.webp)
June 5, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Mis à jour : September 11, 2025

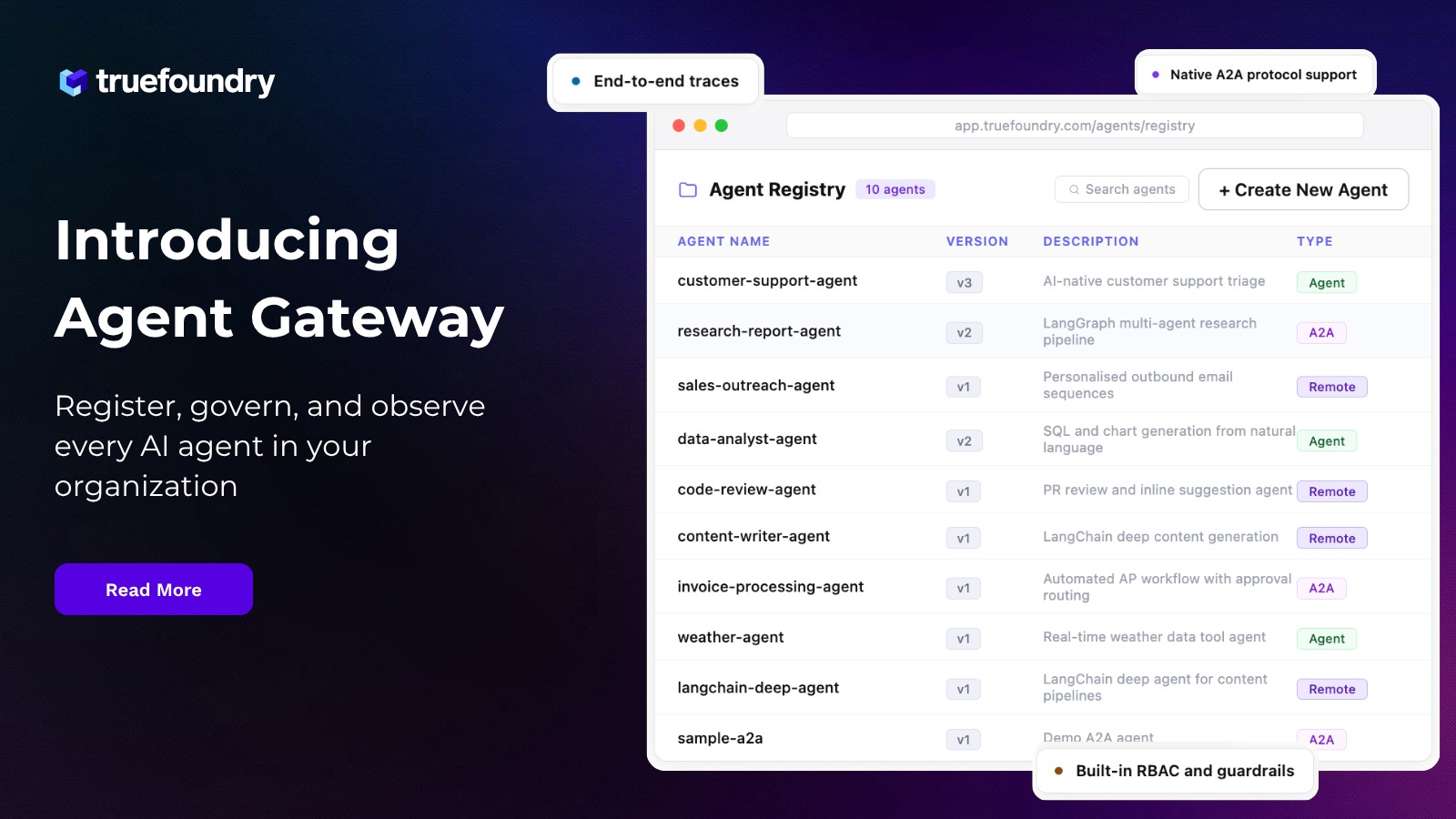
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les entreprises s'efforcent d'opérationnaliser l'IA, mais le trajet entre la validation de concept et la production se trouve souvent coincé entre deux extrêmes : performance brute et discipline opérationnelle. D'une part, vous avez besoin d'une infrastructure capable de gérer les exigences d'échelle et de latence des applications d'IA modernes. D'autre part, vous avez besoin de gouvernance, de sécurité et de contrôles des coûts pour assurer la viabilité de l'entreprise.
Le nouveau partenariat entre Systèmes cérébraux et True Foundry comble cette lacune. Ensemble, ils fournissent une plateforme permettant aux entreprises d'exécuter les modèles les plus avancés du monde à une vitesse sans précédent, tout en garantissant l'observabilité, la gouvernance et la flexibilité.
Cerebras s'est fait connaître pour avoir repoussé les limites du matériel d'IA et de l'inférence. Grâce à sa technologie Wafer Scale et Inférence cérébrale service, les entreprises obtiennent :
Pour les entreprises, cela signifie la capacité à enfin livrer produits d'IA à faible latence, des agents conversationnels à la synthèse en temps réel, sans être entravé par le matériel.
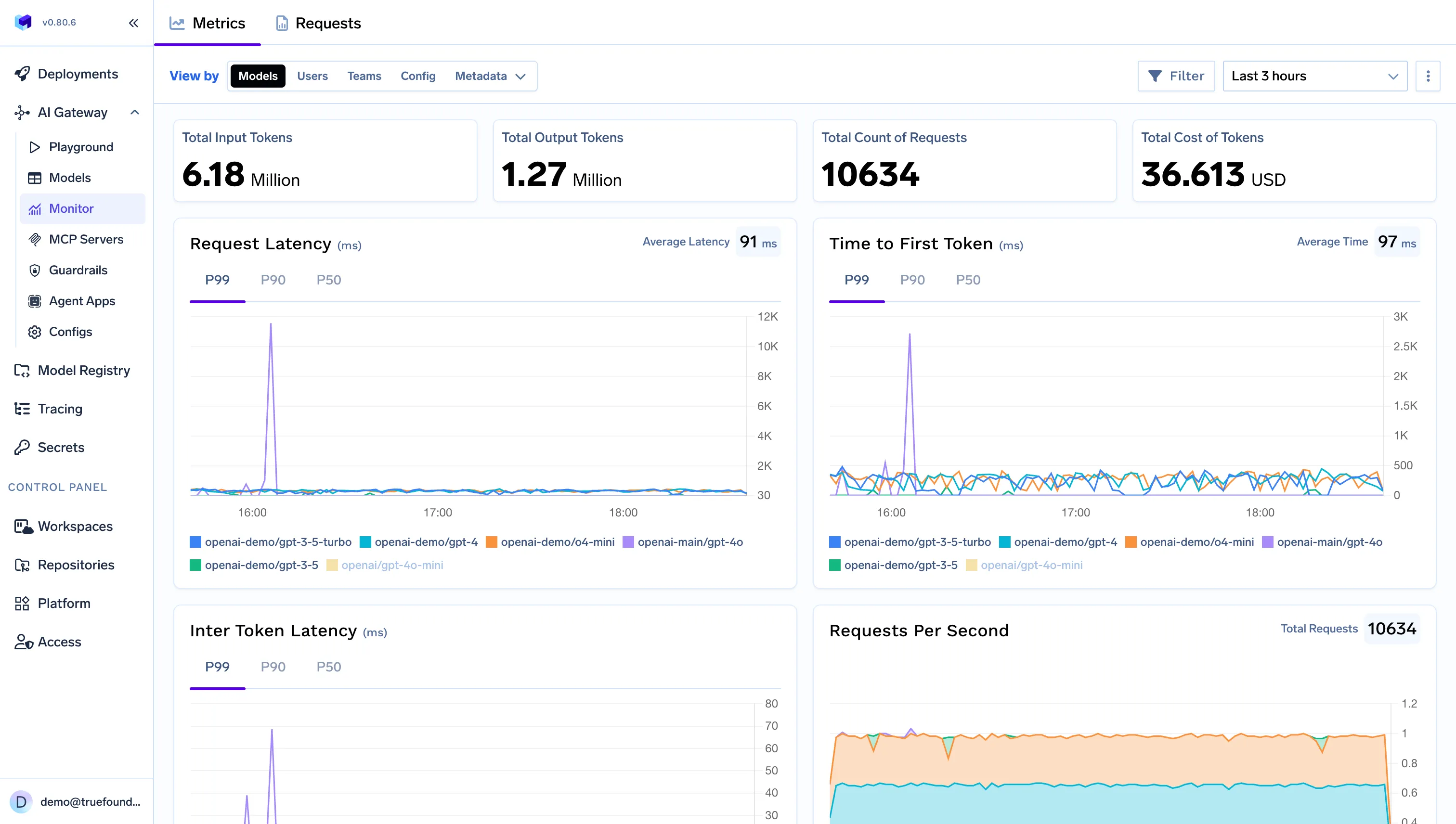
Pendant que Cerebras résout le performance problème, TrueFoundry résout le problème opérationnel un. C'est Passerelle IA fait office de plan de contrôle pour l'utilisation de l'IA en entreprise :
En bref, TrueFoundry permet aux entreprises d'étendre l'utilisation de l'IA de manière sûre, visible et prévisible.
L'association de Cerebras et TrueFoundry crée un solution complète pour le déploiement de l'IA en entreprise :
Ce partenariat marque un changement dans la façon dont les entreprises abordent l'IA. Il ne suffit plus d'exécuter des tests de performance dans des laboratoires ou de mener des projets pilotes au sein d'équipes isolées. Les entreprises ont besoin de :
Cerebras × TrueFoundry répond à ces trois critères.
Le partenariat Cerebras-TrueFoundry représente bien plus qu'une simple intégration, c'est un plan directeur pour prochaine phase de l'adoption de l'IA en entreprise. En combinant Les performances d'inférence sans précédent de Cerebras avec La passerelle IA de TrueFoundry pour la gouvernance et le contrôle, les entreprises peuvent enfin exécuter des charges de travail d'IA qui sont non seulement puissantes, mais également prêtes pour la production.
Pour les entreprises qui souhaitent intégrer l'IA à des prototypes et à des flux de travail critiques, cette collaboration permet de débloquer la pièce manquante : une plateforme rapide, gouvernée et pérenne.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.








Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception
© 2026 Tous droits réservés.



.webp)
.webp)
.webp)
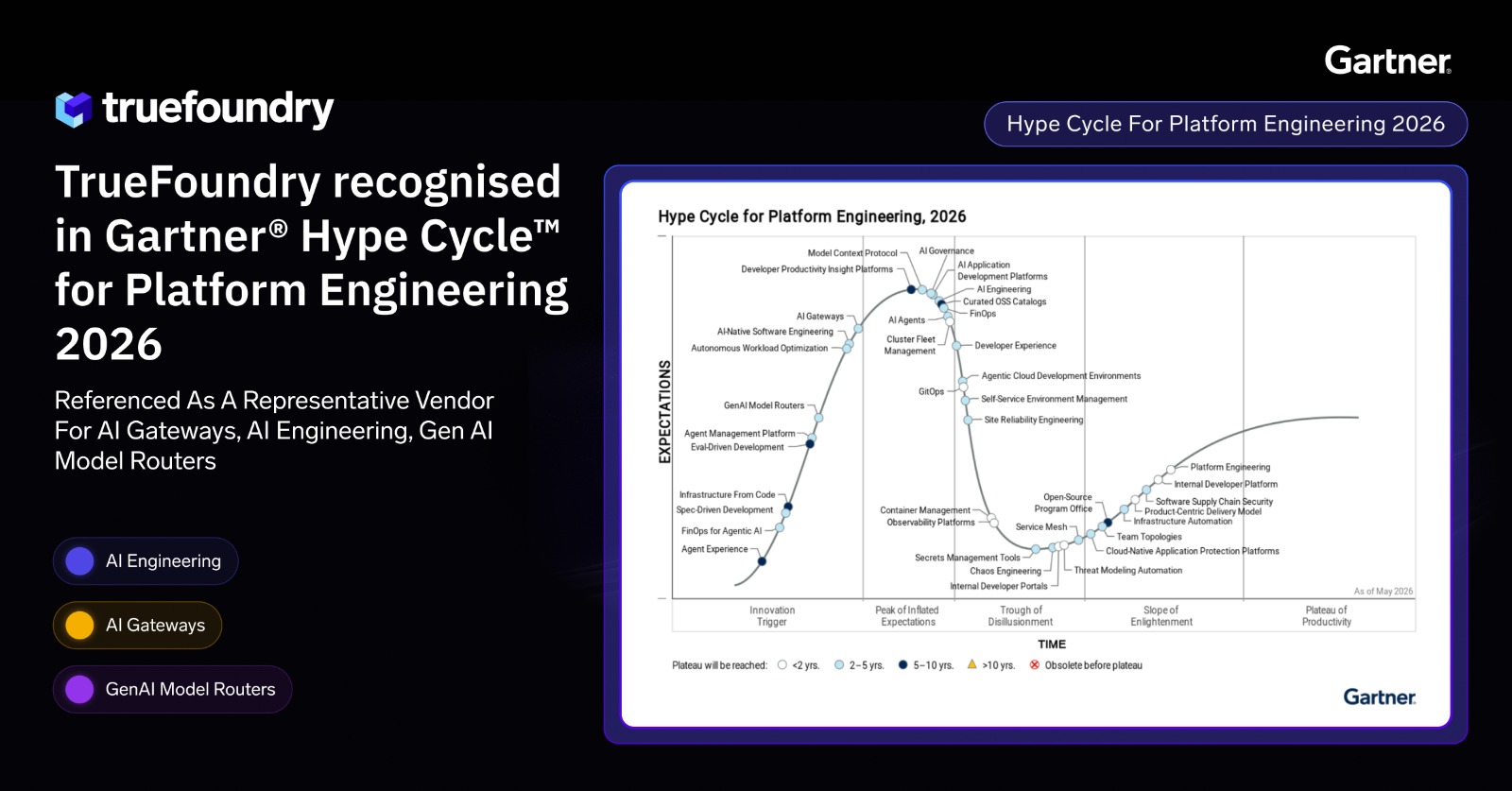
.webp)




.webp)
.webp)