

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Nous avons dépassé la phase « découvrez cette démo sympa » de Voice AI. Les entreprises ne se contentent plus de développer de jolies compétences Alexa. Ils déploient des systèmes multimodaux complexes conçus pour gérer des millions d'interactions sensibles avec les clients, qu'il s'agisse de virements bancaires ou de triage médical.
Mais voici la triste vérité concernant le passage de l'IA vocale du prototype à la production : elle est incroyablement fragile.
Contrairement aux chatbots basés sur du texte, où un échec n'est qu'une mauvaise réponse textuelle, un échec dans Voice AI est viscéral. C'est de l'air mort. C'est une voix robotique qui bégaie. C'est un client qui crie « agent » ! à plusieurs reprises car la latence de la recherche RAG a pris 400 ms de trop et l'ASR les a interrompues.
Lorsque vous orchestrez un système tentaculaire impliquant la reconnaissance vocale automatique (ASR), la classification complexe des intentions, la génération agentique par extraction augmentée (RAG) et la synthèse vocale (TTS) réaliste, les outils standard de surveillance des applications (APM) sont totalement inadéquats. Ils te disent cette quelque chose s'est cassé, mais rarement pourquoi.
Cet article présente un cas d'utilisation réaliste à grande échelle pour une entreprise afin de démontrer pourquoi l'observabilité spécialisée n'est pas négociable et comment des plateformes telles que TrueFoundry sont en train de devenir le plan de contrôle de ces systèmes complexes.
Pour comprendre le défi de l'observabilité, nous devons d'abord examiner la « bête » que nous essayons d'apprivoiser. Un agent vocal conversationnel moderne n'est pas un modèle unique ; il s'agit d'une course relais de composants hautement spécialisés, souvent répartis sur différentes infrastructures.
Si un transfert échoue dans cette course de relais, toute l'expérience utilisateur se bloque.
Imaginons Apex Financial, une grande banque déployant un assistant vocal pour gérer les transactions de niveau intermédiaire, telles que la vérification des soldes de différentes classes d'actifs et l'initiation de virements internationaux.
L'échelle : 50 000 appels simultanés aux heures de pointe.
Les enjeux : élevés. Interpréter « cinquante » comme « soixante » lors d'un transfert est catastrophique.
La pile :
Une cliente, « Sarah », appelle. Elle émet un léger bruit de fond et déclare : « Je dois envoyer 5 000 dollars à mon frère à Londres avec mes économies. »
Voici à quoi ressemble ce flux de travail et les domaines dans lesquels les choses tournent généralement mal.
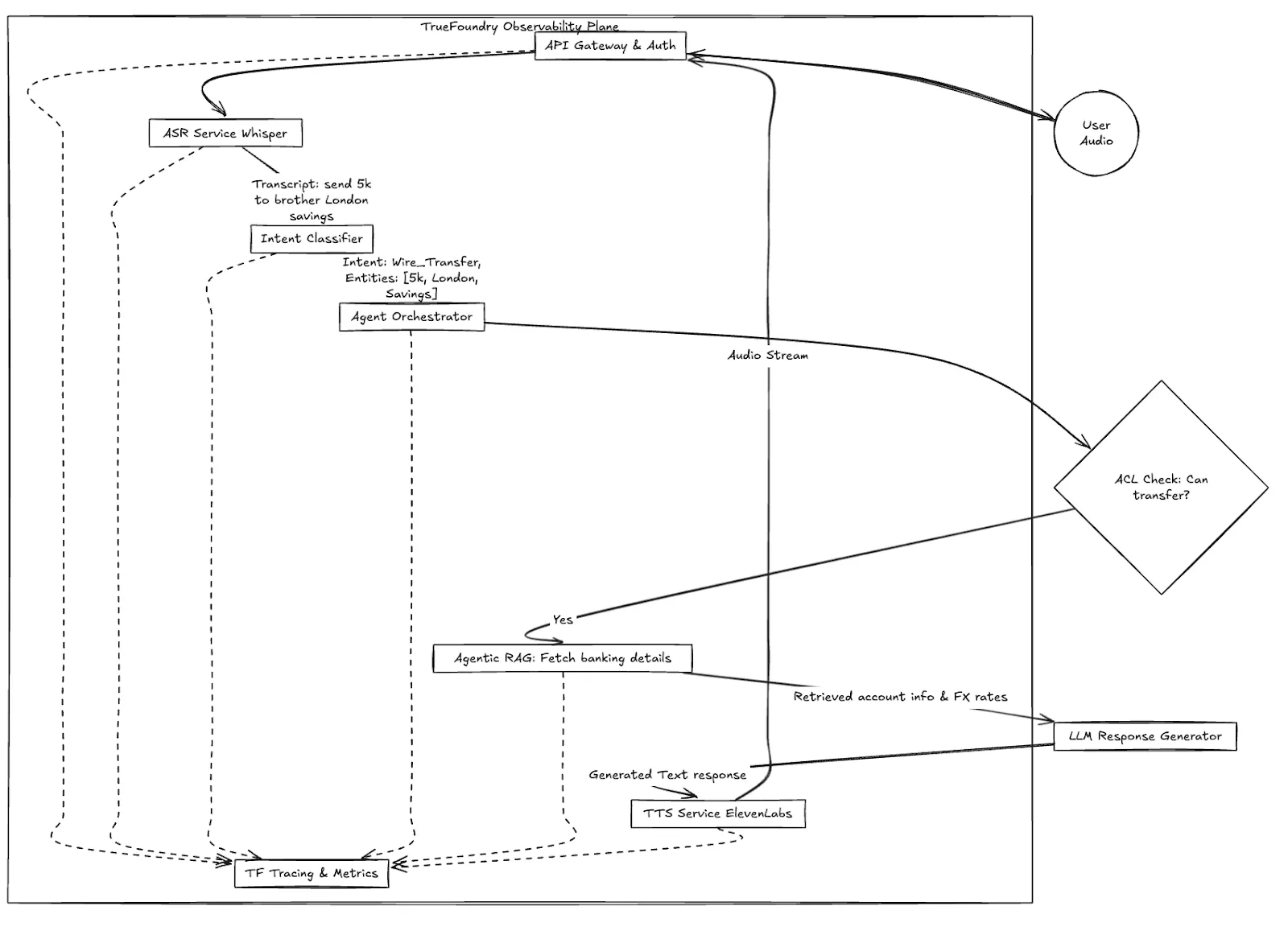
Figure 1 : Flux de travail de haut niveau de la transaction vocale d'Apex Financial, montrant le rôle essentiel du plan d'observabilité.
Dans une configuration standard, si l'appel de Sarah échoue, l'équipe d'ingénierie reçoit un ticket indiquant « Le bot vocal a raccroché ».
Ils consultent Datadog ou Prometheus. Le processeur fonctionne bien. La mémoire est bonne. Les pods Kubernetes sont en ligne. Que s'est-il passé ?
Sans l'observabilité spécialisée de l'IA vocale, le déboguer revient à résoudre un labyrinthe mystérieux sans outils de criminalistique.
Dans un système Voice AI distribué, la latence est cumulative. Un délai de 200 ms dans l'ASR plus un délai de 400 ms dans le RAG équivaut à une expérience client ratée. Vous avez besoin d'un traçage qui comprenne les trames audio, et pas seulement les requêtes HTTP.
C'est là que les plateformes comme TrueFoundry deviennent essentielles. TrueFoundry n'est pas un simple tableau de bord de surveillance ; il s'agit d'une infrastructure AI/ML et d'une plateforme d'observabilité spécialement conçues pour les complexités des piles GenAI, y compris la voix.
TrueFoundry traite l'ensemble de la chaîne, du premier paquet audio au flux TTS final, comme un flux observable.
Voici comment il répond aux besoins critiques des entreprises auxquels les outils génériques ne répondent pas :
Le traçage standard vous indique les temps de saut entre les services. Le suivi spécialisé de TrueFoundry vous permet de visualiser le budget de latence d'une conversation en temps réel.
Vous pouvez voir que pour l'appel de Sarah, l'ASR a pris 350 ms (acceptable), mais l'étape Agentic RAG a pris 2,1 secondes (inacceptable). Vous pouvez immédiatement passer à l'étape RAG : s'agit-il de la récupération de la base de données vectorielle ? Etait-ce le modèle de reclassement ?
Vous arrêtez de deviner et commencez à réparer le goulot d'étranglement.
Lorsque votre Voice AI fait appel à un agent pour prendre des décisions (par exemple pour vérifier si Sarah dispose de fonds suffisants) avant en demandant la destination), vous devez auditer le « processus de réflexion » de l'agent.
TrueFoundry assure l'observabilité des étapes intermédiaires de l'agent. Vous ne voyez pas seulement les entrées et les sorties ; vous voyez les outils sélectionnés par l'agent, les requêtes qu'il a exécutées dans la base de données vectorielles et le contexte brut qu'il a récupéré. Si le bot donne une mauvaise réponse, vous pouvez voir exactement quelle donnée obsolète il a récupérée du système RAG à l'origine de l'hallucination.
Dans le secteur bancaire, « qui peut faire quoi » est primordial. Votre robot vocal marketing ne peut pas accéder accidentellement à l'agent de transaction.
TrueFoundry fournit des listes de contrôle d'accès (ACL) robustes qui régissent les modèles et les agents qui peuvent interagir. En outre, à mesure que les systèmes multi-agents se développent, TrueFoundry adopte des normes telles que le Model Context Protocol (MCP) pour garantir une communication authentifiée et sécurisée entre les différents agents d'IA au sein de votre écosystème.
L'observabilité ne se limite pas à la performance ; il s'agit d'un audit de sécurité. Vous avez besoin d'un journal qui prouve pourquoi L'agent A s'est vu refuser l'accès à la source de données B lors d'un appel en direct.
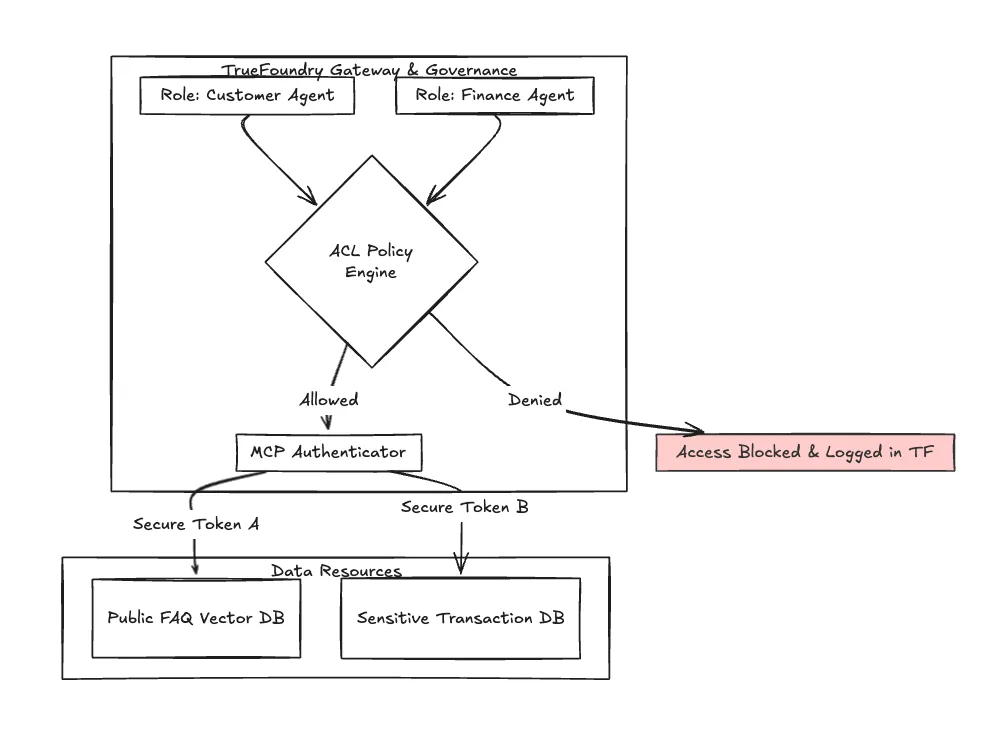
Figure 2 : Vue simplifiée du flux d'authentification ACL et MCP géré au sein de l'écosystème TrueFoundry, garantissant l'isolation des agents vocaux sensibles.
Pour résumer la différence entre la surveillance standard et ce qui est requis pour l'IA vocale d'entreprise :
Tableau 1 : Comparaison des profondeurs d'observabilité de l'APM standard et de TrueFoundry Voice AI.
Pour Apex Financial, le déploiement de TrueFoundry a fait toute la différence entre annuler son programme d'assistant vocal et le faire évoluer. Ils sont passés d'un temps moyen à la détection (MTTD) de quelques heures à quelques minutes. Ils ont pu identifier de manière proactive qu'un modèle d'intégration RAG spécifique provoquait des pics de latence pendant les périodes de volume élevé avant les clients ont commencé à raccrocher.
Lorsque vous créez une IA vocale d'entreprise, les modèles que vous choisissez (Whisper, ElevenLabs, GPT-4O) ne sont que le moteur. L'observabilité est le système avionique. Vous ne devriez pas essayer de piloter un jet avec un simple compteur de vitesse ; n'essayez pas de gérer une pile vocale d'entreprise sans une observabilité approfondie et spécialisée.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


