

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Si vous avez déjà participé à une réunion avec votre équipe InfoSec ou juridique concernant un déploiement mondial de machine learning, vous savez exactement à quel moment l'ambiance change. C'est quand quelqu'un demande : « Attendez, où se trouvent réellement les journaux d'inférence des clients allemands ? »
La résidence des données était autrefois un problème de base de données. Aujourd'hui, avec les pipelines de machine learning couvrant la formation, la diffusion, la surveillance et les magasins de fonctionnalités, l'ensemble de votre infrastructure est en désordre. Le RGPD, le CCPA, les lois sur la souveraineté des données en Asie, ce ne sont pas des suggestions. Si vous vous trompez, vous devrez payer de lourdes amendes ou, pire encore, devoir démanteler un déploiement actif.
Nous utilisons TrueFoundry pour gérer notre infrastructure de machine learning et, franchement, leur approche de la résidence des données est l'une des principales raisons pour lesquelles nous avons choisi cette solution. Cela change fondamentalement la façon dont nous envisageons l'emplacement des données par rapport à l'endroit où elles sont gérées.
Voici un aperçu de son fonctionnement dans la pratique et des raisons pour lesquelles il est différent des plateformes MLOps SaaS classiques.
Le principal problème de nombreuses plateformes MLOps gérées est que pour bénéficier de la commodité de leurs outils, vous devez souvent envoyer vos données (artefacts de modèle, extraits de formation, journaux) vers leur cloud. C'est un échec pour les secteurs hautement réglementés.
TrueFoundry fonctionne différemment. Ils utilisent une séparation stricte entre les Plan de contrôle (leur interface de gestion SaaS) et Plan de données (vos comptes cloud).
Pensez-y comme ceci : TrueFoundry est le contrôleur du trafic aérien. Ils indiquent aux avions où aller et quand atterrir. Mais vous êtes propriétaire de l'aéroport, des hangars et des avions eux-mêmes. TrueFoundry ne possède jamais réellement la cargaison à l'intérieur de l'avion.
Lorsque vous connectez un cluster Kubernetes (EKS, GKE, AKS) à TrueFoundry, vous installez essentiellement un agent. Cet agent contacte le plan de contrôle TrueFoundry pour obtenir des instructions, mais le traitement et le stockage des données se font dans le périmètre de votre réseau prédéfini.
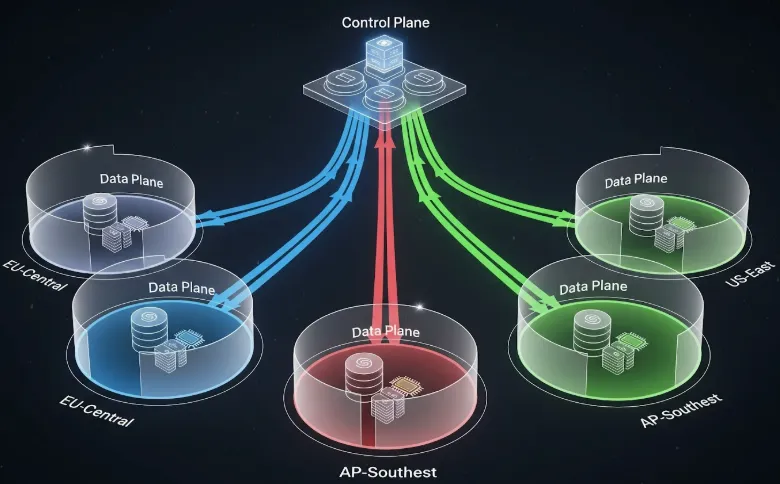
Voici une vue d'ensemble de cette relation.
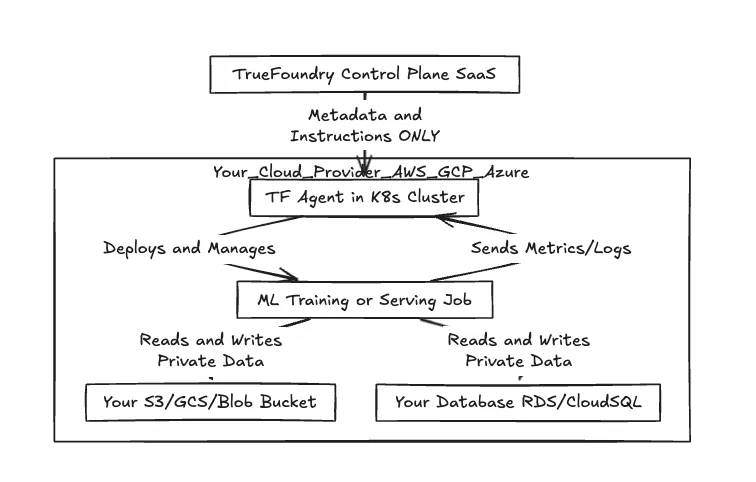
Figure 1 : Flux de travail entre le plan de contrôle et la séparation du plan de données
Comme indiqué ci-dessus, le « gros du travail » et les entrées/sorties de données réelles restent entièrement dans les limites de votre environnement cloud. La seule chose qui remonte à TrueFoundry, ce sont les métadonnées, c'est-à-dire l'état des tâches, les mesures d'utilisation des ressources et les spécifications de configuration.
Comment cela se traduit-il dans une configuration réelle dans laquelle vous avez une équipe dans l'UE qui ne peut légalement pas faire entrer les données de ses clients sur le sol américain ?
TrueFoundry utilise un concept appelé « espaces de travail ». Un espace de travail est un regroupement logique de ressources lié à un cluster de calcul sous-jacent spécifique et à une intégration de stockage d'artefacts.
Pour faire respecter la résidence, nous avons mis en place des clusters distincts dans les régions géographiques requises.
Nous répétons le processus pour us-east-1 avec un espace de travail « US-Prod ».
Lorsqu'un data scientist de l'UE souhaite déployer un modèle, il n'a accès qu'à l'espace de travail « EU-Prod ». Lorsqu'ils déclenchent une tâche de formation ou déploient un service, le plan de contrôle de TrueFoundry garantit que le calcul est effectué sur le cluster de Francfort et que les poids de modèle qui en résultent sont enregistrés dans le compartiment S3 de Francfort. La plateforme ne peut physiquement pas placer les données ailleurs, car cet espace de travail ne connaît pas l'existence d'une autre infrastructure.
Vous trouverez ci-dessous une comparaison de la manière dont les données sont gérées dans un ML SaaS géré typique par rapport à cette architecture.
Tableau 1 : Ceci est la comparaison des modèles de traitement des données
Dans une organisation mature, vous vous retrouvez avec un modèle en étoile. Vous disposez d'un plan de contrôle TrueFoundry centralisé qui permet à l'équipe d'ingénierie de votre plateforme d'accéder à une interface unique pour faciliter la gestion, mais l'exécution réelle est fragmentée géographiquement.
Cet isolement est essentiel. Cela signifie que même si un développeur essaie accidentellement de configurer une tâche de manière incorrecte, les contraintes d'infrastructure empêchent les fuites de données entre les régions.
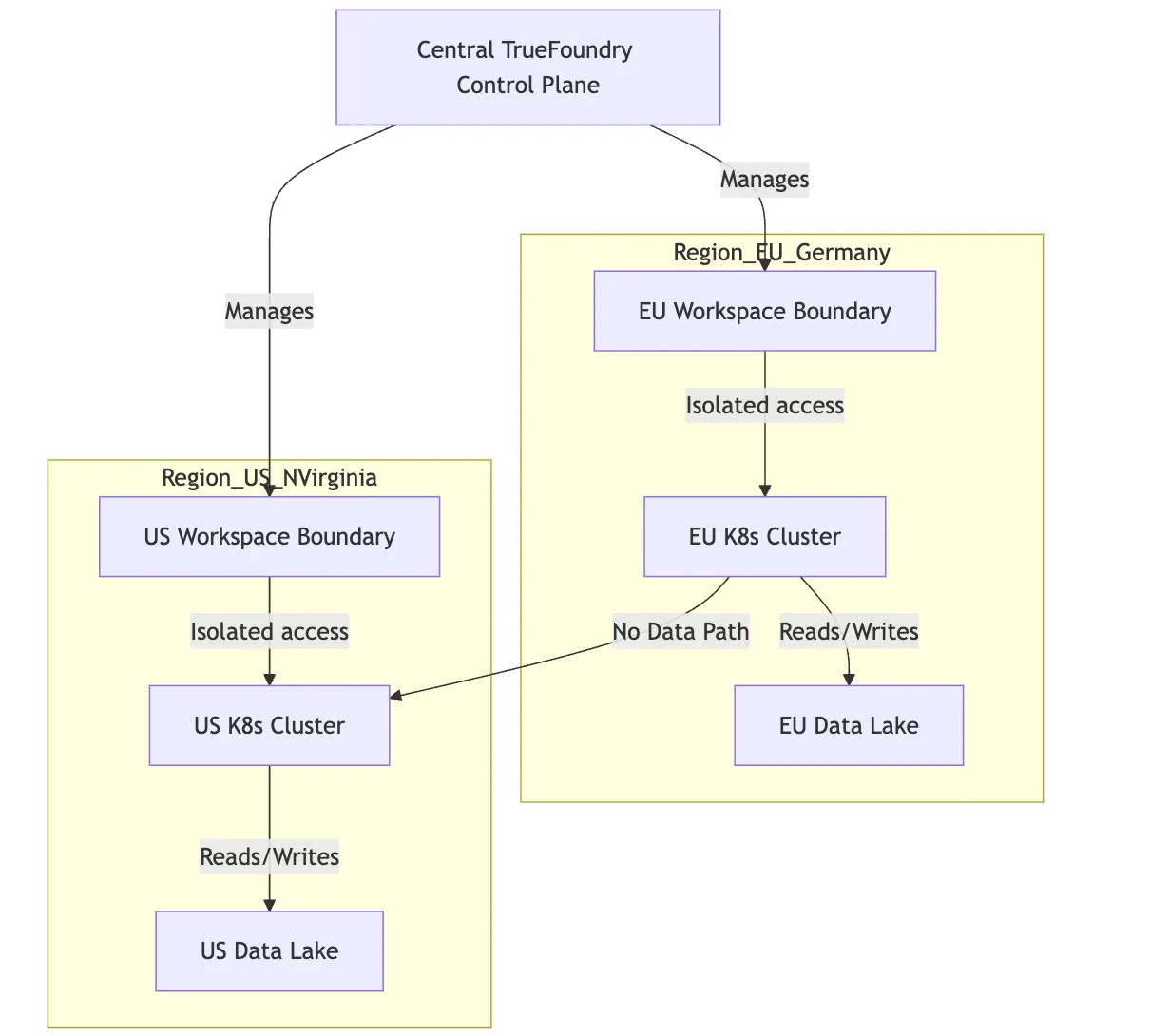
Figure 2 : Schéma de l'isolation multirégionale à l'aide d'espaces de travail
La résidence de données est rarement une activité passionnante, mais elle est fondamentale. Si vous vous trompez, rien d'autre ne compte.
La beauté de l'architecture de TrueFoundry réside dans le fait qu'elle n'essaie pas d'être elle-même un « bunker de données sécurisé ». Au contraire, il respecte les bunkers que vous avez déjà créés dans AWS, Azure ou GCP. Cela nous permet de fournir à nos data scientists une expérience de déploiement moderne, similaire à celle d'Heroku, sans devoir constamment nous battre contre notre équipe InfoSec pour les exceptions. Nous définissons le périmètre une fois, y associons TrueFoundry et cessons de nous inquiéter d'une sortie accidentelle de données.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


