

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Nous avons tous connu ce moment avec l'interpréteur de code de ChatGPT (désormais « Analyse avancée des données »). Vous chargez un fichier CSV désordonné, vous lui demandez de « fixer les dates et tracer la tendance », et vous le regardez avec émerveillement écrire et exécuter du code Python en temps réel.
C'est une super arme en matière de productivité. Il s'agit également d'une faille de sécurité massive si vous travaillez avec des données sensibles.
Au moment où vous chargez ce fichier CSV, il quitte votre périmètre. Pour notre équipe, l'objectif était de reproduire cette fonctionnalité « OpenCode », en donnant à nos agents LLM la capacité d'écrire et d'exécuter du code, sans risques d'exfiltration de données. Nous ne voulions pas d'API « boîte noire » ; nous avions besoin d'une Interprète de code privé où le calcul s'effectue à côté des données.
Voici comment nous avons mis en œuvre une utilisation sécurisée des outils et une exécution de code à l'aide des composants d'infrastructure de TrueFoundry.
« OpenCode » ne consiste pas simplement à disposer d'un modèle capable d'écrire Python. Elle nécessite trois composants distincts qui fonctionnent à l'unisson :
La plupart des gens restent bloqués sur « The Hands ». Vous ne pouvez pas simplement laisser un LLM exécuter os.system ('rm -rf /') sur votre cluster de production. Tu as besoin d'un bac à sable.
TrueFoundry résout ce problème en nous permettant de déployer environnements d'exécution éphémères (Services ou Jobs) qui font office de bac à sable. La passerelle LLM gère les définitions d'utilisation des outils, et l'exécution proprement dite a lieu dans un conteneur verrouillé au sein de notre VPC.
Voici le flux de travail qui explique comment une demande utilisateur se transforme en exécution de code sécurisée.
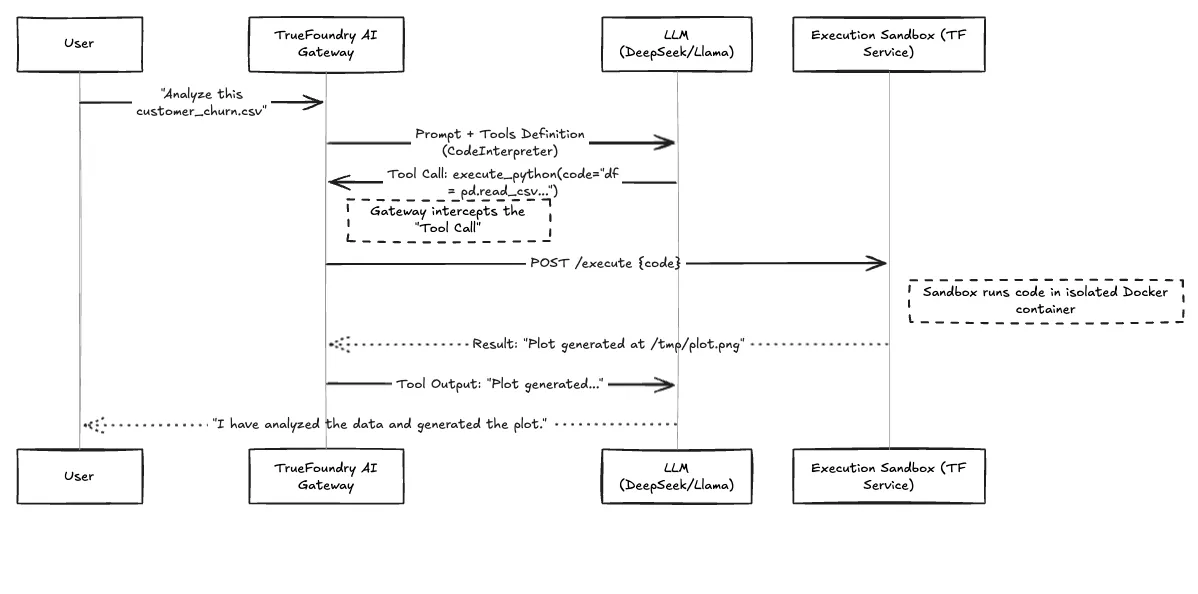
Figure 1 : Flux de travail de la boucle d'exécution OpenCode
Lorsque nous avons essayé de le créer pour la première fois, nous avons sous-estimé la complexité de l'environnement d'exécution. Si vous utilisez une API d'interprétation de code SaaS standard, vous lui envoyez vos données. Si vous l'exécutez localement, vous risquez de compromettre l'hôte.
Nous utilisons TrueFoundry Des services pour héberger un « agent d'exécution de code » personnalisé. Il s'agit essentiellement d'un service Python FastAPI encapsulé dans un conteneur Docker qui contient :
Comme TrueFoundry gère le manifeste Kubernetes sous-jacent, nous pouvons injecter ces contraintes de sécurité (SecurityContext, NetworkPolicies) directement depuis l'interface utilisateur de déploiement ou Terraform, garantissant ainsi que le sandbox est véritablement un sandbox.
Le compromis a toujours été la commodité par rapport au contrôle. En utilisant TrueFoundry pour orchestrer le modèle « OpenCode », nous changeons l'équilibre. Nous bénéficions de la commodité d'un déploiement géré sans les risques liés aux données.
Tableau 1 : Voici un exemple de comparaison entre une passerelle et un bac à sable
Le véritable pouvoir se débloque lorsque vous combinez Utilisation de l'outil avec vos API internes.
Nous avons configuré la passerelle TrueFoundry LLM pour exposer non seulement l'outil « Python Interpreter », mais également des outils pour notre lac de données interne (par exemple, get_user_churn_metrics (user_id)).
Étant donné que le LLM est acheminé via la passerelle et que celle-ci est connectée à nos services privés, le modèle peut désormais :
Tout cela se fait sans qu'un seul octet de données client ne quitte notre sous-réseau privé.
La mise en œuvre d' « OpenCode » n'est plus seulement un projet de hackathon amusant ; c'est une exigence pour les agents d'IA modernes. Mais vous ne pouvez pas simplement le pirater avec LangChain et espérer que tout ira pour le mieux.
Nous traitons notre interpréteur de code comme infrastructures critiques. Nous le surveillons à l'aide de la pile d'observabilité de TrueFoundry, qui permet de suivre non seulement les jetons LLM, mais aussi les pics de processeur dans le sandbox et la latence d'exécution. Si un utilisateur écrit un script qui tente d'allouer 50 Go de RAM, TrueFoundry tue le pod avant qu'il n'affecte le cluster et l'utilisateur reçoit un message d'erreur poli.
C'est la différence entre une démo et une plateforme.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


