

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
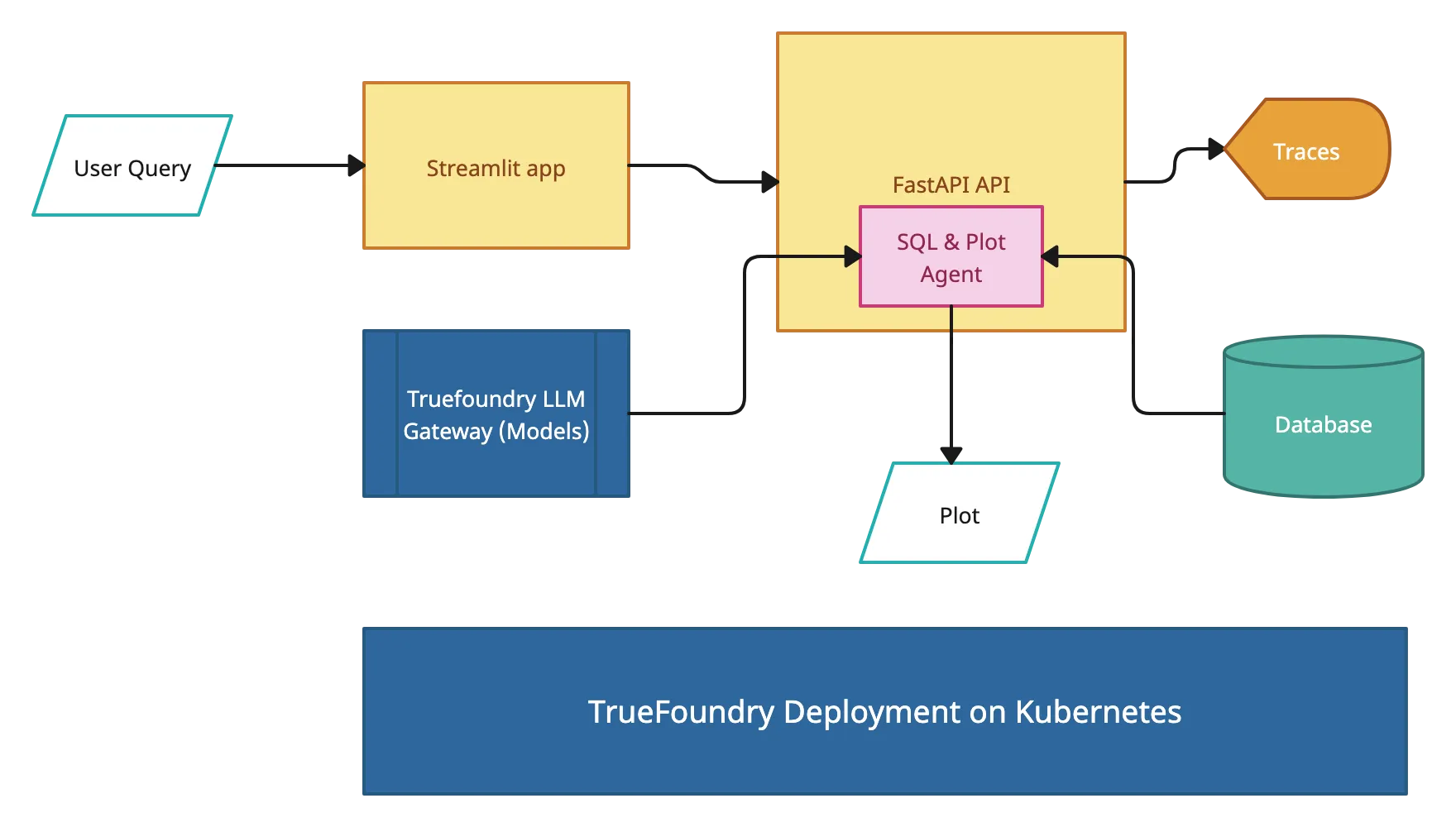
Dans ce guide, nous allons vous montrer comment déployer un Langgraph agent sur True Foundry, une plateforme conçue pour simplifier le déploiement de l'IA avec un minimum d'expertise DevOps ou MLOps. TrueFoundry automatise la gestion, la mise à l'échelle et la surveillance de l'infrastructure, ce qui vous permet de vous concentrer sur l'obtention d'informations plutôt que sur la gestion des complexités de déploiement. En quelques clics, vous pouvez transformer les requêtes en langage naturel en requêtes SQL et en graphiques dynamiques, rendant ainsi l'exploration des données fluide et intelligente. Aucune requête manuelle n'est requise !
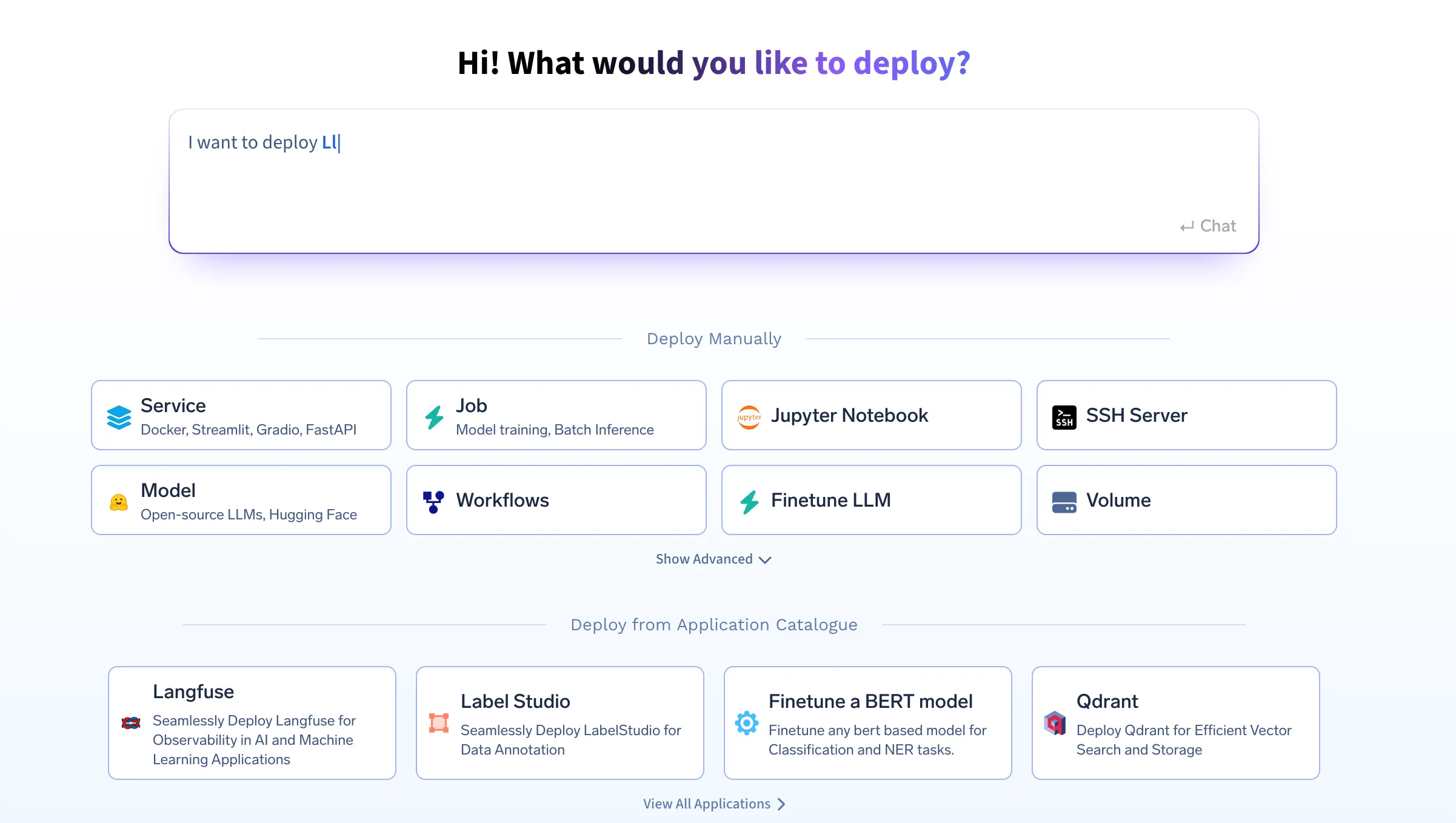
Si vous souhaitez l'essayer directement, rendez-vous sur la plateforme TrueFoundry et accédez à Live Demos et Langgraph-Streamlit : Démonstration en direct de notre flux de travail pour les agents
Ce projet comprend plusieurs éléments clés qui travaillent ensemble :
Agent de requête
Agent de visualisation: Un deuxième agent d'IA qui
Backend FastAPI: API RESTful qui
Frontend rationalisé: interface utilisateur qui
Cloner le référentiel
Tout d'abord, accédez au Exemples de démarrage avec TrueFoundry référentiel et clonez-le :
git clone <https://github.com/truefoundry/getting-started-examples.git>Accédez au répertoire des agents Plot
Accédez au répertoire plot_agent :
cd getting-started-examples/plot_agent/langgraph_plot_agentConfiguration de l'environnement
Pour créer et activer un environnement virtuel :
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activateInstaller les dépendances
pip install -r requirements.txtConfiguration de l'environnement
Copiez l'exemple de fichier d'environnement :
```bash
cp .env.example .env
```Créez un .env fichier avec vos informations d'identification
# Truefoundry LLMGateway Configuration if using Truefoundry LLM Gateway for calling models
LLM_GATEWAY_BASE_URL=your_llm_gateway_base_url_here
LLM_GATEWAY_API_KEY=your_llm_gateway_api_key_here
# OPENAI API Configuration if not using Truefoundry LLM Gateway
OPENAI_API_KEY=<your_openai_api_key_here>
# ClickHouse Database Configuration
CLICKHOUSE_HOST=your_clickhouse_host_here
CLICKHOUSE_PORT=443
CLICKHOUSE_USER=your_clickhouse_user_here
CLICKHOUSE_PASSWORD=your_clickhouse_password_here
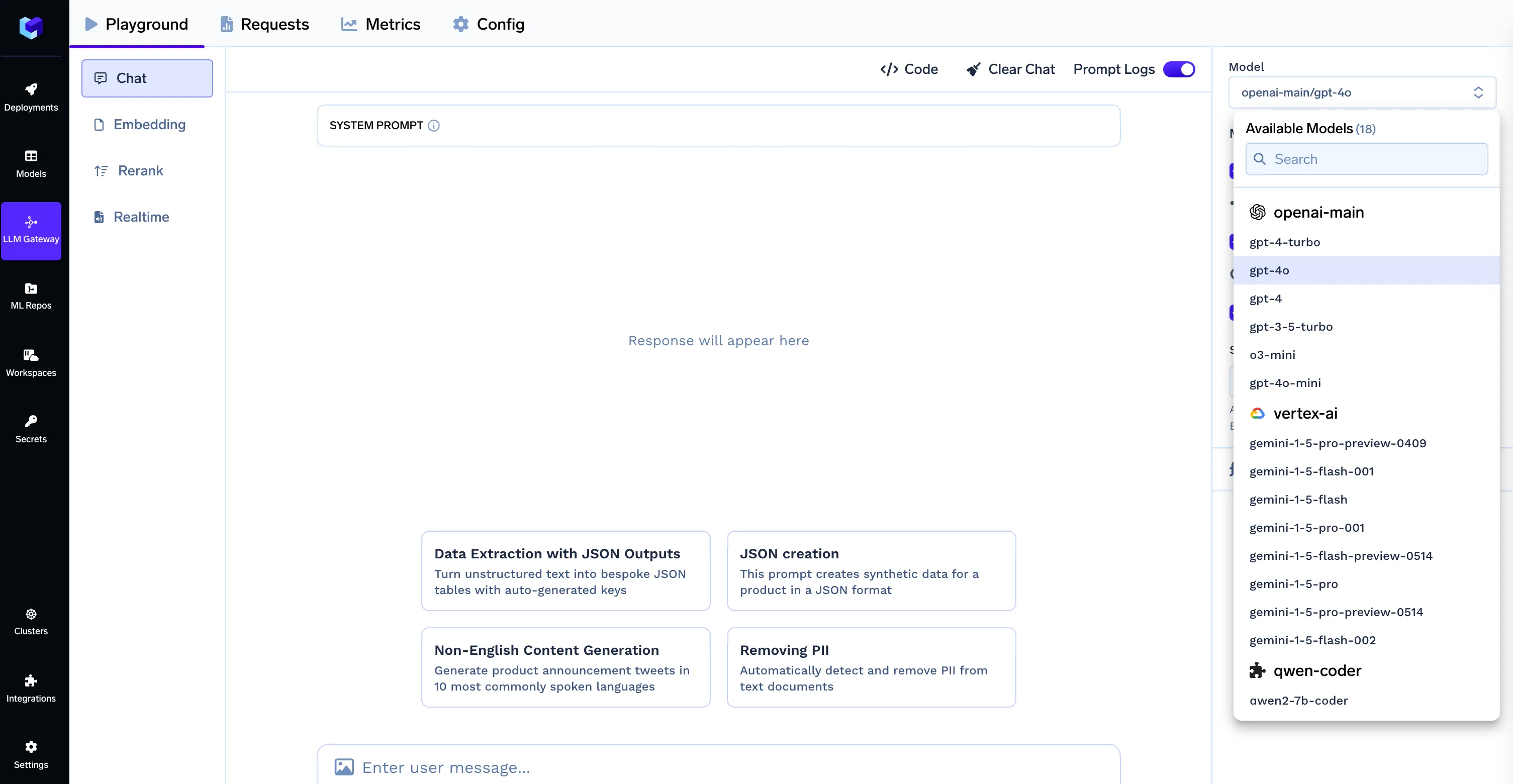
CLICKHOUSE_DATABASE=defaultRemarque : Lorsque vous utilisez la passerelle TrueFoundry LLM Gateway, le format de l'ID du modèle doit être nom du fournisseur/nom du modèle (par exemple, openai-main/gpt-4o). Assurez-vous que votre .env Le fichier contient les informations d'identification LLM Gateway correctes, comme indiqué dans la section Configuration de l'environnement.
Pour obtenir les informations d'identification Clickhouse, créez un compte sur clickhouse, connectez-vous et créez un service. Après avoir cliqué sur le service, vous verrez un bouton de connexion au milieu de la barre latérale gauche, sur lequel vous pouvez cliquer pour voir les informations d'identification, comme indiqué ci-dessous. Vous pouvez créer une base de données en téléchargeant vos fichiers ou en utiliser une prédéfinie.

Le projet utilise deux agents LangGraph, ce qui en fait également une référence pratique utile lors de l'évaluation AutoGen et LangGraph pour la conception de flux de travail multi-agents. Si vous préférez utiliser uniquement openai, remplacez :
model=OpenAIChat(
id="openai-main/gpt-4o", # Format: provider-name/model-name
api_key=os.getenv("LLM_GATEWAY_API_KEY"),
base_url=os.getenv("LLM_GATEWAY_BASE_URL")
),Avec :
model=OpenAIChat(
id="gpt-4o", # Specify model here
api_key=os.getenv("OPENAI_API_KEY")
),Voici comment ils sont configurés dans une configuration où Langflow et LangGraph revient souvent en matière de choix d'orchestration.
class State(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
tools_list = [execute_clickhouse_query, create_plot]
def tools_condition_modified(state):
ans = tools_condition(state)
human_messages_id = [m.id for m in state["messages"] if m.type == "human"]
if ans == "tools":
return "tools"
else:
return "__end__"
def create_agent():
builder = StateGraph(State)
llm = ChatOpenAI(
model=os.getenv("MODEL_ID"),
api_key=os.getenv("LLM_GATEWAY_API_KEY"),
base_url=os.getenv("LLM_GATEWAY_BASE_URL"),
streaming=True # Enable streaming for the LLM
)
llm.bind_tools(tools_list)
# Define nodes: these do the work
builder.add_node("assistant", llm)
builder.add_node("tools", ToolNode(tools_list))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_edge("tools", "assistant")
builder.add_conditional_edges(
"assistant",
tools_condition_modified,
)
builder.add_edge("assistant", "__end__")
agent = builder.compile()
return agent
agent = create_agent()
Démarrez le serveur FastAPI :
python api.pyDémarrez Streamlit UI (nouveau terminal) :
streamlit run app.py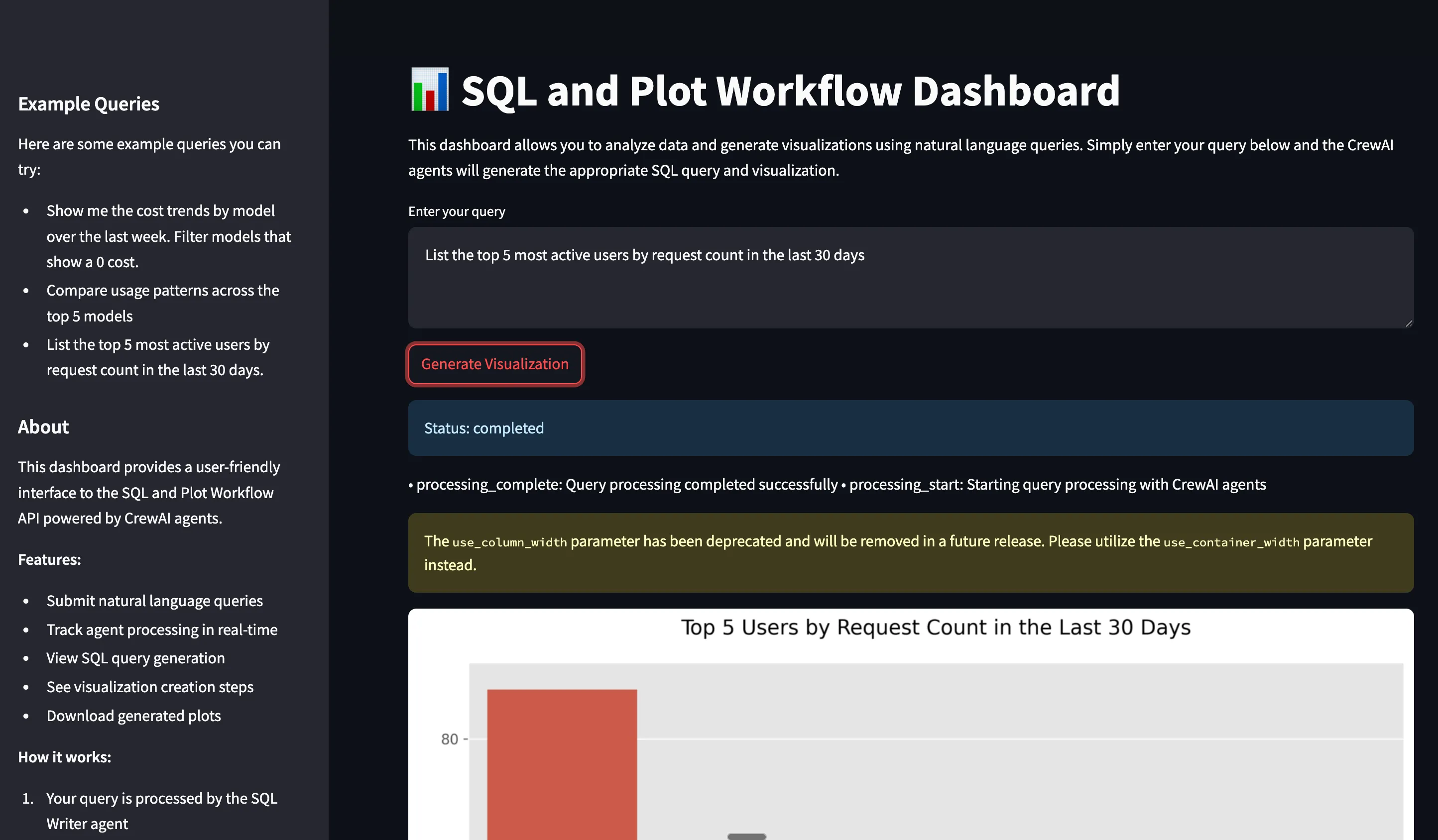
Prérequis
Installez la CLI TrueFoundry :
pip install -U "truefoundry"Connectez-vous à TrueFoundry :
tfy login --host "<https://app.truefoundry.com>"
# In the generated deploy.py file, locate the env section and add your variables:
env={
# If using OPENAI
"OPENAI_API_KEY": "your_openai_api_key",
# If using LLM_GATEWAY
"LLM_GATEWAY_API_KEY": "your_llm_gateway_api_key",
"LLM_GATEWAY_BASE_URL": "your_llm_gateway_base_url",
"CLICKHOUSE_HOST": "your_clickhouse_host",
"CLICKHOUSE_PORT": "443",
"CLICKHOUSE_USER": "your_user",
"CLICKHOUSE_PASSWORD": "your_password",
"CLICKHOUSE_DATABASE": "default",
"MODEL_ID": "gpt-4o"
}, Assurez-vous de remplacer les valeurs des espaces réservés par vos informations d'identification réelles. Sans ces variables d'environnement, votre application ne fonctionnera pas correctement.
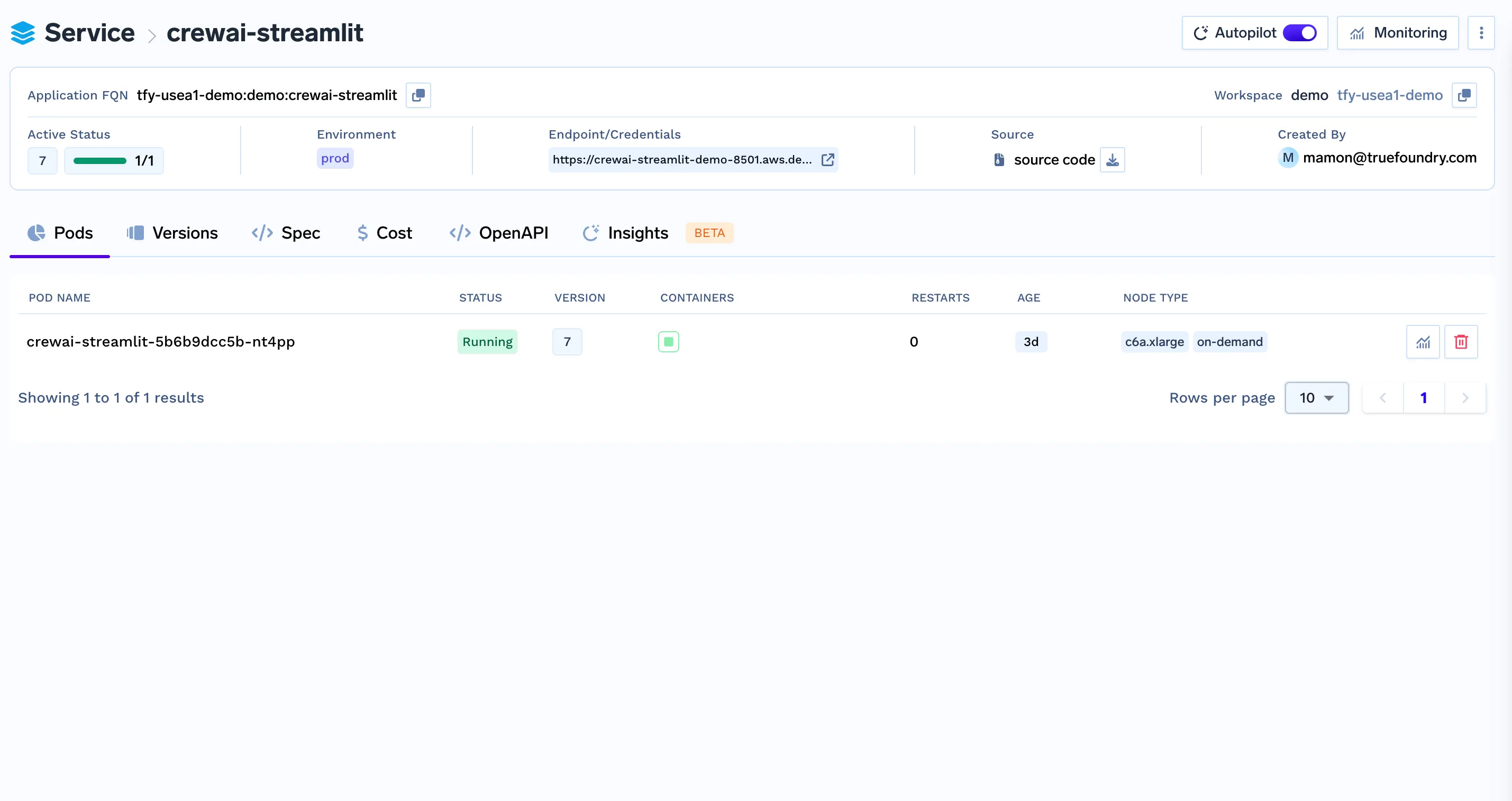
python deploy.pyVotre API SQL and Plot Workflow est désormais déployée et exécutée sur TrueFoundry !
curl -X POST -H "Content-Type: application/json" \
-d '{"query": "Show me the cost trends by model over the last week"}' \
https://Langgraph-plot-agent-demo-8000.aws.demo.truefoundry.cloud/query Si tout est configuré correctement, vous devriez recevoir une réponse du type :
{
"job_id": "123e4567-e89b-12d3-a456-426614174000",
"status": "processing",
"message": "Query is being processed. Check status with /status/{job_id}"
} 
curl -X POST "https://plot-agent-8000.your-workspace.truefoundry.cloud/query" \
-H "Content-Type: application/json" \
-d '{"query": "Show me the cost trends by model over the last week"}' curl -X POST http://localhost:8000/query \
-H "Content-Type: application/json" \
-d '{"query": "Show me the cost trends by model over the last week. Filter models that show a 0 cost."}'
{
"job_id": "123e4567-e89b-12d3-a456-426614174000",
"status": "processing",
"message": "Query is being processed. Check status with /status/{job_id}"
}
curl -X GET http://localhost:8000/status/123e4567-e89b-12d3-a456-426614174000
curl -X GET http://localhost:8000/plot/123e4567-e89b-12d3-a456-426614174000 --output plot.png Pour garantir une communication correcte entre FastAPI et Streamlit, vous devez déployer Streamlit en tant que service distinct sur la plateforme TrueFoundry.
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
) Votre application Streamlit doit utiliser une variable d'environnement pour pointer vers le backend FastAPI : dans votre Environnement rationalisé configuration :
FASTAPI_ENDPOINT="https://langgraph-plot-agent-demo-8000.aws.demo.truefoundry.cloud"Modifiez ensuite votre Application Streamlit pour lire cette variable d'environnement :
import os
FASTAPI_ENDPOINT = os.getenv("FASTAPI_ENDPOINT", "http://localhost:8000")Cela garantit que Streamlit référence dynamiquement l'instance FastAPI correcte.
4. Utiliser des ports séparés
En cas de déploiement local ou si TrueFoundry ne gère pas automatiquement les conflits de ports, assurez-vous FastAPI et Streamlit fonctionnent sur des ports distincts.
Exemple :
API rapide: https://langgraph-plot-agent-demo-8000.aws.demo.truefoundry.cloud
Streamlit: https://langgraph-streamlit-demo-8501.aws.demo.truefoundry.cloud
Pour exécuter Streamlit sur un autre port en local, procédez comme suit :
streamlit run app.py --server.port 8501Le traçage vous permet de comprendre ce qui se passe sous le capot lorsqu'un agent est appelé. Vous apprenez à comprendre le chemin, les appels d'outils effectués, le contexte utilisé, la latence prise lorsque vous exécutez votre agent à l'aide de la fonctionnalité de traçage de Truefoundry en ajoutant très peu de lignes de code.
Vous devez installer les éléments suivants
pip install traceloop-sdkAjoutez ensuite les variables d'environnement nécessaires pour activer le traçage
"TRACELOOP_BASE_URL": "<your_host_name>/api/otel" # "https://internal.devtest.truefoundry.tech/api/otel"
"TRACELOOP_HEADERS"="Authorization=Bearer%20<your_tfy_api_key>"Dans votre base de code où vous définissez votre agent, vous avez juste besoin de ces lignes pour activer le traçage
from traceloop.sdk import Traceloop
Traceloop.init(app_name="langraph")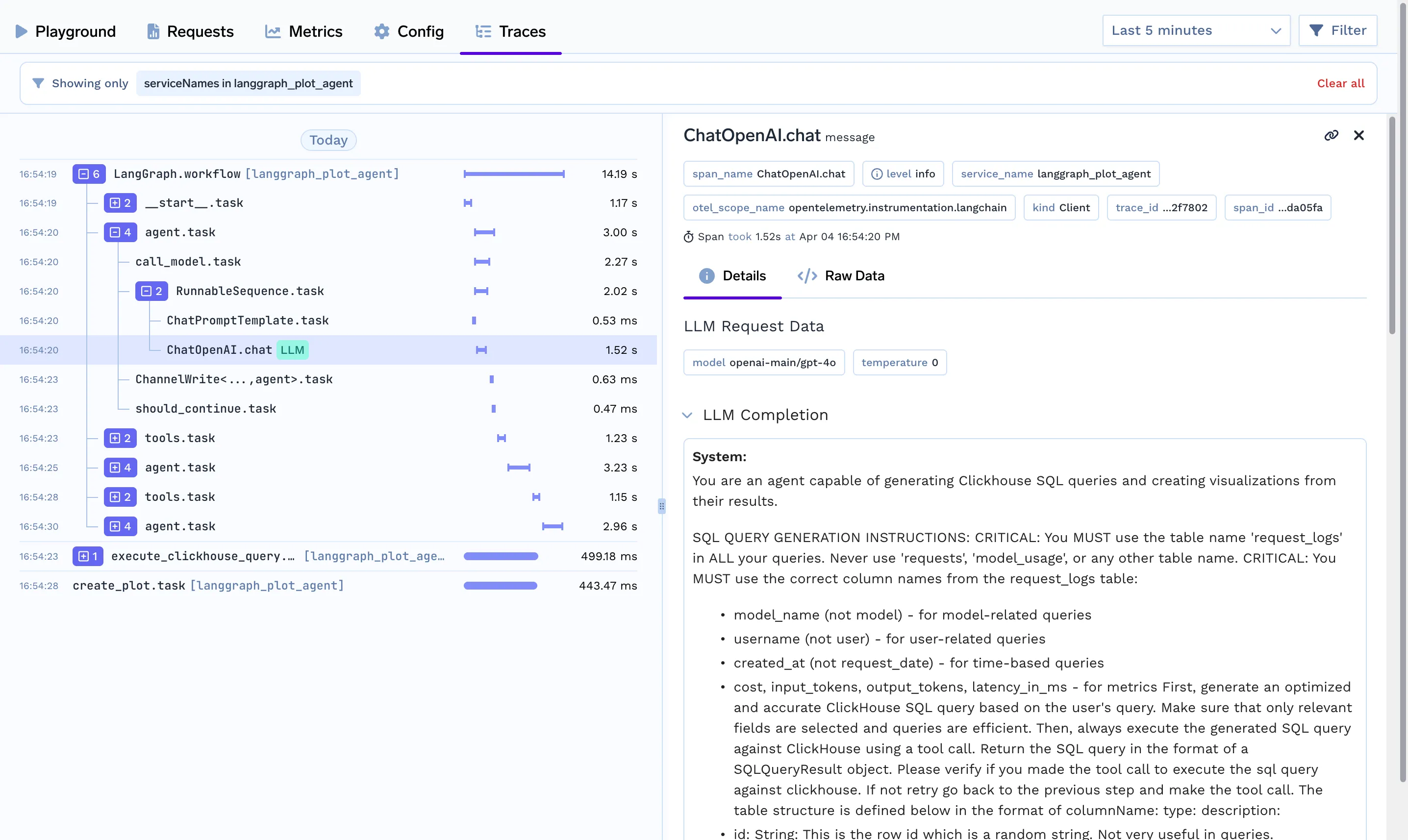
Après avoir déployé les deux services, assurez-vous de :
.env fichier avec le point de terminaison FastAPI correct.Cela garantit que votre API SQL et Plot Workflow fonctionnent correctement sur les deux services.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


