




July 20, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 8, 2026
Blazingly fast way to build, track and deploy your models!
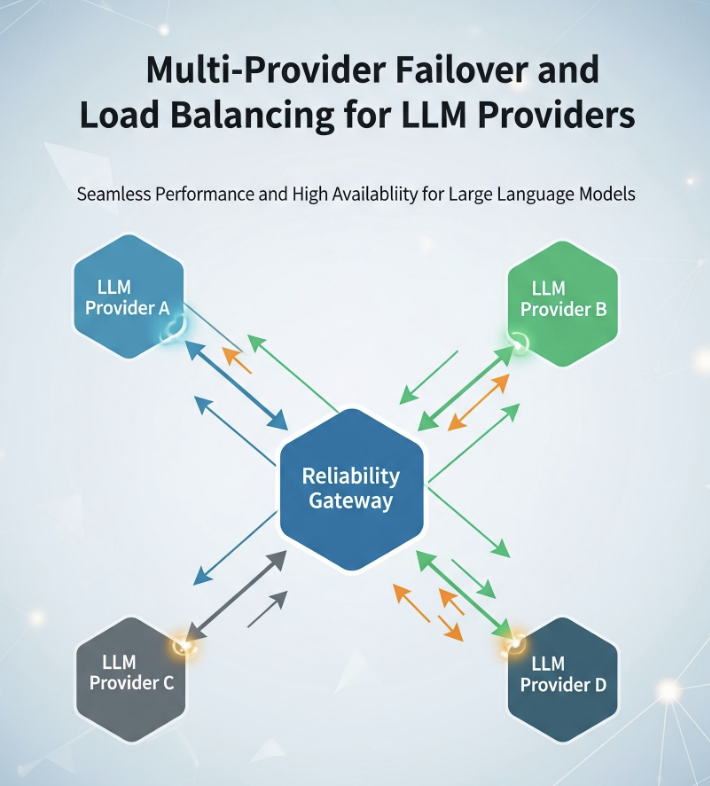
Every model provider has bad days — regional outages, rate-limit storms under load, latency that degrades without quite failing. If your application calls one provider directly, that provider's worst day is your worst day. This post is the reliability layer that prevents it: a taxonomy of how LLM calls fail, retries that don't make things worse, fallback chains across providers, health-aware load balancing, circuit breakers that fail fast, and the genuinely hard case of failing over mid-stream.
2:14 a.m. at Northwind. Nadia, an SRE, woke to a page: the customer-facing support agent was returning errors to every user. Not some users — every user. Northwind's own services were healthy; CPU, memory, and queues were all nominal. The errors were identical: 503 from the model provider. A regional incident on the provider's side had taken its inference endpoint down, and Northwind's agent called that endpoint directly. Every request hit the dead endpoint, failed, and returned an error to the customer. For forty minutes, until the provider recovered, there was nothing to do but wait — the agent had exactly one way to get a completion, and it was down.
The postmortem's action item wasn't "pick a more reliable provider." Every provider has incidents. It was "never depend on a single provider for a request that has to succeed." That is a gateway problem, and this post is how to solve it: retries that don't make things worse, fallback chains across providers, health-aware load balancing, and circuit breakers that fail fast instead of dragging your whole system down with the provider.
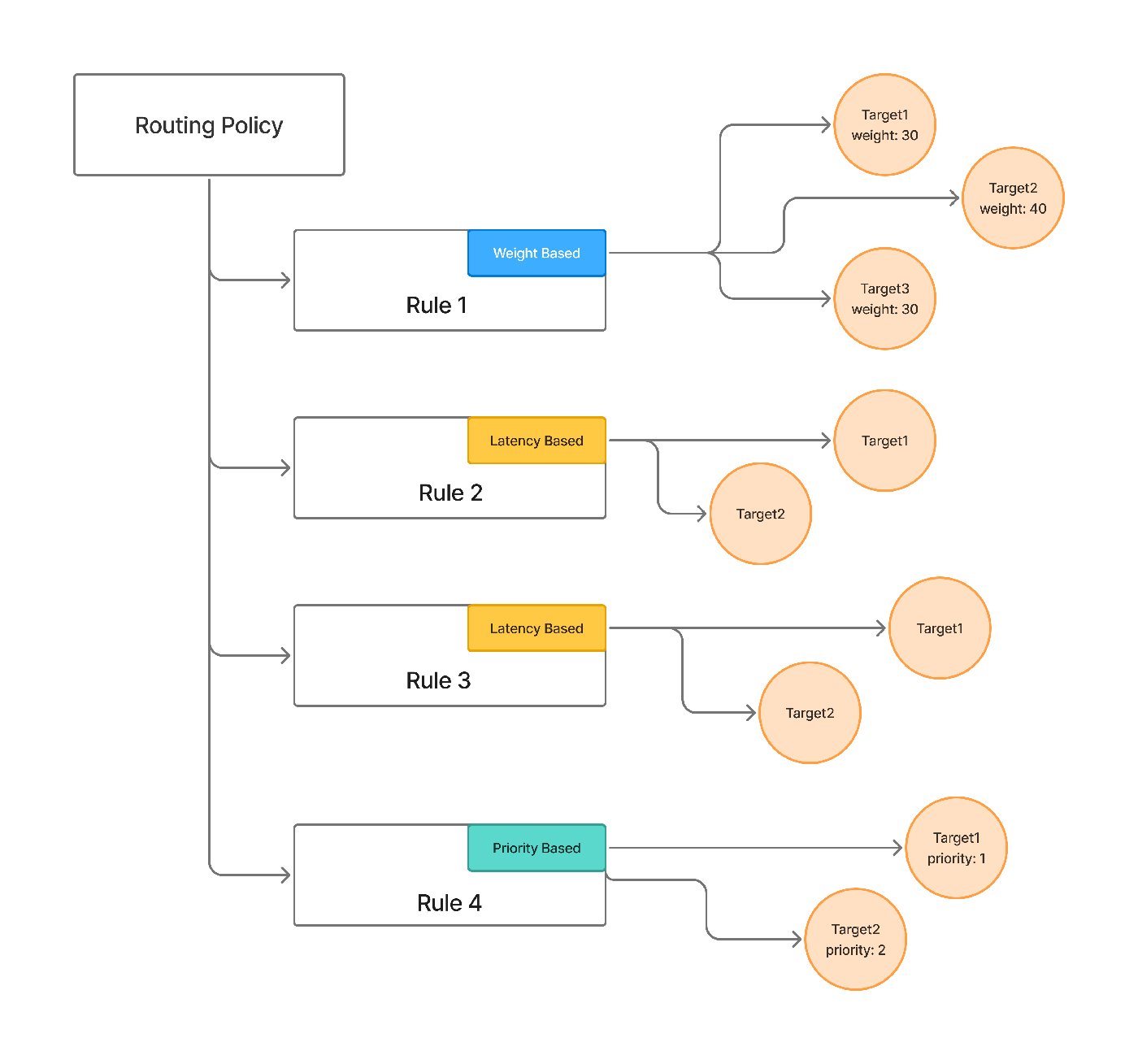
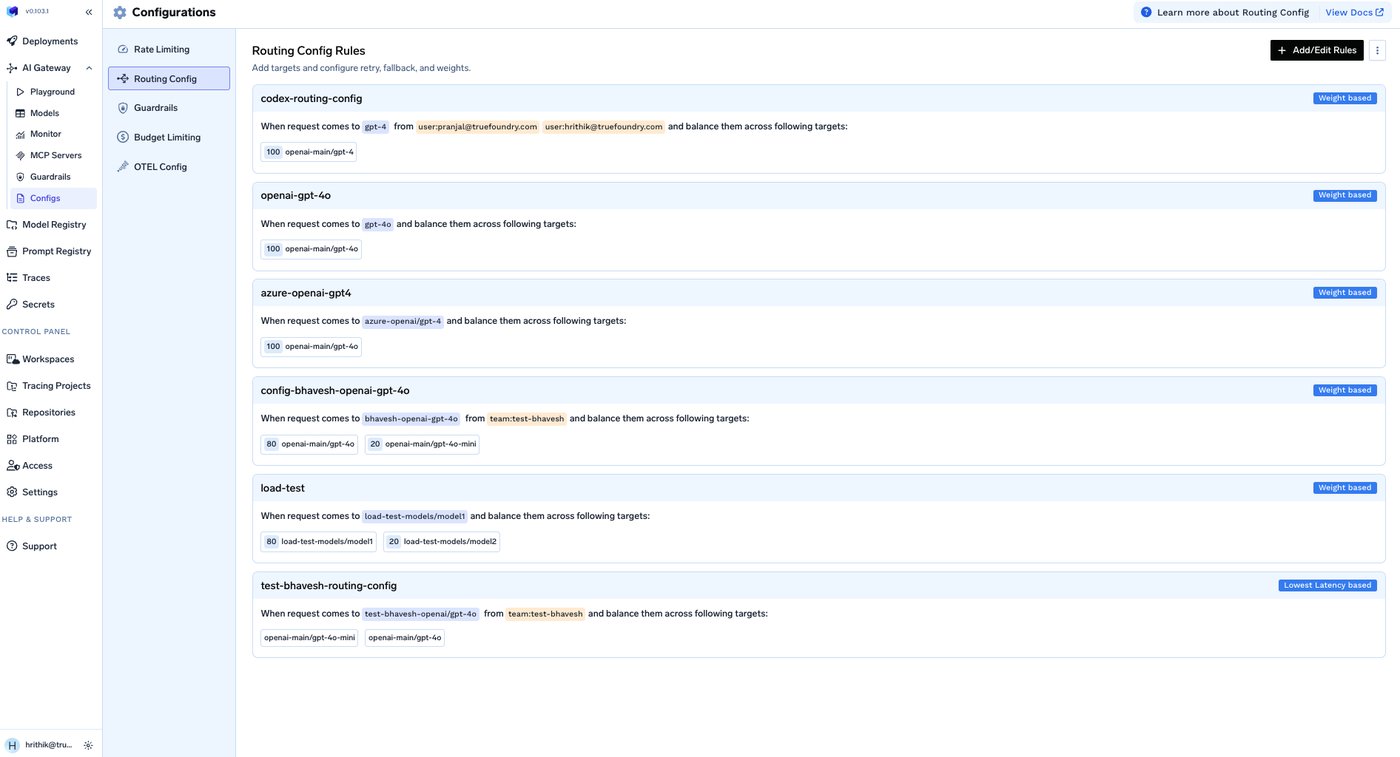
Everything in this post — retries, fallback chains, health-aware load balancing — is something TrueFoundry's AI Gateway expresses as configuration rather than per-service code. Its routing configuration defines load-balancing, fallback, and retry rules in YAML, evaluates them in order so the first matching rule wins, and applies them centrally to every request instead of being reimplemented in each app.
The pieces map onto the failure taxonomy below. Each target carries its own retry_config — attempts, delay, and the status codes worth retrying (429/500/502/503 by default) — and a separate fallback_status_codes list moves the request to the next target when retries won't help. Priority-based routing gives an ordered failover chain; latency-based routing favors the lowest-latency healthy target; and an unhealthy target is detected from its requests-, tokens-, and failures-per-minute and sidelined for a cooldown. The docs even cover the hard streaming case from section 8 — provider-specific stream-overload handling so a fall-through can happen before any user-visible tokens are emitted.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


