



.webp)
June 26, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 26, 2026

Blazingly fast way to build, track and deploy your models!
Cada requisição LLM que passa pelo TrueFoundry AI Gateway gera um rastreamento. Esse rastreamento captura a árvore completa de spans da requisição: o tratamento pelo gateway, a validação JWT, a resolução de autorização, o roteamento do provedor, a chamada do modelo de saída e a resposta transmitida. Esses rastreamentos são armazenados internamente para a interface do usuário do TrueFoundry Monitor. Mas eles também podem ser exportados através de protocolos OpenTelemetry padrão para backends de observabilidade externos. Arize é um desses backends.
Esta publicação detalha como a exportação de rastreamentos funciona no nível da arquitetura: quais primitivas OTEL estão envolvidas, como o gateway emite rastreamentos sem adicionar latência ao caminho da requisição e o que o Arize faz com os dados de rastreamento assim que chegam. Também aborda a superfície de configuração e os controles de privacidade de dados que permitem remover o conteúdo do prompt antes que ele saia da sua infraestrutura.
OpenTelemetry define um formato de comunicação neutro em relação ao fornecedor para rastreamentos distribuídos. Um rastreamento é uma árvore de spans conectados por relações pai-filho. Cada span representa uma unidade de trabalho discreta: um manipulador HTTP, uma chamada LLM ou uma invocação de ferramenta. Spans carregam atributos de chave-valor tipados que codificam o contexto operacional, como latência, códigos de status e contagens de tokens.
As convenções semânticas padrão do OTEL cobrem bem os sistemas distribuídos de uso geral, mas não foram projetadas para cargas de trabalho de LLM. Chamadas LLM carregam entradas estruturadas (arrays de mensagens de múltiplas voltas com prompts de sistema, definições de ferramentas e conteúdo multimodal) e saídas estruturadas (conclusões com motivos de término e chamadas de função). A economia de tokens são métricas operacionais de primeira classe: tokens de prompt, tokens de conclusão, tokens em cache e tokens de raciocínio, todos precisam ser rastreados por span. Um único input.value atributo de string é insuficiente.
É aqui que entram as convenções semânticas específicas para LLM. Arize mantém a especificação OpenInference, que define um esquema de atributos concreto e uma taxonomia de tipos de span sobre os spans OTEL. Cada rastreamento OpenInference é um rastreamento OTLP válido. As convenções dão aos nomes dos atributos seu significado específico de IA. Tipos de span como LLM e CHAIN e RETRIEVER e TOOL e EMBEDDING classificam as operações para que as plataformas de observabilidade possam renderizar rastreamentos com visualizações e agregações conscientes de IA.
TrueFoundry AI Gateway emite rastreamentos usando seu próprio namespace de atributos (tfy.input e tfy.output e tfy.input_short_hand juntamente com os atributos padrão gen_ai.* atributos para contagens de tokens e metadados do modelo e motivos de conclusão). Arize ingere-os como rastreamentos OTLP válidos e mapeia os atributos para sua interface de usuário de rastreamento.
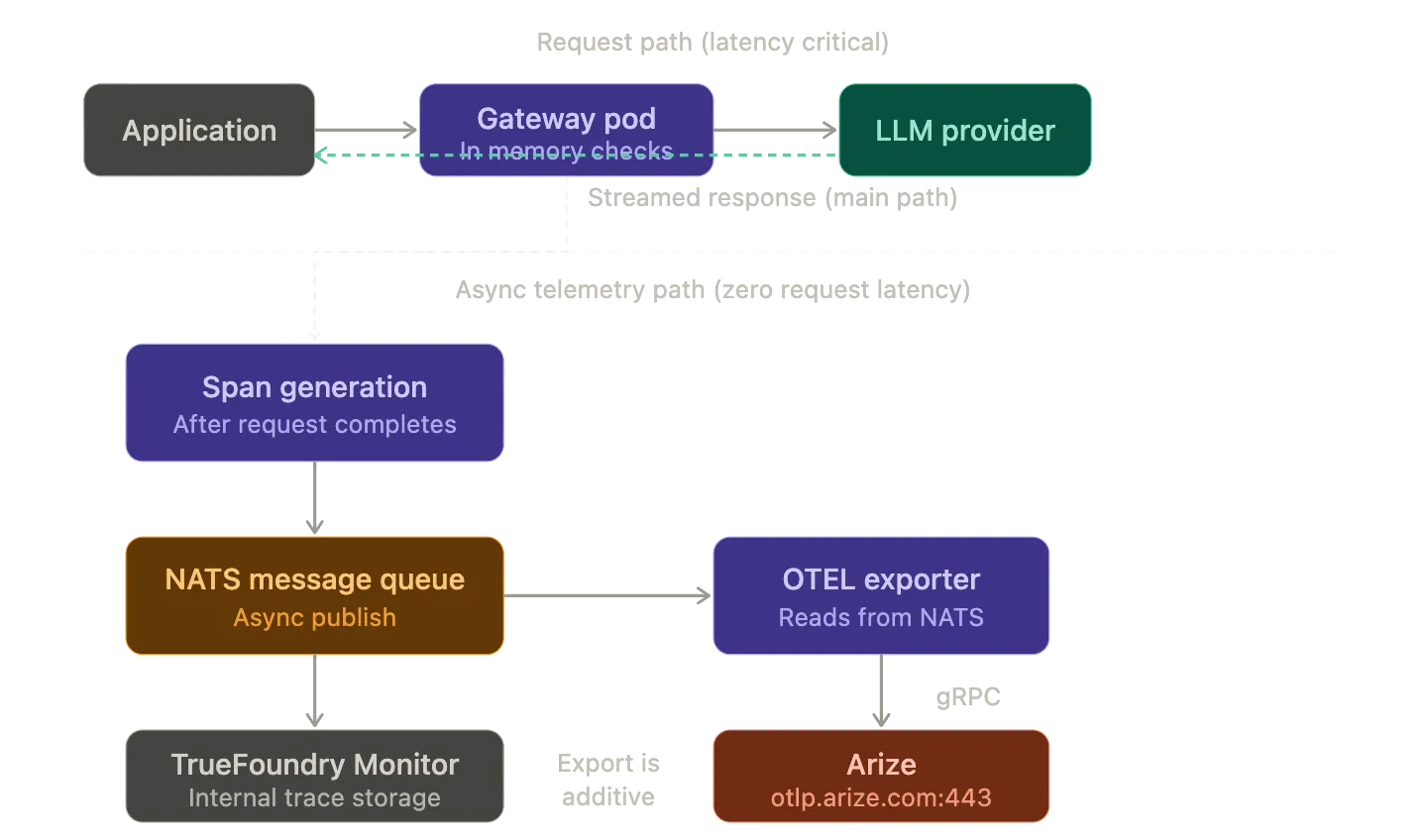
O TrueFoundry AI Gateway utiliza uma arquitetura dividida: um plano de controle que gerencia a configuração e um plano de gateway que processa as solicitações de inferência. O plano de gateway é construído sobre o framework Hono, que é um runtime HTTP otimizado para borda e ultrarrápido. Um único pod de gateway com 1 vCPU e 1 GB de RAM lida com mais de 250 solicitações por segundo com aproximadamente 3 ms de latência adicionada.
O princípio de design crítico é que não há chamadas externas no caminho da solicitação, exceto a chamada real do provedor LLM. Quando uma solicitação chega a um pod de gateway, o seguinte acontece inteiramente na memória:
A geração de rastreamento acontece assincronamente junto a este fluxo. O gateway cria spans OTEL para cada estágio do ciclo de vida da solicitação: o manipulador HTTP de entrada, a verificação de autenticação, a resolução do modelo, a chamada de provedor de saída e a resposta de streaming. Esses spans carregam atributos que capturam o uso de tokens, latência, nome do modelo, provedor, estimativa de custo e metadados da solicitação. Após a conclusão da solicitação, o gateway publica os dados de rastreamento em uma fila de mensagens NATS. Este é o mesmo barramento NATS que lida com a sincronização de configuração entre o plano de controle e os pods de gateway.
O exportador OTEL coleta os dados de rastreamento deste caminho assíncrono e os encaminha para o endpoint externo configurado. Como a exportação de rastreamento é desacoplada do caminho da solicitação, ela adiciona latência zero às solicitações de inferência. O gateway nunca falha uma solicitação, mesmo que o endpoint OTEL externo esteja inacessível.

Arize é uma plataforma de observabilidade e avaliação de IA construída especificamente para cargas de trabalho de LLM e agentes. Ela aceita rastreamentos OTEL via gRPC em otlp.arize.com:443 e oferece várias camadas de análise sobre os dados brutos de rastreamento.
Visualização de rastreamento. O Arize renderiza cascatas de rastreamento completas, mostrando a árvore de spans para cada solicitação. Você pode inspecionar spans individuais para ver o uso de tokens, o detalhamento da latência, o conteúdo de entrada e saída e os metadados do modelo. Para fluxos de trabalho de agentes, onde uma única solicitação do usuário aciona múltiplas chamadas de LLM e invocações de ferramentas, essa visualização em cascata torna o caminho de execução legível.
Análise de desempenho. O Arize calcula métricas agregadas em seu fluxo de rastreamento: distribuições de latência por modelo e por provedor, taxas de erro ao longo do tempo e tendências de throughput. Você pode configurar regras de alerta que disparam quando anomalias aparecem nessas distribuições. Isso é útil para detectar a degradação do provedor antes que ela afete os usuários finais.
Avaliação de LLM. Além do rastreamento bruto, o Arize suporta pipelines de avaliação automatizados. Você pode executar fluxos de trabalho de LLM como Juiz que pontuam as conclusões em dimensões como relevância, coerência e factualidade. Você também pode trazer fluxos de trabalho de anotação humana para uma avaliação de qualidade mais detalhada. Os rastreamentos fornecem os dados brutos (entradas, saídas e parâmetros do modelo) que alimentam esses ciclos de avaliação.
O principal diferencial é que o Arize entende a semântica específica de LLM nativamente. Ele analisa contagens de tokens, identificadores de modelo e conteúdo de prompt a partir de atributos de span e os exibe em visualizações criadas para esse fim, em vez de tratá-los como pares genéricos de chave-valor de string.
A integração é uma exportação gRPC direta do gateway para o Arize. Nenhum sidecar de coletor é necessário. Nenhum SDK personalizado está envolvido. Você configura o exportador OTEL no painel do TrueFoundry e os rastreamentos começam a fluir.
Você pode seguir os passos de integração aqui: https://www.truefoundry.com/docs/ai-gateway/arize
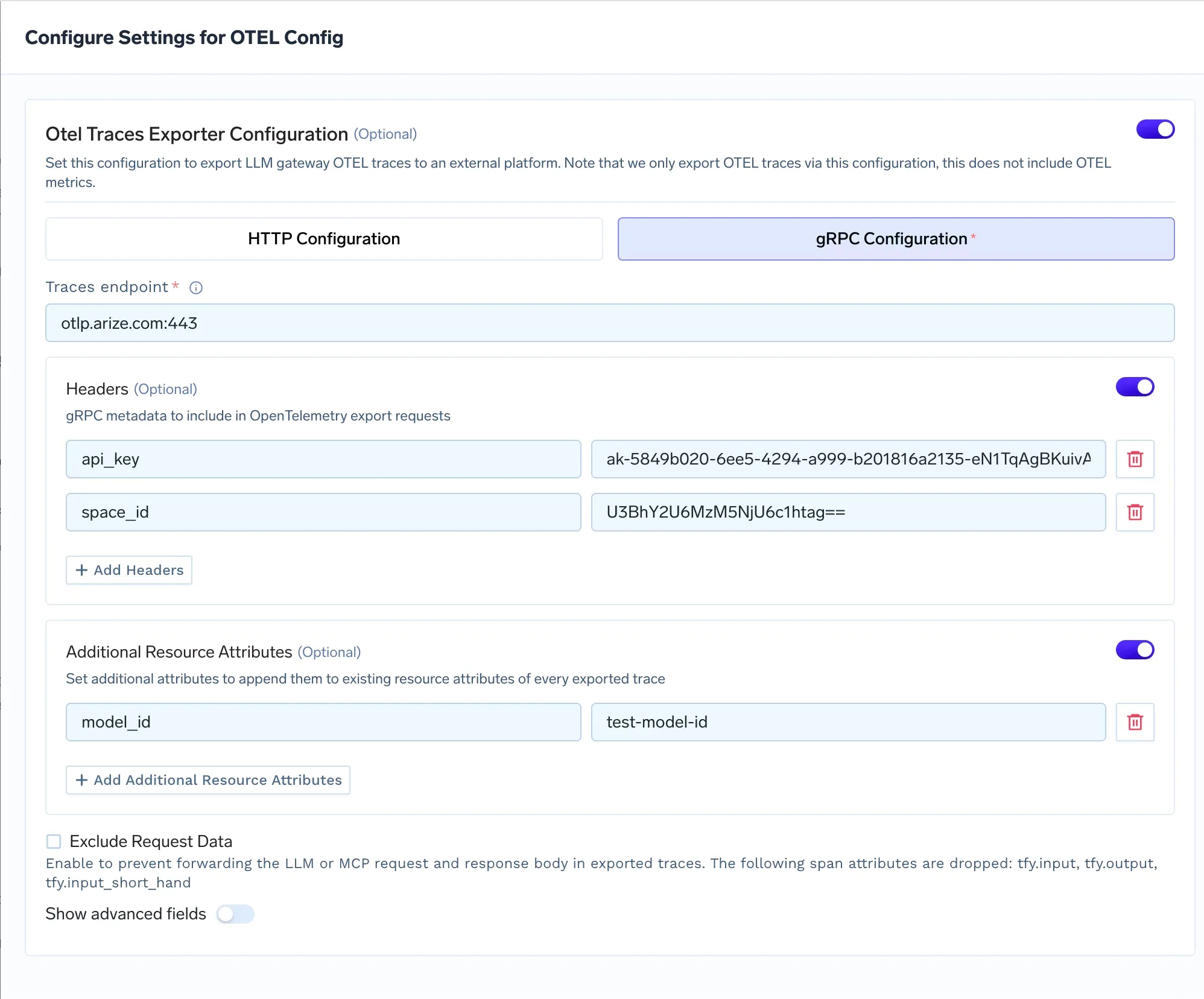
Você pode anexar atributos de recurso adicionais a cada rastreamento exportado. Estes são pares de chave-valor que são anexados no nível do rastreamento e são úteis para filtrar e agrupar no Arize.
O atributo mais comum a ser definido é model_id. O Arize usa isso para agrupar rastreamentos por modelo em suas visualizações de painel. Se você estiver roteando tráfego de produção através de um modelo LLama ajustado, você pode definir model_id para finetuned-llama-3-production. Você também pode adicionar model_version se você estiver executando implantações paralelas e quiser comparar o desempenho entre as versões no Arize.
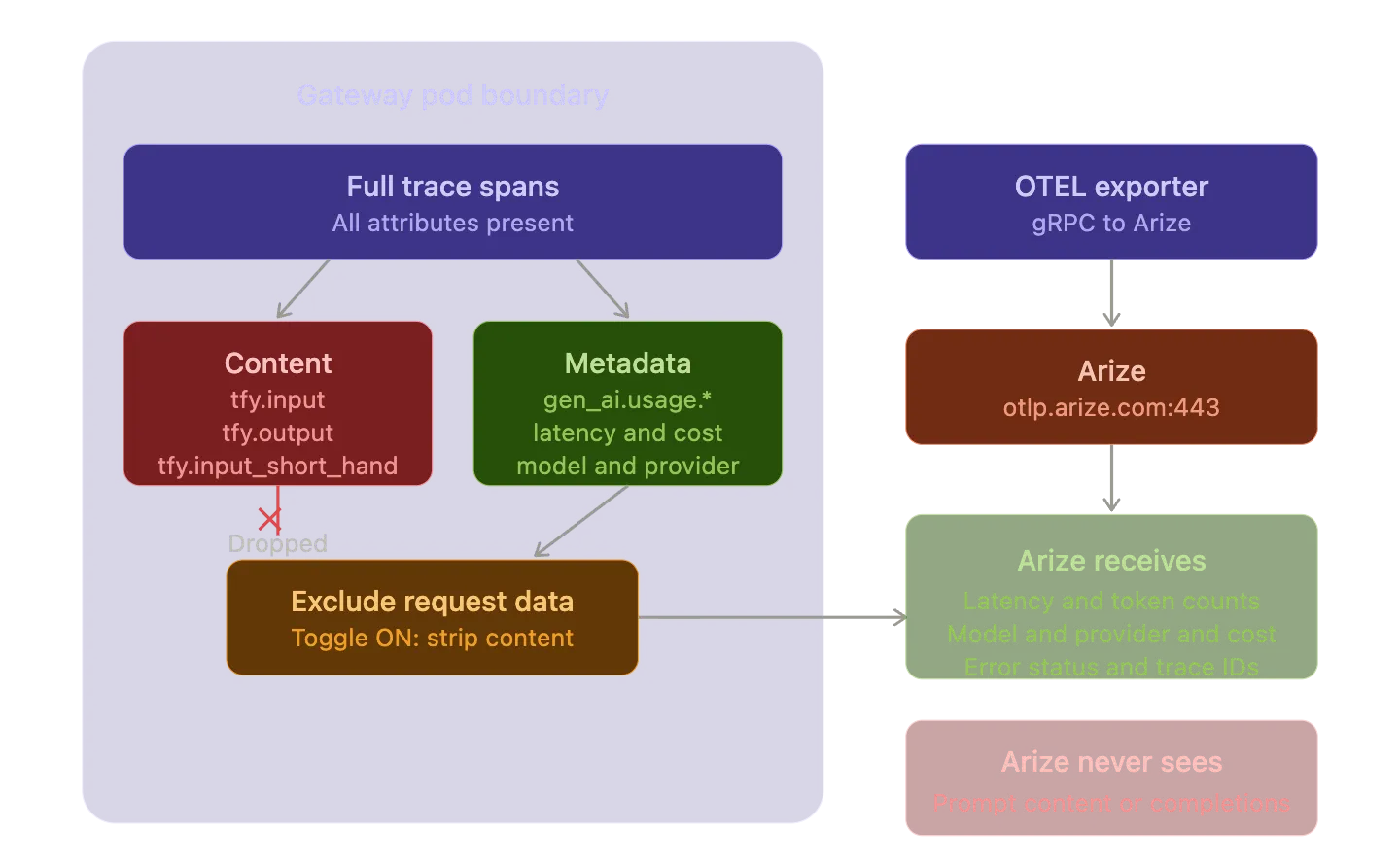
Existem cenários de implantação onde o conteúdo do prompt e o conteúdo da conclusão não devem sair da sua infraestrutura. Requisitos de conformidade podem proibir o envio de corpos de requisição para serviços de terceiros. PII em prompts pode tornar a exportação externa inviável.
A TrueFoundry lida com isso usando a opção 'Exclude Request Data' na configuração do exportador OTEL. Quando ativado, o gateway descarta três atributos de span antes da exportação: tfy.input e tfy.output e tfy.input_short_hand. O Arize ainda recebe os dados de rastreamento estruturais (latência, contagens de tokens, metadados do modelo e status de erro), mas nunca vê o conteúdo real dos prompts ou das conclusões.
Este é um detalhe arquitetônico importante. A filtragem ocorre no nível do gateway antes que os dados de rastreamento cheguem ao exportador gRPC. O conteúdo nunca sai do pod do gateway. Você obtém observabilidade total sobre desempenho, custo e confiabilidade sem expor conteúdo sensível a uma plataforma externa.
Após salvar a configuração OTEL, envie algumas requisições LLM através do gateway. Em seguida, abra o painel do Arize e navegue até 'Traces'. Procure por rastreamentos do tfy-llm-gateway serviço. Cada rastreamento deve mostrar a árvore de spans completa com os spans de tratamento do gateway e o span da chamada do provedor LLM de saída. Clique em spans individuais para verificar se o uso de tokens, a latência e os metadados do modelo estão preenchidos corretamente.
Se você configurou atributos de recurso, você deverá vê-los refletidos nos metadados do rastreamento. Use o model_id atributo para filtrar a lista de rastreamentos e verificar se os rastreamentos estão sendo agrupados corretamente por modelo.
O fluxo de dados é direto. Os aplicativos enviam solicitações LLM para o TrueFoundry AI Gateway. O gateway processa a solicitação em memória (autenticação e autorização, roteamento e limitação de taxa) e a encaminha para o provedor de modelo configurado. Em paralelo, o gateway gera spans OTEL para o ciclo de vida da solicitação e os publica assincronamente na fila de mensagens NATS. O exportador OTEL lê desta fila e envia rastreamentos via gRPC para otlp.arize.com:443. O Arize ingere os rastreamentos OTLP e os disponibiliza para visualização, análise e avaliação.
Nenhuma chamada externa é adicionada ao caminho de inferência. Nenhum sidecar de coletor precisa ser implantado. Nenhuma alteração no código do aplicativo é necessária. O gateway é o único ponto de instrumentação e a exportação OTEL é um complemento ao armazenamento interno de rastreamentos do próprio gateway. Você pode exportar para o Arize enquanto continua a usar a interface de monitoramento integrada do TrueFoundry para os mesmos dados de rastreamento.
Este é o padrão que torna o OTEL valioso como escolha de protocolo. O gateway emite rastreamentos OTLP padrão. O Arize aceita rastreamentos OTLP padrão. Se você decidir mudar de backend de observabilidade amanhã, você altera o endpoint e os cabeçalhos na configuração do gateway e aponta para um receptor OTLP diferente. O código do seu aplicativo, a configuração do seu gateway e a instrumentação de rastreamento permanecem exatamente os mesmos.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.




.webp)

.webp)
.webp)
.png)






.webp)
.webp)


