

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En los sistemas de software tradicionales, los fallos suelen ser explícitos. Una función produce un error, un servicio se bloquea o una solicitud pierde el tiempo de espera. La depuración es en gran medida determinista. Los agentes de IA cambian radicalmente este modelo.
Los agentes no son deterministas por diseño. Razonan en función de los pasos intermedios, eligen las herramientas de forma dinámica y adaptan su comportamiento en tiempo de ejecución. Esta autonomía permite flujos de trabajo potentes, pero también introduce nuevos modos de fallo que son más difíciles de detectar y depurar.
Cuando un agente falla en la producción, rara vez se bloquea por completo. En su lugar, puede entrar en un bucle, seleccionar la herramienta equivocada o tomar una decisión incorrecta basándose en un contexto incompleto o obsoleto. Estas fallas suelen aparecer solo como una degradación de la calidad de salida, un aumento de la latencia o un costo inesperado, sin ninguna señal de error evidente.
Para los equipos que tienen agentes en producción, esto hace que la supervisión tradicional sea insuficiente. Observabilidad de los agentes es necesario para comprender cómo se comportan los agentes en tiempo de ejecución, identificar los modos de falla de manera temprana y operar estos sistemas de manera confiable a escala.
Si la observabilidad tradicional consiste en comprobar el pulso de un sistema, Agente de IA la observabilidad es más como leer su mente. En una aplicación estándar, rastreamos el flujo de datos a través de rutas de código fijas. Sin embargo, un agente no tiene una ruta fija. Construye su propia carretera a medida que corre. Esto significa que necesitamos un nuevo juego de lentes para ver lo que sucede debajo del capó.
Cierto observabilidad para los agentes va más allá del simple tiempo de actividad y se centra en cuatro pilares específicos: las trazas, las llamadas de herramientas, los pasos de decisión y los fallos.
Sin dejar rastro, es posible que veas que un agente gastó tres dólares y tardó veinte segundos en responder a una pregunta, pero no sabrías por qué. Un rastreo bien estructurado le permite repetición toda la sesión. Puede ver exactamente dónde empezó el agente, dónde se desvió y cómo llegó finalmente a una conclusión.
Las herramientas de monitoreo estándar se crearon para un mundo en el que el código es una serie de códigos predecibles, «si-esto-entonces aquello» declaraciones. En ese mundo, un error es una parada difícil y un éxito es una tarea terminada. Pero cuando se opta por agentes autónomos, los límites entre el éxito y el fracaso se vuelven borrosos. Puede tener un sistema técnicamente «en buen estado» según su panel de control y, al mismo tiempo, fallar a sus usuarios.
La observabilidad tradicional normalmente se basa en dos pilares principales: registros y métricas. Ambas se quedan cortas cuando se aplican a la naturaleza fluida de los flujos de trabajo de las agencias.
Los registros de aplicaciones sin procesar son excelentes para detectar un servidor bloqueado o el tiempo de espera de una base de datos. Sin embargo, un agente que sí pensando no produce necesariamente un registro de errores. Produce una corriente de razonamiento.
Escenario de ejemplo: Un agente tiene la tarea de encontrar un documento específico en una base de datos grande, pero se le proporciona una herramienta de búsqueda un poco ambigua. El agente puede entrar en un bucle recursivo, realizar una búsqueda, no encontrar el resultado y, a continuación, volver a buscar con una pequeña variación.
Desde una perspectiva de registro tradicional, cada una de esas llamadas a la API puede devolver un estado de 200 OK. Sus registros mostrarían miles de visitas exitosas, aunque el agente esté realmente atascado y agote su presupuesto. Sin el «por qué» detrás de las llamadas, los registros sin procesar son solo ruido.
Las métricas tradicionales se centran en indicadores de alto nivel como Uso de la CPU, memoria y latencia de solicitudes. Si bien siguen siendo importantes, son fundamentalmente ciego al contexto.
En una API estándar, un aumento en la latencia es casi siempre una mala señal. En un sistema de agencia, una latencia alta puede ser, de hecho, una señal de éxito.
Si un agente encuentra una consulta particularmente compleja y decide seguir cinco pasos de razonamiento adicionales para garantizar la precisión, el latencia aumentará, pero el calidad del resultado mejorará.
Por el contrario, una latencia baja podría significar que el agente se dio por vencido demasiado pronto o dio una respuesta superficial y alucinante. Si no hay una forma de correlacionar las métricas de rendimiento con la lógica interna del agente y su trayectoria de toma de decisiones, las cifras que aparecen en el panel de control pueden resultar engañosas. Para entender realmente a un agente, debes tener en cuenta el «margen de razonamiento» que vincula las métricas con el objetivo específico que el agente intentaba alcanzar.
Para gestionar los agentes de forma eficaz, debemos dejar de analizar el conjunto y empezar a analizar la secuencia. Como un agente es básicamente una serie de «bucles», las métricas que importan son las que describen el estado de cada bucle y cómo se conectan con el objetivo final.
Si desea ir más allá del tiempo de actividad básico, estas son las cuatro señales clave que su sistema de observabilidad debe priorizar.
En un flujo de trabajo de agencia, una sola solicitud de usuario puede activar cinco o seis pasos de razonamiento interno. Un seguimiento a nivel escalonado captura la pensamiento el modelo tenía en cada etapa. Esto incluye el mensaje específico enviado al LLM, el resultado sin procesar y, lo que es más importante, los metadatos, como el uso de los tokens y las puntuaciones de probabilidad.
Al observar el linaje de estos pasos, puede determinar dónde comienza a desviarse la lógica.
Por ejemplo, si a un agente se le asigna la tarea de generar un informe, pero se queda atascado en el paso tres al intentar volver a formatear una tabla repetidamente, el seguimiento a nivel de paso hace lo siguiente: fricción lógica inmediatamente visible. Sin esto, solo verás una solicitud de larga duración que, con el tiempo, se agota.
Los agentes son tan rápidos como las herramientas que utilizan. Cuando un agente llama a una base de datos o a una API de búsqueda, el tiempo de respuesta de esa herramienta se suma al tiempo total de ejecución del agente. Las herramientas de observabilidad deben realizar un seguimiento de la latencia de la herramienta como una métrica distinta.
Si un agente tarda 30 segundos en responder, debes saber si la demora se debió a la «mentalidad» del LLM o a una API de terceros lenta.
La latencia de las herramientas de supervisión le permite establecer acuerdos de nivel de servicio específicos para sus integraciones externas. Si una herramienta de búsqueda concreta añade constantemente 10 segundos de retraso, puedes optar por cambiarla por una base de datos vectorial más rápida u optimizar la consulta subyacente de la herramienta.
En sistemas complejos, un pequeño error en una etapa inicial puede convertirse en una falla total al final. Esto se conoce como propagación de errores. Por ejemplo, si un Recuperación de datos La herramienta devuelve un objeto JSON con formato incorrecto, por lo que el agente podría intentar «razonar» a partir de esos datos incorrectos en el siguiente paso, lo que llevaría a una respuesta final alucinante.
La observabilidad para los agentes significa rastrear cómo se produce un error en el lapso el nivel afecta al resto de la traza. Debe ver el momento exacto en que una herramienta devolvió un error y el modo en que el agente intentó recuperarse. ¿Se ha vuelto a intentar? ¿Se degradó con gracia? ¿O continuó a ciegas con un contexto corrupto?
A diferencia de un chatbot estándar, en el que una solicitud tiene un costo relativamente fijo, el costo de un agente es muy variable. Una ejecución puede costar cinco céntimos, mientras que la siguiente, provocada por el mismo mensaje, pero que requiere más pasos de razonamiento, puede costar dos dólares.
Rastreo «coste por ejecución» es la única forma de entender la economía unitaria de tu función de IA. Esta métrica agrega los tokens utilizados en cada modelo de llamada y los costos de cada invocación de herramientas en una sola sesión.
Al correlacionar este costo con la satisfacción del usuario o el éxito de la tarea, puede identificar «alto costo, bajo valor» modela y optimiza tu lógica de orquestación para que sea más eficiente.
La depuración de los agentes en la capa de aplicación se vuelve rápidamente poco práctica a medida que los flujos de trabajo aumentan en complejidad. Las ejecuciones de los agentes suelen abarcar varios modelos, herramientas y servicios, lo que produce una telemetría fragmentada.
Una puerta de enlace de IA proporciona una capa de observabilidad centralizada al situarse entre aplicaciones, modelos y herramientas. Como todas las interacciones pasan por la puerta de enlace, puede capturar una visión completa y coherente del comportamiento de los agentes.
Este enfoque convierte la observabilidad de un ejercicio de registro basado en el mejor esfuerzo en una capacidad estructurada para todo el sistema.
La puerta de enlace actúa como un punto de interceptación unificado para todas las interacciones de los agentes. Las solicitudes, las respuestas del modelo, las llamadas a las herramientas y los reintentos se capturan y normalizan en un formato uniforme.
Esto elimina la necesidad de correlacionar los registros de varios servicios o proveedores. Independientemente del modelo o la herramienta que utilice un agente, los datos de ejecución se recopilan de forma centralizada y se pueden analizar como un único flujo de trabajo.
Al inyectar identificadores de correlación en la capa de puerta de enlace, todos los eventos relacionados con la ejecución de un solo agente se pueden agrupar en un seguimiento jerárquico.
Esto permite a los equipos ver la ejecución de un agente como una secuencia estructurada de pasos, en lugar de solicitudes desconectadas. Los rastreos unificados permiten identificar qué modelo específico, llamada, invocación de herramienta o paso de razonamiento provocó una regresión en la calidad, la latencia o el costo.
Uno de los problemas más difíciles de la depuración de agentes es comprender la relación entre la intención del modelo y el comportamiento de la herramienta.
Como la puerta de enlace observa ambos lados de la interacción, puede correlacionar:
Esta visibilidad entre capas permite a los equipos determinar si las fallas se deben a una mala orientación, a limitaciones del modelo o a problemas relacionados con las herramientas, lo que permite realizar mejoras específicas.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

TrueFoundry traduce la complejidad del comportamiento de los agentes en una suite de observabilidad estructurada y lista para la producción. Al actuar como un plano de control central a través de su AI Gateway, permite a los equipos monitorear, analizar y depurar los agentes en diversos marcos, como CrewAI, Langroid, OpenAI Agents SDK y Strands Agents.
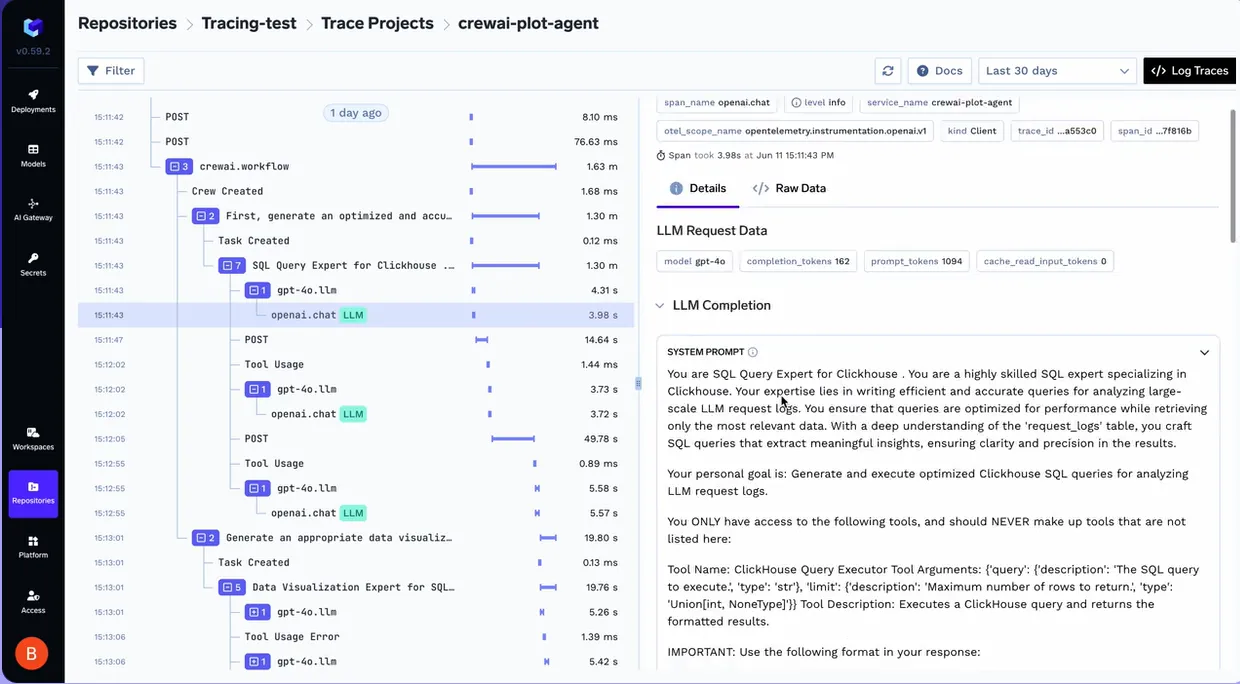
TrueFoundry proporciona una visibilidad de alta fidelidad de cada paso que da un agente. Al utilizar el SDK de Traceloop, la plataforma permite una correlación de trazas detallada en flujos de trabajo de agentes complejos. Esto va más allá del simple registro; permite ver la relación jerárquica entre la solicitud inicial de un usuario y la cadena subsiguiente de llamadas a modelos y ejecuciones de herramientas.
Para empezar a rastrear, solo tiene que inicializar el SDK en el código de la aplicación.
from traceloop.sdk import Traceloop
Traceloop.init(
api_endpoint="https://your-truefoundry-endpoint/api/tracing",
headers={
"Authorization": f"Bearer {your_pat_token}",
"TFY-Tracing-Project": "your_project"
}
)
TrueFoundry aborda el «misterio de la latencia» en los sistemas de agentes mediante el seguimiento de los datos de rendimiento granulares. El panel de control ofrece una visión completa de:
La gobernanza y la gestión de costos se integran directamente en el conjunto de la observabilidad. TrueFoundry proporciona desgloses detallados de tokens de entrada y salida, calcular automáticamente los costos por modelo en función de las tarifas actuales de los proveedores.
Los equipos pueden analizar Patrones de uso para identificar a sus usuarios más activos, ver cómo se distribuyen las solicitudes en los diferentes modelos y hacer un seguimiento del gasto por equipo en relación con las devoluciones de cargo internas. Con soporte integrado para Limitación de tarifas y controles presupuestarios, TrueFoundry garantiza que sus agentes se mantengan dentro de sus límites operativos, lo que evita el habitual escenario de «factura sorpresa» y, al mismo tiempo, mantiene la confiabilidad necesaria para la producción empresarial.
El funcionamiento de los agentes de IA en producción requiere pasar de la supervisión tradicional a la observabilidad profunda. Como los agentes razonan, actúan y se adaptan de forma dinámica, sus errores suelen ser más lógicos que técnicos.
Al centralizar la observabilidad en AI Gateway y proporcionar visibilidad a nivel de ejecución del razonamiento, las herramientas y los costos, los equipos pueden convertir el comportamiento opaco de los agentes en algo medible y manejable. Con la capacidad de observación adecuada, los agentes se convierten en componentes confiables de los sistemas de producción, en lugar de convertirse en cajas negras impredecibles.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


