

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En los últimos meses, hemos tenido la oportunidad de trabajar con un equipo reducido. Han desarrollado un modelo de aprendizaje profundo de última generación y han creado asociaciones para hacerlo llegar a más de 10 millones de usuarios con talento extremo.
La última pieza que faltaba en su historia de impacto era gestionar la ingeniería para lograrlo. El modelo requería una gran cantidad de cómputos y, dado que querían ofrecer este modelo a sus usuarios finales, necesitaban una infraestructura confiable y de alto rendimiento que pudieran administrar los dos (1 ingeniero de DevOps y 1 ingeniero de aprendizaje automático).
El modelo fue construido para procesar entradas de audio de diferentes tamaños. Como el modelo tenía un tiempo de procesamiento elevado (con un promedio de aproximadamente 5 segundos), necesitaba una inferencia asíncrona para cada solicitud a fin de procesar y responder a estas solicitudes.
El equipo ha creado su pila inicial para servir el modelo en Sagemaker. Sin embargo, cuando llevaron a cabo su primer proyecto piloto con este diseño, se dieron cuenta de que sería difícil ofrecer el modelo de forma fiable a la escala deseada con esta pila.
Incluso después de usar la configuración asíncrona, dado que las instancias tardaban en ampliarse (de 8 a 10 minutos por máquina), la experiencia del usuario final se vio comprometida al tener que soportar este retraso.
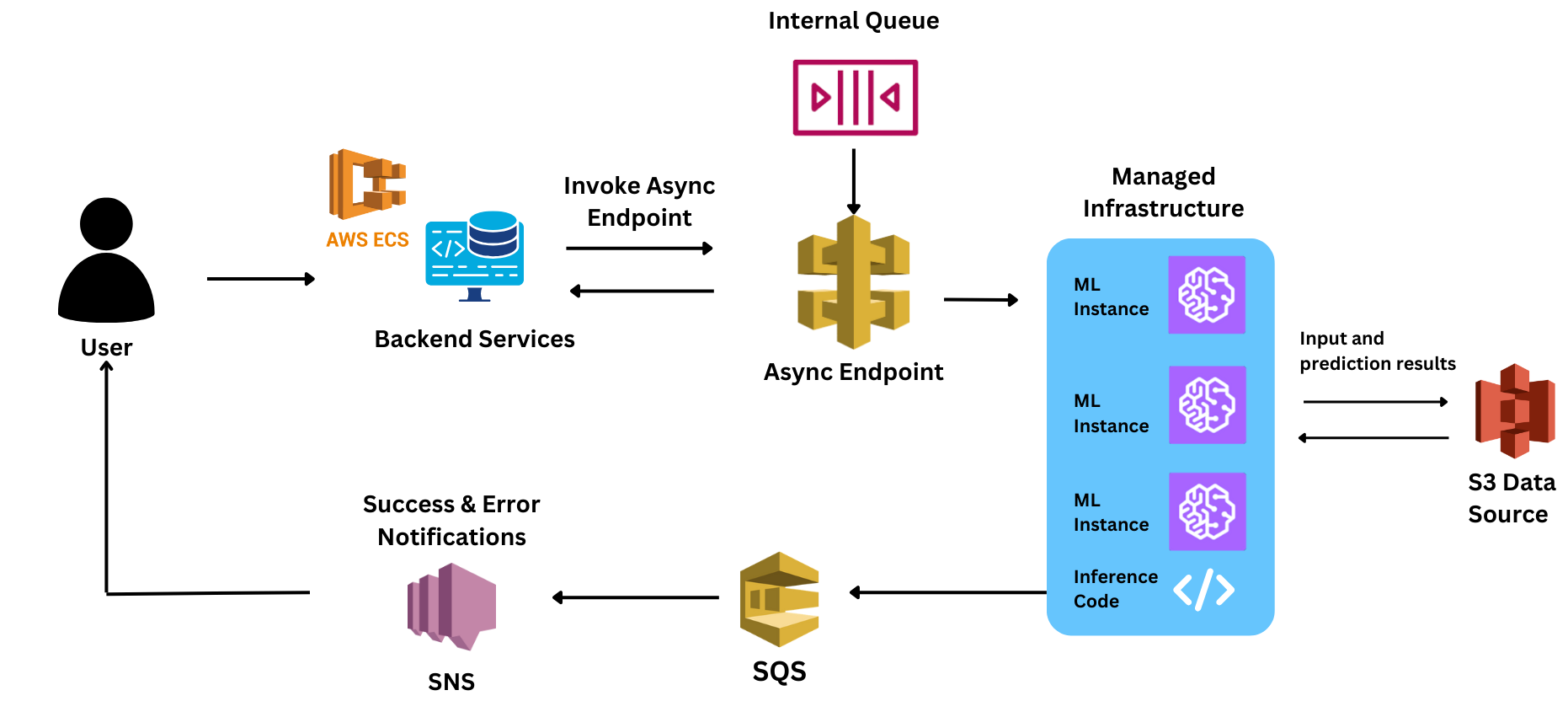
Sin embargo, durante la PoC, se enfrentaron a enormes retrasos en los tiempos de respuesta. Como muchos de los controles relacionados con SageMaker eran nuevos, perdieron un tiempo crucial para encontrar el motivo de los retrasos. Algunos de los desafíos a los que se enfrentaron fueron:
Tras la PoC, el equipo perdió la confianza en Sagemaker y decidió que necesitaban una solución que los dos (un ingeniero de ML y un ingeniero de DevOps) pudieran ofrecer a su público objetivo de más de 10 millones de usuarios.
Cuando empezamos a colaborar con el equipo, su piloto estaba a unos 7 días de distancia. Le aseguramos al equipo que podríamos ayudarlos a migrar toda la pila y a reconstruirla con los módulos de TrueFoundry en menos de 2 días para que tuvieran tiempo suficiente para realizar las pruebas antes de que el piloto tuviera que pasar a la fase de producción.
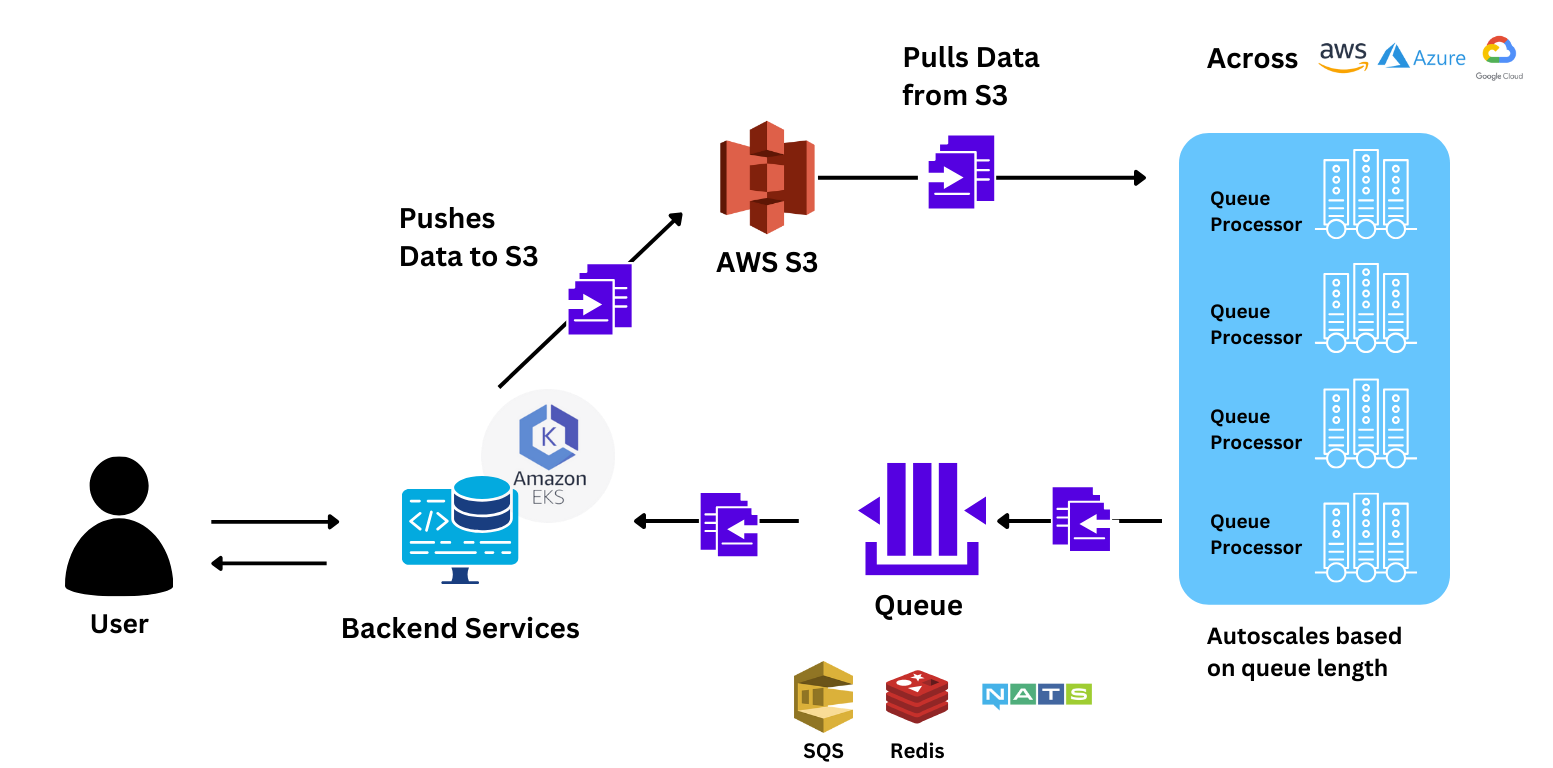
El equipo llevó a cabo los análisis comparativos enviando una ráfaga de 88 solicitudes al modelo para comparar el rendimiento con el de Sagemaker. TrueFoundry ampliado 78% más rápida que Sagemaker, lo que brinda al usuario respuestas mucho más rápidas. El el tiempo necesario para responder a la consulta de principio a fin fue un 40% más rápido con TrueFoundry.
El equipo simplemente pudo escalar la aplicación a más de 150 nodos de GPU porque:
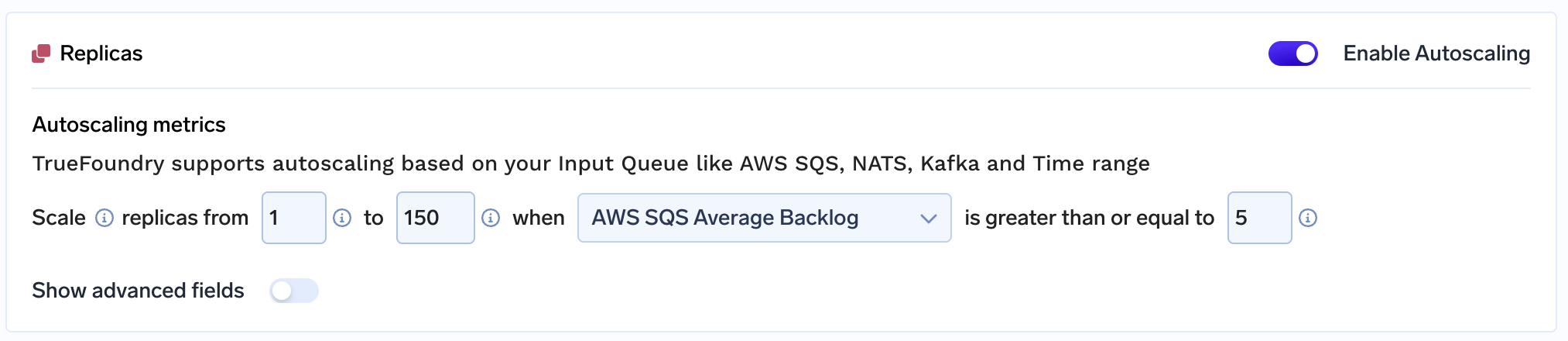

Uso True Foundry, el equipo de 2 miembros puede gestionar toda su carga de trabajo, ¡que a menudo se amplía a más de 150 nodos de GPU! por sí mismos. Mientras trabajaba con nosotros, lo más destacable para el equipo fue nuestra atención al cliente y los bajos tiempos de respuesta. ¡TrueFoundry invierte en el éxito de sus clientes y espera que todos nuestros clientes puedan crecer y crear un impacto a escalas similares a las de este proyecto!
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


