

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
.webp)
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Alors que le développement de modèles est devenu plus rationalisé, le déploiement, la mise à l'échelle et la gestion des modèles de machine learning en production restent un obstacle majeur. Les équipes chargées de la plateforme sont chargées de veiller à ce que les modèles de machine learning puissent être déployés, surveillés, mis à l'échelle et optimisés de manière fluide dans de multiples environnements, tout en minimisant les coûts d'infrastructure et en préservant la fiabilité.
Les approches traditionnelles de déploiement du machine learning nécessitent souvent une expertise approfondie de Kubernetes, une gestion manuelle des ressources GPU et des mécanismes de mise à l'échelle inefficaces, ce qui entraîne des frais opérationnels élevés pour les équipes de la plateforme. Pour répondre à ces défis, TrueFoundry propose une solution de déploiement de machine learning en tant que service, conçue pour automatiser la sélection de l'infrastructure, simplifier le déploiement, optimiser les performances et améliorer l'observabilité.
Le déploiement de modèles ML nécessite de sélectionner les instances GPU, les serveurs modèles et les configurations Kubernetes appropriés. Sans automatisation intelligente, les équipes de la plateforme doivent allouer manuellement les ressources, ce qui entraîne des déploiements longs et sujets aux erreurs.
Le processus actuel implique souvent de multiples transferts entre les data scientists, les ingénieurs ML et les équipes DevOps. Les ingénieurs de plateforme interviennent fréquemment pour faciliter la configuration, la mise à l'échelle et la surveillance de Kubernetes, ce qui entraîne des inefficacités et des blocages.
Les déploiements de machine learning traditionnels ne disposent pas de mécanismes de dimensionnement automatique du GPU intégrés. Sans mise à l'échelle dynamique basée sur les demandes par seconde (RPS), l'utilisation ou des déclencheurs temporels, l'infrastructure est soit sous-utilisée (ce qui entraîne un gaspillage de dépenses) soit surprovisionnée (ce qui entraîne des goulots d'étranglement en termes de performances).
Choisir le plus efficace service de modèles Une approche, ainsi que le bon modèle de serveur (par exemple, vLLM, SGlang, Triton, FastAPI, TensorFlow Serving) nécessitent une expertise approfondie en matière d'analyse comparative des performances, d'optimisation de la mémoire et d'équilibrage de charge.
Les déploiements de machine learning génèrent des journaux, des métriques et des événements sur plusieurs plateformes. La résolution des problèmes de performances ou des défaillances est fastidieuse, car les journaux sont souvent éparpillés, ce qui rend difficile pour les équipes de la plateforme d'identifier et de résoudre rapidement les problèmes.
Sans optimisation automatique des ressources, les équipes de la plateforme doivent surveiller et gérer manuellement les modèles inactifs, ce qui entraîne des dépenses inutiles liées au cloud. Les méthodes traditionnelles de déploiement du machine learning ne prennent pas en charge l'arrêt automatique ni la mise à l'échelle dynamique.
Les entreprises ont besoin de mettre à niveau leurs modèles sans interruption de service, mais les méthodes traditionnelles ne disposent pas de mises à jour continues, de versions Canary et de déploiements bleu-vert. Cela augmente le risque d'interruption de service lors du déploiement de nouvelles versions de modèles.
TrueFoundry élimine ces défis en fournissant un plateforme de déploiement de machine learning entièrement gérée, permettant déploiements en libre-service, sélection intelligente des ressources, optimisation des coûts et meilleure observabilité. Voici comment procéder :
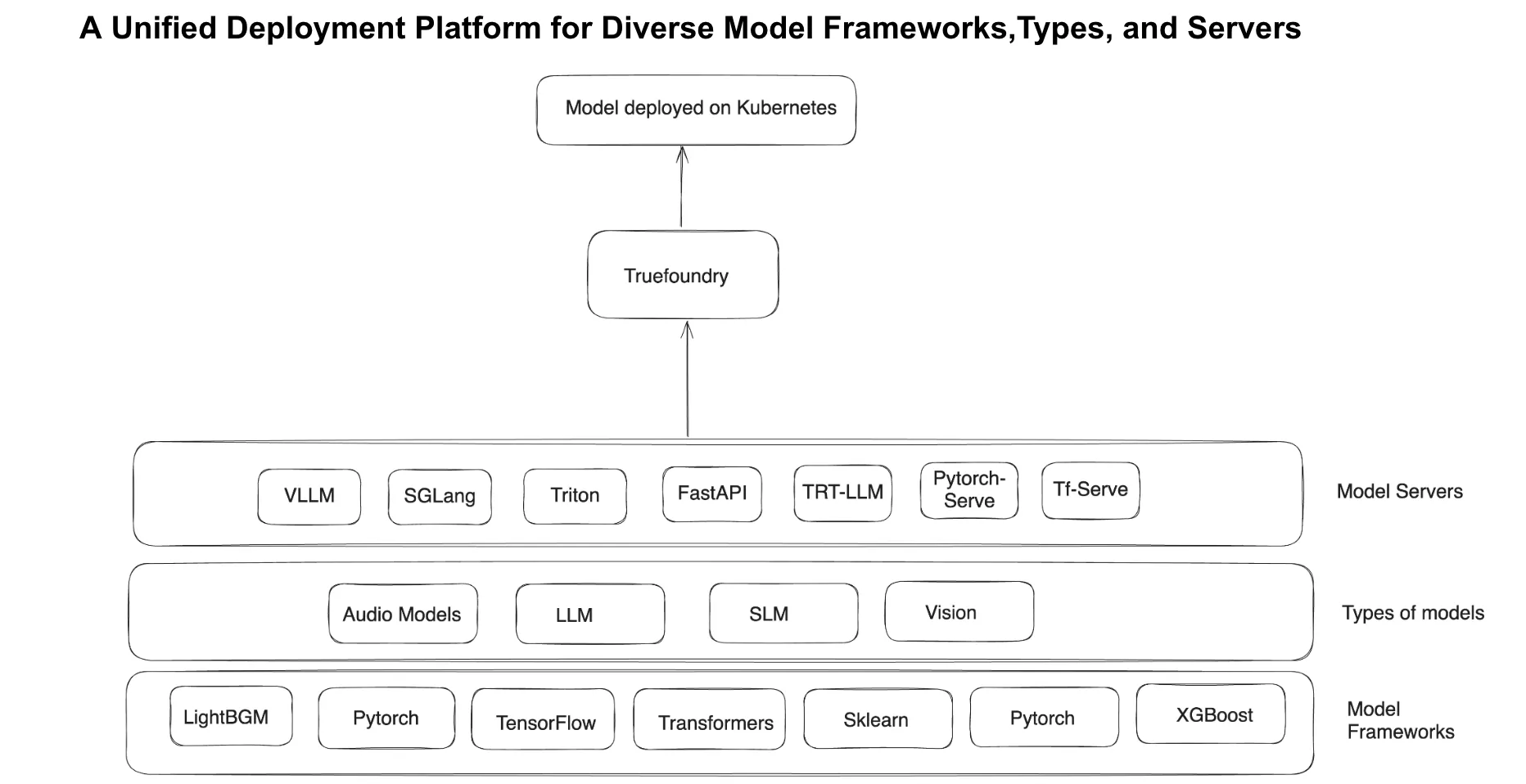
TrueFoundry permet aux équipes de la plateforme de déployer des modèles de machine learning en un seul clic, éliminant ainsi le besoin d'expertise Kubernetes. La plateforme sélectionne intelligemment les meilleures configurations d'infrastructure, en sélectionnant les types d'instances GPU, les modèles de serveurs et les stratégies de dimensionnement optimaux en fonction des exigences de charge de travail.
De plus, l'intégration de GitOps garantit que tous les déploiements sont automatisés et reproductibles, avec la génération YAML intégrée pour faciliter les flux de travail CI/CD. En faisant abstraction de la complexité de l'infrastructure, TrueFoundry permet aux data scientists et aux ingénieurs ML de déployer des modèles de manière indépendante, réduisant ainsi la charge opérationnelle des équipes de la plateforme.
La mise à l'échelle automatique avancée basée sur le GPU de TrueFoundry ajuste dynamiquement les ressources en fonction de la demande en temps réel. Les modèles évoluent vers le haut et vers le bas en fonction du RPS, de l'utilisation du GPU ou de déclencheurs planifiés, garantissant ainsi des performances et une rentabilité optimales. La plateforme propose également :
En outre, TrueFoundry prend en charge des stratégies de déploiement avancées, notamment des mises à jour continues, des versions Canary et des déploiements bleu-vert, permettant aux équipes de la plateforme de déployer de nouvelles versions de modèles sans interruption de service.
TrueFoundry fournit une observabilité centralisée, proposant des journaux, des mesures et des événements en un seul endroit, améliorant ainsi considérablement l'efficacité du dépannage. Ce tableau de bord unifié aide les équipes de la plateforme à :
Le routage permanent pour les LLM améliore encore le débit de 50 %, garantissant ainsi une gestion efficace des demandes, tandis que la prise en charge du catalogue de modèles (actuellement intégrée à Hugging Face) permet de gérer facilement les versions des modèles et les registres.
En outre, les suggestions infra automatisées de TrueFoundry optimisent les configurations du processeur, de la mémoire et de la mise à l'échelle automatique en fonction des modèles de trafic, rationalisant ainsi davantage la gestion des déploiements
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


