

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: July 8, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
La disponibilité du calcul est le principal obstacle à la formation des LLM et à la mise à l'échelle de l'inférence haut débit. Si vous avez essayé de provisionner Instances Amazon EC2 P5 ou des machines virtuelles Azure ND H100 v5 récemment, vous avez probablement rencontré des erreurs InsuffisantInstanceCapacity ou on vous a dit que vous aviez besoin d'un contrat de tarification privé pluriannuel.
Cette rareté fait des fournisseurs de GPU spécialisés, tels que CoreWeave, Lambda Labs et FluidStack, des alternatives viables. Ces offres « Neo-Clouds » NVIDIA H100 et les A100 proposent souvent des tarifs à la demande inférieurs à ceux des trois grands.
Le problème ? Exécuter AWS pour votre Amazon S3 Un lac de données lors de la création manuelle de nœuds bare metal dans Lambda Labs crée des flux de travail fragmentés. Nous résolvons ce problème en traitant les clouds spécialisés comme standard Kubernetes clusters au sein d'un plan de contrôle unifié.
TrueFoundry utilise une architecture à plans divisés. Le plan de contrôle gère la planification des tâches et le suivi des expériences, tandis que le plan de calcul reste dans votre environnement. Étant donné que la plupart des clouds spécialisés fournissent une Kubernetes service ou vous permettre de déployer K3, nous les joignons via un agent standard.
Nous résumons le stockage et l'entrée. Que le fournisseur utilise Vast Data ou un RAID NVMe local, nous le mappons à un Réclamation concernant le volume persistant. Cela permet de conserver votre Docker conteneurs portables entre les fournisseurs.
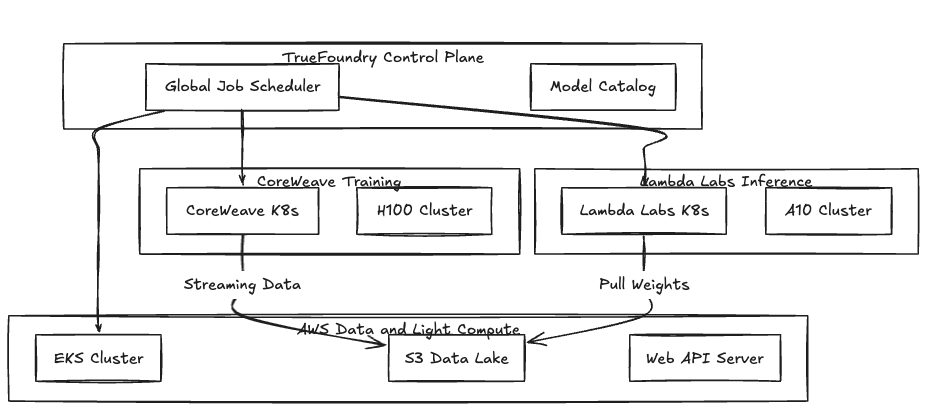
Figure 1 : Topologie hybride utilisant AWS pour la persistance des données et des clouds spécialisés pour les charges de travail gourmandes en GPU.
Les prix du H100 à la demande varient considérablement. Nous utilisons TrueFoundry pour configurer des files d'attente hiérarchisées. Vous pouvez d'abord cibler une capacité interruptible bon marché sur des clouds spécialisés. Si le fournisseur préempte l'instance ou si la capacité disparaît, le planificateur peut automatiquement basculer vers une instance réservée Amazon EC2 instance.
Le recours à des plateformes d'IA propriétaires vous lie souvent à l'écosystème de stockage et d'IAM d'un cloud spécifique. Nous emballons les tâches de formation sous forme de conteneurs standard. TrueFoundry gère les Pilotes Kubernetes CSI pour le montage S3 et configure le Boîte à outils NVIDIA Container variables d'environnement automatiquement. Vous déplacez une tâche d'AWS vers CoreWeave en mettant à jour le cluster_name dans votre spécification de déploiement.
Les configurations multicloud interrompent généralement la journalisation. Nous agrégeons Prométhée métriques et Grafana tableaux de bord pour tous les clusters. Si une tâche de formation apparaît sur un nœud Lambda Labs, l'utilisation du GPU et les journaux système s'affichent dans la même interface utilisateur que celle que vous utilisez pour votre environnement de production EKS.
Pour ajouter une capacité spécialisée, suivez ce cycle de vie :
helm repo add truefoundry https://truefoundry.github.io/infra-charts/
helm install tfy-agent truefoundry/tfy-agent \
--set tenantName=my-org \
--set clusterName=lambda-h100-pool \
--set apiKey=<YOUR_API_KEY>
Comparaison des modèles d'infrastructure
S'appuyer sur un cloud unique pour le calcul LLM n'est plus une stratégie viable pour les équipes d'ingénierie à forte croissance. En découplant la définition de la charge de travail du lieu d'exécution, vous pouvez traiter les GPU comme une marchandise. Dirigez votre entraînement intensif vers des clouds spécialisés pour plus d'efficacité tout en conservant vos données et services de base dans votre région hyperscale principale.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


