

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !

C'est un scénario familier pour les équipes opérationnelles à 10 heures du matin : un flux de travail critique doit être automatisé (vérification de l'inventaire des fournisseurs, analyse des prix compétitifs ou obtention de réservations) mais la plateforme cible n'offre aucun accès programmatique.
À l'ère de la connectivité, de nombreuses plateformes à forte valeur ajoutée bloquent leurs données derrière des « douves numériques ». Ils ne disposent pas d'API publiques, ce qui oblige les développeurs à s'appuyer sur la solution de repli qu'est le web scraping. Cependant, le grattage traditionnel est notoirement fragile. Il repose sur des « sélecteurs fragiles », c'est-à-dire des chemins CSS codés en dur ou des XPaths (par exemple, div.btn-primary) qui s'interrompent dès qu'un développeur frontend change le nom d'une classe en btn-submit.
Pour y remédier, nous avons créé le Accélérateur automatique des réservations de restaurants. Il s'agit d'une implémentation de référence pour une nouvelle catégorie d'automatisation : les agents résilients qui ne se contentent pas de « scraper » le Web, mais qui le font fonctionner.
L'innovation fondamentale de cet accélérateur est de passer du modèle objet de document (DOM) au profit du Modèle d'objet d'accessibilité (AOM).
Dans un script traditionnel, si un bouton passe d'une barre latérale à un en-tête, l'automatisation échoue. Dans ce système agentic, nous fournissons au moteur d'inférence un instantané de l'arbre d'accessibilité. Il s'agit d'une représentation sémantique de la page conçue pour les lecteurs d'écran, supprimant les modifications de style pour révéler l'utilité fondamentale de l'interface.
Cela permet au système de raisonner en fonction de l'intention plutôt que des coordonnées : « Je vois un widget de calendrier ; je vais cliquer sur la date « 15 » car elle correspond à la demande de l'utilisateur. » Si le site fait l'objet d'une refonte mais que le rôle sémantique du bouton reste « Confirmer la réservation », l'agent s'auto-guérit et le flux de travail fonctionne correctement.
Nous avons structuré l'application à l'aide d'un outil spécialisé Contrôleur/travailleur motif. Plutôt qu'un script monolithique, nous avons des agents distincts utilisant Dramaturge pour l'exécution et LLM pour la prise de décisions.
Figure 1 : Architecture de haut niveau
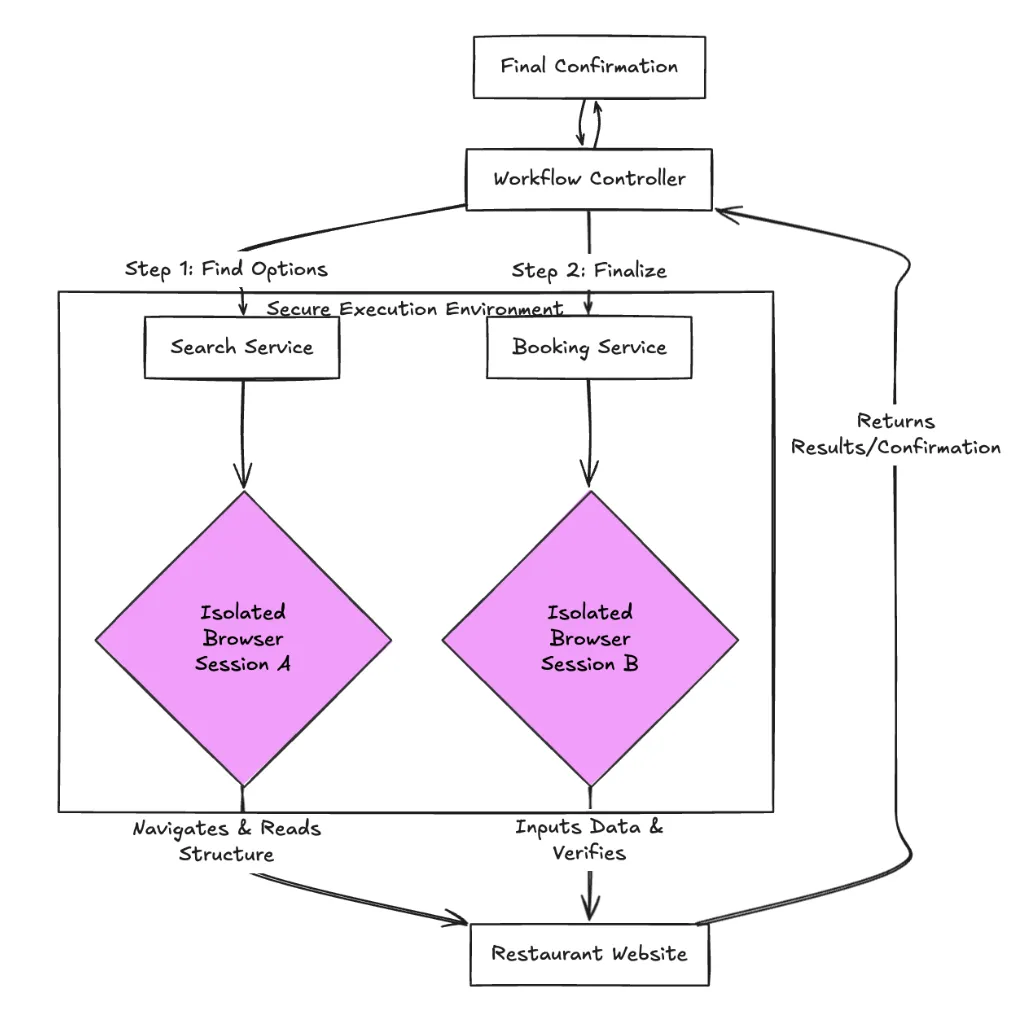
Comme le montre le schéma d'architecture, contrôleur de flux de travail gère l'état en déléguant des tâches à deux composants spécialisés :
L'utilisation de ces agents en production nécessite un plan de contrôle robuste. Nous utilisons Plateforme TrueFoundry pour gérer l'infrastructure et Protocole de contexte modèle (MCP) pour standardiser l'intégration des navigateurs.
Figure 2 : Comment TrueFoundry prend en charge le cycle de vie des applications
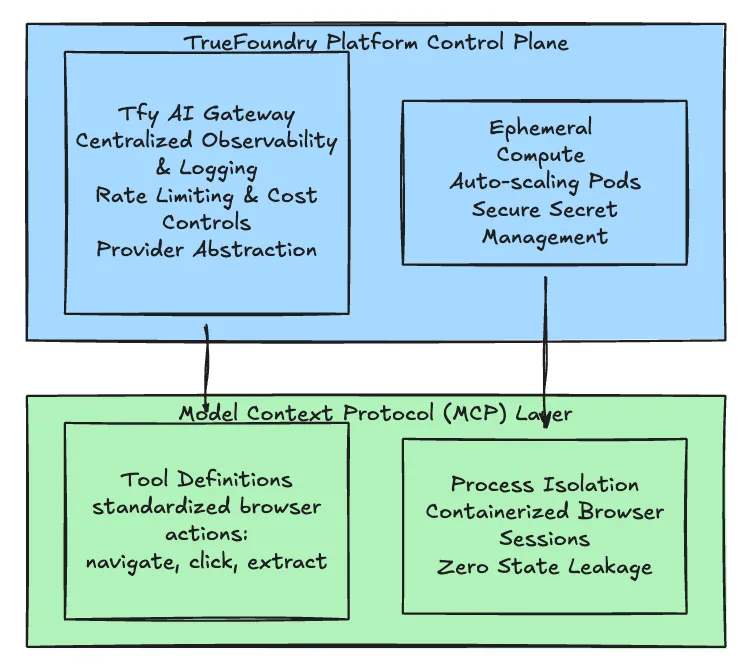
Pour les flux de travail transactionnels, nous mettons en œuvre un « Vérifier-puis exécuter » motif. L'agent effectue le gros du travail de la découverte mais nécessite une confirmation humaine avant l'exécution finale.
Étape 1 : Intention et découverte
Le système accepte les entrées en langage naturel et les normalise en JSON structuré (Location, Heure, Taille du groupe) pour l'agent de recherche.
Étape 2 : La porte de confirmation
Lorsqu'il trouve un créneau, l'agent de réservation fait une pause. Il présente les détails à l'utilisateur et passe en état d'attente, ne procédant qu'après avoir reçu un signal clair.
Le test le plus critique d'un agent Web est sa capacité à gérer des scénarios « Human-in-the-Loop » (HITL). Les sites modernes utilisent souvent des pare-feux d'applications Web (WAF) qui déclenchent des CAPTCHA ou des codes de vérification par e-mail lorsqu'ils détectent une automatisation.
Un script standard échoue ici. Notre système utilise un Machine à états de pause et de reprise.
Figure 3 : Logique d'état de gestion des exceptions
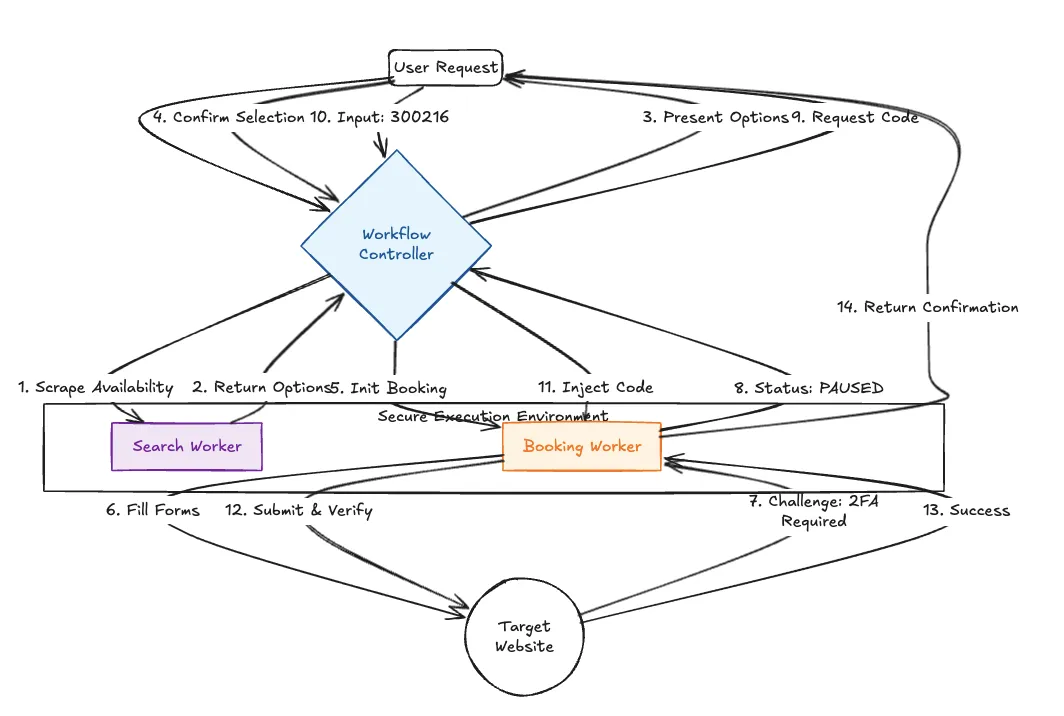
Comme indiqué dans le schéma ci-dessus (étapes 7 à 11), lorsque l'agent détecte une invite de défi :
Nous sommes en train de passer du « Web Scraping » au « Web Operating ». En utilisant Playwright pour les « mains » et l'inférence sémantique pour les « yeux », nous pouvons traiter le Web orienté vers l'humain comme une interface programmatique.
Cet accélérateur démontre qu'avec une architecture adaptée : interprétation sémantique, orchestration dynamique et infrastructure sécurisée telle que True Foundry—nous pouvons créer des automatisations résilientes qui comblent les lacunes en matière d'API.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


