

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
AWS Bedrock fait office de couche gérée permettant d'accéder aux modèles de base dans les limites d'AWS VPC. Pour les équipes d'ingénierie, cela supprime la charge opérationnelle liée au provisionnement des instances GPU ou à la gestion des clusters Kubernetes à des fins d'inférence. Le service offre un accès immédiat à des modèles tels que Claude 3.5 Sonnet, Llama 3 et Amazon Titan via une API unifiée.
Cependant, Tarification d'AWS Bedrock n'est pas un taux forfaitaire. Il fonctionne comme un menu complexe dont le coût final dépend de la variance du modèle, de la distribution des jetons, des capacités de trafic régionales et des frais opérationnels liés à des services de support tels que CloudWatch et OpenSearch. Ce rapport analyse l'économie unitaire d'AWS Bedrock, identifie les domaines dans lesquels les coûts augmentent à grande échelle et analyse les compromis architecturaux entre l'inférence gérée et les alternatives auto-hébergées à l'aide de plateformes telles que TrueFoundry.
Avant d'examiner les coûts détaillés, il est important de comprendre le modèle de tarification global d'AWS Bedrock. AWS Bedrock suit une tendance pure approche de tarification basée sur l'utilisation sans frais de plateforme ni d'abonnement initiaux.
Vous ne payez pas pour activer le service. Au lieu de cela, vous êtes facturé principalement pour l'inférence de modèles, mesurée au moyen de jetons ou de sorties générées. Cependant, le prix unitaire varie considérablement en fonction du fournisseur du modèle de base ; un modèle anthropique coûte nettement plus cher qu'un modèle Meta ou Mistral, même si le nombre de jetons est identique.
La tarification d'AWS Bedrock dépend de la façon dont les modèles consomment les ressources lors de l'inférence. Alors que la plupart des modèles de texte sont facturés par jeton, les modèles multimodaux diffèrent.
Vous devez faire la distinction entre Jetons d'entrée et Jetons de sortie. Les jetons d'entrée se composent de la charge utile rapide, y compris les instructions système, les requêtes des utilisateurs et, surtout, le contexte récupéré à partir des pipelines RAG. Les jetons de sortie sont la réponse générée.
La réalité opérationnelle veut que les jetons de sortie soient nettement plus coûteux car le coût informatique de génération (prédiction du prochain jeton) est plus élevé que le traitement du contexte d'entrée. Par exemple, avec Claude Sonnet 4,5 dans us-east-1, vous payez 3,00$ par million de jetons d'entrée mais 15,00$ par million de jetons de sortie—un multiplicateur 5x. Pour les modèles multimodaux tels qu'Amazon Titan Image Generator, la facturation se fait sur une base par image, calculée en fonction de la résolution et du nombre de pas.
Figure 1 : L'effet multiplicateur des coûts
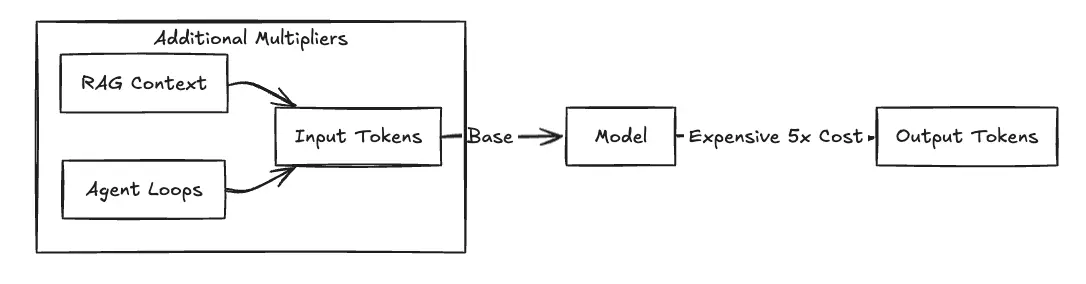
La tarification d'AWS Bedrock ne se limite pas au « paiement par jeton ». Les équipes doivent choisir entre deux modèles de tarification qui échangent la flexibilité contre une capacité garantie.
Figure 2 : Décomposition de la facture totale
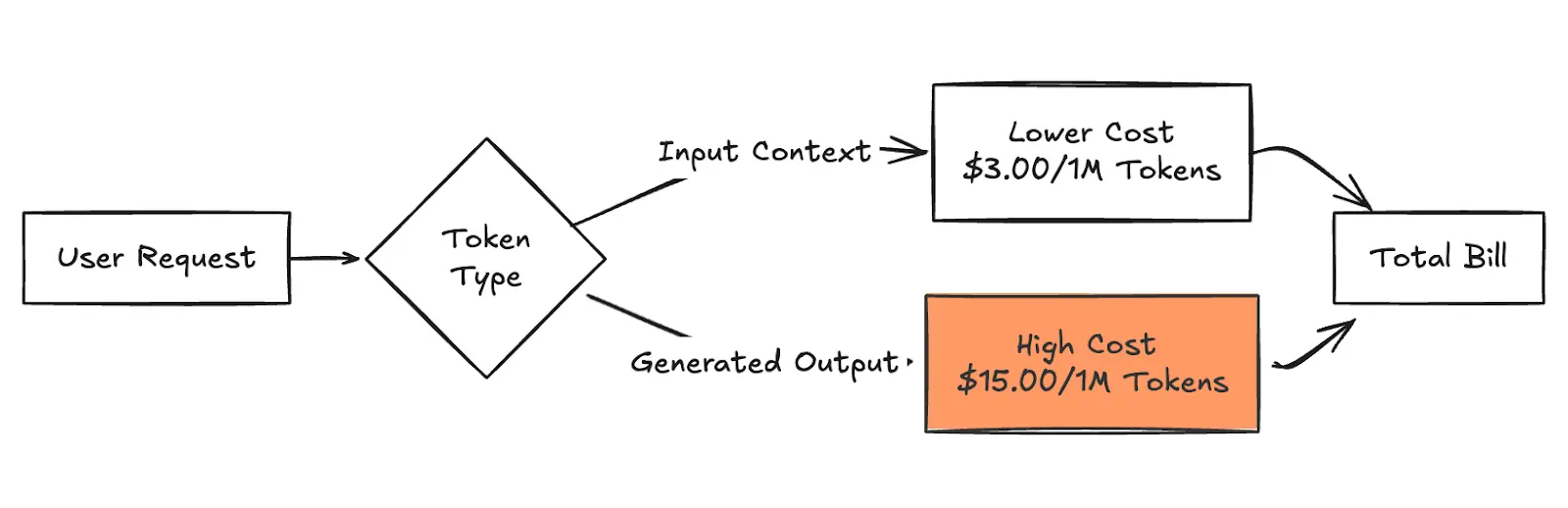
La tarification reflète les tarifs à la demande d'AWS Bedrock pour Anthropic Claude 3.5 Sonnet dans le us-est-1 région en janvier 2026. Les prix peuvent varier selon la région ou la version du modèle.
La tarification à la demande est l'option par défaut pour la plupart des utilisateurs d'AWS Bedrock. Il offre de la flexibilité mais comporte des risques opérationnels. Vous êtes facturé uniquement pour 1 000 jetons traités, ce qui est idéal pour les modèles de trafic variables ou les premières expérimentations lorsque les modèles d'utilisation sont « éclatants ». Cependant, l'inconvénient est la fiabilité. AWS applique des limites de limitation, ce qui signifie que pendant les pics de demande, vos demandes peuvent être limitées.
La tarification du débit provisionné est conçue pour les équipes qui ont besoin d'une disponibilité garantie des modèles à grande échelle. Il introduit la prévisibilité mais nécessite un engagement financier. Au lieu de payer par jeton, vous achetez une unité modèle dédiée pour réserver la capacité d'inférence et garantir un niveau de tarification de débit spécifique.
Le hic, c'est que vous devez payer un tarif horaire fixe, que vous n'envoyiez aucune demande ou que vous utilisiez le maximum de l'unité. Ce modèle fonctionne comme une instance réservée ; il nécessite généralement un engagement de 1 à 6 mois, ce qui réduit votre capacité à changer rapidement de modèle si un meilleur modèle est publié la semaine prochaine.
Contrairement à OpenAI, où vous ne payez qu'un seul fournisseur, Bedrock est une place de marché. Les stratégies de tarification varient d'un fournisseur à l'autre.
Les modèles Amazon Titan sont des modèles de base natifs d'AWS conçus pour les charges de travail d'IA à usage général. Comme il s'agit de modèles propriétaires, leur prix est généralement inférieur à celui des alternatives tierces. Ils sont donc adaptés aux cas d'utilisation de production sensibles aux coûts, tels que la génération intégrée ou la classification simple, où l'objectif est de fournir des performances « suffisantes » à un prix bas.
AWS Bedrock permet également d'accéder à des modèles provenant de fournisseurs externes tels que Anthropic, Cohere et AI21 Labs. Les prix y sont généralement plus élevés en raison des fonctionnalités avancées et des licences externes impliquées. Sachez que les modèles à forte logique tels que Claude 4.5 Sonnet présentent des coûts supplémentaires, dans lesquels les jetons de sortie sont nettement plus chers. Dans ce cas, les coûts peuvent augmenter rapidement pour les applications riches en discussions dans lesquelles le modèle « pense » ou génère des réponses longues et détaillées.
La conception de votre application a un impact sur votre facture tout autant que le prix du modèle.
Le prix de base du jeton n'est souvent que la partie visible de l'iceberg. Les applications d'IA du monde réel utilisent des « bases de connaissances » et des « agents », qui possèdent leurs propres compteurs distincts.
Figure 3 : Le cumul des coûts supplémentaires
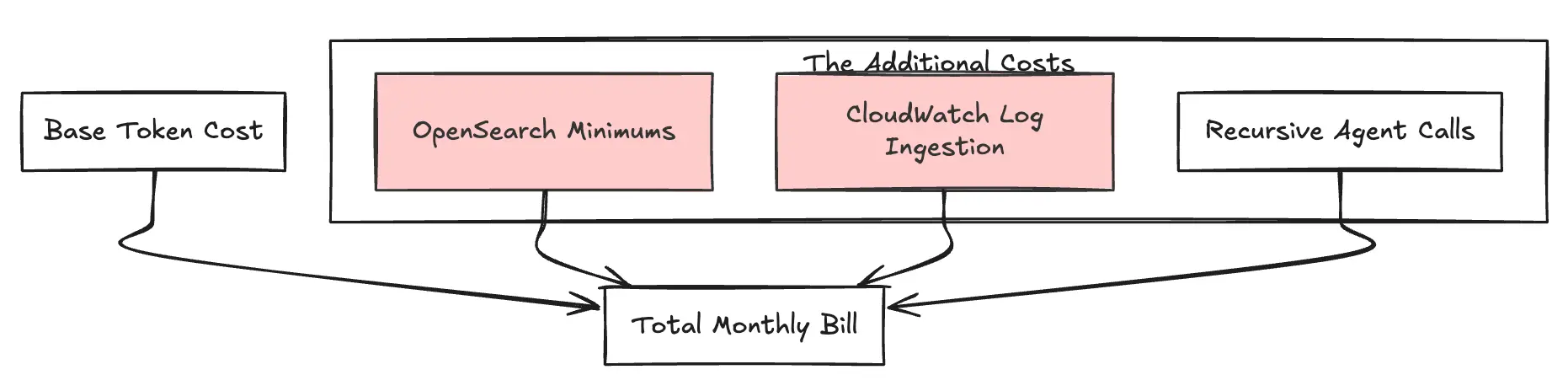
Les bases de connaissances de Bedrock font abstraction du pipeline RAG, mais de l'infrastructure d'approvisionnement en arrière-plan. En règle générale, cela fait apparaître un OpenSearch sans serveur magasin vectoriel. Les équipes d'ingénierie négligent souvent le coût minimum : OpenSearch Serverless nécessite un minimum de 2 OCU (OpenSearch Compute Units) pour la redondance en production. À ~0,24 $ par OCU/heure (en us-est-1), cela se traduit par un coût de référence d'environ 350 $/mois (pour une configuration redondante standard) pour que l'index existe, même en l'absence de trafic de requêtes.
Les « agents » exécutent plusieurs étapes pour répondre à une requête utilisateur (Réflexion → Recherche → Récapitulatif). L'impact est qu'une seule question de l'utilisateur peut déclencher 10 fois les jetons vous vous y attendiez en raison de cette boucle interne et de cette trace de raisonnement. Vous payez pour l'entrée et la sortie de chaque idée intermédiaire, ce qui crée un effet multiplicateur sur votre facture.
L'auditabilité est obligatoire pour l'IA d'entreprise, mais l'intégration de Bedrock à CloudWatch Logs est détaillée. Il enregistre les charges utiles complètes de prompte et de réponse. L'ingestion de CloudWatch dans des régions telles que les coûts de l'est des États-Unis 0,50$ par Go, et le stockage en ajoute un autre 0,03$ par Go. Les applications de génération de texte à volume élevé peuvent facilement générer des centaines de gigaoctets de données de journal, ce qui ajoute discrètement des frais généraux à la facture mensuelle.
De nombreuses équipes sous-estiment la tarification d'AWS Bedrock lors des premières expériences, car les variables sont difficiles à isoler. L'utilisation des jetons varie considérablement en fonction du comportement de l'utilisateur ; un utilisateur peut poser une question simple tandis qu'un autre colle un PDF de 50 pages pour le résumer. De plus, les développeurs adorent expérimenter, et passer de Claude Haiku à Claude Sonnet modifie instantanément votre niveau de tarification, souvent sans que le service des finances ne s'en rende compte avant la fin du mois. Enfin, les budgets AWS fonctionnent au niveau du compte, ce qui rend très difficile de savoir « Combien a dépensé le robot marketing par rapport au robot d'ingénierie ? » sans stratégies de balisage complexes.
Malgré sa complexité, la tarification d'AWS Bedrock fonctionne bien dans certains scénarios. Si vous êtes déjà standardisé sur AWS, la taxe « intégration native » en vaut la peine pour les avantages en matière de sécurité et de conformité, tels que IAM et PrivateLink. Pour les applications dont le trafic est élevé et qui sont utilisées de manière peu fréquente ou imprévisible, le modèle à la demande est parfait car vous ne payez rien lorsque l'application est inactive. Il permet de lancer rapidement des projets en phase initiale sans avoir à gérer de GPU ou de clusters Kubernetes, ce qui permet de valider l'adéquation entre le produit et le marché avant d'optimiser les coûts.
À mesure que les charges de travail liées à l'IA arrivent à maturité, les équipes sont souvent confrontées à des limites structurelles. À des volumes élevés (millions de requêtes), le balisage par jeton devient coûteux par rapport à la possession du calcul. La mise au point de Bedrock nécessite souvent des achats Débit provisionné, ce qui augmente considérablement la barrière à l'entrée par rapport au réglage précis de Llama 3 sur votre propre GPU. En outre, les environnements multi-équipes ne sont pas correctement appliqués au niveau des applications, ce qui entraîne une utilisation « tragique des biens communs » où une équipe épuise le budget partagé.
TrueFoundry propose un modèle architectural alternatif aux équipes qui atteignent le plafond de l'économie unitaire de Bedrock. Plutôt que de louer l'API du modèle avec un balisage, TrueFoundry orchestre le déploiement de modèles open source (Llama 3, Mistral, Qwen) directement sur vos propres clusters AWS EC2 ou EKS.
Cela ouvre la possibilité d'utiliser Instances AWS Spot. En utilisant la capacité d'inférence au comptant (calcul AWS de rechange disponible à des prix très réduits), vous pouvez réduire les coûts d'inférence bruts en : 60 à 70 % par rapport aux tarifs de On-Demand Bedrock. TrueFoundry gère le risque opérationnel lié aux interruptions ponctuelles en automatisant le retour aux instances à la demande si la capacité ponctuelle est récupérée, garantissant ainsi la fiabilité sans blocage du débit provisionné pendant 6 mois.
Il s'agit d'une comparaison factuelle axée sur les aspects économiques des modèles de service.
À mesure que l'adoption de l'IA augmente, la clarté des prix devient essentielle pour une mise à l'échelle durable. La tarification d'AWS Bedrock ne devrait pas avoir à choisir entre innovation et faillite.
TrueFoundry vous permet de contrôler vos dépenses d'IA, en offrant une visibilité granulaire sur chaque modèle et la flexibilité nécessaire pour exécuter des charges de travail sur l'infrastructure la plus rentable disponible, qu'il s'agisse de l'API Bedrock ou d'une instance Spot dans votre VPC.
Réservez une démo gratuite dès maintenant pour en savoir plus sur la façon dont TrueFoundry peut aider vos opérations.
La tarification d'AWS Bedrock varie en fonction du modèle de base et de l'utilisation des jetons. Bien que l'inférence de modèles à faible volume soit accessible, l'inférence de modèles à grande échelle devient coûteuse en raison des majorations des services gérés. TrueFoundry permet une meilleure optimisation des coûts en exécutant des modèles sur des instances AWS Spot, ce qui réduit considérablement votre coût mensuel total par rapport aux tarifs de Bedrock.
Oui, le coût d'AWS Bedrock suit un modèle de tarification basé sur la facturation à l'utilisation. Vous êtes facturé pour chaque nombre de jetons traités pour les jetons d'entrée et les jetons de sortie. Pour les applications d'IA génératives lourdes, ces frais s'accumulent rapidement. TrueFoundry propose une approche plus économique en utilisant les taux de calcul bruts sur votre propre infrastructure.
La tarification d'Amazon Bedrock n'inclut pas le mode gratuit permanent. Bien qu'un nouveau compte AWS puisse proposer des crédits généraux, Bedrock facture immédiatement l'inférence de modèles. TrueFoundry contribue à minimiser les coûts de base en vous permettant d'utiliser des instances ponctuelles moins coûteuses pour vos cas d'utilisation spécifiques et vos tâches par lots.
Il n'existe aucun niveau gratuit dédié pour AWS Bedrock. Les utilisateurs paient pour toutes les utilisations liées à la génération de texte et à la génération d'images. Pour éviter les coûts imprévisibles liés à AWS Bedrock, les équipes optent pour TrueFoundry, qui exploite la mise à l'échelle automatique et l'inférence par lots pour gérer les dépenses génératives liées à l'IA de manière plus efficace que le service géré.
TrueFoundry est un équivalent supérieur à ce service entièrement géré. Il vous permet de déployer n'importe quel modèle personnalisé (tel que Mistral AI) ou un modèle Amazon Titan sur votre propre cloud. Contrairement à Bedrock, il simplifie la gestion des coûts en utilisant des instances ponctuelles et l'automatisation des données, évitant ainsi de dépendre d'un fournisseur pour les importations de modèles personnalisés.
Il n'existe pas de version gratuite d'Amazon Bedrock ; vous payez pour accéder à tous les modèles de fondation. Pour une meilleure valeur à long terme, TrueFoundry vous permet d'exécuter des modèles open source avec une mise en cache et une distillation rapides des modèles sur votre propre matériel, abaissant ainsi considérablement la barrière d'entrée à l'adoption générative de l'IA.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


