

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 26, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les outils de codage de l'IA font désormais partie du développement quotidien. Les développeurs utilisent des produits tels que Claude Code, Cline, Cursor, Gemini CLI, OpenAI Codex CLI, Qwen Code CLI, Roo Code et Goose pour générer du code, refactoriser, déboguer et expliquer de grandes bases de code directement depuis l'éditeur ou le terminal. Dans la plupart des entreprises, le problème n'est pas l'adoption. Le problème, c'est la gouvernance. Chaque outil peut communiquer avec un ou plusieurs fournisseurs de modèles. Chaque outil stocke souvent les clés localement. Les équipes se retrouvent rapidement avec des dizaines de points d'entrée non gérés vers des modèles externes. Cela crée un réel risque en ce qui concerne les modèles approuvés, l'endroit où le code et le contexte sont envoyés, la manière dont les dépenses sont attribuées et la manière dont les incidents sont examinés. Cela rend également la fiabilité plus difficile car le routage et les solutions de secours ne sont pas cohérents entre les outils.
Si vous essayez de résoudre ce problème manuellement, vous finissez généralement par créer un proxy interne vers lequel pointent tous les IDE et CLI. Ce proxy a besoin d'authentification, d'autorisation, de listes d'autorisations de modèles approuvés, de routage des fournisseurs, de journaux d'audit, de limites de débit, de contrôles budgétaires et d'observabilité. Il doit également être compatible avec les API attendues par ces outils. De nombreux outils utilisent une API compatible avec OpenAI, mais ils présentent également des particularités en matière de dénomination des modèles et de comportements spéciaux que vous devez gérer.
Voici un petit exemple factice qui montre pourquoi cela devient un véritable travail d'ingénierie. Il n'est pas prêt pour la production. Il vise uniquement à montrer la forme du problème.
depuis fastapi import FastAPI, Request, HttpException
heure d'importation
importer httpx
app = FastAPI ()
MODÈLES_APPROUVÉS = {
« gpt-4o » : {"provider » : « openai », « target » : « gpt-4o"},
« claude-3-5-sonnet » : {"provider » : « anthropique », « cible » : « claude-3-5-sonnet"},
}
OPENAI_URL = « https://api.openai.com/v1/chat/completions »
URL_ANTHROPIQUE = « https://api.anthropic.com/v1/messages »
def verify_token (auth_header : str) -> dict :
# En réalité, il s'agit d'une validation JWT par rapport à Okta ou à votre IdP.
si ce n'est pas auth_header ou si ce n'est pas auth_header.startswith (« Bearer ») :
lever HTTPException (status_code=401, detail="jeton manquant »)
return {"user » : « alice », « team » : « plateforme"}
@app .post (« /v1/chat/completions »)
async def chat_completions (exigence : requête) :
user_ctx = verify_token (req.headers.get (« autorisation »))
body = wait req.json ()
model = body.get (« modèle »)
si le modèle ne figure pas dans APPROVED_MODELS :
lever HTTPException (status_code=403, detail="modèle non approuvé »)
route = APPROVED_MODELS [modèle]
commencé = time.time ()
async avec Httpx.AsyncClient (timeout=60) comme client :
si route ["provider"] == « openai » :
en amont = attend client.post (
OPENAI_URL,
headers= {"Autorisation » : « Porteur" + « UPSTREAM_OPENAI_KEY"},
json= {**body, « modèle » : route ["cible"]},
)
autre :
# Vous aurez également besoin de transformations de demande et de réponse ici.
en amont = attend client.post (
URL_ANTHROPIQUE,
headers= {"x-api-key » : « UPSTREAM_ANTHROPIC_KEY"},
json= {"model » : route ["cible"], « messages » : body.get (« messages », [])},
)
latency_ms = int ((time.time () - démarré) * 1000)
# En réalité, vous émettriez des traces OpenTelemetry et des journaux structurés ici.
print (« llm_request », {"utilisateur » : user_ctx ["utilisateur"], « modèle » : modèle, « latency_ms » : latency_ms})
return upstream.json ()
Même dans cette version simplifiée, vous pouvez voir les pièces manquantes. Vous avez toujours besoin de transformations robustes entre les fournisseurs, d'une prise en charge du streaming, de nouvelles tentatives, de solutions de secours, d'en-têtes de transmission sécurisés, d'une définition du périmètre des locataires et des équipes et de journaux d'audit durables. Vous avez également besoin d'un système de configuration qui s'adapte à toutes les équipes.
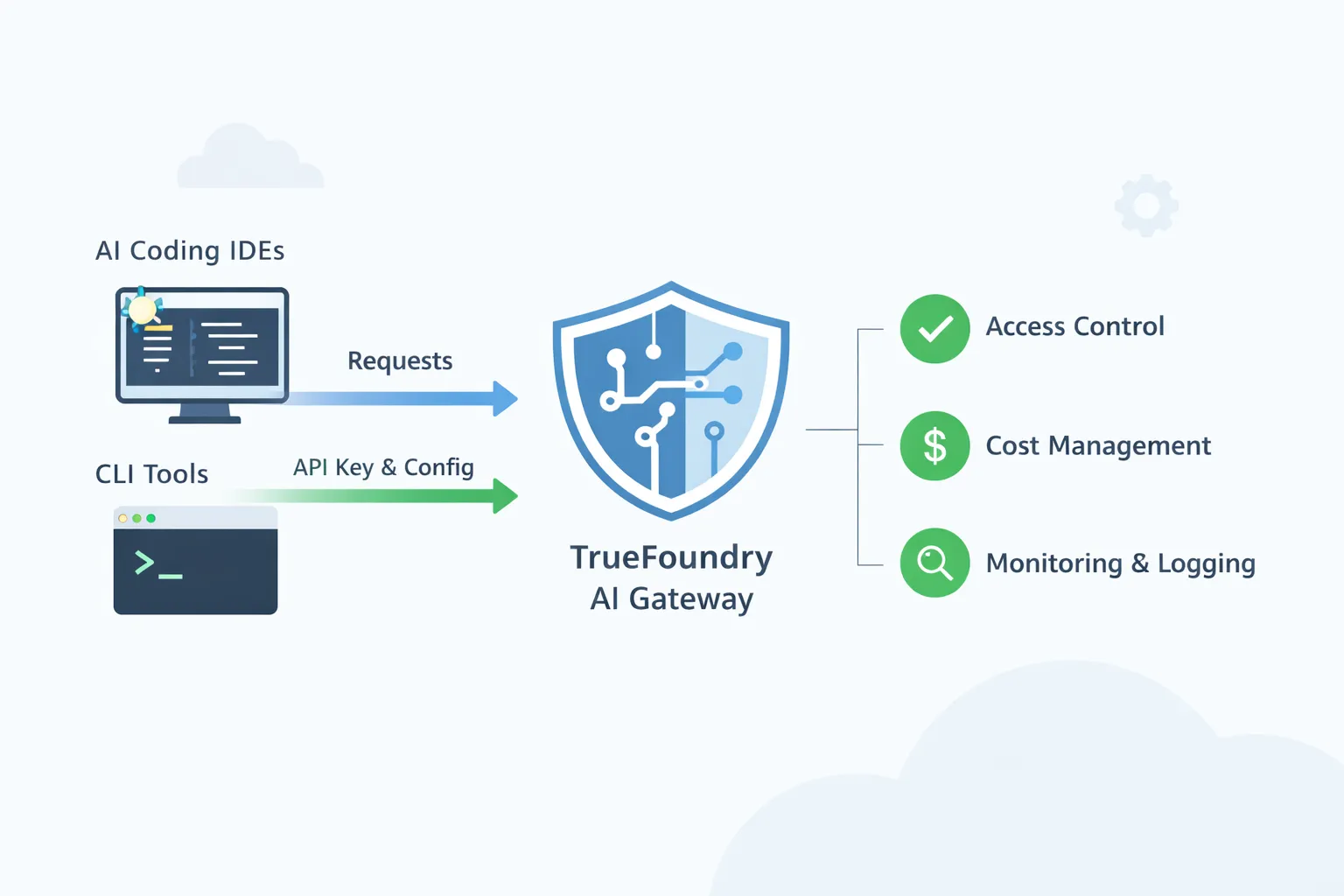
TrueFoundry AI Gateway est conçu pour être ce point de contrôle partagé. Les IDE et les CLI continuent d'utiliser les flux de travail que les développeurs apprécient déjà, mais le trafic est acheminé via une passerelle gérée unique. La passerelle devient l'endroit où les équipes de la plateforme appliquent l'accès approuvé aux modèles, appliquent les politiques et obtiennent une visibilité complète sur l'utilisation.
L'un des thèmes principaux des guides de l'IDE est simple. Vous extrayez l'URL de base et le nom du modèle depuis le terrain de jeu TrueFoundry AI Gateway. Vous configurez ensuite l'IDE ou la CLI pour utiliser cette URL de base et un jeton TrueFoundry.
La plupart des IDE de codage IA et des outils de bureau peuvent être redirigés vers un seul point de terminaison compatible avec OpenAI. La passerelle TrueFoundry AI vous offre ce point de terminaison. Vous commencez dans le terrain de jeu Gateway et vous copiez l'extrait unifié. Cet extrait vous donne l'URL de base et le nom du modèle que vous devez utiliser. Vous ouvrez ensuite les paramètres de l'IDE et sélectionnez une option de fournisseur qui prend en charge une URL de base personnalisée. De nombreux outils le qualifient de compatible avec OpenAI. Vous collez l'URL de base de Gateway. Vous collez un jeton TrueFoundry comme clé d'API. Le jeton peut être un jeton personnel pour un développeur ou un jeton de compte virtuel pour une utilisation partagée ou automatisée. TrueFoundry documente les deux options et recommande le jeton de compte virtuel pour une utilisation en mode production. Pour en savoir plus, cliquez ici
Certains IDE fonctionnent mieux lorsqu'ils voient des noms de modèles standard courts tels que gpt 4o. Les noms de modèles TrueFoundry sont souvent complets. La solution recommandée consiste à définir une règle de routage ou d'équilibrage de charge dans la passerelle afin que l'IDE continue à utiliser le nom abrégé pendant que la passerelle le mappe au modèle cible entièrement qualifié. Le curseur et le Codex documentent tous deux ce modèle car leur logique interne est liée aux noms de modèles standard. Curseur-Docs
Il peut également y avoir des contraintes de réseau. Cursor indique que son flux de requêtes peut impliquer des serveurs Cursor. Cela signifie que l'URL de la passerelle doit être accessible depuis l'infrastructure Cursor. En pratique, le point de terminaison Gateway doit être accessible au public pour que Cursor fonctionne comme décrit dans le guide.
Les outils CLI s'intègrent généralement via des variables d'environnement ou un fichier de configuration local. Pour les CLI compatibles avec OpenAI, le modèle courant consiste à définir OPENAI_BASE_URL sur le point de terminaison TrueFoundry Gateway et à définir OPENAI_API_KEY sur un jeton TrueFoundry. TrueFoundry décrit cela comme une approche d'authentification prise en charge pour la passerelle. Lire la suite : Authentification
Certaines CLI utilisent des variables spécifiques au fournisseur. La CLI Gemini utilise une URL de base Gemini et une clé API Gemini. Le guide TrueFoundry montre que vous définissez GOOGLE_GEMINI_BASE_URL sur une URL proxy TrueFoundry Gemini et que vous définissez GEMINI_API_KEY sur un jeton TrueFoundry afin que chaque demande passe par la passerelle. En savoir plus : Gemini-CLI
Les autres CLI s'appuient sur un fichier de paramètres json. Claude Code est configuré via un fichier settings.json qui définit les valeurs d'environnement pour l'URL de base et les en-têtes d'authentification. Le guide TrueFoundry montre ANTHROPIC_BASE_URL pointant vers la passerelle et utilise un jeton Bearer dans les en-têtes personnalisés afin que le trafic Claude Code soit régi via la passerelle. En savoir plus : Code Claude
Certains outils nécessitent également le mappage de noms standard mentionné précédemment. Le guide CLI du Codex explique que le Codex attend des noms de modèles standard et peut se comporter mal avec des noms complets. Il recommande d'utiliser le routage Gateway afin d'appeler gpt 5 dans la CLI pendant que la passerelle achemine vers le modèle complet approprié en arrière-plan. Lire la suite : Codex
L'approbation des modèles et le contrôle d'accès constituent les besoins de gouvernance les plus fondamentaux lorsque les outils de codage d'IA sont répandus dans une entreprise. Un développeur peut installer Cursor ou Cline en quelques minutes et le diriger vers n'importe quel fournisseur de modèles. Sans passerelle, l'entreprise se retrouve avec de nombreux chemins non gérés où le contexte du code et les invites peuvent quitter le réseau à l'aide de clés personnelles. Avec TrueFoundry AI Gateway, vous créez un petit catalogue approuvé de modèles autorisés à coder et vous associez ces modèles à des équipes ou à des groupes d'utilisateurs. Les développeurs continuent à utiliser le même IDE qu'ils préfèrent, mais chaque demande passe par la passerelle, de sorte qu'une demande vers un modèle non approuvé est bloquée. Cela permet également de séparer les accès par niveau de risque. Un ingénieur débutant peut avoir accès à un modèle moins cher pour des modifications rapides, tandis qu'un ingénieur du personnel ou une équipe chargée des incidents de production peut accéder à un modèle plus puissant pour les débogage difficiles. L'important est que l'approbation soit appliquée de manière centralisée au lieu de demander à chaque développeur de suivre un document de politique.
La maîtrise des coûts devient importante car les outils de codage d'IA peuvent générer de grands volumes de jetons sans que personne ne s'en aperçoive. Un seul développeur utilisant un agent qui itère sur une base de code peut créer des centaines, voire des milliers d'appels dans un court laps de temps. Sans passerelle, les dépenses sont réparties entre les clés personnelles et les comptes fournisseurs, de sorte que le service financier voit une facture mais ne peut pas savoir quelle équipe ou quelle application l'a pilotée. Avec une passerelle, vous pouvez émettre des jetons basés sur l'identité et demander à chaque session IDE ou CLI de s'authentifier à l'aide de l'identité d'un utilisateur ou d'un service. Cela vous permet d'attribuer l'utilisation à une personne, à une équipe ou à un outil interne. Une fois que l'attribution existe, les contrôles deviennent pratiques. Vous pouvez définir des budgets pour une équipe pendant un mois et vous pouvez définir des limites tarifaires afin d'éviter des boucles incontrôlables accidentelles. Si un outil lance des demandes de spam, la passerelle peut le limiter au lieu de le laisser épuiser son budget en silence.
La réponse aux incidents et l'audit sont les domaines dans lesquels les équipes de la plateforme ressentent la différence au quotidien. Lorsqu'un développeur indique que l'assistant est lent ou défaillant, il est difficile de le déboguer si le trafic passe directement d'un ordinateur portable à un fournisseur. Vous ne savez peut-être pas si le problème provient du fournisseur, du réseau, d'un nom de modèle mal configuré ou d'un paramètre spécifique à un outil. Lorsque les demandes passent par la passerelle, l'équipe de la plateforme peut examiner les métriques et les journaux de la passerelle pour savoir quel modèle a été appelé, à quoi ressemblait la latence, quelles erreurs se sont produites et si les défaillances sont liées à un fournisseur ou à une région. C'est également la base des exigences en matière d'audit. Les équipes chargées de la sécurité et de la conformité demandent souvent où le contexte du code a été envoyé et qui y a eu accès. Une passerelle peut conserver une trace des destinations qui ont été utilisées et des personnes qui les ont invoquées. Il peut également prendre en charge des politiques qui réduisent les risques, telles que le masquage des chaînes sensibles avant que les demandes n'atteignent des fournisseurs externes ou l'interdiction pour certaines équipes d'envoyer des invites à des terminaux externes.
La fiabilité en cas de problèmes avec les fournisseurs est importante car les fournisseurs de modèles sont soumis à des ralentissements et à des délais d'attente périodiques. Les outils de codage de l'IA sont particulièrement sensibles car ils sont interactifs. Quelques temps d'attente peuvent donner l'impression que l'outil ne fonctionne pas et les développeurs passeront à ce qui fonctionne. De nombreux IDE prennent également certains noms de modèles. Le curseur et les outils similaires fonctionnent souvent mieux lorsque le nom du modèle ressemble à un nom de style OpenAI standard. Si vous changez de fournisseur, vous devez normalement modifier la configuration de chaque développeur. Grâce au routage par passerelle, vous pouvez conserver le même nom de modèle dans les paramètres de l'IDE et modifier son mappage en arrière-plan. Si le délai d'un fournisseur expire, vous pouvez effectuer un routage vers un autre fournisseur ou vers un autre compte ou une autre région. Le développeur continue à utiliser la même configuration IDE et il voit simplement que l'outil continue de fonctionner. Cela est également utile lorsque vous souhaitez déployer un nouveau modèle. Vous pouvez transférer progressivement le trafic vers le nouveau modèle tout en préservant la stabilité de l'expérience utilisateur, et vous pouvez revenir rapidement en arrière si la qualité ou la latence ne sont pas acceptables.
Les IDE de codage IA accélèrent les développeurs. Les entreprises ont besoin du même niveau de gouvernance que celui qu'elles appliquent déjà au contrôle des sources et aux systèmes CI. La solution pratique consiste à centraliser le contrôle sans obliger les développeurs à changer d'outil. TrueFoundry AI Gateway est conçu pour se situer dans ce point de contrôle. Les guides d'intégration de Claude Code, Cline, Cursor, Gemini CLI, OpenAI Codex CLI, Qwen Code CLI, Roo Code et Goose suivent tous le même principe. Conservez le flux de travail des développeurs. Centralisez les politiques, la visibilité et le contrôle au niveau de la passerelle.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


