comprender qué tan costosas son las interacciones individuales de los usuarios y cómo ese costo cambia con el tiempo. Los picos en este caso suelen indicar un rápido crecimiento, reintentos o cambios en las rutas.
En los sistemas multimodelo, los diferentes modelos tienen perfiles de costes muy diferentes. Los equipos necesitan saber cuánto gasto se destina a cada modelo y proveedor, y cómo las decisiones de enrutamiento afectan al costo general. Esto es esencial para lograr un equilibrio fundamentado entre la calidad, la latencia y el gasto.
Las indicaciones influyen directamente en el uso de los tokens. El seguimiento de los costes por versión rápida y rápida permite a los equipos ver qué anuncios son más caros y si los cambios recientes han aumentado o reducido el gasto. Esto es especialmente importante cuando las solicitudes se comparten entre varias aplicaciones o agentes.
En los sistemas basados en agentes, la atribución de costos debe ir más allá de las llamadas de modelos individuales. Los equipos deben comprender cuánto cuesta la ejecución completa de un agente o un flujo de trabajo de principio a fin, incluidos los pasos de planificación, las llamadas a las herramientas y los reintentos. Esto ayuda a detectar de forma temprana el comportamiento ineficiente de los agentes.
Para las plataformas internas y las implementaciones empresariales, la atribución de los costos a los usuarios o equipos permite la rendición de cuentas y la presupuestación. Esta dimensión suele ser necesaria para hacer cumplir los límites de uso o para reducir los costos de forma interna.
La observación conjunta de estas dimensiones permite a los equipos pasar del análisis de costos reactivo al control de costos proactivo.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

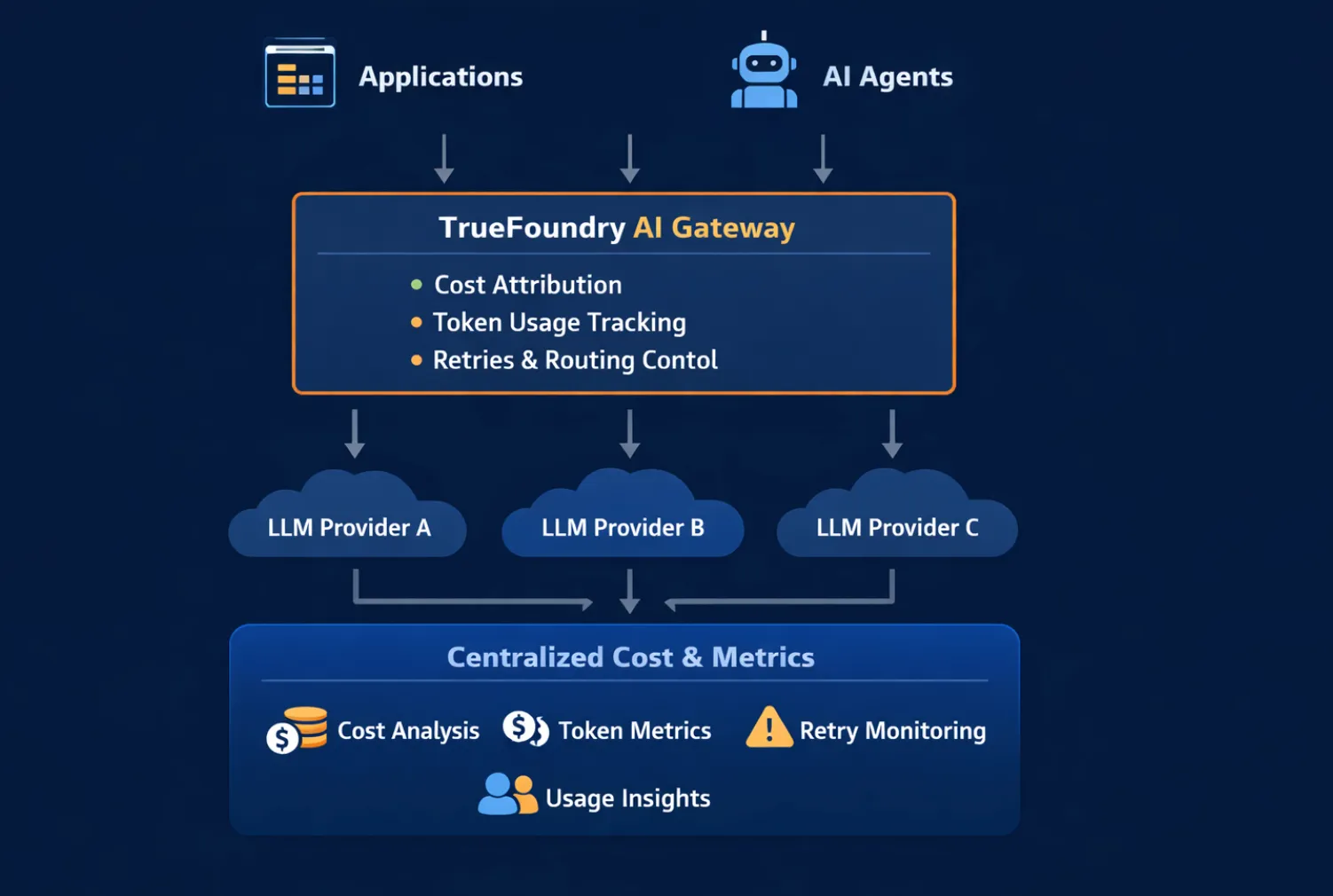
La observabilidad de costos de la IA funciona mejor cuando se implementa en punto de intercepción central, donde están visibles todas las solicitudes, decisiones de enrutamiento y reintentos. Esta es la razón por la que las pasarelas de IA desempeñan un papel fundamental.
Un Puerta de enlace de IA se encuentra entre las aplicaciones o los agentes y los proveedores de modelos. Como todas las solicitudes fluyen a través de ella, la pasarela puede:
Sin una puerta de enlace, los datos de costos se fragmentan en los SDK, los servicios y los paneles de proveedores. Con una puerta de enlace, el costo se convierte en una señal de primera clase que se puede analizar y actuar en consecuencia antes de que los gastos aumenten.
En TrueFoundry, el Puerta de enlace de IA proporciona este punto de control centralizado, lo que permite observar y gestionar los costes de la IA en todos los modelos, agentes y flujos de trabajo de forma unificada.
Los sistemas basados en agentes amplifican tanto la potencia como el coste de las cargas de trabajo de IA. A diferencia de las aplicaciones de una sola solicitud, los agentes ejecutan flujos de trabajo de varios pasos que pueden implicar la planificación, el razonamiento, los reintentos y el uso de herramientas. Esto hace que el comportamiento de los costos sea más difícil de predecir y más importante de monitorear de cerca.
La ejecución de un solo agente puede incluir:
Sin una observabilidad adecuada, estas interacciones pueden multiplicar silenciosamente los costos. Los bucles entre agentes, las solicitudes mal restringidas o el uso excesivo de herramientas suelen pasar desapercibidos hasta que el gasto total aumenta de forma significativa.
La observabilidad de los costos de la IA para los agentes requiere visibilidad en el nivel de ejecución del agente, no solo a nivel de llamada modelo. Los equipos deben entender:
Aquí es donde una arquitectura basada en pasarelas adquiere un valor especial. Al capturar las solicitudes de los agentes en la puerta de enlace, los equipos pueden atribuir los costos a lo largo de todo el ciclo de vida de un agente, en lugar de tratar cada llamada modelo de forma aislada.
En TrueFoundry, las implementaciones de agentes se integran con AI Gateway, lo que permite a los equipos observar los costos en todos los pasos y flujos de trabajo de los agentes. Esto permite a los equipos de plataformas y aplicaciones detectar anticipadamente el comportamiento ineficiente de los agentes y aplicar restricciones antes de que los costos se disparen.
.svg)
En True Foundry, La observabilidad de costos de la IA se implementa directamente en el Puerta de enlace de IA y capa de ejecución de agentes, donde están visibles todas las solicitudes del modelo, las decisiones de enrutamiento y los reintentos. Esto proporciona una visión unificada y uniforme de los costos en todos los modelos, solicitudes, agentes y flujos de trabajo.
Como cada solicitud fluye a través de la puerta de enlace, TrueFoundry puede:
Este enfoque centralizado convierte el costo de una métrica pasiva en una señal operativa. Los equipos pueden establecer alertas sobre los gastos anormales, hacer cumplir los presupuestos a nivel de enrutamiento y tomar decisiones teniendo en cuenta los costos a la hora de elegir modelos o estrategias alternativas.
Para los equipos que ejecutan cargas de trabajo de IA de producción, esto garantiza que el costo se mantenga predecible, explicable y controlable, incluso a medida que los sistemas aumentan en complejidad con más agentes, modelos y flujos de trabajo.
Los costos de la IA se vuelven difíciles de administrar tan pronto como las aplicaciones de LLM pasan a la producción. Los costos ya no dependen de un único modelo de llamada, sino de una combinación de indicaciones, decisiones de enrutamiento, reintentos, agentes y uso de herramientas. Sin una visibilidad adecuada, los equipos suelen descubrir los problemas relacionados con los costes solo después de que los gastos ya hayan aumentado.
La observabilidad de costos de la IA aborda este problema al convertir el costo en una señal de primera clase. Al atribuir el gasto entre las solicitudes, los modelos, las solicitudes, los agentes y los flujos de trabajo, los equipos pueden comprender no solo cuánto gastan, sino también por qué. Este nivel de conocimiento es esencial para operar los sistemas de IA de manera confiable y a escala.
Las arquitecturas basadas en pasarelas desempeñan un papel fundamental a la hora de permitir esta visibilidad. Al capturar las solicitudes en un único punto de control, los equipos pueden observar, analizar y controlar el gasto en inteligencia artificial de manera uniforme en todos los proveedores y rutas de ejecución. En TrueFoundry, este enfoque permite a los equipos de plataformas y aplicaciones detectar las ineficiencias de manera temprana, hacer cumplir los presupuestos y equilibrar los costos con el rendimiento a medida que aumentan las cargas de trabajo de IA.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


