Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
GenAI en tant que service pour les entreprises
Published: April 22, 2026
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Gère plus de 350 RPS sur un seul processeur virtuel, aucun réglage n'est nécessaire
Prêt pour la production avec un support complet pour les entreprises
Pour les ingénieurs de plateforme, GenAI as a Service signifie la création d'un système qui permet à différentes équipes (data scientists, développeurs d'applications et utilisateurs professionnels) d'accéder, de déployer et d'expérimenter des modèles d'IA de manière fluide sans se soucier des goulots d'étranglement liés à l'infrastructure et aux opérations.
Bien que l'idée de GenAI semble passionnante, la réalité est que les équipes des plateformes sont soumises à une pression immense pour fournir une infrastructure d'IA évolutive, rentable et sécurisée. Ils sont confrontés à des délais serrés, à l'évolution des besoins des entreprises et à des modèles d'IA en évolution rapide, faisant du déploiement de GenAI une cible en constante évolution.
Le principal défi : la prolifération des modèles et la complexité de l'infrastructure
L'un des principaux maux de tête pour les équipes chargées des plateformes est que les modèles sont en train de devenir une marchandise. Toutes les quelques semaines, de nouveaux LLM améliorés, des modèles d'intégration et des reclasseurs, etc. sont publiés. Les équipes commerciales souhaitent les intégrer immédiatement, mais cela constitue un véritable cauchemar pour la planification de l'infrastructure.
Comment échanger et échanger des LLM sans perturber les applications existantes ?
Comment vous assurer que les différentes équipes ont accès au bon modèle sans dupliquer les efforts ?
Comment faire en sorte que les modèles fonctionnent de manière rentable lorsque les ressources GPU sont limitées ?
Les entreprises ont besoin d'un système centralisé qui fasse abstraction de ces complexités, permettant aux équipes de consommer des services d'IA sans interrompre l'infrastructure.
Défis liés à l'opérationnalisation de GenAI en tant que service
Ready to Build With GenAI? Start With TrueFoundry.
TrueFoundry gives you everything you need to build, deploy, and scale generative AI applications across open and closed-source models. From a unified API layer and prompt management to full observability and self-hosted deployment, it’s the enterprise-grade GenAIaaS platform built for developers.
Le déploiement de modèles GenAI en interne est bien plus complexe que l'exécution d'une application logicielle standard -
Prise en charge de divers modèles
Prise en charge de plusieurs modèles open source (par exemple, Llama) et de modèles d'API propriétaires (par exemple, OpenAI, Anthropic).
Les entreprises doivent prendre en charge divers modèles tels que les modèles d'intégration, les reclassement, etc. pour différentes tâches.
Déploiement multicloud et sur site: Les entreprises ont besoin de flexibilité pour déployer des modèles auprès de fournisseurs de cloud (AWS, GCP, Azure) ou sur site, en fonction des coûts, de la conformité et de la disponibilité du GPU
L'orchestration du GPU n'est pas triviale: Kubernetes, Ray et Slurm sont souvent nécessaires pour allouer dynamiquement les GPU. De plus, le passage d'un fournisseur à un autre (par exemple, d'AWS A100 à GCP TPU) nécessite un travail personnalisé.
Conteneurisation et orchestration: Sans conteneurisation des modèles, les équipes sont confrontées à des incohérences de dépendance, à des conflits logiciels et à des problèmes de version. Cela a également apporté des avantages supplémentaires en matière de mise à l'échelle automatique, de planification des GPU, de tolérance aux pannes, etc., qui sont très importants dans un environnement de production.
Déploiement sur différentes configurations infra: Certaines charges de travail nécessitent une latence très faible pour la production, tandis que le développement et l'expérimentation peuvent tolérer des latences plus élevées. Exemple : Une entreprise peut avoir besoin de deux instances différentes de LLAMA : l'une fonctionnant efficacement sur des GPU T4 ou A10G pour des raisons de rentabilité, tandis qu'une autre fonctionne sur des GPU H100 pour les applications hautement prioritaires et sensibles à la latence.
Intégration avec les registres de modèles: Les organisations gèrent souvent plusieurs registres de modèles (par exemple, MLflow, SageMaker, Hugging Face), ce qui nécessite une intégration fluide pour le contrôle des versions et l'audit.
Gestion de modèles affinés: Les data scientists peaufinent fréquemment les modèles, et les équipes de la plateforme doivent s'assurer que ces modèles sont déployés de manière efficace et sécurisée.
2. Permettre une inférence sécurisée et évolutive
Une fois déployés, le défi consiste désormais à rendre ces modèles disponibles pour l'inférence dans diverses applications d'entreprise.
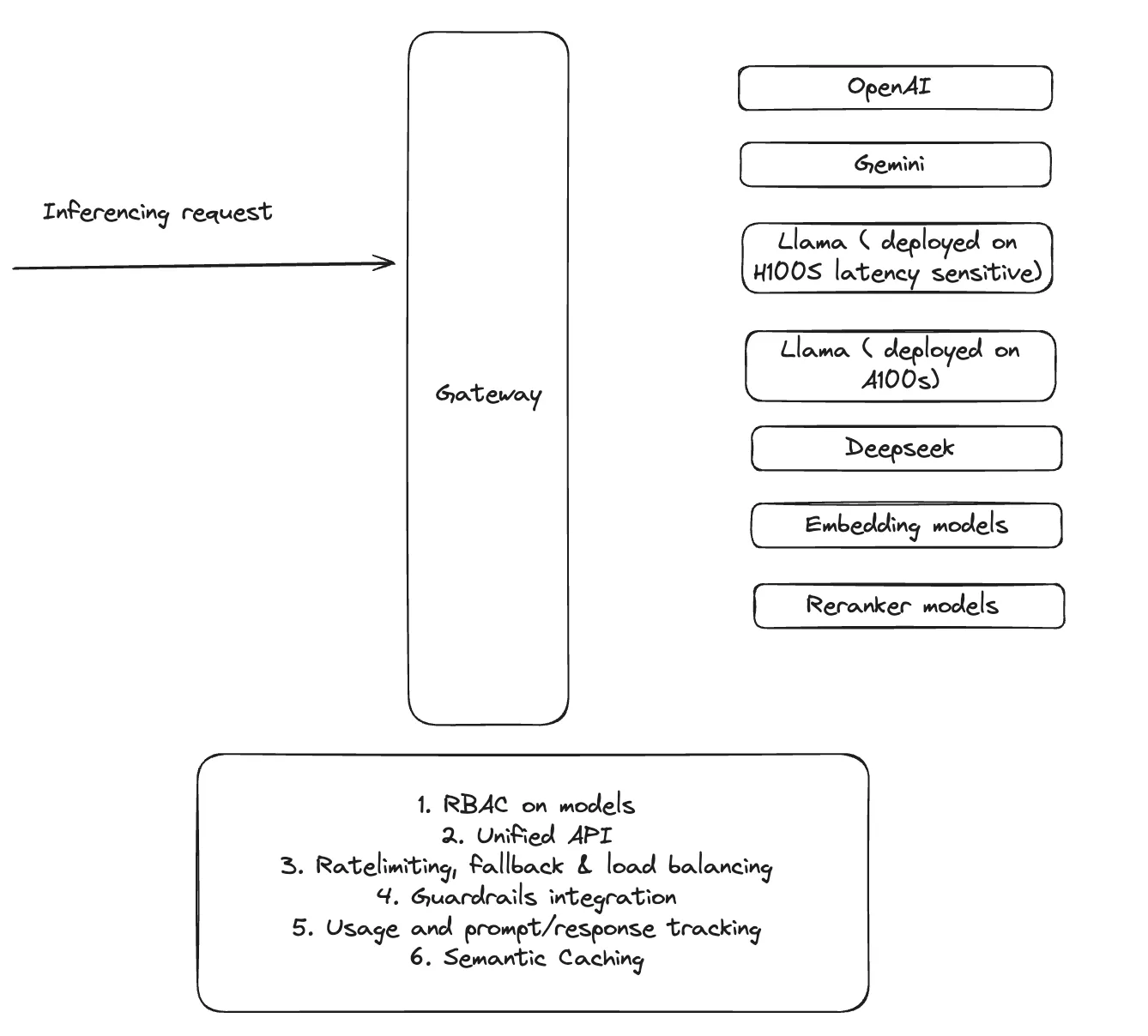
Contrôle d'accès sur les modèles: Définition du RBAC (Role-Based Access Control) pour gérer l'accès aux modèles en fonction des équipes ou des utilisateurs
API et standardisation: permettre aux équipes de créer facilement des points de terminaison d'inférence et d'échanger/échanger plusieurs LLM via un portail en libre-service.
Quotas personnalisés et limitation des taux: définition de quotas d'utilisation des modèles au niveau de l'utilisateur, de l'équipe ou de l'organisation afin de garantir une allocation équitable des ressources.
Mécanismes de basculement: Mise en œuvre de solutions de repli pour éviter les interruptions de production, telles que le passage automatique à un autre fournisseur de modèles (par exemple, OpenAI vers un modèle alternatif).
Mise en cache sémantique: Tirer parti des stratégies de mise en cache pour s'assurer que des requêtes similaires ne nécessitent pas de calculs redondants, améliorant ainsi l'efficacité.
Observabilité de l'utilisation du modèle: capture de toutes les demandes des utilisateurs, des réponses des modèles et des appels d'API à des fins de gouvernance, de débogage et de facturation.
3. Observabilité et gouvernance
Les modèles GenAI ne sont pas statiques ; ils doivent être évalués et améliorés en permanence. Les équipes de la plateforme rencontrent des difficultés avec :
Informations sur la disponibilité et l'utilisation des GPU: offre une transparence quant à l'utilisation du GPU afin d'optimiser l'allocation des ressources.
Journalisation et débogage: Capture de toutes les mesures d'utilisation, y compris les instructions des utilisateurs et les résultats des modèles, pour un meilleur suivi et une meilleure analyse.
Analyse comparative du LLM: Fournir des données empiriques sur les performances du LLM afin de garantir que les modèles choisis répondent aux normes de qualité et de fiabilité souhaitées par l'entreprise.
Rambardes de sécurité: Intégration à des barrières prédéfinies ou personnalisées pour éviter l'exposition des données PII et d'autres informations sensibles
Complexité de gestion des clés: La gestion des clés d'API, des secrets et de l'authentification dans différents environnements cloud augmente les risques de sécurité et les frais opérationnels.
Comment TrueFoundry permet à GenAI de devenir un service
TrueFoundry fournit une plateforme d'infrastructure d'IA de bout en bout qui simplifie le déploiement, l'inférence et la gouvernance des modèles, permettant aux équipes chargées de la plateforme de se concentrer sur l'évolutivité, l'efficacité et la sécurité plutôt que sur les goulots d'étranglement de l'infrastructure.
La plateforme tout-en-un pour les déploiements unifiés
TrueFoundry propose une plateforme d'IA native de Kubernetes qui automatise le déploiement des modèles et la gestion de l'infrastructure, éliminant ainsi le besoin de configuration manuelle.
Support multicloud et sur site : grâce au support multicloud et sur site, les entreprises peuvent déployer des modèles sur AWS, GCP, Azure ou des centres de données privés sans frais opérationnels supplémentaires.
Prend en charge le déploiement de modèles dans divers cadres de modèles, types et serveurs. Supporte également le déploiement de modèles d'intégration et de reclassement.
La plateforme sélectionne automatiquement la meilleure configuration de déploiement de Kubernetes en fonction de l'architecture du modèle, de la disponibilité du GPU et des exigences de débit.
TrueFoundry optimise également l'infrastructure en fournissant des fonctionnalités de dimensionnement automatique qui réduisent le temps de dimensionnement du modèle de 3 à 5 fois, réduisant ainsi de manière significative les délais de démarrage à froid.
Prend également en charge des fonctionnalités avancées telles que le streaming d'images, le routage permanent pour les LLM et les recommandations intelligentes en matière de GPU
En outre, TrueFoundry permet le déploiement de modèles en libre-service, permettant aux data scientists de déployer des modèles sans l'expertise de Kubernetes, de réduire la dépendance vis-à-vis des ingénieurs de la plateforme et d'accélérer l'adoption de l'IA par les équipes.
Support complet de Gitops pour faciliter la vie des équipes de la plateforme
Inférencement de modèles unifié et évolutif
TrueFoundry simplifie l'inférence de modèles en fournissant une passerelle IA centralisée, garantissant un accès transparent aux modèles dans différents environnements cloud.
Grâce à une API unique, les équipes de la plateforme peuvent gérer des modèles open source (Llama), des solutions commerciales (OpenAI, Bedrock, Mistral) et des modèles d'entreprise affinés. Cette unification garantit des expériences d'inférence cohérentes entre les flux de travail.
Il prend également en charge la limitation du débit pour garantir des quotas entre les utilisateurs/les équipes/les modèles, l'équilibrage de charge et le basculement automatique pour éviter les interruptions de service. En cas de panne de service ou de dégradation des performances, les modèles peuvent facilement revenir à d'autres fournisseurs sans intervention manuelle.
En outre, la mise en cache sémantique réduit les calculs redondants, optimise le temps de réponse et réduit les coûts opérationnels.
TrueFoundry intègre également de manière native des modèles de reclassement et d'intégration, ce qui facilite la création de la génération augmentée par la récupération (RAG), un cas d'utilisation courant
Observabilité, sécurité et gouvernance
Les équipes de la plateforme peuvent suivre l'utilisation des modèles en temps réel, contrôler qui invoque quels modèles et à quelle fréquence, et analyser les performances du système pour optimiser l'allocation des ressources.
La plateforme propose des outils de journalisation et de débogage détaillés, permettant aux ingénieurs de suivre efficacement les problèmes, de réduire les temps d'arrêt et d'améliorer la fiabilité.
La sécurité est au cœur des préoccupations, avec une gestion centralisée des clés d'API, empêchant les accès non autorisés et garantissant la sécurité des processus d'authentification dans les environnements cloud. TrueFoundry garantit également la confidentialité des données de niveau professionnel en déployant toutes les charges de travail d'IA au sein de l'infrastructure VPC de l'organisation, éliminant ainsi les risques d'exposition externe aux données.
De plus, la plate-forme s'intègre parfaitement aux garde-corps tels que Nemo, Arize, etc., pour la détection des informations personnelles, etc.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge






























.png)

.webp)
.webp)
.webp)



.webp)
.webp)


