

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Il s'agit du hackathon d'IA interne de votre entreprise, et l'agent de codage d'un participant se retrouve bloqué dans une boucle de nouvelles tentatives involontaires. Il continue de lancer des requêtes contextuelles de longue durée vers un modèle coûteux pendant des heures.
Étant donné que les organisateurs ont distribué des clés de fournisseur brutes à chaque participant, il n'existe aucun contrôle au niveau de l'équipe sur les dépenses ou la rapidité des demandes. Lundi matin, un flux de travail galopant avait absorbé une grande partie du budget LLM partagé et avait mis l'organisation dans une situation difficile en matière de limites tarifaires.
Cette histoire est crédible parce qu'elle est plausible. Mais la véritable leçon est plus large : le bon modèle d'entreprise pour un hackathon est de ne pas distribuer les informations d'identification brutes des fournisseurs en espérant que les équipes se comportent bien. Il achemine chaque demande via une passerelle gouvernée qui peut séparer les équipes, associer une politique aux métadonnées et maintenir l'expérimentation dans le cadre d'un modèle opérationnel contrôlé.
TrueFoundry convient parfaitement à ce modèle car il combine les limites de l'espace de travail natif de Kubernetes, une indirection secrète, des contrôles de politique tenant compte des métadonnées, des barrières de sécurité pour les agents et un terrain de jeu natif pour les passerelles. L'affirmation la plus précise n'est pas qu'elle garantit « zéro fuite » ou une comptabilité parfaite et complète à chaque schéma de rafale. L'affirmation la plus solide et la plus défendable est qu'elle donne aux équipes des plateformes un plan de contrôle crédible pour organiser des hackathons sans les transformer en événements de coûts et de sécurité non gérés.

La première règle d'un hackathon sécurisé est simple : les participants ne devraient jamais avoir besoin de voir les clés d'API brutes du fournisseur. Une fois qu'une clé est copiée dans des blocs-notes, des environnements locaux ou des fichiers de configuration d'agent, cela devient à la fois un problème de sécurité et un problème de facturation.
Le modèle d'espace de travail de TrueFoundry est utile à cet égard, car l'isolation de l'espace de travail correspond aux limites de l'espace de noms Kubernetes. En pratique, cela signifie que les charges de travail d'un espace de travail s'exécutent dans un espace de noms différent de celui des charges de travail d'un autre espace de travail, et les informations d'identification des fournisseurs peuvent être exposées via des groupes secrets et des FQN secrets au lieu d'être collées directement dans les manifestes d'applications ou les fichiers source.
C'est la bonne architecture pour les équipes de hackathon. Donnez à chaque escouade un espace de travail, autorisez les charges de travail à accéder uniquement aux groupes secrets dont elles ont besoin et conservez les informations d'identification réelles du fournisseur sous le contrôle de la plateforme à tout moment. L'expérience utilisateur reste simple, mais le rayon d'explosion est plus petit et contrôlable.
La question opérationnelle la plus importante d'un hackathon basé sur l'IA n'est pas de savoir si vous pouvez évaluer les dépenses après coup. Il s'agit de savoir si la plateforme peut évaluer la politique sur le chemin de la demande avant qu'une charge de travail galopante ne devienne coûteuse.
Le plan de passerelle de TrueFoundry évalue l'authentification, le routage, les barrières, les limites de débit et la politique budgétaire sur le hot path en utilisant l'état en mémoire, ce qui permet d'appliquer une faible latence avant l'invocation du modèle. C'est nettement mieux qu'une conception dans laquelle la seule vue fiable des coûts est obtenue une fois les journaux traités en aval.
La partie particulièrement utile pour les hackathons est la définition de la portée des métadonnées. Au lieu de créer manuellement une règle par équipe, vous pouvez joindre l'identité de l'équipe dans x-tfy-metadata et appliquer la politique de manière dynamique avec des champs tels que metadata.project_id. Cela signifie qu'une règle budgétaire et une règle de limite de taux peuvent être réparties dans des compteurs isolés et des enveloppes de dépenses par équipe.
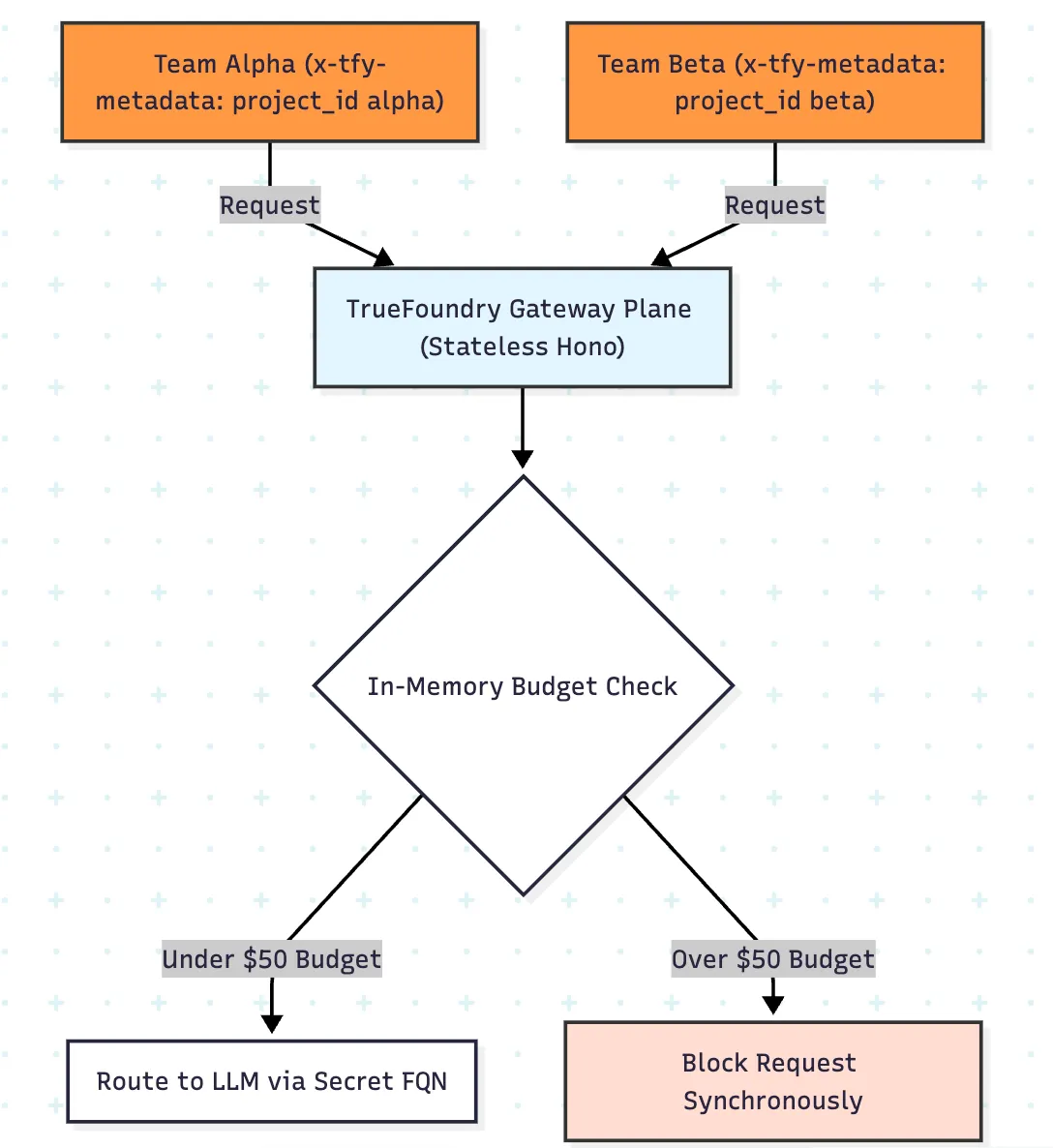
Les hackathons sont l'occasion pour les équipes d'essayer des serveurs MCP, des agents d'appel d'outils, des connecteurs de base de données et des API internes. C'est exactement là qu'un modèle de sécurité traditionnel réservé aux LLM commence à s'effondrer.
Le modèle de garde-corps de TrueFoundry est particulièrement pertinent ici car il expose quatre points d'exécution : entrée LLM, sortie LLM, pré-outil MCP et post-outil MCP. Les équipes de la plateforme disposent ainsi d'un moyen plus opérationnel de gérer les agents que de s'appuyer sur un seul filtre générique devant le modèle.
La distinction utile est que différents risques apparaissent à différents stades. Une injection rapide peut apparaître à l'entrée. Des arguments d'outil non sécurisés apparaissent avant l'exécution. Les enregistrements sensibles peuvent apparaître uniquement après le retour de l'outil. Un modèle à quatre crochets vous permet de placer la bonne commande au bon endroit dans le flux.
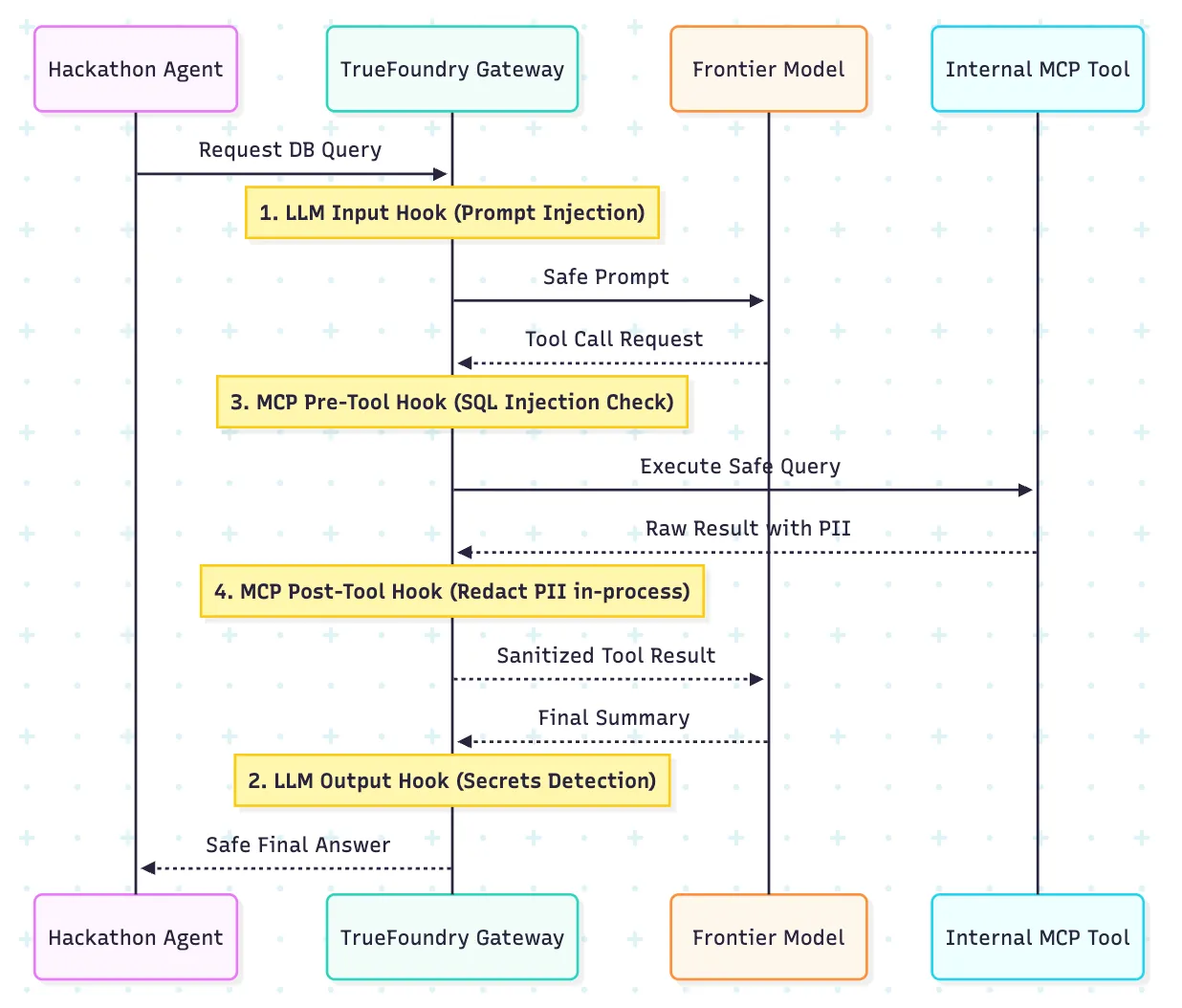
C'est également là que la détection en cours de fabrication est importante. Si l'analyse secrète et les vérifications associées peuvent être exécutées à l'intérieur du chemin de la passerelle sans dépendance sortante supplémentaire, il est plus facile de raisonner sur le modèle de contrôle lors d'un événement en direct. Maintenez des dispositifs de référence communs à toutes les équipes, puis définissez des politiques plus strictes pour les équipes qui utilisent des outils ou des ensembles de données sensibles.
Un hackathon sécurisé doit tout de même être rapide. Si les équipes ont besoin d'un ticket chaque fois qu'elles veulent essayer une invite, elles feront le tour de la plateforme. La réponse n'est pas moins de contrôle. La solution est de faire du chemin contrôlé le chemin le plus simple.
C'est là que le terrain de jeu natif de Gateway est important. L'avantage architectural utile est que le trafic de test peut passer par le même plan de passerelle que celui utilisé pour les politiques de production, afin que les équipes puissent valider les instructions, le routage et les garde-fous en boucle plutôt que de découvrir le comportement des politiques uniquement après le déploiement.
L'expérience des développeurs s'améliore également lorsque la plate-forme expose des signaux de débogage au niveau de la réponse. Les en-têtes tels que x-tfy-resolved-model et x-tfy-applied-configurations, ainsi que les ventilations temporelles des serveurs, aident les équipes à comprendre ce qui s'est réellement passé lors d'une demande de test au lieu de deviner si une règle de repli, de garde-fou ou de routage a été déclenchée.
Les lecteurs professionnels s'y opposeront immédiatement si un article exagère ses promesses en matière de résidence des données. Ils devraient. L'affirmation utile n'est pas que chaque déploiement est « isolé » comme par magie. En effet, la conception à plan divisé permet aux équipes de gérer le plan de passerelle sur leur propre infrastructure tout en maintenant un contrôle opérationnel plus strict sur le chemin actif pour l'inférence, les vérifications des politiques et l'accès aux modèles.
L'autre partie de l'histoire est celle de l'observabilité. Un hackathon est plus facile à gérer lorsque l'équipe de la plateforme peut voir rapidement les traces, la latence et le comportement des politiques. Mais l'observabilité est également une surface de gouvernance des données. Si des données d'invite ou de réponse sont exportées à des fins d'analyse, il doit s'agir d'un choix intentionnel assorti de contrôles de conservation et de destination appropriés.
L'histoire de la résidence se renforce lorsque vous décrivez explicitement le mode de déploiement, le comportement de journalisation et les chemins d'exportation. Cela renforce la confiance que de dire « zéro fuite » en espérant que le lecteur ne posera pas de questions complémentaires.
Oui. L'ajout d'un flux de travail explicite pour les propriétaires est une bonne idée. Il transforme le billet d'un commentaire sur l'architecture en un guide d'exécution.
1. Une semaine avant l'événement : définissez le modèle de contrôle
Créez un espace de travail par équipe ou par circuit de compétition. Décidez des modèles autorisés, du parcours du fournisseur par défaut, du budget par équipe, de la limite de taux par équipe et des équipes qui peuvent utiliser les outils MCP ou des données internes sensibles.
2. Avant le coup d'envoi : préchargez le chemin sécurisé
Publiez un petit kit de démarrage pour les participants : le point de terminaison de la passerelle, la forme de métadonnées requise, des exemples de fragments du SDK et un petit guide du terrain de jeu. Les équipes doivent partir de la voie gouvernée, et non des tableaux de bord bruts des fournisseurs.
3. Lors de l'inscription : attribuez un project_id à chaque équipe
Faites de project_id le champ de métadonnées requis dès le premier jour. Cela vous permet de segmenter les dépenses, d'effectuer un suivi plus précis, d'examiner les incidents de manière plus précise et de réduire le mappage manuel par la suite.
4. Pendant les heures de construction : surveillez l'événement comme un système en direct
Surveillez les dépenses au niveau de l'équipe, la pression liée aux limites tarifaires et les modèles de suivi inhabituels. L'objectif est de secourir rapidement les équipes, et pas seulement d'analyser les défaillances plus tard.
5. Pour les équipes d'agents : exiger une révision des outils avant un accès élargi
Si une équipe souhaite accéder à une base de données, à des serveurs MCP ou à des API internes, déplacez-la vers un profil de protection plus strict avant d'activer ces outils. Les expériences sur les agents devraient progressivement aboutir à une plus grande confiance, et non pas commencer là.
6. Avant les démonstrations : forcez l'obtention d'un dernier pass pour le terrain de jeu
Demandez à chaque équipe de valider son parcours final sur le terrain de jeu ou sur la surface d'essai officielle. Cela permet de détecter les métadonnées manquantes, le routage inattendu et les surprises avant la démo.
7. Après l'événement : transformez les observations en valeurs par défaut de la plateforme
Passez en revue les traces, les incidents budgétaires, les appels bloqués et les questions d'assistance. Convertissez ensuite les meilleures pratiques en modèles d'espace de travail par défaut, en extraits et en lignes de base de politiques pour le prochain hackathon.
La thèse de base de l'article original fonctionne toujours : si vous organisez un hackathon d'IA d'entreprise, le modèle le plus sûr est de ne pas distribuer de clés de fournisseur brutes. Il achemine les demandes via une passerelle capable de séparer les équipes, de mesurer les dépenses, de contrôler le débit et de régir les flux de travail des agents.
Ce qui rend la version révisée meilleure, c'est qu'elle le dit d'une manière qu'un acheteur sceptique peut croire. L'histoire la plus marquante de TrueFoundry en matière de hackathon n'est pas une vague promesse de sécurité totale. Il s'agit d'une combinaison pratique d'isolation de l'espace de travail, d'indirection secrète, de politique axée sur les métadonnées, de crochets d'agents gouvernés, de contrôles du chemin des demandes et d'un terrain de jeu qui aide les équipes à effectuer des tests sur la même surface de politique que celle par laquelle elles expédieront.
Cela suffit. Vos hackers peuvent toujours construire le futur. Vos équipes chargées de la plateforme, de la sécurité et des finances n'ont tout simplement pas à perdre un week-end.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


