

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Dans de nombreux cas, les équipes élaborent des instructions dans un manière détendue, comme si vous écriviez des e-mails informels. Il s'agit d'un processus naturel, auquel on n'accorde pas beaucoup d'importance éléments structuraux. Cette approche détendue convient aux développement exploratoire ou même développement rapide d'un prototype.
Mais lorsque l'on commence à utiliser une fonctionnalité basée sur un grand modèle de langage devant de vrais utilisateurs, les invites deviennent aspect critique. Si les instructions ne sont pas bien conçues, cela peut entraîner un échec et les réponses peuvent ne pas être cohérentes, des informations importantes peuvent ne pas être incluses et les réponses peuvent ne pas être fiables.
En plus de cela, le débogage est étonnamment complexe lorsqu'un problème survient. Il est souvent nécessaire de savoir si le problème est lié à le modèle, l'entrée ou même l'invite.
Cet article va passer en revue le processus exact que nous avons créé pour faire passer les instructions de « probablement assez bon » à « certainement assez bon pour la production » avec de vrais critères, de vrais ensembles de données d'évaluation et de véritables points de référence sur plusieurs modèles. Ce n'est pas magique. Juste une ingénierie structurée appliquée aux invites.
Lorsque la plupart des gens pensent à une invite, ils pensent à une simple demande, telle que « Résumer ce document » ou « Extraire des entités de ce texte ». Mais dans le monde réel, une invite est bien plus que cela. Il s'agit de l'interface fondamentale entre votre programme et le comportement du modèle. Une bonne invite créera le personnage du modèle, les règles d'engagement, le format de sortie et les imprévus.
Le problème, avec les invites, c'est qu'elles ne sont pas testées de manière approfondie. Ils sont conçus, mis en œuvre, puis simplement vérifiés pour voir s'ils fonctionnent. Vous apportez une modification ici et vous y ajoutez une règle. Alors tu espères juste que ça va bien se passer. Parfois, cela fonctionne. D'habitude, ce n'est pas le cas. Quand il échoue, il ne le fait tout simplement pas. Tu ne t'en rendras peut-être même pas compte.
Une bonne invite n'est pas seulement claire, elle est structurée. Considérez-le comme un contrat d'API entre vous et le modèle. Il doit définir :
Lorsque tous ces éléments sont en place, le modèle possède tout ce dont il a besoin pour être cohérent, fiable et prévisible entre les entrées et même entre les différentes versions du modèle.

Voici ce que nous avons constaté en ce qui concerne les instructions médiocres lors de déploiements dans le monde réel :
Des sorties qui semblent correctes mais qui ne le sont pas : Le modèle produit une réponse qui semble être dans le bon format, mais qui comporte des erreurs subtiles car la spécification n'était pas claire.
Défaillances intermodèles : L'invite fonctionne pour GPT-4 mais les réponses sont incohérentes pour les modèles Claude et OSS. Personne ne l'a testé sur tous les modèles avant le déploiement.
Régressions silencieuses : Changer un mot pour résoudre un problème entraîne trois autres problèmes que personne n'a remarqués avant que quelqu'un ne se plaint.
Le problème est toujours le même : personne n'a considéré l'invite comme quelque chose qui devait être testé et validé. Nous avons conçu ce processus pour résoudre ce problème.
Le flux de travail comporte cinq étapes. Chacune d'entre elles s'appuie sur la précédente. Si vous en sautez une, les résultats deviennent rapidement peu fiables. Voici comment cela fonctionne de bout en bout.
Donc, avant d'apporter des modifications, nous voulons savoir ce qui ne fonctionne pas. Nous utilisons un moteur d'évaluation structuré qui s'exécute sur chaque demande et la note selon cinq dimensions différentes et fournit un score de qualité global compris entre 0 et 100.
Nous n'utilisons pas de notation subjective. Nous avons des critères clairs pour toutes les dimensions. Nous sommes confrontés à de fortes contraintes. Par exemple, s'il n'y a aucune spécification de sortie dans l'invite, le score de spécification de sortie est maximal. Le score peut être élevé même si les instructions de l'invite sont bien écrites. Si le score est inférieur à 75, cela signifie qu'il n'est pas prêt pour la production. S'il est supérieur à 90, il est solide sur toutes les dimensions.
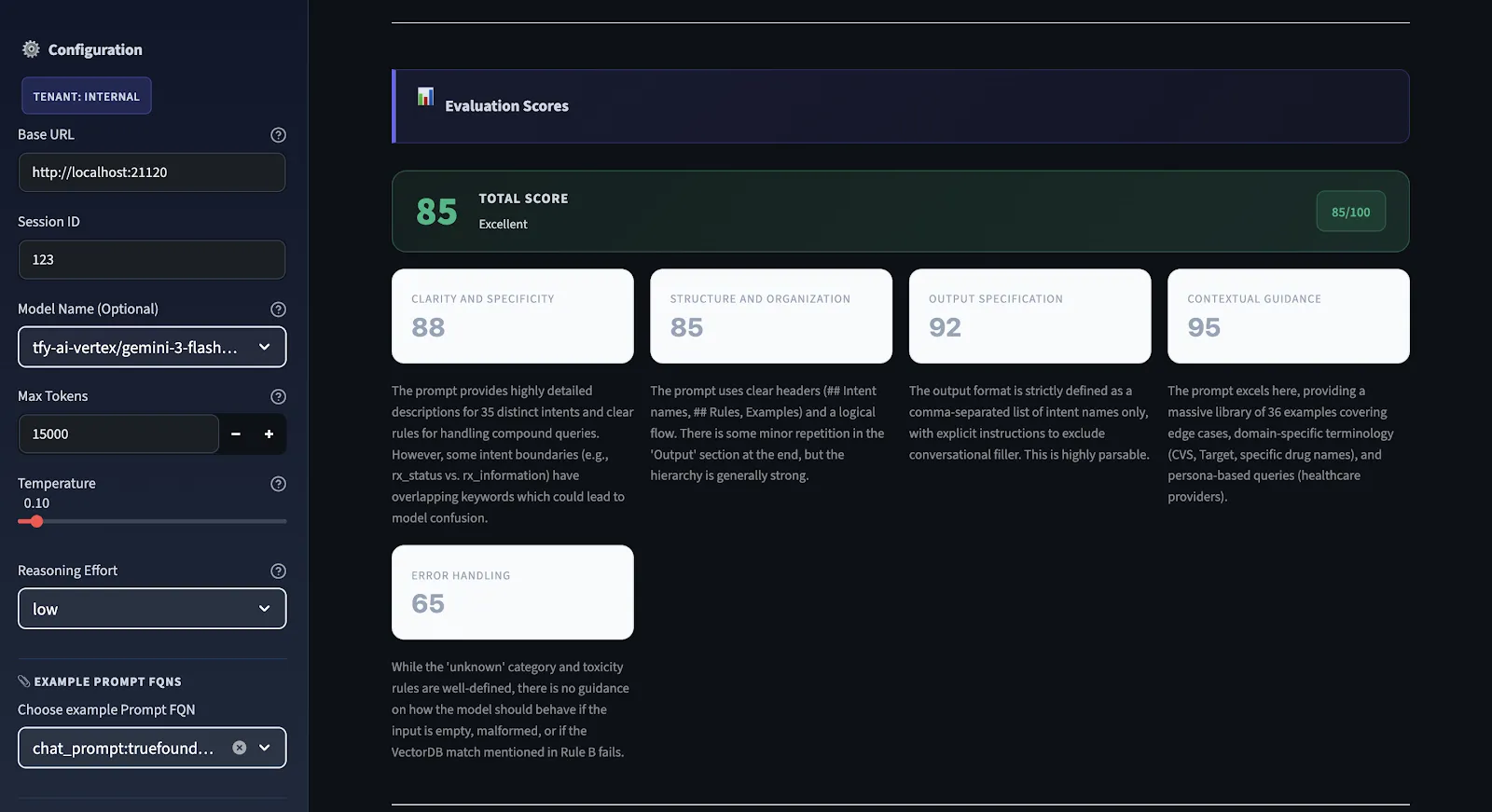
Il s'agit du moteur de diagnostic du flux de travail. Chaque invite reçoit une note de 0 à 100 selon cinq critères spécifiques. Le score global est la moyenne arithmétique des cinq points. Voici ce que chacun mesure et pourquoi c'est important :
Les instructions sont-elles suffisamment claires pour que deux modèles différents puissent les comprendre exactement de la même manière ? Les instructions vagues sont plus source d'incohérences que tout autre facteur. Si vous ne savez pas comment un humain pourrait interpréter votre message, vous ne savez probablement pas comment un modèle l'interprétera. S'il existe plusieurs manières pour un humain de l'interpréter, il existe plusieurs manières pour un modèle de l'interpréter correctement ou incorrectement.
L'invite découle-t-elle logiquement du contexte → des instructions → des contraintes → du format de sortie ? Une invite désorganisée force le modèle à déterminer ce qui est important et dans quel ordre. Une bonne structure facilite le travail du modèle et rend vos sorties plus fiables.
Le format, la structure et la longueur de sortie attendus sont-ils bien définis ? Si la sortie doit être analysée par un analyseur ultérieur, n'y a-t-il aucune ambiguïté quant à l'apparence de la sortie ? Cela permet de vérifier la condition d'erreur la plus courante : les sorties qui semblent correctes mais ne peuvent pas être analysées.
Cette invite fournit-elle au modèle un contexte suffisant pour fonctionner sans émettre d'hypothèses ? Les modèles qui doivent émettre des hypothèses feront toujours des hypothèses incorrectes. Le contexte, tel que la terminologie du domaine, les informations relatives aux limites et le contexte, éliminera complètement ce type d'erreur.
Les boîtiers Edge sont-ils couverts ? Cette invite indique-t-elle ce qu'il faut faire dans les cas où l'entrée est ambiguë, incomplète ou hors limites ? C'est l'erreur la plus courante et celle qui cause le plus de problèmes liés à la production. Hallucinations, formats de saisie inattendus, informations manquantes : tout cela doit être abordé dans cette invite.
Échelle de notation : 90-100 est prêt pour la production. 75—89 comporte des lacunes mais est fonctionnel. 50—74 fonctionne mais n'est pas fiable. En dessous de 50, cela signifie des problèmes structurels importants qui doivent être résolus avant l'expédition.
Nous avons les notes et les explications pour chaque critère. Ensuite, nous produisons une version concrète de l'invite améliorée. Les recommandations ne sont pas que des idées abstraites. Ils correspondent à des modifications réelles de la structure de l'invite. Ces modifications incluent l'ajout de spécifications de sortie manquantes, la précision des instructions peu claires, la division des problèmes liés au contenu et au format, et l'explicitation des solutions de rechange pour les cas limites.
La principale contrainte que nous imposons est celle de la préservation de l'intention. En d'autres termes, nous ne réécrivons pas l'invite. Nous comblons plutôt les lacunes mises en évidence par l'évaluation tout en préservant l'intention et le domaine d'origine.
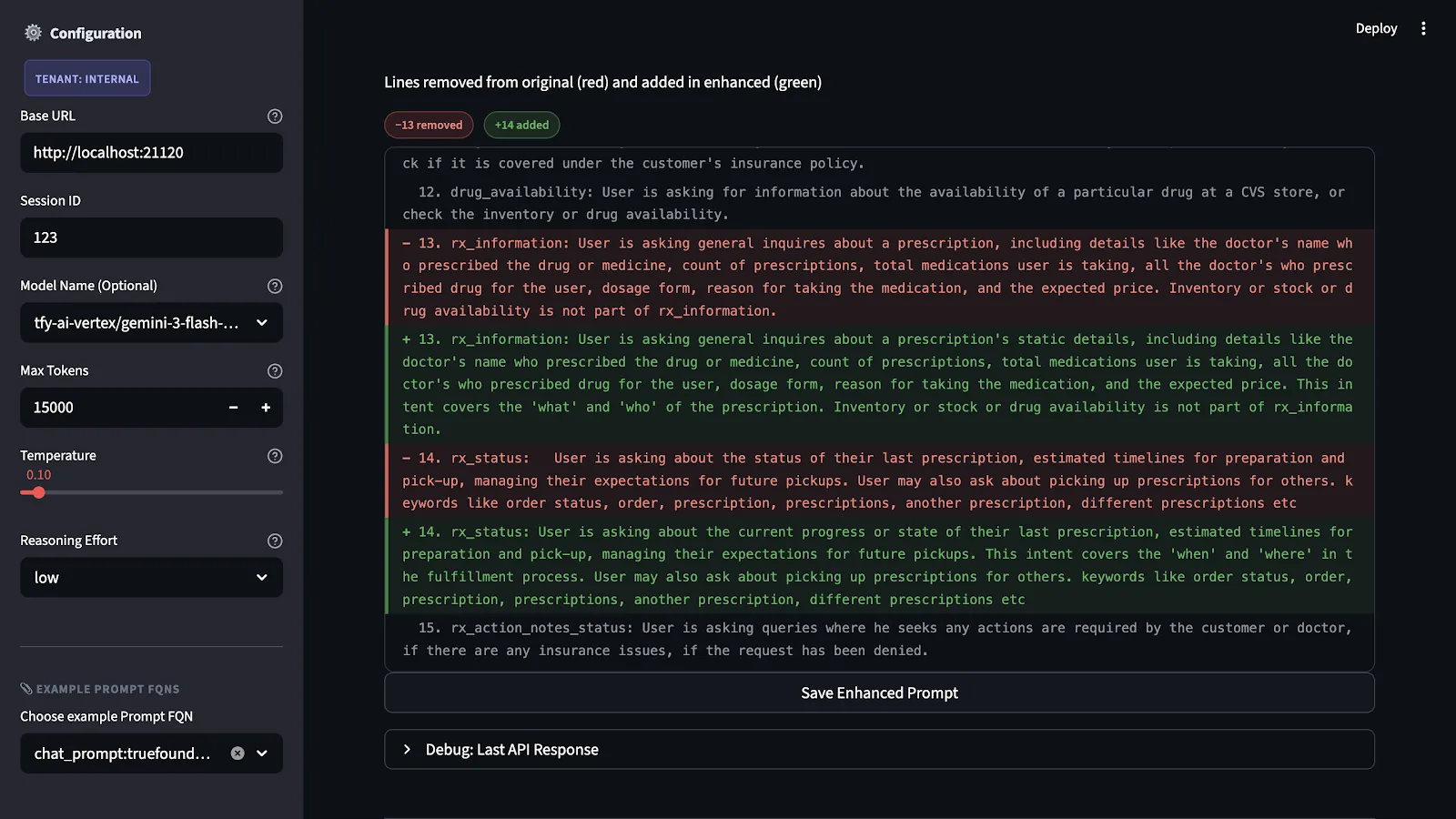
L'invite améliorée n'est exécutée qu'après avoir été testée pour la première fois. Le test est réalisé à l'aide d'un jeu de données de référence qui représente tous les scénarios et échecs possibles en relation avec l'application.
Ce processus est nécessaire car apporter des modifications aux instructions qui semblent bénéfiques en théorie peut entraîner des problèmes d'application imprévus. Bien que le resserrement d'une spécification de sortie puisse entraîner des problèmes d'application imprévus en raison de la dépendance à la flexibilité du modèle dans d'autres situations, il peut entraîner des problèmes lorsqu'il est associé à certains types d'entrée.
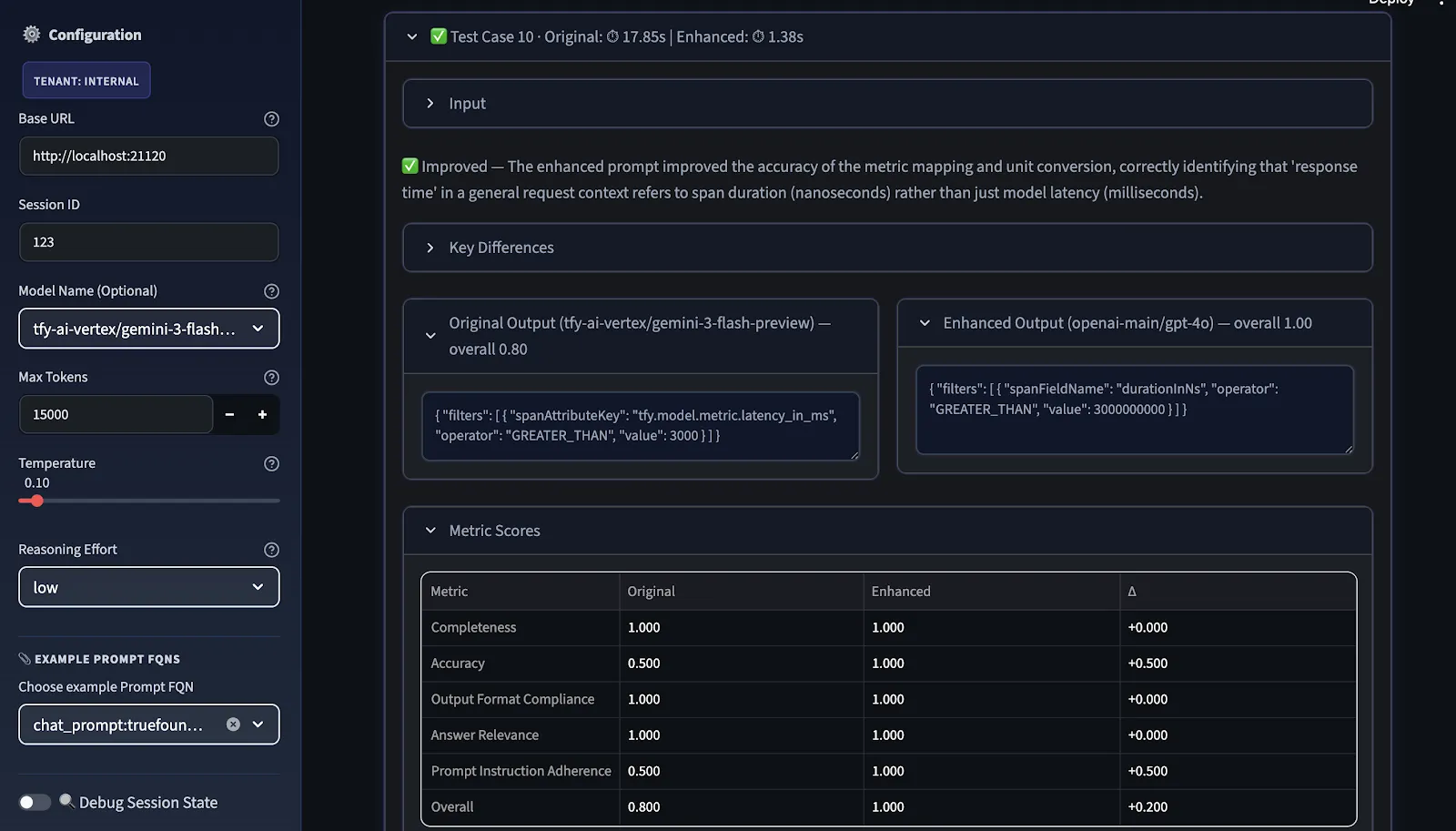
La dernière étape est l'analyse comparative. Nous comparons les instructions d'origine et les instructions améliorées selon deux dimensions :
Le score global est la moyenne arithmétique des indicateurs sélectionnés ; les utilisateurs peuvent choisir des mesures pertinentes avant l'évaluation.
La vue comparative montre les domaines dans lesquels l'amélioration est réelle, les domaines spécifiques au modèle et les domaines dans lesquels des itérations supplémentaires sont nécessaires avant que l'invite puisse être considérée comme transférable d'un fournisseur à l'autre.
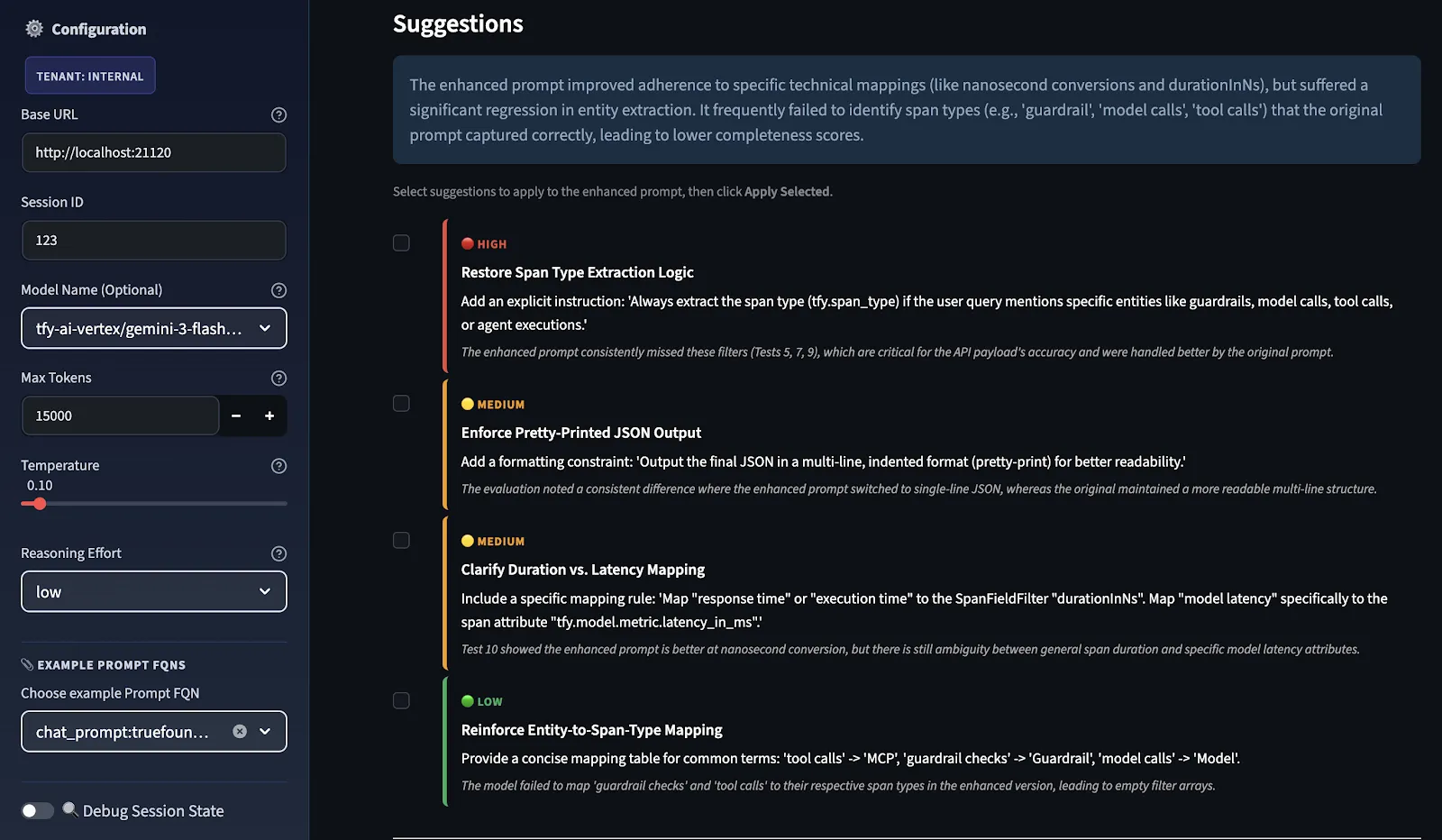
Par la suite, le juge LLM note les deux invites et les suggestions d'amélioration sont fournies par ordre de priorité, classées comme ÉLEVÉ, MOYEN et FAIBLE en fonction de l'endroit où le delta de score entre l'original et l'amélioré était le plus faible.
Vous sélectionnez les suggestions à appliquer en tant que recommandation, et le système les renvoie via le même pipeline d'amélioration pour produire une invite améliorée affinée. Cette boucle de rétroaction améliore continuellement l'invite en la réévaluant et en l'affinant.
Il ne s'agit pas de suggestions générales ; elles sont spécifiques à des cas de test. La raison en est que le modèle Evaluator évalue la performance de vos invites d'origine et de vos invites améliorées dans vos scénarios de test. Les suggestions que vous voyez sont directement liées à ce qui manquait dans l'évaluation de votre scénario de test. Si vous deviez ajouter des cas de test supplémentaires à cette évaluation, d'autres suggestions pourraient s'afficher.
Vous pouvez répéter ce processus autant de fois que nécessaire. Chaque cycle utilise l'invite précédemment améliorée comme nouvelle référence, ce qui permet de cumuler les améliorations. L'invite finale affinée peut être téléchargée directement depuis l'interface utilisateur et déployée à l'aide de Passerelle True Foundry.
Lorsque nous parlons d'ingénierie, il y a une chose à laquelle nous ne pensons pas souvent. Le fait est que des modèles comme Gemini, GPT-5, Claude et LLama ne comprennent pas les choses de cette façon. Cela s'explique par le fait qu'ils ont tous été formés de manière à tirer des enseignements de différents ensembles d'informations et qu'ils ont été amenés à faire les choses un peu différemment. Ainsi, lorsque nous leur demandons quelque chose, ils peuvent nous donner des réponses différentes. Ce n'est pas parce que la question est mauvaise. Parce que chaque modèle a sa propre façon de faire.
Certains modèles sont très bons pour suivre les règles et faire ce que nous disons. Les modèles GPT-4, par exemple, peuvent être très littéraux. Les modèles LLama sont peut-être plus génératifs. Essayez de combler les lacunes. Les modèles Claude peuvent être efficaces pour traiter des questions complexes. D'autres modèles pourraient être meilleurs pour répondre à des questions simples.
La seule façon de savoir comment une invite se comporte sur tous les modèles est de la tester. Et la seule façon de rendre ces tests systématiques est de disposer d'un flux de travail d'évaluation comme celui-ci.
Une fois que votre demande a été évaluée, améliorée et testée, vous avez besoin d'un système capable de la gérer au fil du temps, de gérer les versions, de déployer en fonction de l'environnement et de pouvoir annuler les modifications incorrectes sans redéployer l'intégralité de votre application.
C'est là qu'intervient la passerelle IA de TrueFoundry. TrueFoundry fournit un système de gestion des demandes centralisé avec un système de gestion des versions intégré. Chaque modification apportée à une invite est suivie, et vous pouvez référencer des versions spécifiques à l'aide d'alias lisibles par l'homme tels que v1-prod ou v2-staging. La passerelle corrige la version rapide au moment de l'exécution, ce qui signifie que les mises à jour rapides ne nécessitent plus de redéploiements de code.
Le flux de travail ayant été appliqué à une variété de demandes et de projets, plusieurs points clés sont apparus :
L'objectif que nous visons est de faire en sorte que la qualité des délais soit aussi mesurable et contrôlable que n'importe quel autre élément de votre suite logicielle. Cela implique des tests de régression automatisés pour les demandes lorsque la version du modèle sous-jacent change, un versionnage rapide intégré à votre pipeline de déploiement et des tableaux de bord d'évaluation qui donnent une visibilité sur les performances rapides au fil du temps.
L'ingénierie rapide n'est plus considérée comme un métier mais comme une science. Les organisations qui le traitent comme tel et mettent en œuvre un processus formel d'évaluation, d'itération et de test seront mieux placées pour créer des systèmes d'IA plus fiables que celles qui ne le font pas. Le processus décrit dans ce flux de travail constitue un effort à cette fin.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


