

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Alors que les grands modèles linguistiques (LLM) continuent de transformer la façon dont les applications sont créées, notamment les copilotes d'IA et les interfaces de discussion d'entreprise, il existe un besoin croissant d'infrastructures et de processus structurés pour les gérer efficacement. Cette discipline émergente est connue sous le nom de LLMOPS. À l'instar de la manière dont MLOps a discipliné les flux de travail d'apprentissage automatique traditionnels, LLMops se concentre sur la résolution des défis opérationnels uniques liés à l'utilisation de modèles de base à grande échelle.
LLMops ne se limite pas à servir un modèle via une API. Cela implique l'ensemble du cycle de vie, y compris l'ingénierie rapide, le réglage précis, la génération augmentée par extraction (RAG), le contrôle des versions, la surveillance des performances, l'optimisation des coûts et l'application sécurisée des accès. En raison de la taille et de la complexité des LLM, une architecture dédiée est nécessaire pour garantir des déploiements fiables, évolutifs et maintenables.
Cet article explore les principes fondamentaux de l'architecture LLMops. Nous analyserons ses principaux composants, examinerons les modèles de référence utilisés dans les systèmes du monde réel et mettrons en évidence les outils qui favorisent un développement et une gouvernance rapides. Que vous créiez un assistant de support client, un moteur de recherche de connaissances ou une plateforme d'agents pilotée par l'IA, il est essentiel de comprendre l'architecture LLMops pour créer des solutions efficaces, évolutives et prêtes pour la production.
LLmops L'architecture fait référence à la conception structurée et à l'ensemble de composants nécessaires pour gérer le cycle de vie de grands modèles de langage dans les environnements de production. C'est la base qui permet aux équipes de passer de l'expérimentation des LLM à la création d'applications évolutives, sécurisées et maintenables basées sur ces modèles.
Contrairement aux MLOP traditionnels, qui traitent principalement de jeux de données structurés et de pipelines d'apprentissage de modèles, les LLMOP doivent prendre en compte des défis uniques tels que l'orchestration rapide, la génération augmentée par extraction, la gestion des versions des modèles à grande échelle et la latence d'inférence en temps réel. L'architecture doit également prendre en charge des charges de travail dynamiques, routage multimodèle, et un accès sécurisé entre les utilisateurs et les équipes.
L'architecture LLMops combine infrastructure, automatisation et observabilité pour garantir un déploiement et une gouvernance fiables. Il comprend généralement :
Cette architecture est conçue pour prendre en charge à la fois des modèles pré-entraînés utilisés comme API et des modèles personnalisés et affinés déployés dans des environnements privés. À mesure que l'utilisation du LLM augmente dans tous les domaines, une architecture bien structurée devient essentielle pour une itération rapide, une rentabilité et la confiance des utilisateurs.
Comprendre l'architecture LLMops aide les équipes à créer des systèmes évolutifs tout en restant flexibles, conformes et alignés sur les résultats commerciaux réels.
L'architecture LLMops apporte structure et évolutivité au déploiement de grands modèles de langage. Contrairement aux MLOP traditionnels, il répond à des complexités uniques liées à l'orchestration rapide, aux pipelines de récupération et au comportement des modèles lors de l'exécution. Une architecture robuste relie plusieurs couches centrales, chacune remplissant une fonction essentielle.
Gestion des données
Les LLM dépendent de données diverses et de haute qualité pour fonctionner correctement. Ce composant implique la recherche, le nettoyage, la mise en forme et le stockage de données de texte ou de documents à grande échelle. Pour les modèles affinés, des ensembles de données étiquetés peuvent également être nécessaires. La gestion des versions des données et le suivi du lignage sont essentiels pour garantir la traçabilité entre les itérations du modèle.
Développement de modèles
Cette couche se concentre sur la sélection du modèle de base et l'application de la personnalisation par le biais d'un réglage fin, d'un réglage des instructions ou d'une ingénierie rapide. Les cadres d'analyse comparative sont utilisés pour valider les performances de diverses tâches en aval. Des outils tels que LoRa et PEFT permettent de réduire les coûts et les calculs lors des mises à jour des modèles.
Inférence et déploiement
La prestation de services aux LLM nécessite une infrastructure évolutive. Cela inclut des API optimisées, la quantification des modèles, le streaming au niveau des jetons et la mise à l'échelle automatique sur les GPU. Les outils d'observabilité surveillent le coût d'inférence, la latence et le débit. Les configurations de production incluent souvent des tests A/B, des stratégies de restauration et un routage multimodèle.
Sécurité et conformité
Les LLMOP doivent répondre aux besoins de sécurité des entreprises. Le chiffrement, le contrôle d'accès, la pseudonymisation des données et les pistes d'audit sont essentiels pour respecter les normes de conformité telles que HIPAA, GDPR ou SOC 2.
Gouvernance et IA responsable
Cette couche gère le versionnage rapide, le suivi des hallucinations et la détection des biais. L'enregistrement de toutes les interactions et l'application de filtres pour les contenus préjudiciables garantissent un comportement éthique et cohérent en production.
Meilleures pratiques et préparation pour l'avenir
Les LLMOP efficaces incluent des pipelines modulaires, des boucles d'évaluation et une traçabilité rapide. À l'avenir, les architectures évoluent pour prendre en charge la récupération en temps réel, le réglage continu et la coordination multi-agents.
En alignant ces composants, les équipes peuvent fournir des applications LLM robustes, adaptables et prêtes à l'emploi.
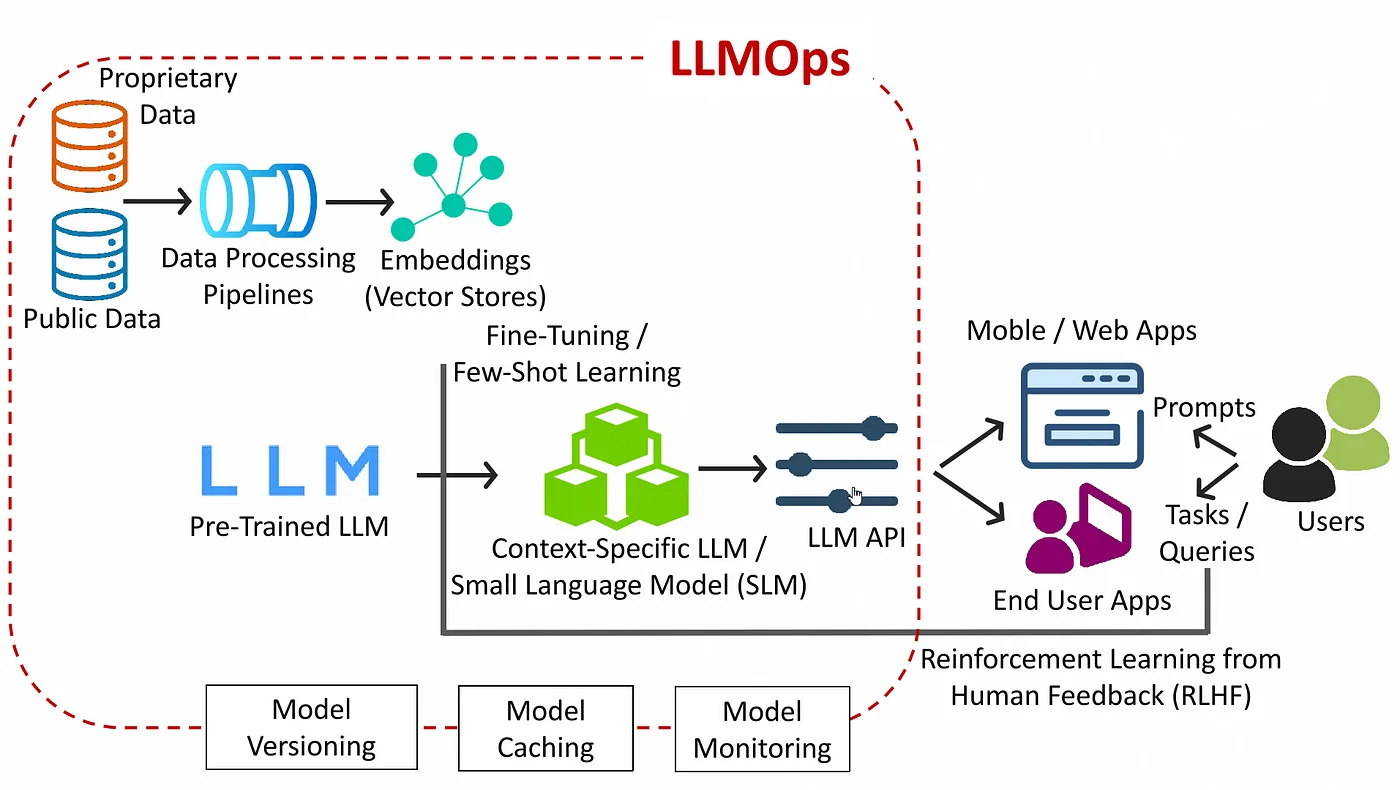
Ce visuel présente une architecture LLMops moderne, couvrant l'ensemble du pipeline, de l'ingestion des données brutes au déploiement en production, en passant par l'interaction avec les utilisateurs et l'apprentissage basé sur les commentaires. Il reflète la manière dont les systèmes de grands modèles linguistiques du monde réel sont conçus et gérés au sein des équipes et des environnements.
Collecte et traitement des données : L'architecture commence par des sources de données publiques et propriétaires. Il peut s'agir de corpus de textes, de documents, de données CRM, de bases de connaissances internes ou de conversations avec les clients. Toutes les données passent par un pipeline de traitement des données, où elles sont nettoyées, normalisées et enrichies pour les tâches en aval. Cela inclut la conversion de texte en intégrations vectorielles, qui sont stockées dans des bases de données vectorielles ou des magasins d'intégration pour une récupération rapide basée sur les similitudes.
Sélection et adaptation du modèle : Un LLM pré-formé (tel que GPT, LLama ou Falçon) est sélectionné comme modèle de base. À l'aide d'ajustements ou d'un apprentissage par étapes, les équipes créent un LLM ou un modèle de langage simplifié (SLM) spécifique au contexte et adapté à leur domaine ou à leur cas d'utilisation. Cela permet un meilleur alignement avec le langage, le ton, les tâches et la structure de données spécifiques à l'application.
Passerelle LLM
Au cœur de l'architecture se trouve le LLM Gateway. Il fournit une surface d'API unifiée pour tous les points de terminaison du modèle, en gérant l'authentification, le routage, le traitement par lots et la traduction des protocoles. La passerelle applique des limites de débit et des quotas, applique des modèles rapides et orchestre le routage de secours ou A/B entre les versions des modèles. Il collecte également des mesures précises sur le nombre de demandes, les latences et les taux d'erreur avant de transmettre les appels à la couche d'inférence.
Service d'API LLM : Le modèle personnalisé est exposé via une API LLM, qui fait office d'interface principale pour les applications. Ces API sont conçues pour une interaction en temps réel et gèrent l'optimisation de l'inférence grâce au traitement par lots, à la quantification et au contrôle de la latence. L'architecture inclut également la mise en cache des modèles pour réduire la redondance et la surveillance des modèles pour garantir la fiabilité et la rentabilité.
Applications utilisateur et boucle de feedback
Les clients mobiles et Web soumettent des invites à la passerelle, reçoivent les réponses générées et les présentent aux utilisateurs finaux. Les données d'interaction sont capturées pour le réentraînement RLHF ou hors ligne, bouclant ainsi la boucle en matière d'amélioration continue du modèle.
Gouvernance et gestion du cycle de vie : L'architecture inclut des fonctionnalités opérationnelles de base telles que la gestion des versions des modèles, les pistes d'audit, le suivi rapide et les politiques d'accès sécurisées. Ils garantissent que les systèmes LLM restent reproductibles, interprétables et conformes au fil du temps.
Ce diagramme capture efficacement le cycle de vie complet du déploiement et de l'optimisation du LLM au sein d'un pipeline LLMOPs de niveau production.
L'architecture LLMops commence par des données publiques et propriétaires circulant via des pipelines de traitement pour générer des intégrations, qui sont stockées dans des bases de données vectorielles. Un grand modèle de langage pré-entraîné est ensuite affiné ou adapté à l'aide d'un apprentissage en quelques étapes pour créer un modèle spécifique au contexte. Ce modèle est déployé derrière une API LLM optimisée qui dessert les applications mobiles et Web en temps réel. Les utilisateurs interagissent avec ces applications en soumettant des invites et en recevant des réponses intelligentes. Les commentaires issus des interactions avec les utilisateurs sont exploités grâce à l'apprentissage par renforcement à partir du feedback humain (RLHF), tandis que la gestion des versions, la mise en cache et la surveillance des modèles garantissent les performances, la traçabilité et la gouvernance du système.
L'architecture LLMops n'est pas universelle. En fonction de la taille, du domaine et des exigences réglementaires de l'organisation, différents modèles apparaissent pour opérationnaliser efficacement les LLM. Ces modèles aident les équipes à équilibrer les performances, les coûts, la gouvernance et la vitesse de développement. Vous trouverez ci-dessous quelques modèles de référence largement adoptés dans les déploiements du monde réel.
Déploiement LLM centré sur les API
Il s'agit du modèle le plus courant pour les équipes en phase de démarrage ou les cas d'utilisation légers. Un LLM pré-entraîné ou affiné est hébergé derrière une API REST, et les applications en aval émettent des requêtes synchrones. Les modèles d'invite sont versionnés et une orchestration minimale est utilisée. Ce modèle est simple à implémenter et fonctionne bien pour la génération de contenu, la synthèse ou les interfaces de discussion de base.
Modèle RAG (Retrieval-Augmented Generation)
Utilisée dans des environnements à forte intensité de connaissances, cette architecture associe un LLM à une base de données vectorielle qui extrait des informations pertinentes au contexte. Les entrées sont d'abord enrichies par une extraction basée sur l'intégration à partir de bases de connaissances internes ou externes, puis transmises au LLM. Ce modèle améliore le fondement factuel et la spécificité du domaine. Il est idéal pour le support client, l'analyse de documents juridiques ou la recherche d'entreprises.
Modèle d'orchestration des flux de travail LLM +
Dans les systèmes plus complexes, les LLM sont intégrés dans des flux de travail plus importants à l'aide de frameworks d'orchestration tels que LangChain, LangGraph ou Airflow. Ces architectures enchaînent plusieurs étapes : récupération, mise en forme rapide, inférence, post-traitement et déclencheurs d'action. Cela permet une prise de décision dynamique, des systèmes multi-agents et une exécution autonome des tâches. Il est utilisé dans l'IA agentique, les copilotes d'IA et les applications multitours.
Modèle LLM privé affiné
Pour les secteurs hautement réglementés ou les cas d'utilisation de données sensibles, les organisations peuvent affiner les LLM open source et les héberger au sein de leur propre infrastructure ou VPC. L'architecture inclut l'anonymisation des données, la mise au point de pipelines, des environnements d'inférence isolés, ainsi qu'une surveillance et un contrôle d'accès complets. Ce schéma est courant dans les domaines de la santé, de la finance et de la défense.
Modèle hybride Cloud-Edge
Apparaissant dans les scénarios d'IA de pointe, ce modèle permet de conserver le principal LLM dans le cloud mais de transférer des modèles légers ou une logique de traitement rapide vers les appareils de périphérie. Il réduit la latence et l'utilisation de la bande passante tout en conservant les données sensibles locales. Il est de plus en plus utilisé dans les expériences IoT, automobiles et mobiles.
Ces modèles reflètent la flexibilité et l'adaptabilité des LLMOP, offrant des voies vers
L'écosystème LLMops se développe rapidement et aucun outil ne peut répondre à tous les besoins. Les équipes les plus performantes élaborent des piles modulaires qui s'adaptent à leur infrastructure et à leurs flux de travail. Au cœur de nombreuses solutions destinées aux entreprises, TrueFoundry joue un rôle central en offrant une assistance sur les niveaux de déploiement, d'observabilité, d'orchestration et d'automatisation. Vous trouverez ci-dessous une ventilation des principales couches et des outils qui les alimentent.
1. Couche de données et d'intégration
Cette couche gère le nettoyage, la transformation, le découpage et l'intégration des données pour la génération augmentée par extraction (RAG). Il permet aux LLM de fonctionner en tenant compte du contexte.
Ces outils permettent aux modèles d'extraire des informations pertinentes au moment de l'inférence, améliorant ainsi la base factuelle et la qualité des résultats.
2. Service de modèles et couche d'inférence
Il s'agit de l'épine dorsale de la pile LLMops. Il inclut les composants nécessaires pour héberger et diffuser des modèles de manière efficace, gérer l'utilisation du GPU et faire évoluer les API.
Cette couche garantit que les réponses LLM sont fournies rapidement et à moindre coût, même en cas de trafic de production.
3. Couche d'exécution et d'orchestration
Cette couche gère les modèles d'invite, les flux d'agents et les interactions dynamiques. Il aide à acheminer la logique et à enchaîner les processus en plusieurs étapes au sein des applications LLM.
L'orchestration rapide permet aux équipes de contrôler le comportement des LLM dans des cas d'utilisation métier complexes.
4. Niveau de surveillance, de feedback et de gouvernance
La fiabilité, la transparence et l'éthique nécessitent des systèmes de surveillance et de gouvernance robustes. Cette couche capture les résultats, les commentaires des utilisateurs et les mesures de performance.
5. Couche de flux de travail et d'automatisation
Cette dernière couche gère la formation, l'évaluation, l'automatisation du déploiement et le CI/CD. Il permet des flux de travail traçables et reproductibles qui favorisent le développement itératif.
Ces outils, lorsqu'ils sont alignés sur plusieurs couches, transforment les LLMOP d'expériences dispersées en une discipline d'ingénierie reproductible et évolutive. Plutôt que de s'appuyer sur une seule solution de bout en bout, les équipes modernes assemblent des piles composables qui répondent à leurs besoins en matière d'infrastructure, d'évolutivité et de conformité.
La clé réside dans l'interopérabilité, en choisissant des outils qui s'intègrent parfaitement, automatisent les étapes clés et assurent la transparence tout au long du cycle de vie des modèles. Une fois la bonne solution en place, les LLM peuvent passer de prototypes à des systèmes de production qui génèrent des résultats commerciaux significatifs.
LLMops est en train de devenir rapidement une discipline fondamentale pour les équipes qui créent des applications basées sur de grands modèles de langage. Alors que les LLM passent d'une utilisation expérimentale à des systèmes critiques pour la production, les organisations ont besoin d'une architecture structurée, d'outils spécialisés et de flux de travail reproductibles pour gérer la complexité, les coûts et les performances. Une architecture LLMops bien conçue accélère non seulement le déploiement, mais garantit également un alignement éthique, une gouvernance des données et une amélioration continue grâce au feedback.
En adoptant des outils modulaires couvrant les couches de gestion des données, d'inférence, d'orchestration et de surveillance, les équipes gagnent en flexibilité et en contrôle sur tous les aspects du cycle de vie du LLM. Que vous utilisiez un modèle open source ou que vous peaufiniez un modèle propriétaire, les pratiques LLMops évolutives constituent l'épine dorsale des systèmes d'IA durables.
L'avenir du LLMoPS réside dans sa capacité à suivre le rythme de l'évolution rapide des modèles, des risques émergents et de la demande croissante des entreprises. Pour les organisations prêtes à évoluer de manière responsable, investir dans l'architecture LLMops n'est plus une option, mais un avantage stratégique.
Une architecture LLMops est le cadre structurel conçu pour gérer l'ensemble du cycle de vie de grands modèles de langage dans un environnement de production. Il fournit l'infrastructure nécessaire à l'ingestion de données, à la gestion rapide des versions et à l'orchestration des modèles, permettant ainsi à l'IA de passer d'une simple expérimentation à un déploiement fiable en entreprise. Cette architecture garantit que les applications restent évolutives, sécurisées et maintenables au fur et à mesure de leur évolution.
Une architecture LLMops comprend plusieurs couches critiques : des bases de données vectorielles pour le contexte basé sur RAG, des systèmes de gestion rapide pour le contrôle des versions et une passerelle IA centralisée pour la diffusion de modèles. En outre, il doit inclure des modules d'observabilité pour suivre la latence et l'utilisation des jetons, ainsi que des pipelines de réglage pour les tâches spécialisées. TrueFoundry unifie ces composants en un seul plan de contrôle, simplifiant ainsi la gestion d'une pile d'IA fragmentée.
La principale différence de l'architecture LLMops réside dans le passage de flux de travail nécessitant beaucoup de formation à des pipelines gourmands en orchestration. Alors que les MLOps traditionnels se concentrent sur la création de modèles personnalisés et l'ingénierie des fonctionnalités, LLMops donne la priorité à la gestion de modèles de base pré-entraînés grâce à une ingénierie rapide et à une génération augmentée par extraction (RAG). TrueFoundry fournit une plateforme qui prend en charge les deux paradigmes, permettant aux équipes de passer à l'IA générative sans abandonner les normes opérationnelles établies.
Les outils standard d'une architecture LLMops incluent des magasins vectoriels tels que Pinecone ou Weaviate, des frameworks d'orchestration tels que LangChain et des suites de surveillance spécialisées. Cependant, leur gestion en tant qu'entités distinctes crée souvent des silos d'intégration. TrueFoundry fonctionne comme une couche d'orchestration complète, fournissant l'infrastructure nécessaire pour gérer les déploiements de modèles, la rotation des secrets et le routage sensible aux coûts sur n'importe quel fournisseur de cloud.
TrueFoundry est une plate-forme idéale pour l'architecture LLMOPS car elle fournit un plan de contrôle centré sur le développeur qui s'exécute de manière native dans votre propre environnement cloud sécurisé. Il résume la complexité de Kubernetes et du provisionnement de l'infrastructure tout en offrant des passerelles hautes performances et une observabilité approfondie. En conservant les données dans votre VPC et en automatisant l'optimisation des ressources, cela garantit que la mise à l'échelle de l'IA d'entreprise reste à la fois sécurisée et rentable.
L'architecture LLMops se compose généralement de plusieurs couches : la couche de données, la couche modèle, la couche d'application et la couche d'infrastructure. La couche de données gère les ensembles de données, la couche modèle gère la formation ou l'inférence, la couche d'application intègre l'IA dans les produits et la couche d'infrastructure prend en charge le déploiement, la mise à l'échelle, la surveillance et la gestion du système.
LLMops inclut un contrôle de version structuré pour les invites, les modèles et les itérations de réglage. Le contrôle de version garantit la reproductibilité, facilite le retour en arrière et permet l'expérimentation sans perturber les systèmes de production. Les équipes peuvent suivre les améliorations, comparer les performances des modèles et maintenir la conformité aux exigences réglementaires et d'audit.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


