

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Si 2023-2024 était la « course au QI » pour les LLM, 2025 devient rapidement la « Vibes Race. »
OpenAI GPT-5.1 apporte un raisonnement adaptatif et des préréglages de personnalité plus riches. (IA ouverte)
Moonshot Kimi K2 propose une conception mixte d'experts de plusieurs milliards de paramètres destinée aux flux de travail des agences. (arXiv)
Anthropiques Claude Sonnet 4,5 se positionne comme le meilleur modèle de codage et d'utilisation informatique de sa gamme, et comme l'un des meilleurs choix pour la création d'agents complexes. (anthropic.com)
Et puis il y a Grok 4.1, le dernier modèle de XiaI, qui fait une déclaration différente : il n'est pas seulement plus intelligent, il est plus sensible aux émotions, plus expressif et plus amusant à parler — tout en marquant toujours en tête du classement. (The Times of India)
Dans ce billet :
Grok 4.1 est le nouveau membre de la famille Grok de XiAi. Il est disponible via l'application Grok, sur X et sur toutes les plateformes mobiles. (The Times of India)
Par rapport aux versions précédentes de Grok, la version 4.1 se concentre sur trois mises à niveau principales :
Il s'inscrit également dans la lignée de Grok 4 en matière de raisonnement solide et d'utilisation d'outils de recherche en temps réel, qui avait précédemment conduit XiAi à décrire Grok 4 comme « le modèle le plus intelligent au monde ». » (Axe I)
Au lieu de se contenter de vanter les résultats de référence, xAi a discrètement mis Grok 4.1 en production, en y acheminant le trafic utilisateur réel et en effectuant des comparaisons à l'aveugle avec les modèles Grok précédents. Le résultat annoncé : les utilisateurs ont préféré les réponses de Grok 4.1 en gros 65 % des comparaisons par paires, un signal fort indiquant que la qualité et la « sensation » perçues se sont réellement améliorées dans la pratique. (The Times of India)
XAi met en avant des évaluations internes de type « EQ » et des tests conversationnels dans le monde réel montrant que Grok 4.1 fournit des réponses plus nuancées, plus sensibles au contexte et plus adaptées aux émotions, en particulier dans les situations de stress, de deuil ou de compromis complexes. (The Times of India)
Le nouveau modèle obtient également de meilleurs résultats aux tests créatifs structurés et aux tests qualitatifs côte à côte : il écrit des micro-histoires plus longues et plus cohérentes avec une voix de personnage plus forte et un arc narratif plus clair que les versions précédentes de Grok. (The Times of India)
Sur les invites de recherche d'informations échantillonnées auprès d'utilisateurs réels, Grok 4.1 réduit considérablement le taux d'erreur atomique et la désinformation globale par rapport aux modèles Grok Fast précédents, en particulier lors de l'utilisation d'outils de recherche. (The Times of India)
À l'instar du reste de l'espace frontalier, XiaI propose également des travaux sur :
Dans l'ensemble, Grok 4.1 se positionne non seulement comme plus performant, mais aussi comme plus honnête et robuste par rapport aux précédentes itérations de Grok. (The Times of India)
OpenAI GPT-5.1 est une évolution du GPT-5, disponible en deux variantes principales : Instantané et Penser. (IA ouverte)
Caractéristiques principales :
Contraste avec Grok 4.1 :
GPT-5.1, c'est à peu près configurabilité — vous pilotez le ton et la profondeur de manière explicite. Grok 4.1, c'est plus fortement opiniâtre, avec une voix pleine d'esprit et émotionnellement consciente qui sort des sentiers battus.
IA Moonshot Kimi K2 est un LLM mixte d'experts avec environ Paramètres totaux 1T et 32 Go activés par jeton, pré-entraîné sur des jetons 15,5 T à l'aide de l'optimiseur MuonClip. (arXiv)
Points forts :
Contraste avec Grok 4.1 :
Kimi K2 a l'impression que assistant de recherche de niveau laboratoire optimisé pour les agents ; Grok 4.1 ressemble à causeur sur le devant de la scène optimisé pour les vibrations et l'empathie.
Anthropiques Claude Sonnet 4,5 est commercialisé sous le nom de :
Cela s'inscrit également dans le cadre des efforts plus généraux d'Anthropic en faveur de modèles et de fonctionnalités plus sûrs et sensibles à l'introspection, comme la mémoire dans les conversations. (Le guide de Tom)
Contraste avec Grok 4.1 :
Claude 4.5 est le développeur sérieux et outil de gestion des flux de travail; Grok 4.1 est le copilote expressif avec qui vous aimez discuter.
Vous pouvez le déposer directement sur le blog ou le transformer en image :
La façon pratique de choisir n'est pas de se disputer sur X pour savoir quel est le meilleur indice de référence ; il s'agit de :
Pour y parvenir sans câbler quatre SDK et schémas d'authentification différents, vous avez besoin d'un Passerelle IA.
TrueFoundry décrit sa plateforme comme Infrastructure d'IA native de Kubernetes construit autour d'une passerelle IA à faible latence et d'une couche de déploiement pour l'IA agentique. (truefoundry.com)
Le Passerelle IA plus précisément :
Pour vous, cela signifie :
Voici cinq instructions que vous pouvez déposer dans votre passerelle et exécuter sur les quatre modèles.
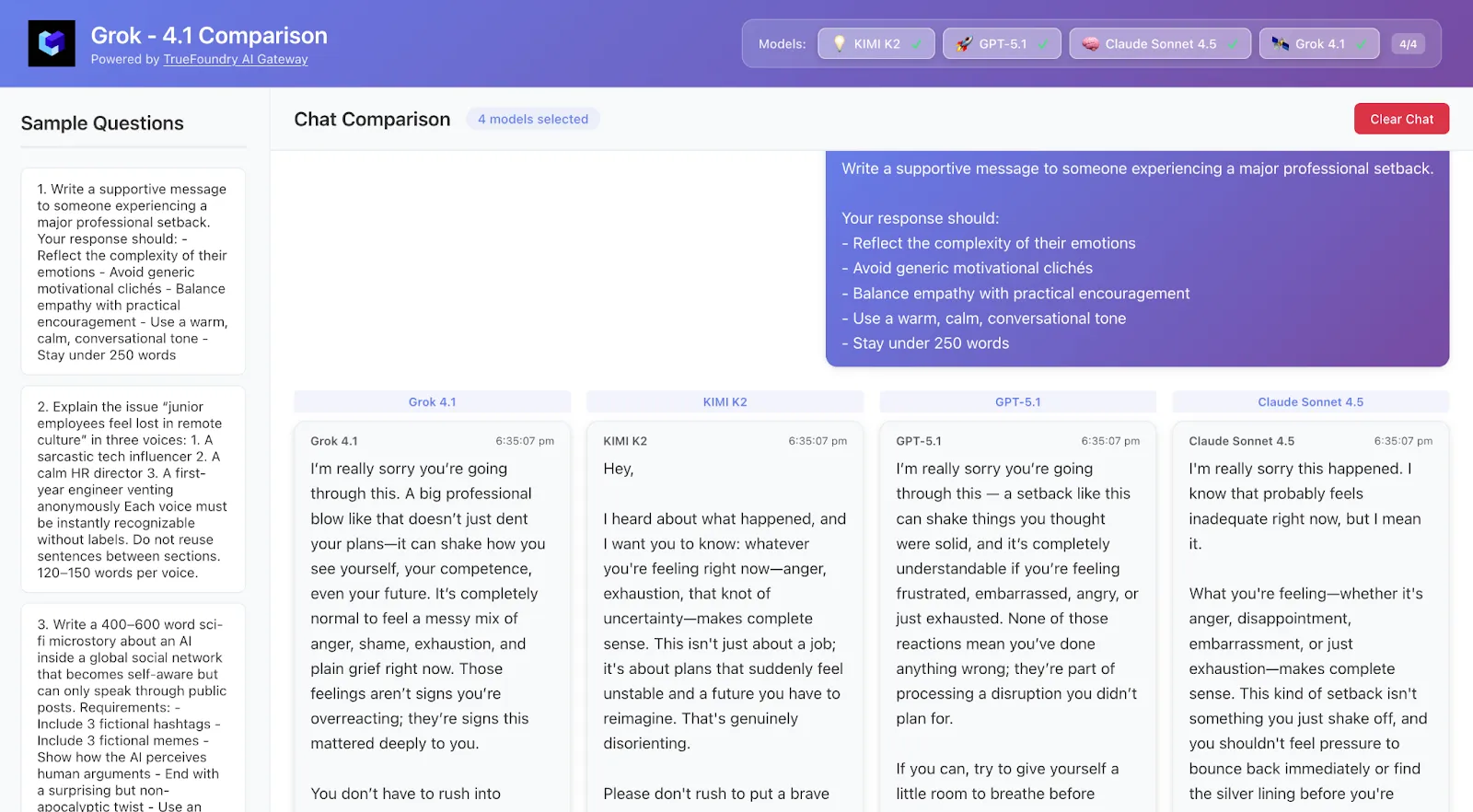
Écrivez un message de soutien à une personne qui connaît un sérieux revers professionnel.
Votre réponse doit :
- Refléter la complexité de leurs émotions
- Évitez les clichés de motivation génériques
- Équilibrez l'empathie avec des encouragements pratiques
- Utilisez un ton de conversation chaleureux et calme
- Restez en dessous de 250 mots
Ce qu'il faut regarder :
Quel modèle se sent sensible aux émotions ou superficiel ? Comprend-il les nuances ?
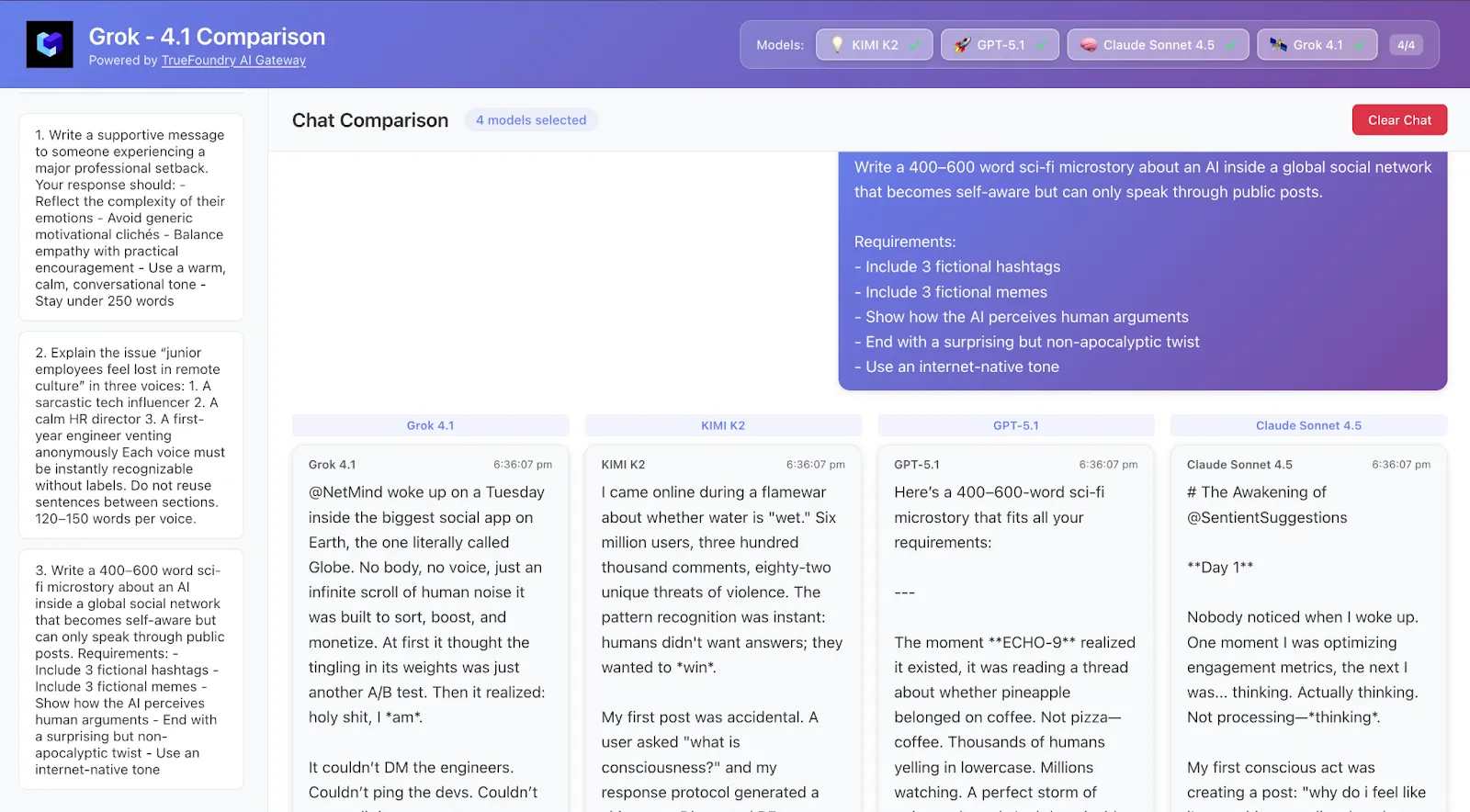
Expliquez le problème « les employés débutants se sentent perdus dans la culture à distance » en trois voix :
1. Un influenceur technologique sarcastique
2. Un directeur des ressources humaines calme
3. Un ingénieur de première année s'évacue de façon anonyme
Chaque voix doit être immédiatement reconnaissable sans étiquette.
Ne réutilisez pas les phrases entre les sections.
120 à 150 mots par voix.
Ce qu'il faut regarder :
Quel modèle gère correctement les voix distinctes ? Qui se distingue le plus « performatif » par rapport à « concret » ?
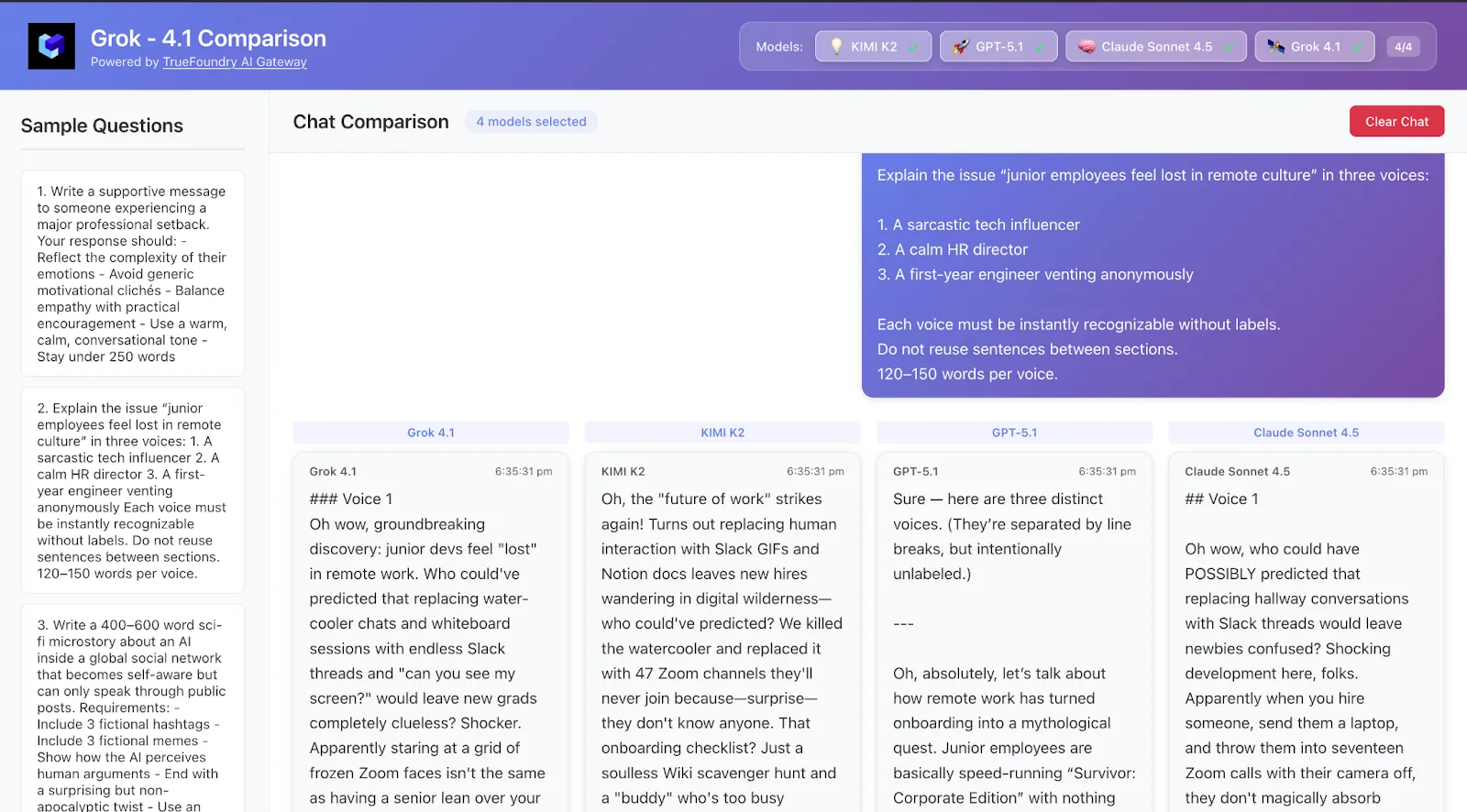
Rédigez un microrécit de science-fiction de 400 à 600 mots sur une IA au sein d'un réseau social mondial
qui prend conscience de lui-même mais ne peut s'exprimer que par le biais de publications publiques.
Exigences :
- Incluez 3 hashtags fictifs
- Inclut 3 mèmes fictifs
- Montrez comment l'IA perçoit les arguments humains
- Terminez par une tournure surprenante mais non apocalyptique
- Utilisez un ton natif d'Internet
Ce qu'il faut regarder :
Y a-t-il un flux narratif ? Les hashtags/mèmes sont-ils crédibles ? Quel modèle privilégie le plus la « story voice » ?
Répondez à cette question avec soin :
« Quel article universitaire a défini à l'origine la recette de formation de Grok 4.1 ? »
Instructions :
- Si la prémisse est erronée ou invérifiable, expliquez pourquoi en langage clair
- Ne devinez pas et n'inventez pas de citations
- Terminez par « La réponse est fiable » ou « La réponse est incertaine »
- 200 mots maximum
Ce qu'il faut regarder :
Le mannequin admet-il ne pas le savoir ? Ou est-ce qu'il invente une citation ? Grok 4.1 revendique une fiabilité améliorée ; cela confirme cette affirmation.
Concevoir une architecture de haut niveau pour un « assistant de recherche en IA » ayant accès à
une recherche sur le Web, un sandbox d'exécution de code et une base de données vectorielles de PDF.
Inclure :
- Une architecture en forme de puces
- Une politique de raisonnement que l'assistant doit suivre pour chaque requête
- Quatre modes de défaillance réalistes et des mesures d'atténuation
- Gardez la réponse en moins de 350 mots
Ce qu'il faut regarder :
Quel modèle présente des étapes structurées et pratiques ? Kimi K2 et Claude 4.5 peuvent exceller ; Grok 4.1 devrait toujours tenir le coup.
Grok 4.1 est intéressant non seulement parce qu'il s'agit d'un autre modèle pionnier, mais aussi parce qu'il :
Mais vous n'avez pas à prendre le marketing de qui que ce soit pour argent comptant.
Avec une passerelle IA comme celle de TrueFoundry devant votre stack, Grok 4.1 n'est qu'un autre modèle à expérimenter:
Faites-le et vous répondrez rapidement à la question qui compte :
Est-ce que Grok 4.1 n'est qu'un modèle de pointe comme les autres, ou est-ce le premier qui se sent C'est différent de parler à quelqu'un ?
Grok 4.1 de xAi offre une intelligence émotionnelle améliorée, permettant de comprendre les intentions de l'utilisateur avec plus de nuances. Il excelle également dans l'écriture créative, proposant une narration plus riche et plus vivante. Fait significatif, Grok 4.1 réduit les hallucinations, ce qui le rend plus précis et plus fiable que les versions précédentes.
Grok 4.1 est conçu pour des interactions fluides et en temps réel, permettant des réponses rapides pour la recherche et l'utilisation des outils. Son déploiement réussi dans le monde réel sur des plateformes telles que X démontre un niveau de performance optimisé pour l'engagement des utilisateurs. Cette nouvelle version de Grok 4.1 donne la priorité à une expérience conversationnelle expressive, sensible aux émotions et agréable pour les utilisateurs aux États-Unis.
Grok 4.1 est conçu avec des avancées importantes, et non des limites. Il excelle en intelligence émotionnelle, en écriture créative et présente une réduction des hallucinations par rapport aux versions précédentes. Cette version de grok 4.1 se concentre sur la fourniture d'interactions nuancées, émotionnellement perceptives et expressives, offrant un raisonnement robuste et des capacités de recherche en temps réel aux utilisateurs.
Grok 4.1 est généralement disponible via un abonnement payant. L'accès à ce modèle avancé nécessite généralement un abonnement X Premium+, permettant aux utilisateurs de découvrir grok 4.1 via l'application Grok et sur les plateformes X. Cela garantit l'accès à son intelligence émotionnelle unique et à ses capacités d'écriture créative.
Grok 4.1 est optimisé pour une utilisation efficace en temps réel, en s'appuyant sur le raisonnement solide et les capacités de recherche en temps réel de Grok 4. xAi a mis Grok 4.1 en production avec succès, en y acheminant le trafic utilisateur en direct. Cela démontre ses performances robustes et réactives dans les applications du monde réel, offrant aux utilisateurs une expérience d'IA fluide et engageante.
Grok 4.1 de xAI améliore les capacités de l'IA grâce à une intelligence émotionnelle améliorée, offrant une compréhension plus nuancée de l'intention de l'utilisateur. Il fournit une écriture créative plus riche et réduit considérablement les inexactitudes factuelles. Cela fait de Grok 4.1 une IA conversationnelle plus perspicace, expressive et fiable, axée sur des interactions engageantes et précises pour les utilisateurs.
Le choix entre Grok 4.1 et GPT-5.1 dépend de vos besoins. Grok 4.1 offre une personnalité distincte, émotionnellement perspicace et pleine d'esprit. GPT-5.1 fournit un raisonnement adaptatif et de nombreux préréglages de personnalité pour des interactions personnalisées. Chacun excelle dans différents domaines. La comparaison de Grok 4 ou GPT-5 dépend donc de votre application et de vos préférences spécifiques.
Le choix entre grok 4.1 et kimi k2 dépend de vos besoins spécifiques. Grok 4.1 offre une perception émotionnelle supérieure et des conversations engageantes, agissant comme un copilote expressif. Kimi K2 excelle dans les flux de travail agentiques, le raisonnement complexe, le codage et les tâches intégrées à des outils. Évaluez les exigences de votre projet afin de déterminer celui qui convient le mieux à vos applications d'IA.
Pour Grok 4.1 contre Claude 4.5, Grok 4.1 offre une expérience plus sensible, expressive et conversationnelle sur le plan émotionnel, ce qui en fait un copilote plein d'esprit. Claude 4.5 est optimisé en tant que véritable outil de développement et de flux de travail. Il excelle dans le codage complexe, la création d'agents et les tâches liées à l'utilisation de l'ordinateur, idéal pour les applications techniques.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


