

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: May 29, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Il était une fois, il y a environ six mois, pendant les années de démarrage, Jason, un brillant ingénieur en machine learning au sein d'une société de technologie financière en pleine croissance. Jason était le « AI Whisperer » résident. Lorsque l'équipe produit a eu besoin de son nouveau chatbot alimenté par LLM pour paraître plus empathique mais moins sujet aux hallucinations à propos des taux d'intérêt, elle a appelé Jason.
La boîte à outils de Jason était vaste : des bases de données vectorielles de pointe, des clusters Kubernetes hautement optimisés et des pipelines CI/CD sophistiqués. Mais le cœur de l'opération, c'est-à-dire les raisons qui sous-tendent ces fonctionnalités de plusieurs millions de dollars, se situait dans un écosystème précaire.
Certaines instructions étaient codées en dur dans des chaînes f de Python, enfouies profondément dans la logique conditionnelle, comme d'anciens artefacts. D'autres existaient dans un document Google Doc partagé de 40 pages intitulé « Final_Prompts_V3_Real_Final (2) .docx », géré par trois chefs de produit différents. Les dernières instructions expérimentales étaient actuellement transmises à Jason par le PDG à 23 h 30.
Lorsqu'un client s'est plaint que le chatbot lui avait proposé de manière confuse un prêt hypothécaire en klingon, Jason n'a pas débogué le code. Jason a effectué une fouille archéologique dans l'histoire de Slack et s'est engagé à le découvrir. quelle version du « message d'empathie » était en cours de production et qui l'a modifié en dernier ?
Jason ne faisait plus d'ingénierie. Jason effectuait des travaux de conciergerie numérique. L'équipe avait construit un moteur Ferrari mais le dirigeait avec des bouts de ficelle lâches.
La douleur qui sous-tend l'histoire ci-dessus est en fait aiguë et universelle. Le passage de l'IA générative d'un prototype de hackathon à un système de production fiable révèle une lacune essentielle dans la pile MLOps traditionnelle.
Au début, traiter les instructions comme du code semblait logique. Vous les versionnez dans Git, vous les déployez avec l'application. Mais à mesure que les équipes évoluent, ce modèle s'effondre. Les instructions ne sont pas du code traditionnel ; elles regroupent la configuration, la logique métier et l'interface utilisateur dans un seul package en langage naturel.
Lorsque les instructions sont étroitement associées à des bases de code, plusieurs problèmes critiques apparaissent :
Pour franchir le fossé entre le prototype et la production, nous devons cesser de traiter les instructions comme des « chaînes magiques » disséminées dans notre infrastructure. Nous devons les traiter comme des citoyens de première classe.
Avant de mettre en œuvre une approche structurée, le flux de travail ressemble souvent à un enchevêtrement de problèmes de communication et d'efforts manuels.
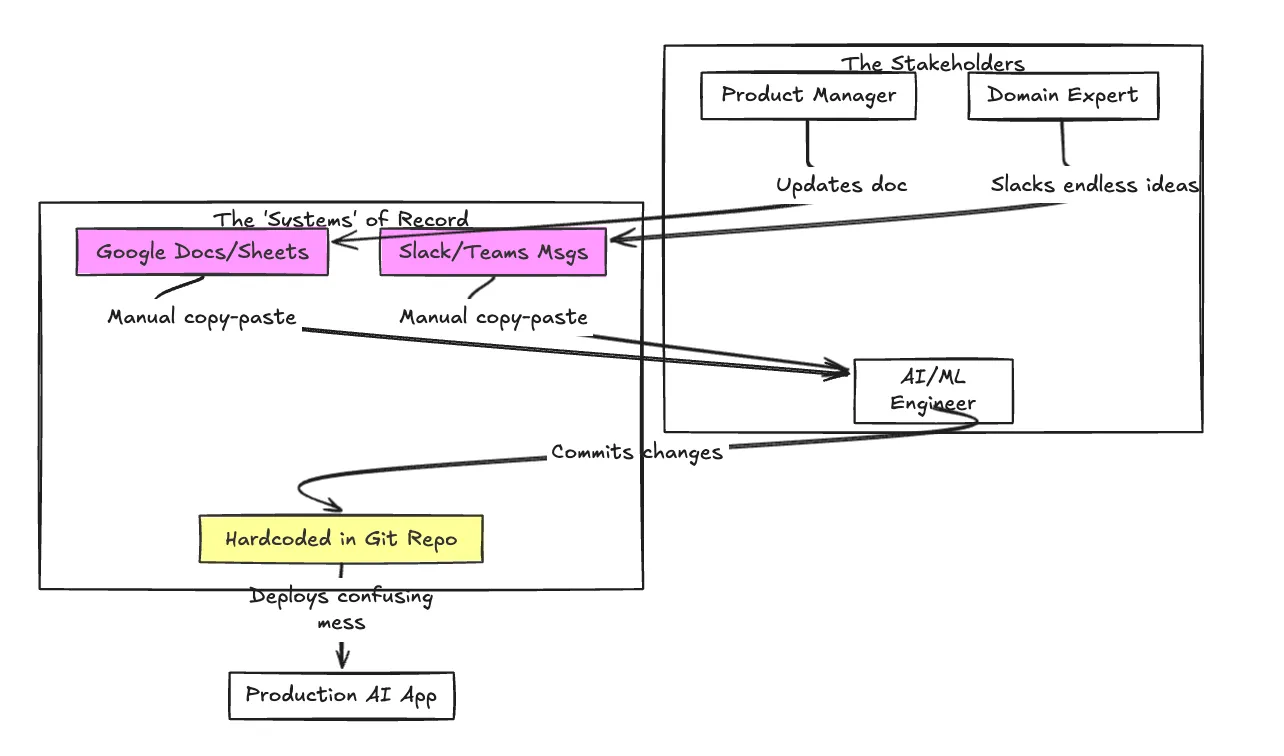
C'est là qu'un système de gestion rapide dédié devient essentiel. C'est le pont entre l'art expérimental de l'ingénierie rapide et la discipline rigoureuse du génie logiciel de production.
TrueFoundry fait office de système de contrôle central. Il est conçu pour dissocier la gestion des invites de la logique des applications, afin de permettre aux équipes de collaborer, de modifier, d'évaluer et de déployer les invites avec la même rigueur qu'au code traditionnel, mais avec des interfaces conçues pour les besoins spécifiques des flux de travail LLM.
TrueFoundry transforme la gestion rapide d'une tâche ad hoc en une couche d'infrastructure structurée et vérifiable.
TrueFoundry fournit un registre rapide centralisé. Plus besoin de chercher dans Google Docs ou dans des bases de code. Chaque invite, pour chaque cas d'utilisation, se trouve dans un emplacement sécurisé et accessible.
Il s'agit du changement de vitesse le plus significatif. Dans TrueFoundry, le code de votre application ne contient pas le texte d'invite. Au lieu de cela, il contient un appel SDK léger qui récupère la version active de l'invite souhaitée.
Cela signifie qu'un chef de produit peut effectuer une itération sur demande, la tester sur le terrain de jeu de TrueFoundry et la « promouvoir » en production sans qu'un ingénieur ait besoin de toucher au code de l'application ou de déclencher un redéploiement.
Avec TrueFoundry, le chaos se transforme en un cycle de vie rationalisé. Les parties prenantes collaborent au sein du hub, les versions sont suivies de manière rigoureuse et les applications utilisent les invites de manière fiable via une API, avec limitation de débit dans la passerelle AI garantir un comportement de production stable en cas d'utilisation intensive.
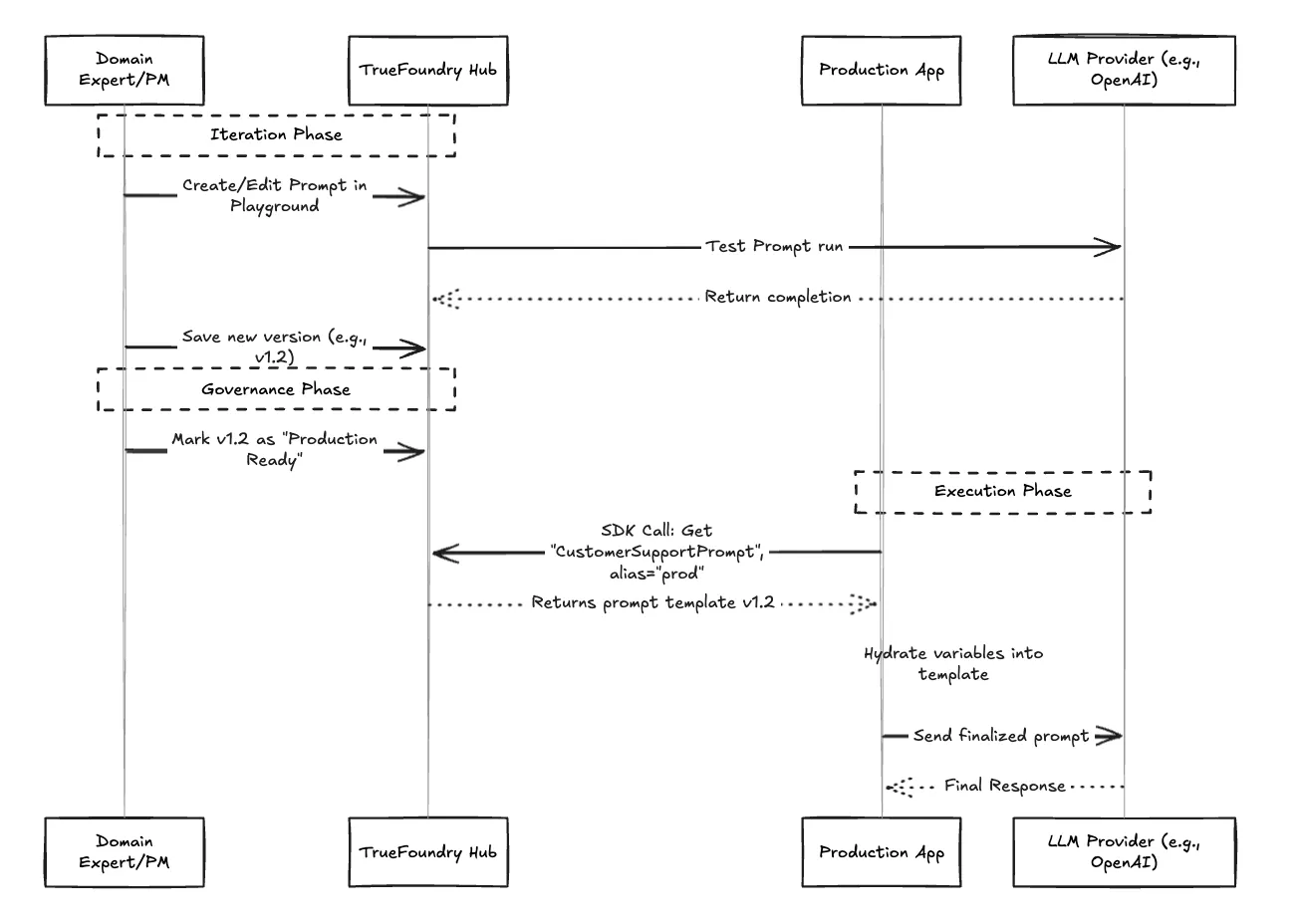
La gestion du texte rapide ne représente que la moitié de la bataille. Comment savoir si la version 2.0 est réellement meilleure que la version 1.5 ? TrueFoundry intègre l'évaluation à la gestion. Avant de promouvoir un prompt en production, vous pouvez l'exécuter par rapport à des ensembles de données dorés pour vous assurer que la précision, le ton et la sécurité n'ont pas régressé.
Pour plus d'informations, rendez-vous sur https://truefoundry.com/docs/ai-gateway/prompt-management
Pour en revenir à notre histoire, Jason a implémenté TrueFoundry. Les documents Google Docs ont été archivés. Les chaînes codées en dur ont été remplacées par des appels SDK.
Désormais, lorsque le PDG souhaite changer le ton du chatbot, il se connecte à TrueFoundry, rédige une nouvelle version, la teste par rapport à quelques exemples et étiquette Jason pour révision. Jason peut voir la différence exacte, exécuter une évaluation par rapport à celle-ci et approuver son déploiement en quelques minutes, le tout sans écrire une seule ligne de Python.
Le passage à l'IA de production nécessite de reconnaître que les invites constituent une nouvelle catégorie d'artefacts logiciels. Ils ont besoin de leur propre infrastructure dédiée. TrueFoundry fournit les outils nécessaires pour transformer l'art de l'ingénierie rapide en une discipline d'ingénierie gérable et évolutive, garantissant ainsi la robustesse de vos applications génératives d'IA au même titre que le reste de votre stack.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


