

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: May 28, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les systèmes d'IA ne sont plus des outils passifs. Ils sont de plus en plus agentique - fonctionner de manière autonome sur les flux de travail, les API et les données sensibles de l'entreprise. Dans les systèmes traditionnels, la résidence des données était définie par l'endroit où les données étaient stockées. Une fois que les bases de données et le stockage étaient installés dans des régions approuvées, la conformité était considérée comme résolue.
L'IA agentique invite ce modèle. Chaque interaction génère de nouvelles surfaces de données - les invitations, la mémoire de l'agent, les journaux, les traces et les données d'inférence transitoires, qui sont traitées et observées au moment de l'exécution, souvent dans différentes régions, même lorsque rien n'est persistant.
Par conséquent, la résidence des données n'est plus une case à cocher de conformité. C'est un base infrastructure problem now discuté au niveau du conseil d'administration. La question à laquelle les entreprises doivent répondre est simple : Où se déplacent les données générées par l'IA au moment de l'exécution et qui contrôle ces chemins ?
Danse True Foundry, la résidence des données est appliquée au Passerelle IA, où l'inférence, les agents et les outils convergent. La résidence est traitée comme system property, appliqué dans des conditions normales de fonctionnement, de pannes et d'échelle. Ce blog explique comment la résidence des données est définie, appliquée et vérifiée dans TrueFoundry AI Gateway.
La résidence des données était plus simple lorsque les applications disposaient de chemins de données prévisibles. Les demandes provenaient des utilisateurs vers des services ou des bases de données, généralement au sein d'une seule région, et les contrôles de conformité étaient en grande partie statiques.
Les systèmes d'IA cassent ce modèle au moment de l'exécution.
Dans les architectures d'IA modernes, le mouvement des données est dynamique et axé sur les décisions, non réparé. Une seule demande utilisateur peut déclencher plusieurs chemins d'exécution, tous orchestrés par AI Gateway. C'est là que la résidence des données devient fragile.
Au moment de l'exécution, une passerelle IA peut :
Chacune de ces décisions peut introduire implicite data movement, souvent à l'insu de l'application.
Les défaillances de résidence des données les plus courantes dans les systèmes d'IA se produisent :
De manière critique, ces échecs se produisent même lorsque :
Ces défaillances ont toutes un point commun : elles surviennent chez exécution, en fonction du routage, des nouvelles tentatives, de l'exécution de l'agent et du comportement de journalisation.
AI Gateway est la seule couche qui :
C'est pourquoi la résidence des données dans les systèmes d'IA ne peut être garantie par la seule configuration de déploiement. Il doit être appliqué to AI Gateway, où les chemins d'exécution sont déterminés en temps réel.
Sur des plateformes comme True Foundry, la résidence est traitée comme strict enforcement contrainte, ce n'est pas la meilleure option pour garantir qu'aucun chemin d'exécution, y compris les scénarios de défaillance, ne peut violer les frontières régionales.
Les systèmes d'IA agentic ne se contentent pas utiliser data, ils générer en permanence de nouvelles surfaces de données au moment de l'exécution. Ces surfaces n'existaient pas dans les applications traditionnelles, et elles modifient fondamentalement ce que doit prendre en compte la résidence des données.
Dans les systèmes d'IA, la residence des données n'est plus limitée aux données au repos. Elle s'étend à toutes les données créées, traitées ou observées lors de l'inférence et de l'exécution de l'agent, même si ces données n'existent que brièvement.
Les plus importantes de ces nouvelles obligations en matière de données sont souvent les moins visibles.
Les demandes d'inférence portent invitations et réponses via l'AI Gateway, qui contient fréquemment une logique propriétaire, des données clients ou un contexte interne sensible. Contrairement aux API traditionnelles, ces données sont de forme libre et non nettoyées, ce qui les rend particulièrement risquées.
Présentation du flux de travail des agences context and persistent memory à travers les interactions. Si cet état est traité ou rejoué en dehors des régions approuvées, la résidence est violée, même lorsque les appels d'inférence individuels semblent conformes.
Les systèmes d'IA génèrent également journaux, traces, intégrations et métadonnées d'exécution qui peut coder des informations sensibles. Si les pipelines d'observabilité exportent ces données d'une région à l'autre, les violations se produisent silencieusement.
Surtout, les données n'ont pas besoin d'être stockées pour être non conformes. Transitoires Inference Data, traité uniquement en mémoire pendant des millisecondes, est toujours soumis aux exigences de résidence s'il franchit une frontière juridictionnelle.
Les contrôles de résidence traditionnels ont été conçus pour les systèmes statiques, et non pour le routage dynamique, les nouvelles tentatives, le basculement et l'exécution pilotée par un agent. Dans les systèmes d'IA, la résidence doit être imposée au moment de l'exécution, où ces chemins de données sont créés.
Sur des plateformes comme True Foundry, cette mise en application au lieu de Passerelle IA, où les instructions, le contexte de l'agent, les nouvelles tentatives et la télémétrie convergent, faisant de la résidence une propriété du système plutôt qu'une hypothèse.
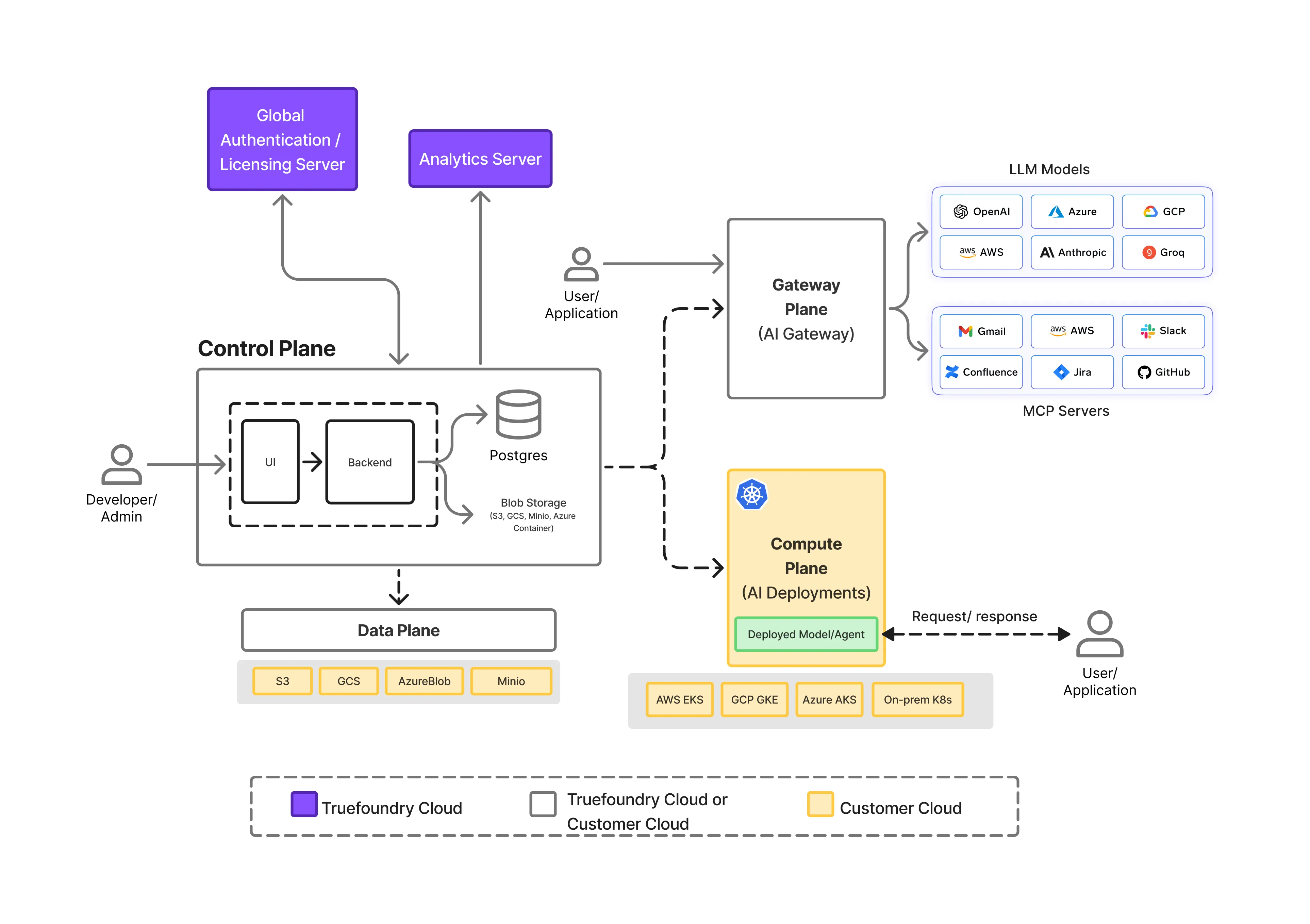
L'application de la résidence des données dans les systèmes d'IA ne se limite pas à un simple déploiement régional. Cela nécessite claire séparation des responsabilités à travers la pile d'IA, afin que l'exécution, le contrôle et les chemins de données puissent être régis indépendamment.
TrueFoundry est conçu autour d'un plan divisé architecture cela rend cela possible.
À un niveau élevé, la plate-forme est composée de trois plans distincts :
Cette séparation est essentielle à la manière dont la résidence des données est appliquée de manière fiable au moment de l'exécution.
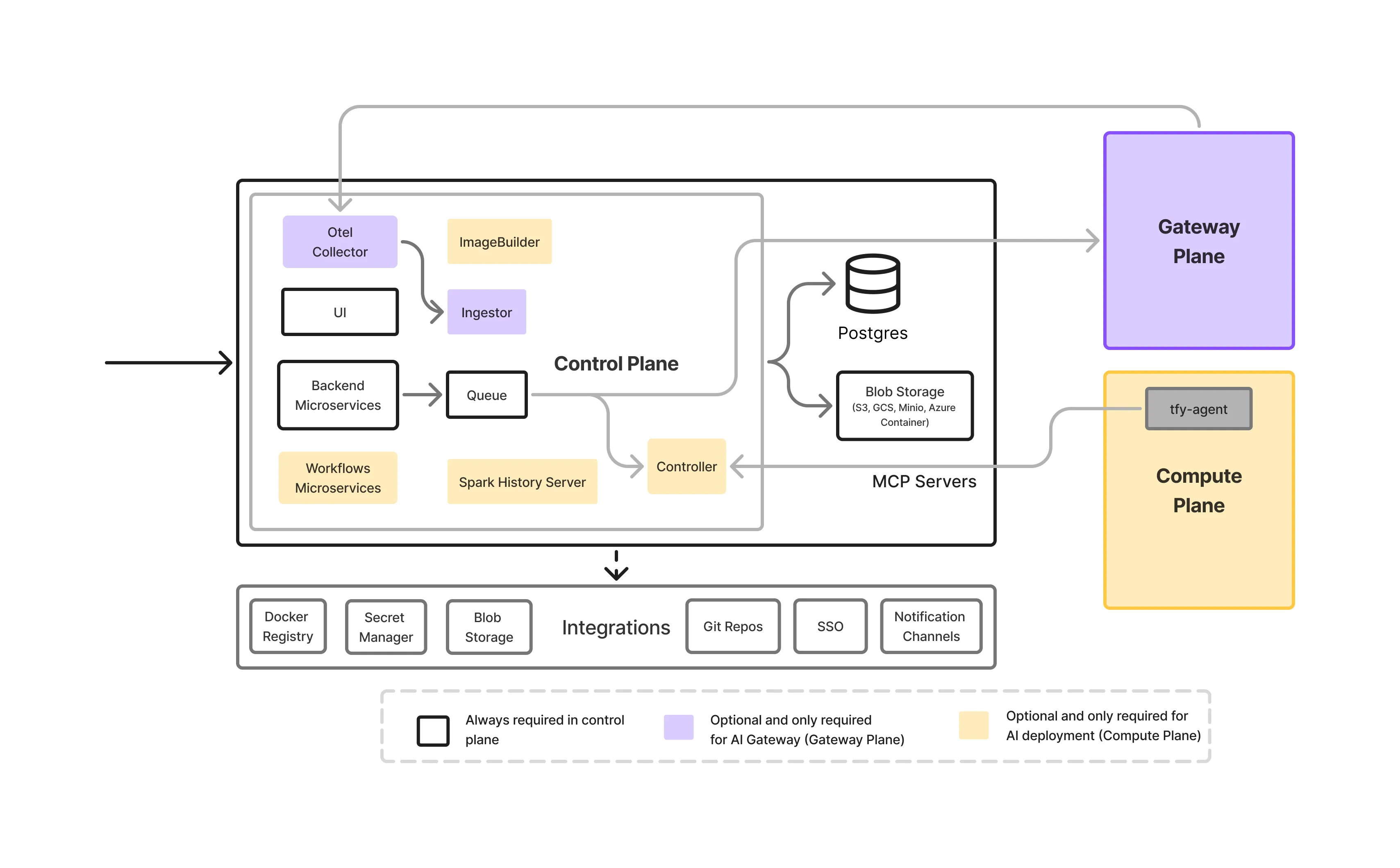
Le control plan est la couche d'orchestration de la plateforme TrueFoundry. Il est chargé de :
De manière critique, le plan de contrôle ne traite pas le trafic d'inférence et n'exécute pas de charges de travail. Il définit que devrait-il passer, pas où les données circulent au moment de l'exécution.
Pour les entreprises ayant des exigences de conformité strictes, TrueFoundry prend en charge à la fois :
Cela permet aux organisations de trouver le juste équilibre entre simplicité opérationnelle et exigences de souveraineté, sans modifier la façon dont l'application du droit de résidence fonctionne en aval.
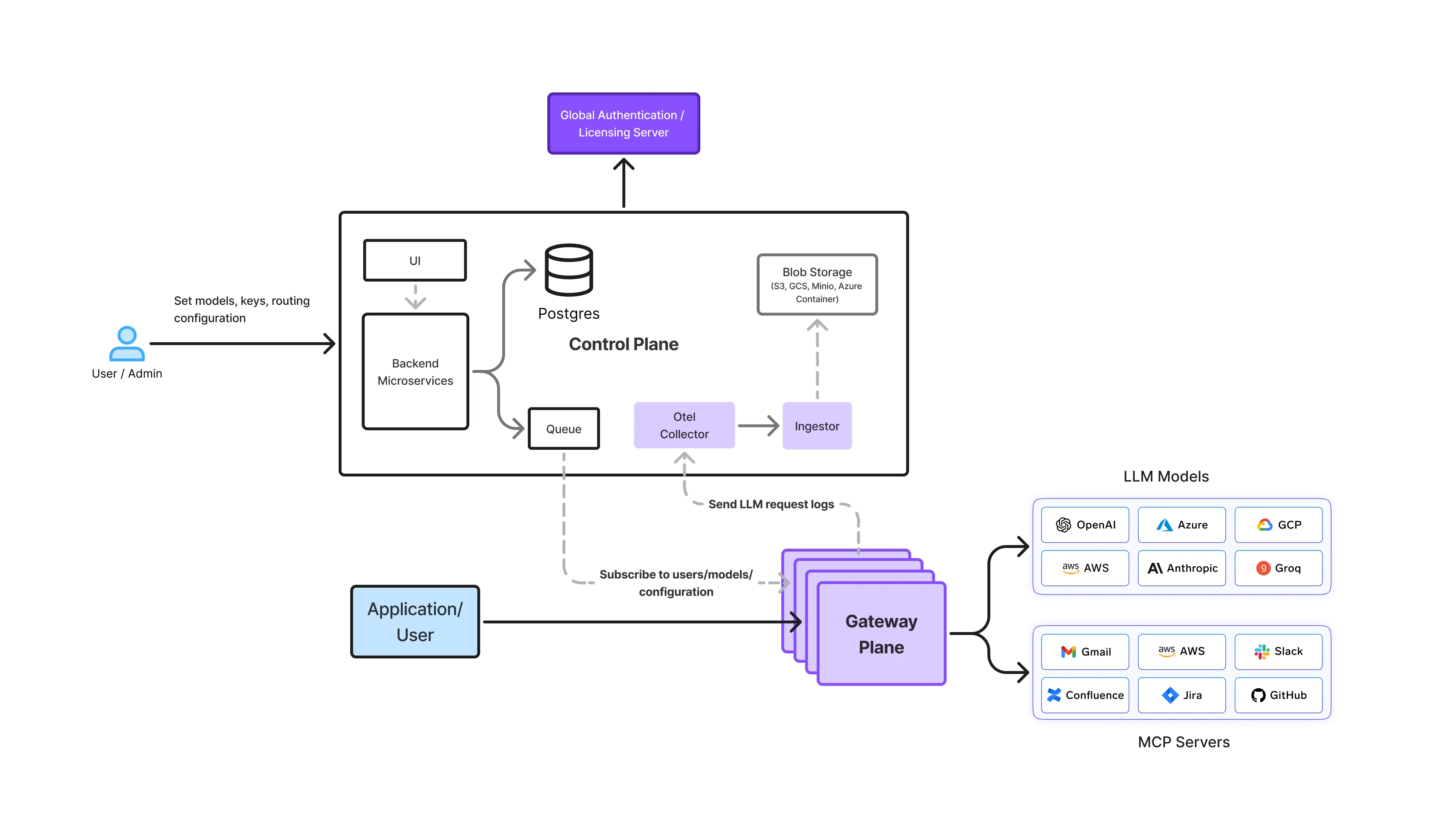
Le passerelle plan est l'endroit où la résidence des données est activement appliquée.
Les passerelles TrueFoundry AI se situent entre les applications et tous les fournisseurs de modèles, agissant comme suit :
Chaque demande d'inférence, nouvelle tentative, basculement, appel d'agent et événement d'observabilité passe par la passerelle. Cela lui donne une visibilité complète sur :
De ce fait, le plan de passerelle est le seule couche capable d'imposer la résidence des données en tant que contrainte stricte.
Si une demande ne peut être satisfaite dans les limites de résidence configurées, la passerelle request closure échec plutôt que de l'acheminer silencieusement vers une région non conforme.
C'est la principale différence entre application des règles d'exécution et une configuration optimale.
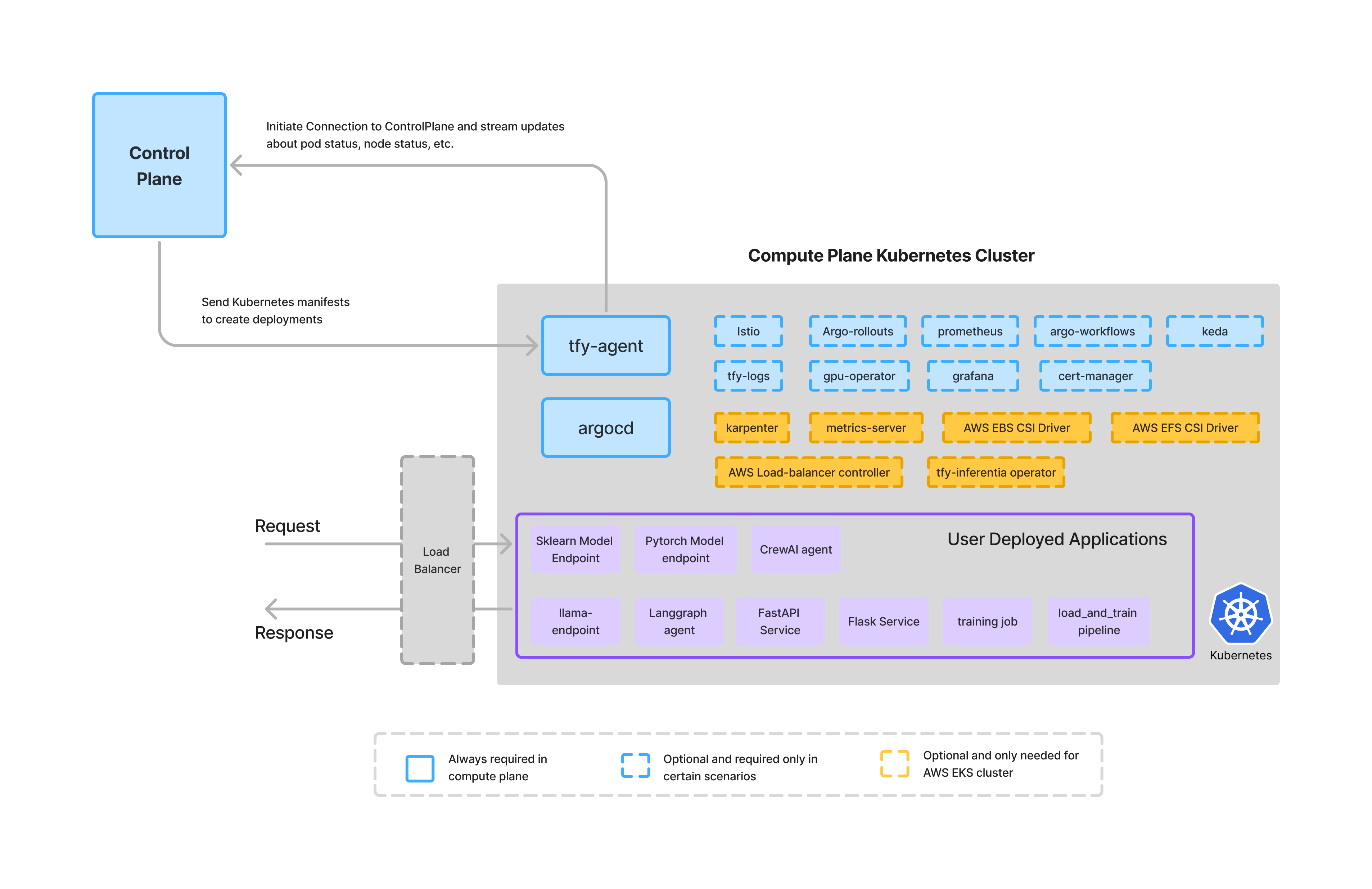
Le plan de calcul est l'endroit où les applications, les agents et les charges de travail s'exécutent réellement.
Dans TrueFoundry, le plan de calcul :
Cette conception garantit que :
TrueFoundry n'exécute pas les charges de travail des clients sur un calcul partagé. Au lieu de cela, il s'intègre aux clusters existants du client ou aide à en fournir de nouveaux, tout en maintenant l'exécution dans les limites de confiance de l'organisation.
Cette séparation des plans permet à TrueFoundry d'imposer la résidence des données sans compromis:
Étant donné que l'application se fait au niveau de la passerelle, là où le routage, les nouvelles tentatives, les agents et les journaux convergent, la résidence des données est maintenue même dans les limites suivantes :
C'est ce qui permet à la résidence des données de devenir une system property, et non une hypothèse liée aux diagrammes de déploiement.
La résidence des données dans les systèmes d'IA n'est pas un simple changement, elle doit être appliquée dans exécution, routage et stockage. Danse True Foundry, ceci est réalisé grâce à trois modes d'application complémentaires qui, ensemble, couvrent le cycle de vie complet des données d'Ia.
Chaque mode répond à une catégorie différente de risque de résidence et peut être utilisé indépendamment ou en combinaison, en fonction des besoins de l'entreprise.
Pour les organisations ayant les besoins les plus stricts en matière de résidence et de conformité, TrueFoundry propose un modèle de déploiement où les données ne quittent jamais l'environnement du client.
Dans ce mode :
Cela vaut à la fois pour :
En garantissant que l'exécution et les chemins de données restent entièrement au sein de l'infrastructure contrôlée par le client, ce mode fournit les meilleures garanties de résidence possibles et simplifie les audits réglementaires.
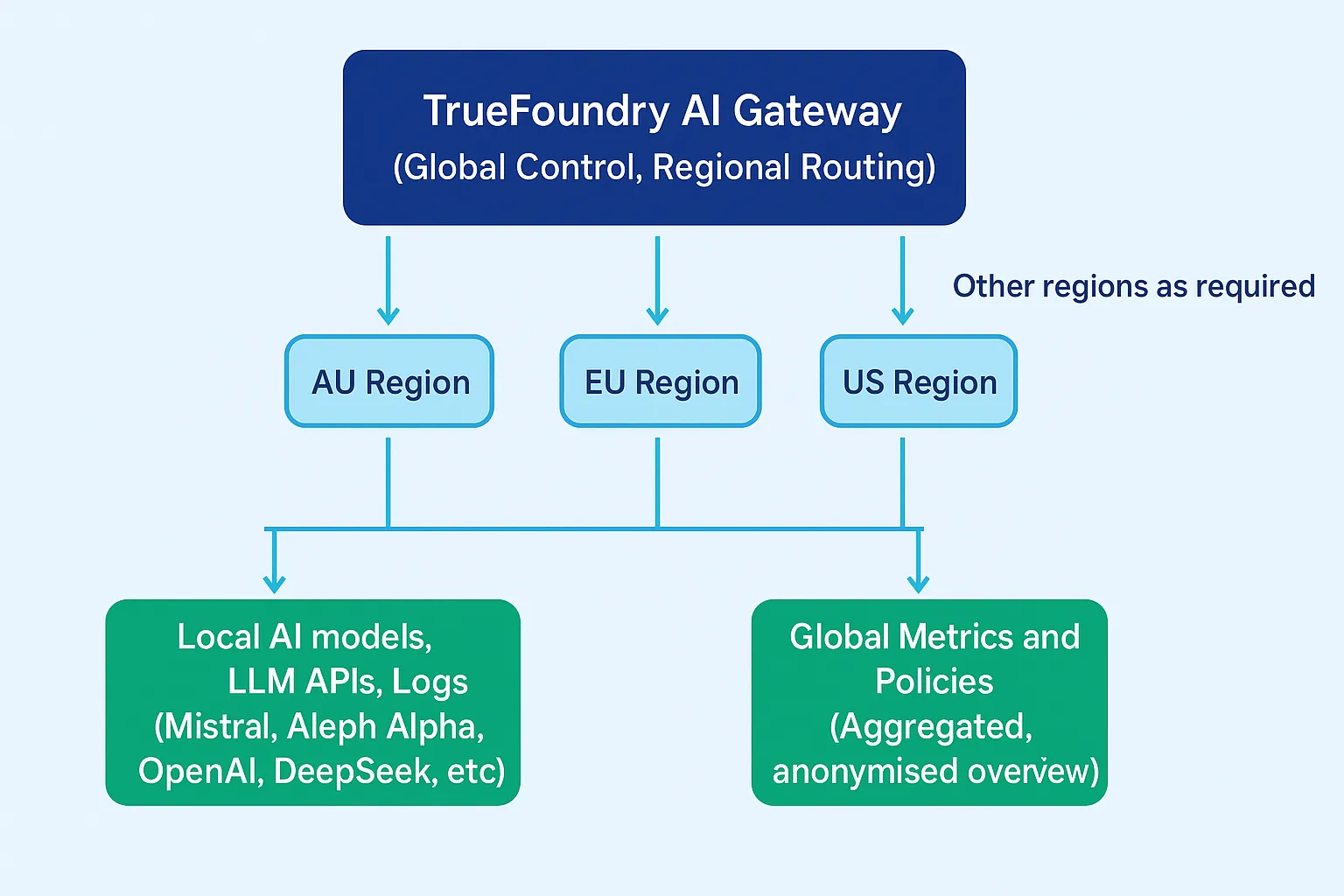
De nombreuses entreprises doivent opérer à l'échelle mondiale tout en veillant à ce que les données relatives à une zone géographique donnée ne franchissent jamais les frontières juridictionnelles.
TrueFoundry applique cela grâce à déploiements d'AI Gateway spécifiques à une région:
Les applications choisissent explicitement le point de terminaison de passerelle régional à utiliser. This made of the data residence :
S'il n'existe aucun chemin d'exécution conforme à la résidence pour une demande, la passerelle request closure échec plutôt que de l'acheminer vers une autre région. Cela garantit que les mécanismes de disponibilité ne l'emportent jamais sur l'intention de conformité.
L'inférence et l'exécution ne constituent qu'une partie de l'histoire de la résidence des données. Journals, traces, instructions et télémétrie contiennent souvent des informations tout aussi sensibles et doivent suivre les mêmes règles de résidence.
TrueFoundry permet aux entreprises d'imposer la résidence au niveau de la couche de stockage en :
Cela permet de :
Étant donné que ces choix de stockage sont intégrés directement dans la configuration d'AI Gateway et du SDK, les données d'observabilité bénéficient des mêmes garanties de résidence que le trafic d'inférence.
Chaque mode d'application permet de résoudre un problème différent :
Ensemble, ils veillent à ce que la résidence des données soit appliquée :
Cette approche en couches permet à TrueFoundry de transformer la résidence des données en configuration optimale dans un property system verifiable and applied at the moment of the exécution.
Danse True Foundry, la résidence des données est imposée par plusieurs couches explicites au sein de l'AI Gateway, chacun abordant une classe différente de risque d'exécution.
Ces couches travaillent ensemble pour garantir que les garanties de résidence sont maintenues dans des conditions réelles.
Dans les systèmes d'IA, les garanties de résidence des données ne sont valables que si elles sont appliquées au moment de l'exécution, sur tous les chemins d'exécution, et pas seulement pendant le fonctionnement en régime permanent. Danse True Foundry, l'AI Gateway est le point d'application où convergent les décisions de routage, les nouvelles tentatives, l'exécution des agents et l'observabilité.
Les mécanismes suivants expliquent comment la résidence des données est appliquée de manière déterministe à l'intérieur de la passerelle TrueFoundry AI.
Les modèles de TrueFoundry sont enregistrés auprès de explicite region affinity. L'AI Gateway évalue les contraintes de résidence before the routage n'importe quelle demande et ne choisit que les points de terminaison du modèle qui sont éligibles pour la région autorisée de la charge de travail.
Cela permet d'éviter :
Parce que la résidence est traitée comme hard routing contrainte, ce n'est pas une préférence, les modèles non conformes ne sont jamais pris en compte, même s'ils sont disponibles ou plus rapides.
Les nouvelles tentatives et les chemins de basculement sont les sources les plus courantes de violations de données silencieuses relatives à la résidence dans les systèmes d'IA.
La passerelle IA de TrueFoundry applique :
Cela garantit que les mécanismes de disponibilité ne l'emportent jamais sur l'intention de conformité. Si un chemin conforme n'est pas disponible, le système échoue explicitement au lieu d'acheminer les données entre les régions.
Pour les charges de travail des agences, la résidence des données doit rester cohérente sur inférence de modèles et appel d'outils en aval.
Applique TrueFoundry :
Cela élimine un mode de défaillance courant dans lequel l'inférence reste conforme, mais où les agents divulguent des données indirectement via des outils ou des serveurs MCP déployés dans d'autres régions.
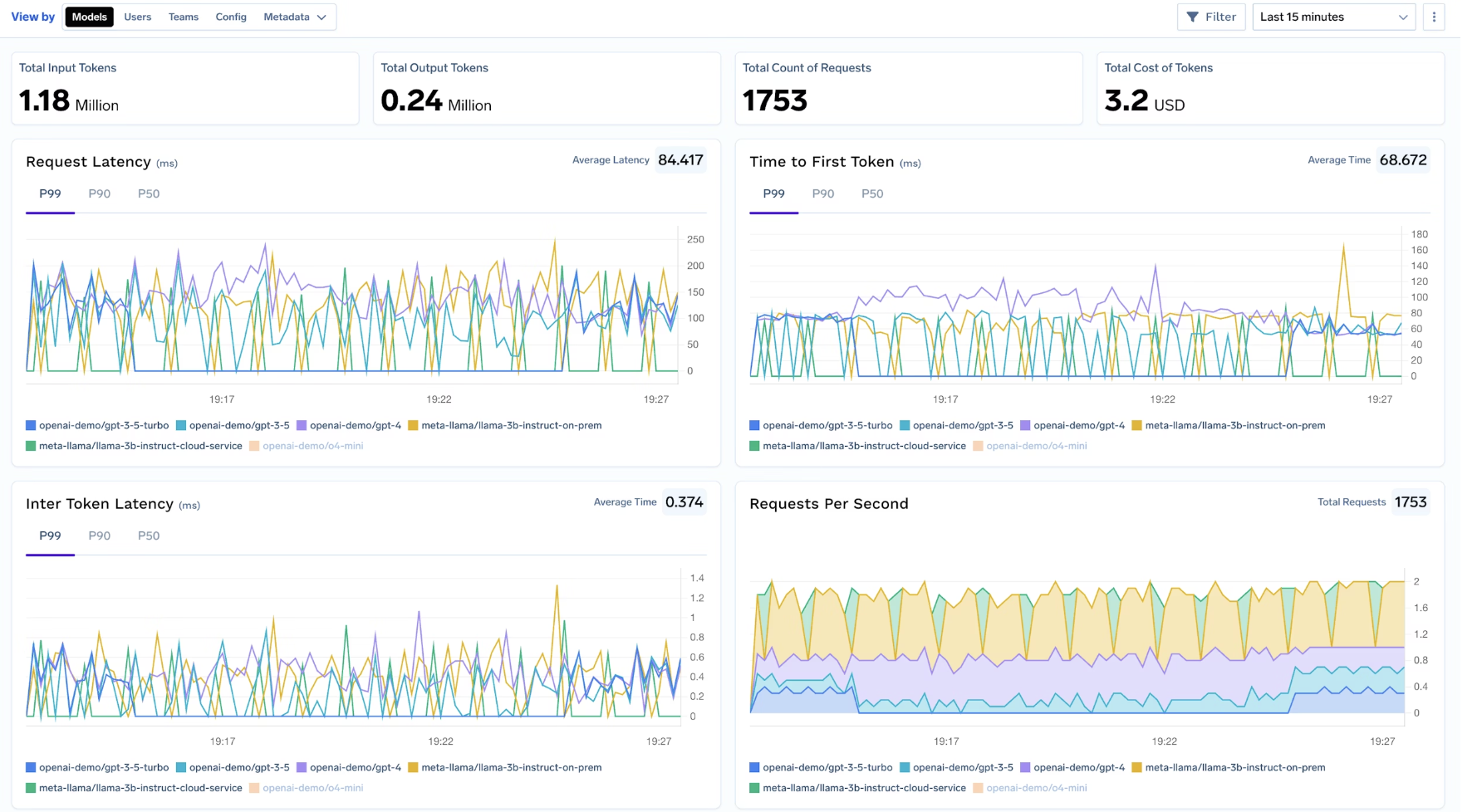
Les pipelines d'observabilité sont souvent négligés dans les conceptions de résidence des données, alors qu'ils contiennent souvent very sensitive data.
La passerelle IA de TrueFoundry garantit que :
Cela comble l'une des lacunes de résidence les plus persistantes dans les systèmes d'IA, où l'inférence est conforme mais pas les journaux et les traces.
Ces mécanismes d'application s'appliquent de manière uniforme dans les domaines suivants :
Parce que l'exécution se produit avant l'exécution, la résidence des données devient verifiable system property, ce n'est pas une configuration optimale liée au placement de l'infrastructure.
La plupart des violations de résidence des données dans les systèmes d'IA ne sont pas causées par des erreurs de configuration évidentes. Ils émergent de cas limites et chemins d'exception qui sont rarement testés jusqu'à ce que quelque chose se passe mal.
Vous trouverez ci-dessous les scénarios de défaillance les plus courants rencontrés par les entreprises et la manière dont Passerelle TrueFoundry AI est conçu pour les prévenir.
Que se passe dans de nombreux systèmes
Un point de terminaison de modèle régional n'est plus disponible. L'AI Gateway réessaie automatiquement ou bascule vers le prochain point de terminaison disponible, souvent dans une autre région.
Du point de vue de la disponibilité, cela semble être une réussite.
Du point de vue de la conformité, il s'agit d'une violation silencieuse.
Comment TrueFoundry évite cela
Cela garantit que les mécanismes de disponibilité ne prévalent jamais sur la politique de résidence.
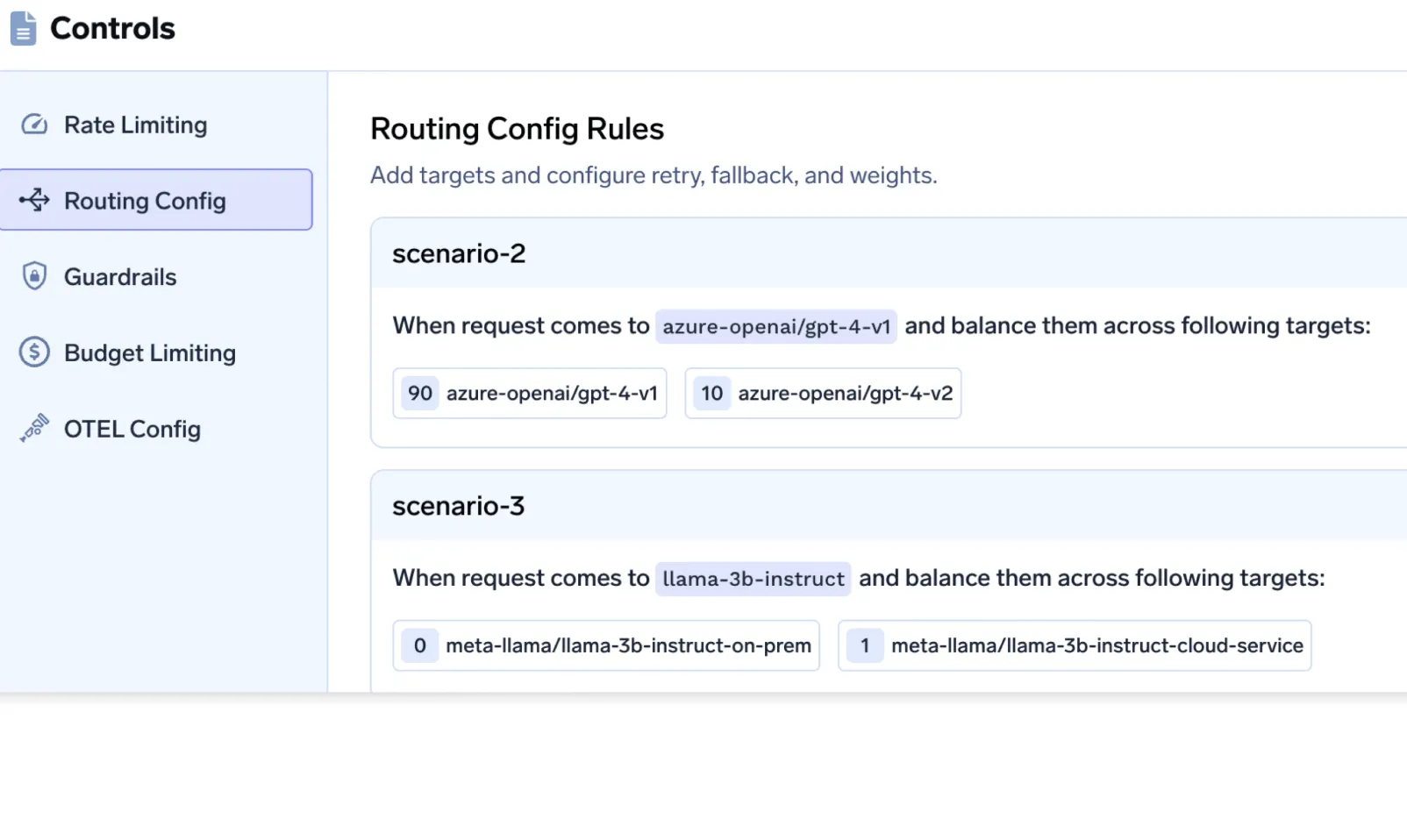
Que se passe dans de nombreux systèmes
Certains modèles sont déployés dans une région, tandis que d'autres (souvent des sauvegardes ou des modèles plus récents) sont hébergés dans le monde entier. Les politiques de routage sélectionnent involontairement des modèles non résidents.
Comment TrueFoundry évite cela
Cela rend les garanties de résidence résistantes à l'abandon des modèles et à l'expérimentation.
Que se passe dans de nombreux systèmes
L'inférence s'exécute localement, mais les agents invoquent des outils ou des serveurs MCP déployés dans d'autres régions, ce qui crée un mouvement de données indirect.
Comment TrueFoundry évite cela
Cela permet de maintenir la cohérence de la résidence dans toutes les inférences et exécution en aval.
Que se passe dans de nombreux systèmes
Les invitations, les réponses et les traces sont exportées vers des services de journalisation ou de surveillance centralisés en dehors de la région, souvent par défaut.
Comment TrueFoundry évite cela
Cela comble l'une des lacunes de conformité les plus fréquemment négligées dans les systèmes d'IA.
Les garanties de résidence n'ont de sens que si elles peuvent l'être vérifié et démontré. TrueFoundry permet aux entreprises de valider la résidence des données via performance visibility and auditability, et non des hypothèses post-hoc.
AI Gateway fournit de la visibilité sur :
Cela permet aux équipes de confirmer que chaque chemin d'exécution est resté conforme.
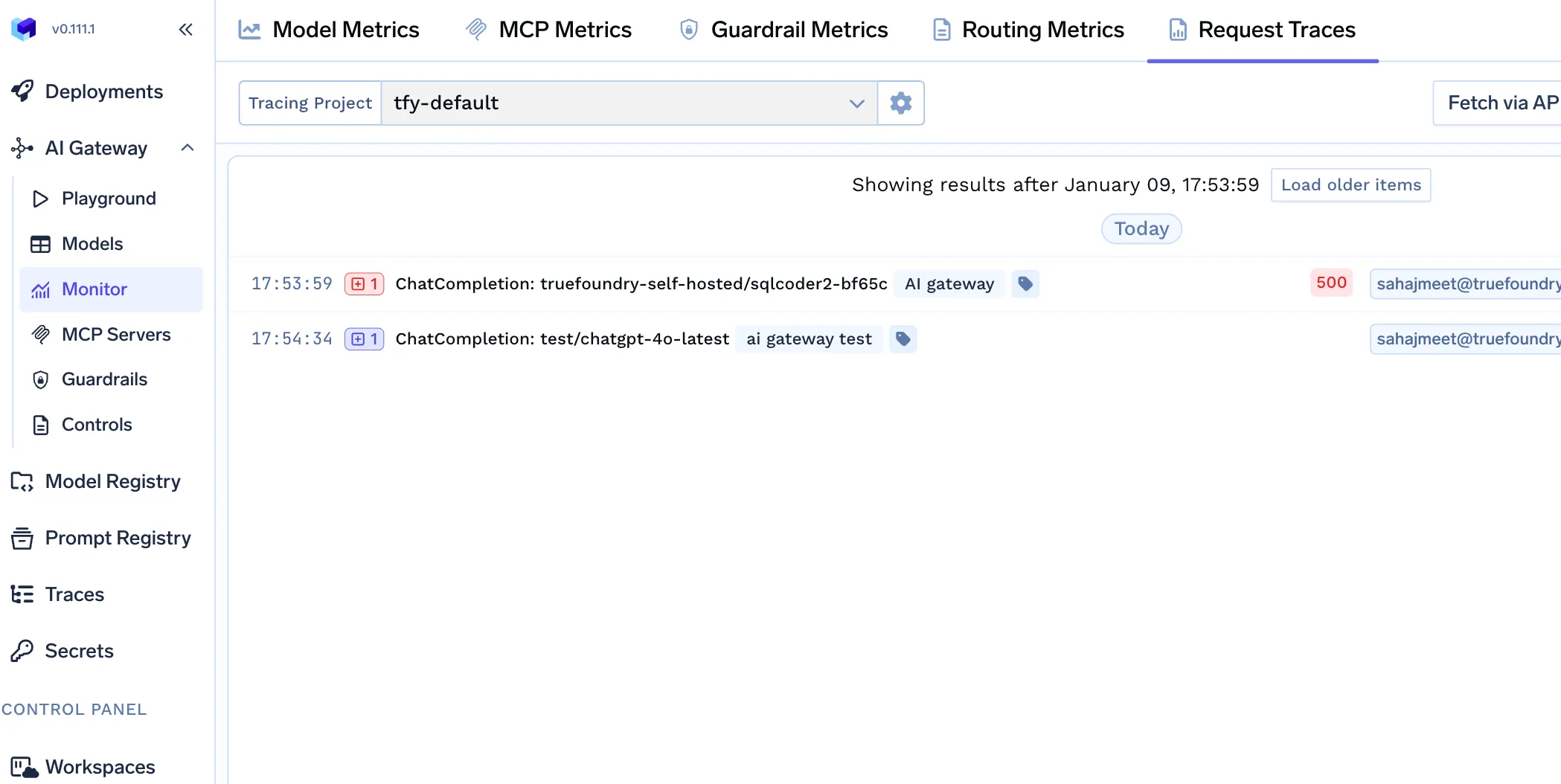
Pour les examens de conformité et de sécurité, TrueFoundry propose les surfaces suivantes :
Cela permet de prouver la résidence lors des audits, plutôt que de s'appuyer uniquement sur des schémas architecturaux.
L'un des principaux avantages de l'application au niveau de la passerelle est la testabilité.
Les entreprises peuvent :
Cela transforme la résidence d'une exigence statique en une property of the system verifiable in permanance.
Dans les systèmes d'IA modernes, la résidence des données ne peut être garantie par les seuls choix de déploiement. Le routage dynamique, les nouvelles tentatives, les flux de travail des agents et les pipelines d'observabilité introduisent tous des chemins d'exécution permettant aux données de franchir silencieusement les frontières régionales.
Le Passerelle IA est la seule couche dotée d'un contexte suffisant pour empêcher cela. Il voit chaque demande d'inférence, chaque nouvelle tentative, chaque action de l'agent et chaque trace émise par le système. Si la résidence n'est pas imposée ici, elle ne peut pas être appliquée de manière uniforme ailleurs.
Danse True Foundry, la résidence des données est traitée comme property of the system of exécution. Les voies d'exécution sont limitées par conception, les cas d'exception échouent et l'application est observable et vérifiable. Cela rend les garanties de résidence résilientes, non seulement en période d'équilibre, mais également en cas de défaillance, d'ampleur et de changement.
Pour les entreprises qui déploient l'IA dans des environnements réglementés ou multirégionaux, cette distinction est importante. La résidence des données n'est plus une case à cocher, c'est un engagement architectural. Et c'est grâce à AI Gateway que cet engagement devient réalité.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


