

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Le déploiement de Generative AI sur Google Cloud Platform (GCP) nécessite l'orchestration d'un ensemble complexe de primitives : Moteur Google Kubernetes (GKE), les TPU cloud et Vertex AI. Bien que GCP fournisse le calcul brut, le câblage de ceux-ci dans une plate-forme de développement interne (IDP) conforme nécessite une ingénierie personnalisée importante.
TrueFoundry joue le rôle de superposition de l'infrastructure. Nous nous occupons de l'orchestration, ce qui vous permet de contrôler le VPC et la résidence des données. Cet article détaille nos modèles d'intégration avec GCP, en particulier en ce qui concerne l'architecture à plan divisé, Fédération des identités de charge de travailet gestion du TPU.
Nous utilisons une architecture à plans divisés pour isoler l'interface de gestion de votre environnement d'exécution de la charge de travail.
Frontière de sécurité Nous n'avons pas besoin de règles de pare-feu entrant. L'agent de votre cluster lance un flux WebSocket ou gRPC sécurisé et sortant uniquement vers notre plan de contrôle. Il recherche les manifestes de déploiement et diffuse la télémétrie. Votre VPC reste privé du trafic entrant externe.
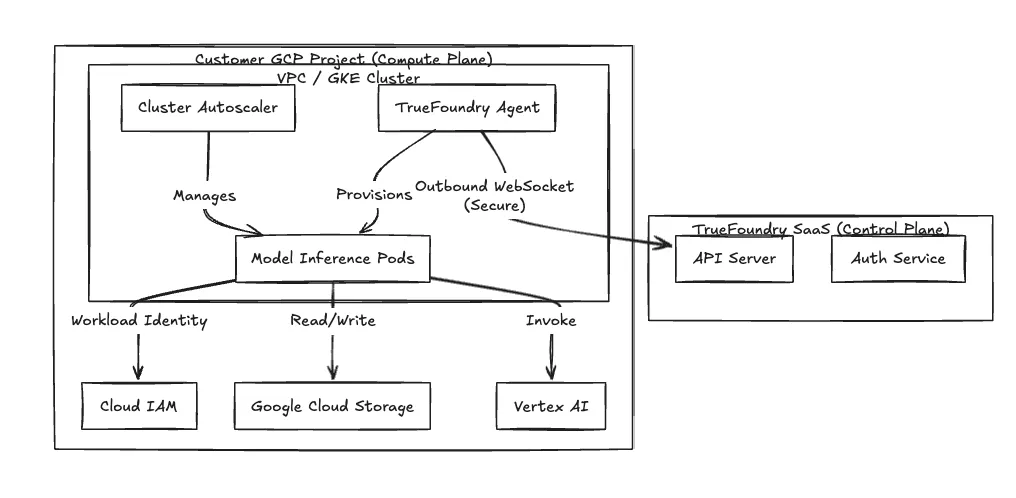
Figure 1 : L'architecture Split-Plane isole le traitement des données au sein du VPC du client.
Pour des performances élevées, nous configurons le plan de calcul à utiliser Clusters natifs VPC en utilisant Alias IP. Toutes les ressources de calcul se trouvent dans des sous-réseaux privés.
Entrée (demandes d'inférence) Le trafic des applications entre dans le VPC via Équilibrage de charge cloud (généralement un ALB externe mondial). L'ALB met fin au protocole TLS et transmet les demandes au Passerelle d'entrée Istio s'exécutant au sein du cluster GKE.
Accès privé à Google Pour garantir la conformité, le trafic vers les API Google (Cloud Storage, Vertex AI) est acheminé via Accès privé à Google. Cela permet de conserver le trafic entre les pods d'inférence et les services gérés par GCP sur le backbone du réseau Google, en contournant l'Internet public.
Sortie Les nœuds de travail GKE nécessitent un accès sortant pour extraire des images de conteneurs depuis Registre des artefacts. Nous acheminons ce trafic via NAT dans le cloud attachés aux sous-réseaux privés.
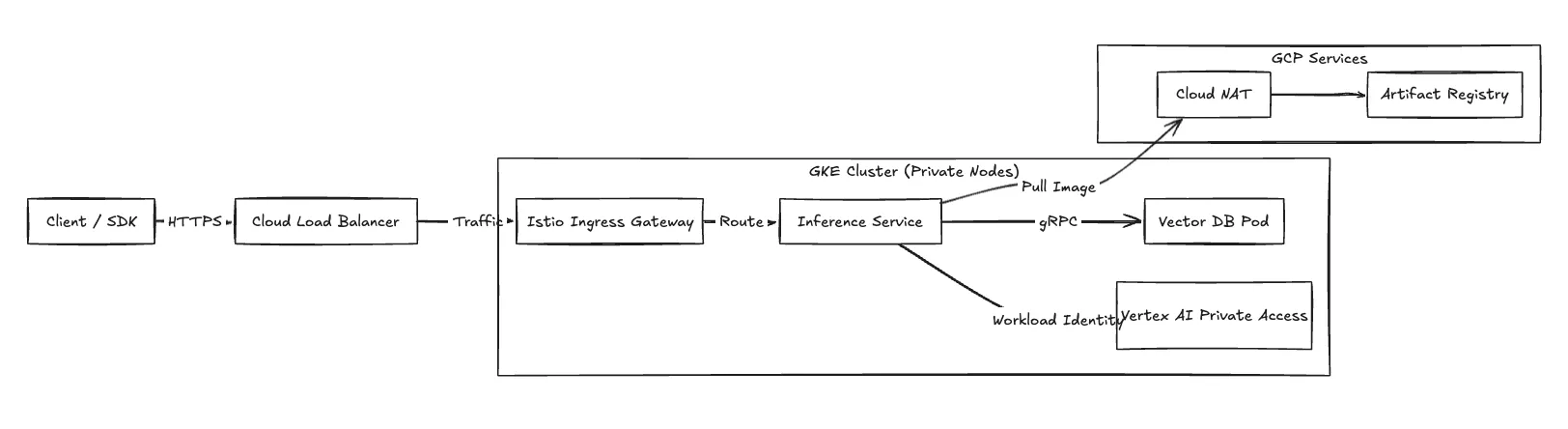
Figure 2 : Flux de trafic réseau détaillant l'entrée et la connectivité privée.
Nous appliquons la suppression des clés de compte de service statiques (fichiers .json). Implémente TrueFoundry Identité de la charge de travail GKE pour l'authentification de toutes les charges de travail.
La séquence d'authentification
Si un pod est compromis, le rayon d'explosion est strictement limité aux rôles IAM attribués à cette GSA spécifique.
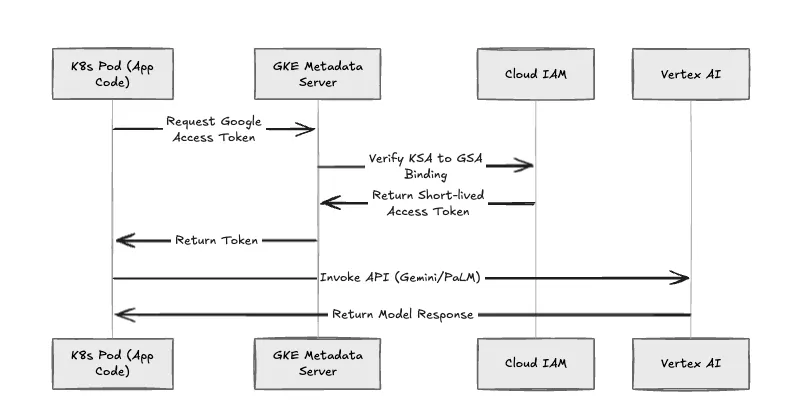
Figure 3 : Le flux d'authentification GKE Workload Identity.
Nous nous intégrons à Pools de nœuds GKE pour orchestrer les GPU NVIDIA et les TPU Cloud.
Orchestration en TPU La planification sur les TPU nécessite la gestion de contraintes topologiques spécifiques. TrueFoundry gère le NodeSelector et les tolérances requises pour planifier les pods sur des tranches en TPU (par exemple, v4-8, v5e). Nous injectons automatiquement les pilotes et les limites de ressources nécessaires dans le manifeste de déploiement, en faisant abstraction de la configuration Kubernetes de bas niveau.
Gestion des machines virtuelles Spot Pour les charges de travail de traitement par lots ou de développement, nous gérons Machines virtuelles Spot pour réduire les coûts (généralement de 60 à 90 % par rapport à la demande).
Gestion de clés distinctes pour des modèles tels que Gémeaux Pro crée des frais d'exploitation. TrueFoundry fournit une passerelle IA qui agit comme une interface API unifiée.
Cette intégration permet à votre équipe d'exploiter pleinement les avantages matériels de GCP, en particulier les TPU et les réseaux haut débit, sans s'enliser dans les difficultés opérationnelles liées à la gestion brute de Kubernetes. TrueFoundry agit comme un multiplicateur de force pour votre infrastructure : nous résumons la complexité de l'orchestration GKE tout en vous conférant une autorité absolue en matière de sécurité et de résidence des données. Cet équilibre vous permet d'opérationnaliser immédiatement les charges de travail GenAI, transformant ainsi l'infrastructure d'une contrainte en un avantage concurrentiel en termes de rapidité.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


