

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
.webp)
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Un modèle pré-entraîné est ensuite entraîné ou « réglé » sur un ensemble de données plus petit et spécifique adapté à une tâche particulière.
Supposons que vous développiez un modèle qui génère des manuels techniques pour l'électronique à l'aide de GPT-3 (un grand modèle de langage contenant 175 milliards de paramètres), mais que la sortie générique de GPT-3 ne répond pas à la précision technique et à la tonalité requises.
Dans ce cas, vous pouvez envisager de réentraîner le modèle pour votre cas d'utilisation spécifique, mais entraîner directement un modèle tel que GPT-3 à partir de zéro pour répondre à cette tâche de niche n'est pas pratique en raison des ressources de calcul requises et des données spécialisées.
C'est là que le réglage fin entre en jeu.
La mise au point, c'est comme enseigner une nouvelle astuce à GPT-3. Elle en sait déjà beaucoup sur les langues grâce à sa formation sur de nombreux textes, qu'il s'agisse de livres ou de sites Web. Votre travail consiste à le former davantage sur un ensemble de données ciblé, en l'occurrence un corpus de manuels techniques existants et de documentation spécifiques à l'électronique.
Quelques méthodes de base pour affiner les réglages :
Le réglage fin efficace des paramètres (PEFT) est une technique visant à minimiser le nombre de paramètres supplémentaires requis lors du réglage fin de modèles de réseaux neuronaux pré-entraînés,
Cela permet de réduire les dépenses de calcul et l'utilisation de la mémoire tout en maintenant ou même en améliorant les performances. PEFT y parvient en ajoutant des intégrations rapides en tant que paramètres supplémentaires du modèle et en ne réglant qu'un petit nombre de paramètres supplémentaires.
Le PEFT nécessite également un ensemble de données beaucoup plus petit que le réglage fin traditionnel.
Chargez le modèle que vous avez choisi à l'aide d'un framework d'apprentissage automatique tel que TensorFlow, PyTorch ou la bibliothèque Transformers de Hugging Face. Ces frameworks fournissent des API permettant de télécharger et de charger facilement des modèles pré-entraînés.
Voici un exemple de code :
Avant de peaufiner, vous devez essayer différentes instructions pour orienter les réponses du modèle. Testez différentes instructions à l'aide du modèle pré-entraîné pour voir comment elles affectent le résultat et choisissez celle qui convient le mieux. Vous pouvez également modifier différents paramètres tels que max_length, temperature, etc.
C'est comme trouver la meilleure façon de poser votre question pour que le modèle comprenne ce que vous voulez.
Dans un jeu de données destiné à être peaufiné, il comporte généralement deux parties : Prompt (entrée) et Réponse (sortie). L'invite est comme une question ou un point de départ, et la réponse correspond à ce que vous voulez que le modèle génère en réponse à cette question. Il peut prendre la forme de colonnes ou d'une séquence d'entrées de texte (plus courant).
La meilleure invite identifiée à la dernière étape sera utilisée ici et la réponse sera exactement ce que nous voulons que le modèle produise une fois cette invite donnée.
C'est ici que vous apprenez au modèle à mieux accomplir votre tâche. Vous utiliserez l'ensemble de données pour ajuster légèrement les « connaissances » du modèle.
Voici un aperçu simplifié de la configuration et de l'exécution du processus de réglage avec PyTorch :
Configuration pour la formation :
Boucle d'entraînement :
Lorsque vous explorez des outils permettant une ingénierie rapide, il est utile de les classer en deux domaines principaux : les plateformes de code et les plates-formes sans code. Cette distinction simplifie le processus de sélection
Les plates-formes de code font référence à des plates-formes qui fournissent des machines virtuelles qui peuvent être utilisées pour exécuter votre script Python personnalisé à des fins de réglage, comme celui mentionné précédemment. Par ailleurs, les plateformes No-Code font référence à des outils qui nécessitent un script Python simple ou aucun script Python pour s'exécuter. Il possède une interface utilisateur dédiée où vous pouvez commencer à vous entraîner en quelques clics.
Les plateformes de code sont conçues pour les utilisateurs ayant une solide expérience en programmation. Ces plateformes fournissent des machines virtuelles qui permettent d'exécuter des scripts Python personnalisés pour des tâches telles que la mise au point. Ces plateformes sont parfaites pour les projets qui exigent une personnalisation élevée et un contrôle complexe des phases de formation et de déploiement.
Amazon SageMaker est un service entièrement géré qui permet aux développeurs et aux data scientists de créer, de former et de déployer rapidement des modèles d'apprentissage automatique.
Amazon SageMaker ne dispose pas d'une fonction de « réglage fin » intégrée dédiée, spécifiquement étiquetée comme telle pour les modèles linguistiques de grande taille. Il fournit plutôt une plate-forme puissante et flexible qui vous permet d'exécuter des scripts Python personnalisés pour effectuer des tâches de réglage.
Voici un exemple simple de la façon dont vous pourriez commencer à peaufiner un modèle linguistique avec Hugging Face sur SageMaker. Cela suppose que vous avez déjà créé un compte AWS et configuré l'AWS CLI. (vous pouvez utiliser TensorFlow ou PyTorch directement sur Amazon SageMaker pour affiner les tâches)
Vous écrivez généralement un script de réglage fin (train.py) que vous transmettez à l'estimateur. Ce script doit inclure la logique de chargement, de réglage et de sauvegarde de votre modèle.
Google Colab est un service de bloc-notes Jupyter populaire basé sur le cloud qui offre un accès gratuit aux ressources informatiques, y compris les GPU et les TPU, ce qui en fait une excellente plateforme pour affiner les grands modèles de langage (LLM)
Il est particulièrement adapté aux débutants. Les blocs-notes Colab fonctionnent dans le cloud, directement depuis votre navigateur, sans nécessiter de configuration locale.
Voici un extrait de code simple pour affiner un modèle de transformateur avec Hugging Face Transformers et PyTorch dans Google Colab
Paperspace Gradient est une suite d'outils conçue pour simplifier le processus de développement, de formation et de déploiement de modèles d'apprentissage automatique dans le cloud.
Gradient est particulièrement efficace pour des tâches telles que la mise au point de grands modèles de langage (LLM) en raison de son infrastructure évolutive et de sa prise en charge des conteneurs, ce qui en fait un choix idéal pour les data scientists et les praticiens du ML.
Voici un exemple de réglage précis d'un modèle de transformateur avec PyTorch sur Paperspace Gradient.
Run.AI est une plate-forme conçue pour optimiser les ressources GPU pour les charges de travail d'apprentissage automatique, permettant ainsi aux data scientists et aux chercheurs en IA d'exécuter et de gérer plus facilement des modèles d'IA complexes, notamment en peaufinant les grands modèles de langage (LLM).
Il est basé sur Kubernetes, un outil qui organise efficacement les ressources informatiques. Ainsi, il facilite la gestion de projets d'IA complexes et permet aux équipes de développer leurs projets en douceur.
Vous pouvez consulter la documentation Run.AI pour obtenir des informations détaillées. Voici un exemple simplifié basé sur le flux de travail général pour affiner un modèle tel que LLama-2 sur la plate-forme Run.AI.
Votre script train.py doit inclure la logique de chargement de LLama-2 (ou le modèle que vous avez choisi), de votre ensemble de données et d'exécution du processus de réglage. Cela peut impliquer l'utilisation de bibliothèques telles que Hugging Face Transformers pour le chargement du modèle et TensorFlow ou PyTorch pour la boucle d'entraînement.
Run.AI fournit des outils permettant de surveiller l'utilisation du GPU et la progression de vos tâches de formation, et de gérer efficacement les ressources informatiques. Utilisez le tableau de bord ou l'interface de ligne de commande Run.AI pour suivre l'état et les performances de votre tâche.
offres d'emploi de Runai List
Cette commande répertorie toutes les tâches en cours, ce qui vous permet de suivre la progression et l'utilisation des ressources de votre tâche de réglage.
Les plateformes sans code, quant à elles, sont conçues pour des raisons de simplicité et de facilité d'utilisation. Ils éliminent le besoin d'écrire des scripts Python, offrant une interface utilisateur intuitive où la formation peut être initiée en quelques clics. Ce domaine convient aux utilisateurs sans connaissances en programmation ou à ceux qui préfèrent une approche simple pour une ingénierie rapide.
L'API OpenAI donne accès à des modèles avancés d'intelligence artificielle développés par OpenAI, notamment aux dernières versions de GPT (Generative Pre-trained Transformer). L'une des caractéristiques les plus remarquables de l'API OpenAI est sa capacité à affiner les modèles sur des ensembles de données personnalisés.
Vous pouvez ainsi adapter le comportement de modèles tels que GPT-3 ou des versions plus récentes à des applications spécifiques ou pour respecter des styles de contenu et des préférences particuliers.
Puisque je fais référence à l'API, elle n'est pas exactement « No-Code », mais on peut facilement la configurer pour la formation par rapport aux autres outils de la section précédente.
Exemple de code pour affiner les réglages :
Pour affiner un modèle, vous devez d'abord préparer votre jeu de données dans un format compréhensible par l'API OpenAI. En général, vous devez créer un fichier JSON qui ressemble à ceci :
Vous pouvez facilement télécharger le jeu de données à l'aide de l'Open AI CLI (interface de ligne de commande).
Une fois que votre jeu de données est préparé et téléchargé, vous pouvez lancer un processus de réglage. Voici un exemple utilisant la bibliothèque Python d'OpenAI :
Une fois le processus de réglage terminé, vous pouvez utiliser votre modèle affiné pour générer du texte ou d'autres tâches en spécifiant l'ID du modèle affiné :
Vous pouvez également déployer votre modèle affiné.
Microsoft Azure est une plateforme de cloud computing proposant une large gamme de services, notamment informatiques, de stockage, d'analyse, etc. Il fournit aux utilisateurs les outils nécessaires pour créer, déployer et gérer efficacement des applications.
L'une des caractéristiques remarquables est son interface intuitive, qui permet aux débutants de naviguer facilement sans connaissances approfondies en matière de codage. Grâce à de simples clics plutôt qu'à un codage complexe, les utilisateurs peuvent affiner leurs applications, faisant d'Azure un outil accessible pour un développement sans stress.
Voici une procédure pas à pas simple expliquant comment configurer une « tâche » de réglage dans Azure :
Il s'agit évidemment de l'exigence de base pour tous les outils. Les données d'entraînement peuvent être au format JSON Lines (JSONL), CSV ou TSV. Les exigences relatives à vos données varient en fonction de la tâche spécifique pour laquelle vous souhaitez affiner votre modèle.
Pour la classification du texte :
Deux colonnes : Phrase (chaîne) et Libellé (entier/chaîne)
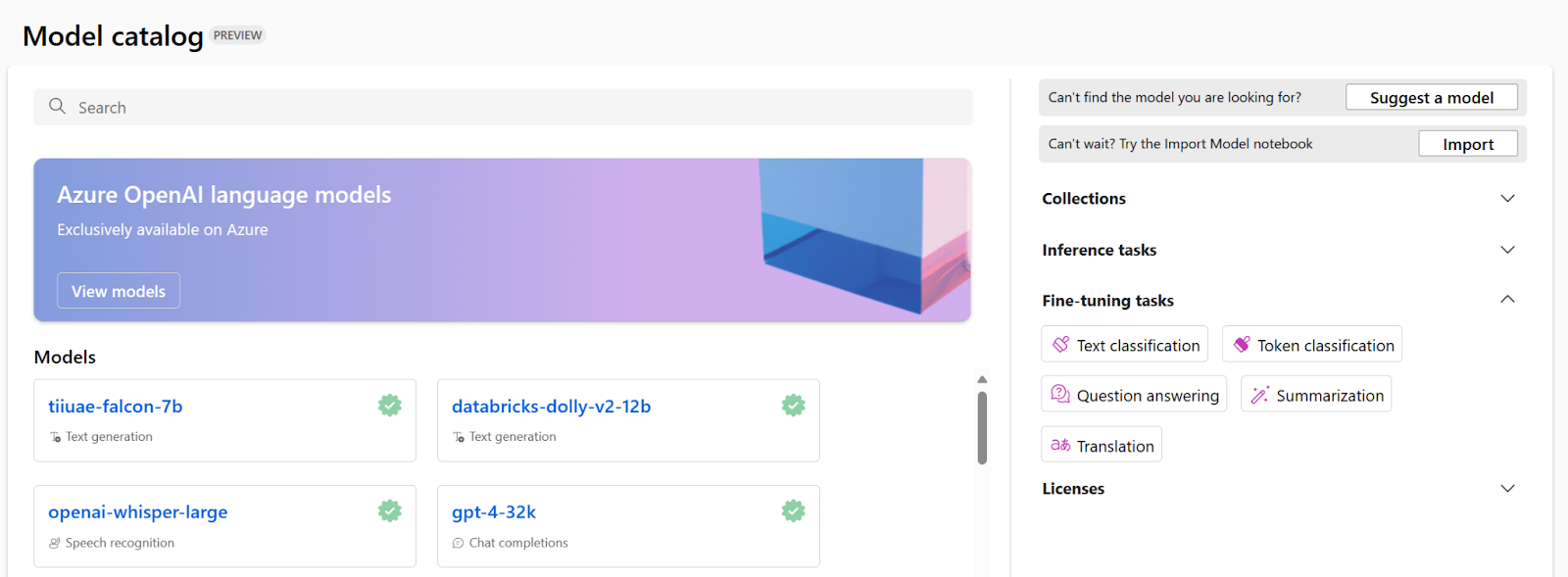
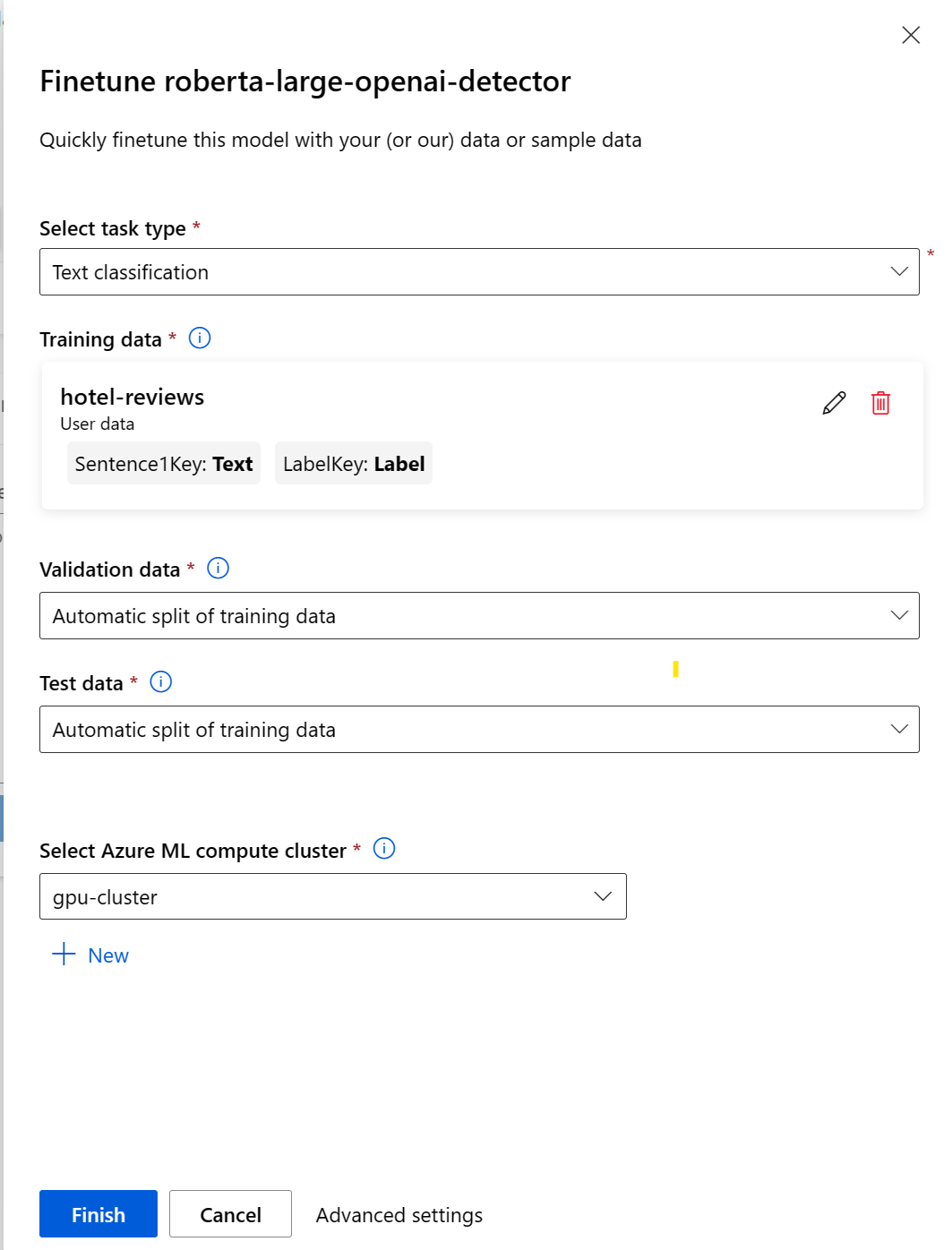
Une fois que vous avez soumis la tâche de réglage, une tâche de pipeline sera créée pour entraîner votre modèle. Vous pouvez passer en revue toutes les entrées et collecter le modèle à partir des résultats des tâches.
Pour déterminer si votre modèle affiné fonctionne comme prévu, vous pouvez consulter les mesures d'entraînement et d'évaluation.
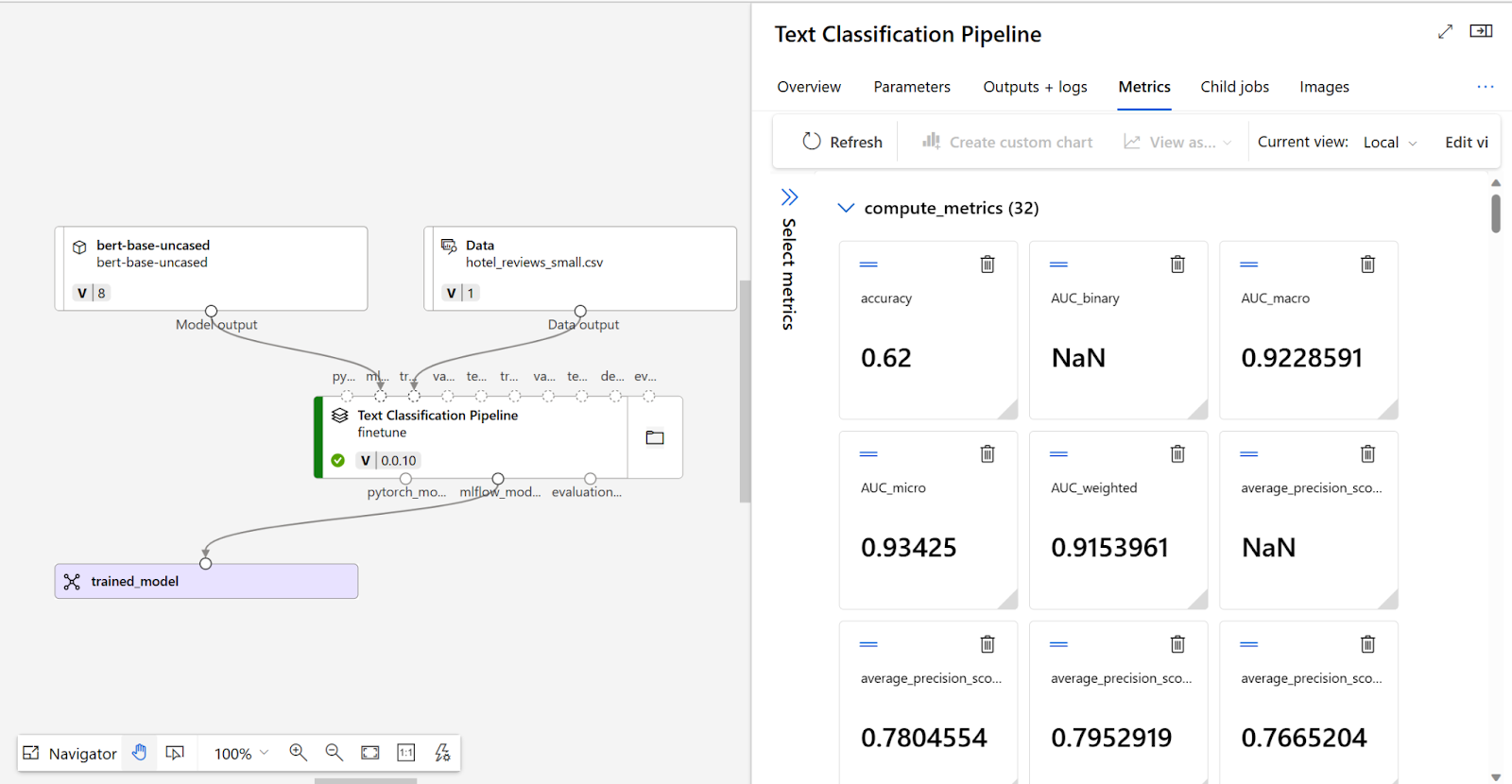
Replicate est un outil polyvalent conçu pour affiner divers aspects des applications logicielles. Les applications de Replicate en tant qu'outil de réglage fin incluent l'optimisation des performances, l'ajustement des configurations et l'amélioration des fonctionnalités avec un minimum d'effort. Il simplifie le processus en gérant la configuration du GPU. Semblable à l'API Open AI, il n'est pas exactement « No-Code » comme les autres outils de la liste, mais on peut facilement le configurer pour la formation par rapport aux autres outils de la section précédente.
Étapes pour affiner le réglage de llama-2b :
Vos données d'entraînement doivent être au format JSONL. Vous trouverez ci-dessous un exemple de la manière dont vous pourriez structurer ce fichier :
Vous devez définir votre jeton d'API Replicate en tant que variable d'environnement dans votre terminal :
Vous pouvez télécharger vos données dans un compartiment S3 ou directement sur Replicate à l'aide des commandes curl :
Vous devez créer un modèle vide sur Replicate pour votre modèle entraîné. Une fois votre entraînement terminé, il sera intégré en tant que nouvelle version à ce modèle.
Vous devez créer un job de formation sur votre IDE, comme indiqué ci-dessous :
Pour suivre la progression par programmation, vous pouvez utiliser :
Une fois la formation terminée, vous pouvez exécuter votre modèle avec l'API :
Chez Gen AI Studio, vous avez les deux options pour configurer des tâches de réglage, via l'API ou le site Web. Ici, je ne parlerai que de la méthode API. Il possède le processus le plus rationalisé par rapport aux outils décrits ci-dessus.
Voici un guide étape par étape :
Votre ensemble de données doit être au format JSONL, chaque ligne étant un objet JSON avec les clés « input_text » et « output_text ». Il peut commencer la formation avec seulement 10 exemples, mais au moins 100 exemples sont recommandés.
Vous devez télécharger votre ensemble de données dans le bucket Google Cloud Storage (GCS). Si vous n'en avez pas, vous pouvez en créer un dans Google Drive.
Vous devez maintenant fournir vos informations d'identification pour établir la connexion :
Vous devez définir une fonction de réglage avec les paramètres nécessaires.
Appelez la fonction de réglage spécifiée précédemment, avec vos paramètres spécifiques. Le paramètre training_data peut être un URI GCS ou un Pandas DataFrame.
Predibase est une plateforme spécialisée conçue pour faciliter l'ajustement de grands modèles de langage (LLM), tels que GPT-4, pour des tâches ou des applications spécifiques. Il donne accès aux fonctionnalités avancées des LLM en fournissant un environnement simplifié et convivial permettant de personnaliser ces modèles en fonction des besoins individuels.
Predibase vous offre la possibilité d'utiliser à la fois le SDK Python et l'interface utilisateur pour effectuer des tâches de réglage.
Voici un guide étape par étape pour affiner mistral-7b-instruct :
Tout d'abord, créez un compte sur Predibase et effectuez un dépôt pour ajouter des crédits. Générez ensuite votre clé API.
Accédez à Modèles, puis cliquez sur « Nouveau référentiel de modèles » comme indiqué ci-dessous :
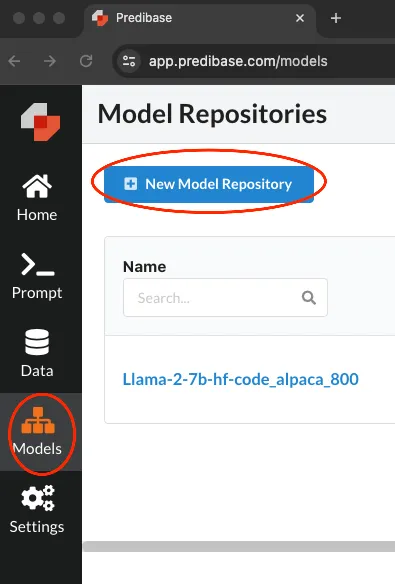
Maintenant, nommez votre dépôt et ajoutez une description.
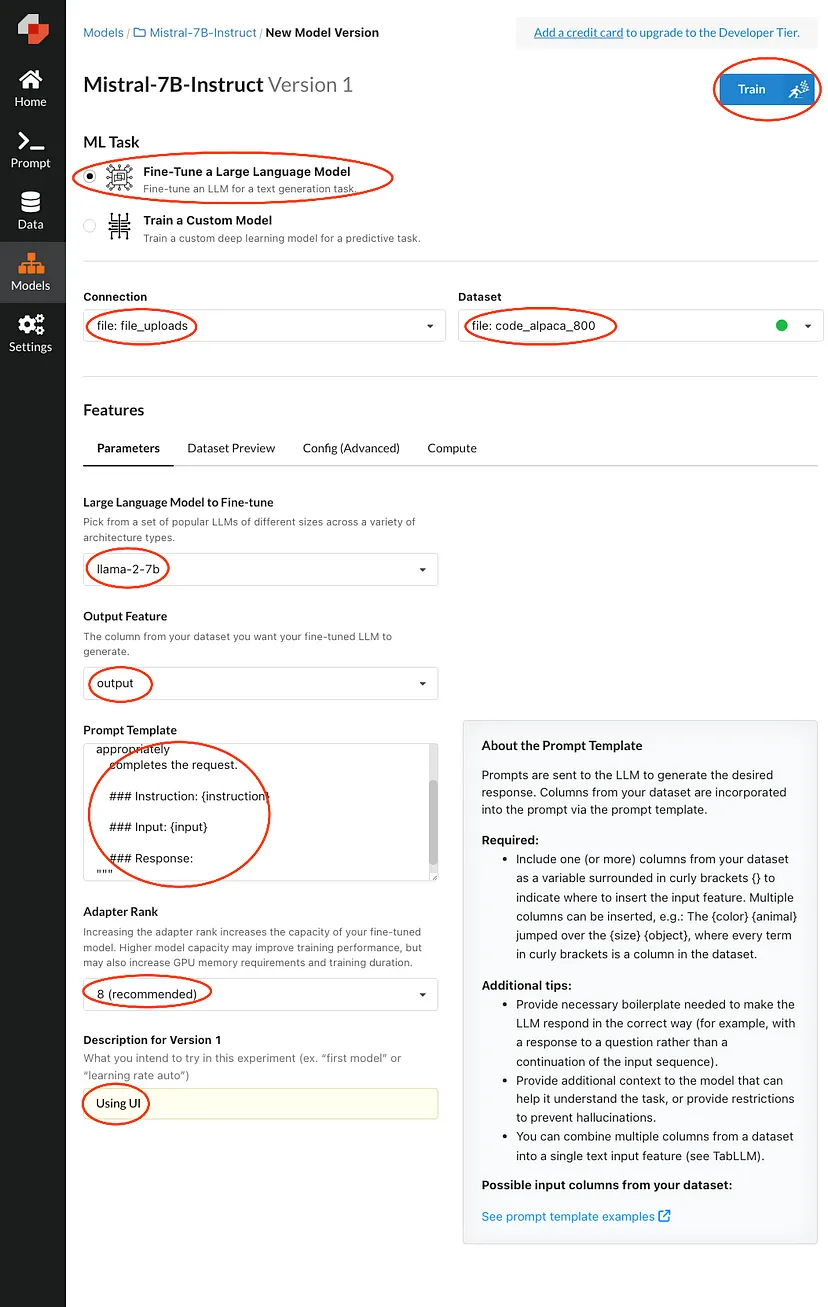
Remplissez les zones surlignées, puis appuyez sur Train. Cela mettra votre demande en file d'attente jusqu'à ce qu'un calcul soit disponible.
TrueFoundry est un outil qui aide les équipes de machine learning à mettre en place et à faire fonctionner leurs modèles sans problème. Il est basé sur Kubernetes, ce qui signifie qu'il peut fonctionner sur différents clouds ou même sur vos propres serveurs. C'est important pour les entreprises soucieuses de protéger leurs données et de contrôler les coûts.
Pour le réglage fin, c'est l'un des meilleurs outils du marché, destiné à la fois aux débutants et aux experts. Deux options s'offrent à vous : déployer un bloc-notes de mise au point à des fins d'expérimentation ou lancer une tâche de réglage dédiée.
Les ordinateurs portables offrent une configuration idéale pour les réglages exploratifs et itératifs. Vous pouvez expérimenter sur un petit sous-ensemble de données, en essayant différents hyperparamètres afin de déterminer la configuration idéale pour les meilleures performances.
Une fois que vous avez identifié les hyperparamètres et la configuration optimaux grâce à des expériences, le passage à une tâche de déploiement vous permet d'affiner l'ensemble de données et facilite une formation rapide et fiable.
Par conséquent, les ordinateurs portables sont vivement recommandés pour les premières étapes de l'exploration et les tâches de réglage et de déploiement des hyperparamètres constituent le choix préféré pour le réglage fin du LLM à grande échelle, en particulier lorsque la configuration optimale a été établie à la suite d'expériences préalables.
Voici un guide étape par étape pour affiner les réglages en utilisant à la fois Notebook et Jobs :
1. Configuration des données d'entraînement
Truefoundry prend en charge deux formats de données différents :
Chaque ligne contient une clé appelée messages. Chaque clé de message contient une liste de messages, chaque message étant un dictionnaire avec des clés de rôle et de contenu. La clé de rôle peut être utilisateur, assistant ou système et la clé de contenu contient le contenu du message.
2. Réglage fin
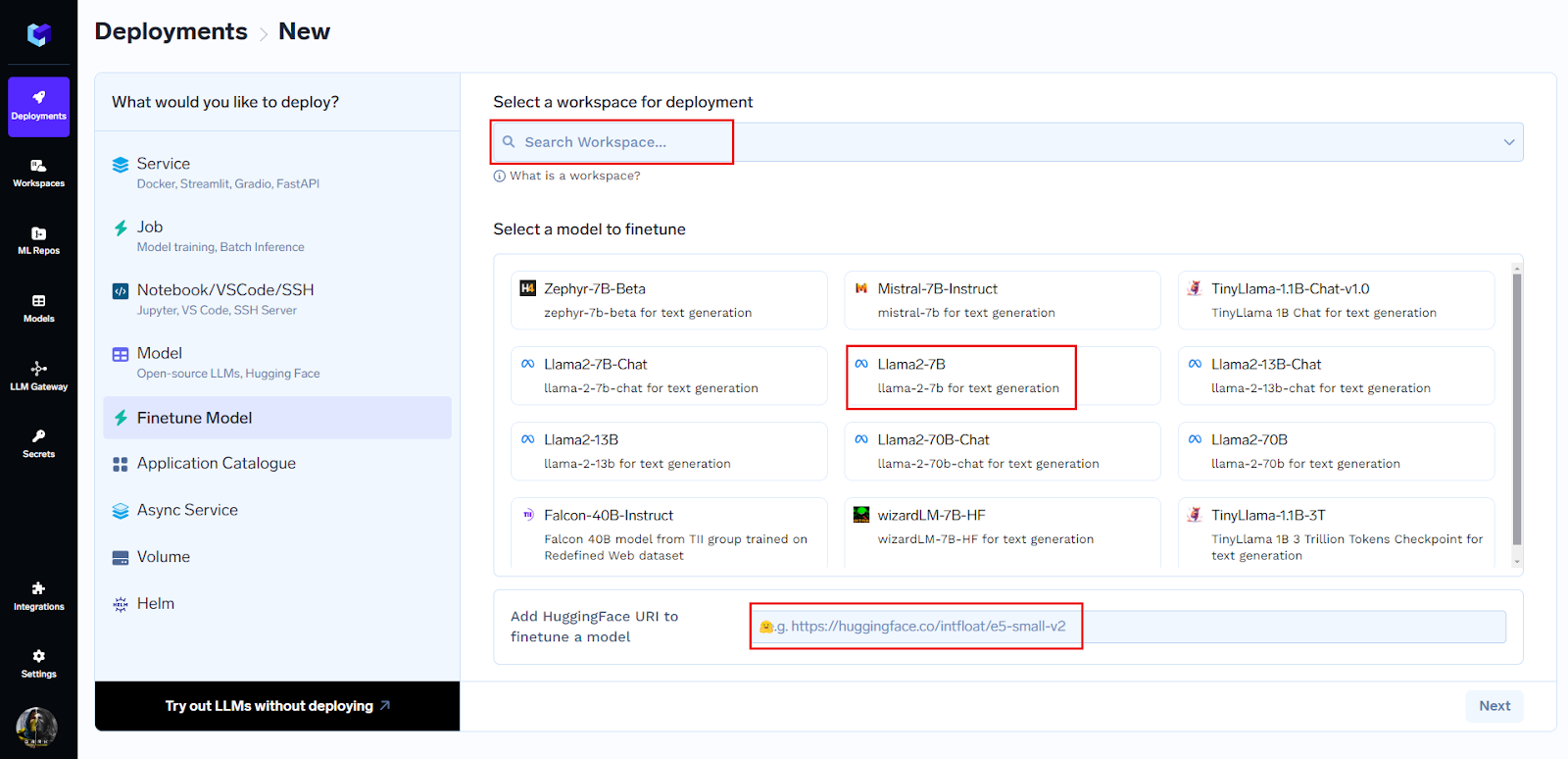
Vous pouvez commencer à peaufiner le réglage en trois clics seulement :
Vous pouvez choisir le modèle dans la liste complète présente ou simplement coller l'URL huggingface pour commencer à peaufiner.
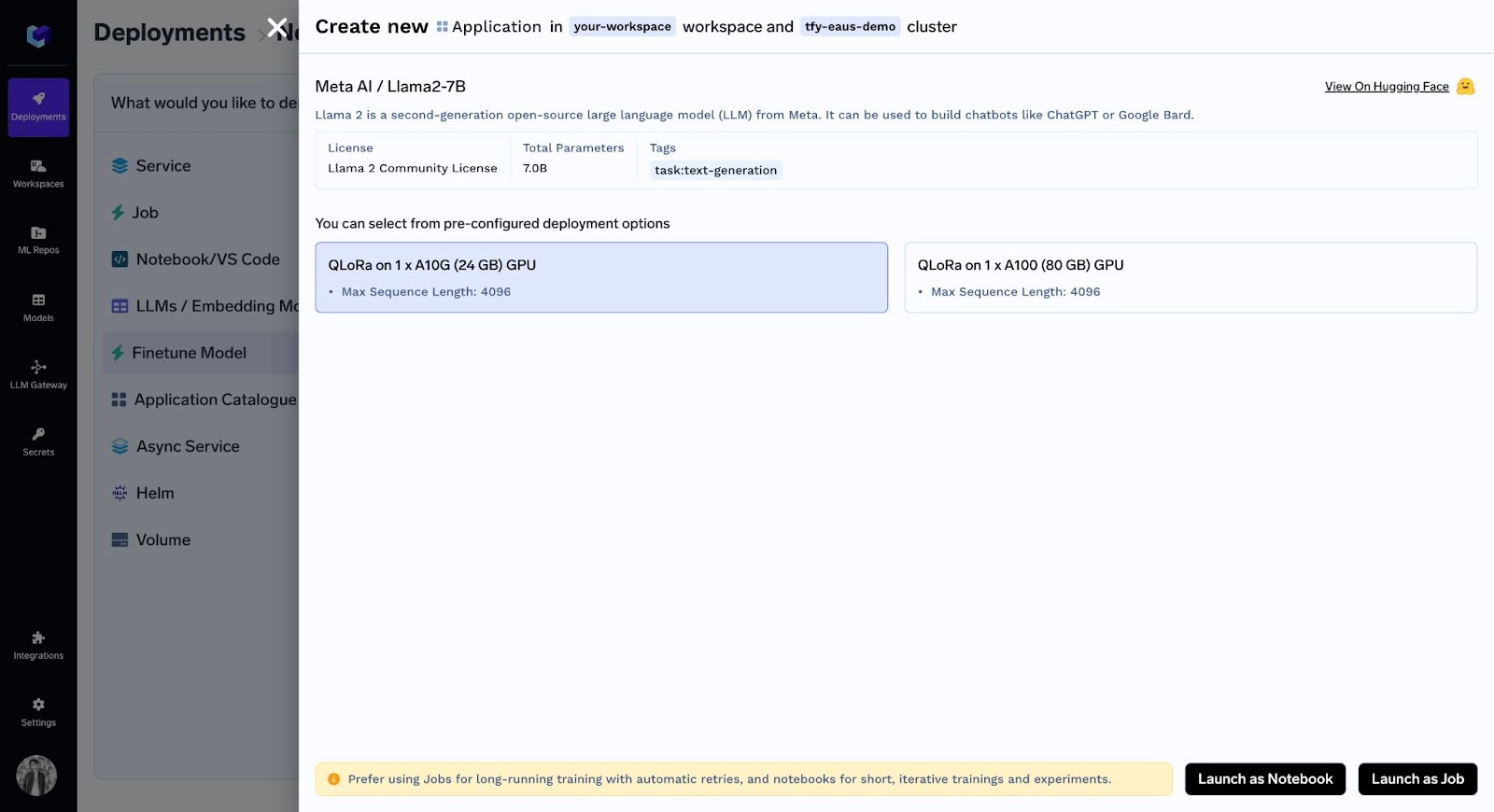
Maintenant, après avoir sélectionné le GPU souhaité, vous avez deux options : Exécuter en tant que bloc-notes ou Job.
3. Réglage précis à l'aide d'un ordinateur portable
Après avoir choisi « Lancer en tant que bloc-notes » et sélectionné les valeurs par défaut pour les hyperparamètres, vous pouvez voir votre bloc-notes :
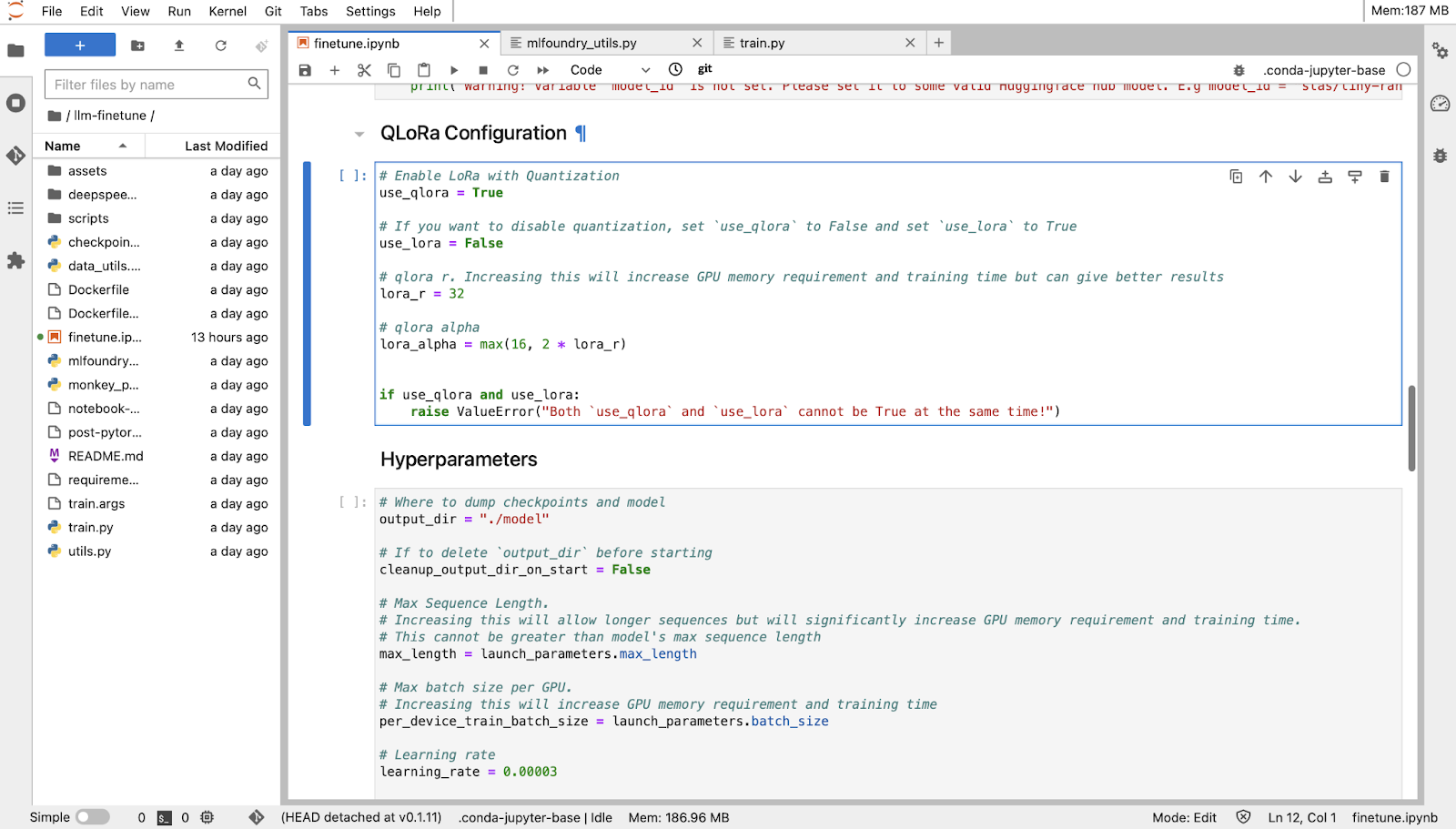
4. Le peaufinage en tant que tâche :
Avant de commencer, vous devez d'abord créer un référentiel ML (il sera utilisé pour stocker vos indicateurs et artefacts d'entraînement, tels que vos points de contrôle et vos modèles) et donner à votre espace de travail l'accès au référentiel ML. Vous pouvez en savoir plus sur ML Repo dans la documentation de Truefoundry.
Vous devez maintenant choisir « Lancer en tant que tâche » et sélectionner les valeurs par défaut des hyperparamètres pour lancer le réglage fin.
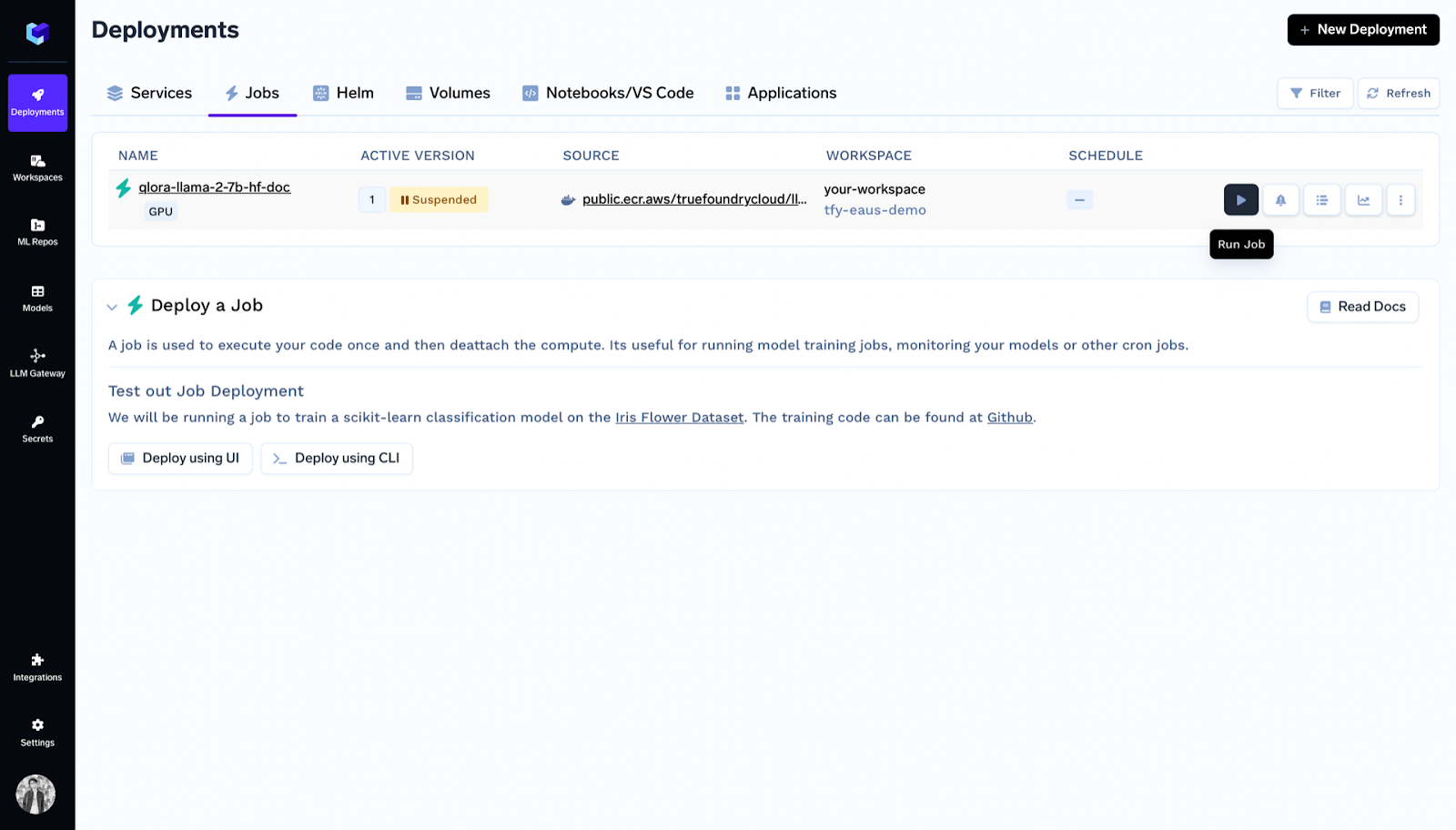
Dans les déploiements, vous pouvez voir la liste des tâches et cliquer sur Exécuter la tâche.
Facilité d'utilisation : Choisissez des outils simples, surtout si vous n'êtes pas passionné par le codage. Certains outils ne nécessitent même pas que vous écriviez du code !
Évolutivité : Assurez-vous que l'outil peut évoluer avec votre projet, en gérant de manière fluide des ensembles de données plus volumineux et des modèles plus complexes.
Support des modèles et des ensembles de données : Choisissez des outils qui fonctionnent bien avec les types spécifiques de données et de modèles que vous utilisez.
Ressources informatiques : Recherchez l'accès à des GPU ou à des TPU si votre projet nécessite une puissance de calcul importante.
Coût : Réfléchissez au montant que vous êtes prêt à dépenser. Certains outils sont gratuits ; d'autres sont payants en fonction des ressources que vous utilisez.
Personnalisation et contrôle : Si vous connaissez le code, vous préférerez peut-être des outils qui vous permettent de tout modifier.
Intégration : C'est plus facile si l'outil s'intègre parfaitement à votre flux de travail et à vos outils existants.
Communauté et soutien : Une communauté solidaire et une bonne documentation peuvent vous éviter bien des maux de tête.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


