

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
L'équipe des ventes est paniquée. Une importante conférence sur les soins de santé aura lieu la semaine prochaine. Le site Web de l'événement répertorie 200 conférenciers - médecins, cadres et chercheurs - répartis sur une douzaine de sous-pages paginées. Pour créer une liste de prospects, quelqu'un doit ouvrir le site, cliquer sur un nom, copier les informations dans une feuille de calcul, ouvrir un nouvel onglet, rechercher cette personne sur LinkedIn, copier l'URL du profil, puis la recoller.
Ils doivent le faire 200 fois.

Pour les ingénieurs, cette requête aboutit généralement à un script Python rapide utilisant Selenium ou BeautifulSoup. Vous inspectez la source de la page, recherchez le div contenant la classe speaker-name et extrayez le texte. Il fonctionne parfaitement pendant environ une semaine. Ensuite, le site Web met à jour son framework frontal, les classes CSS changent et le script se bloque.
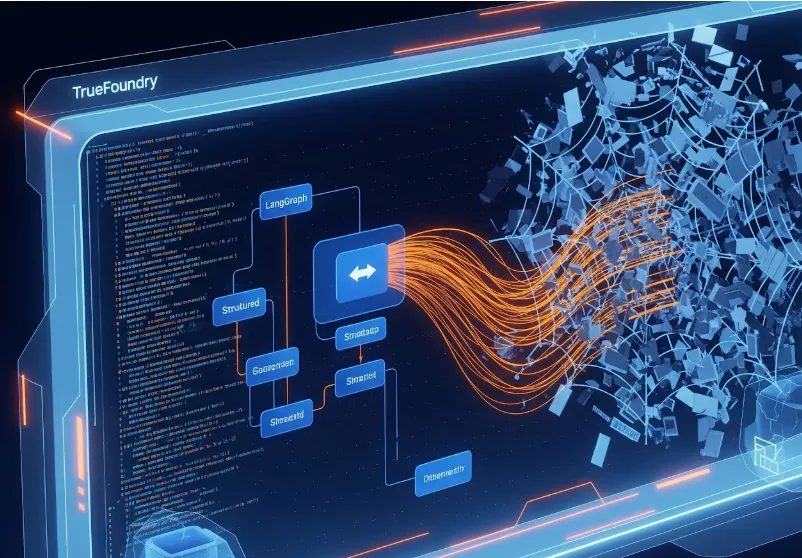
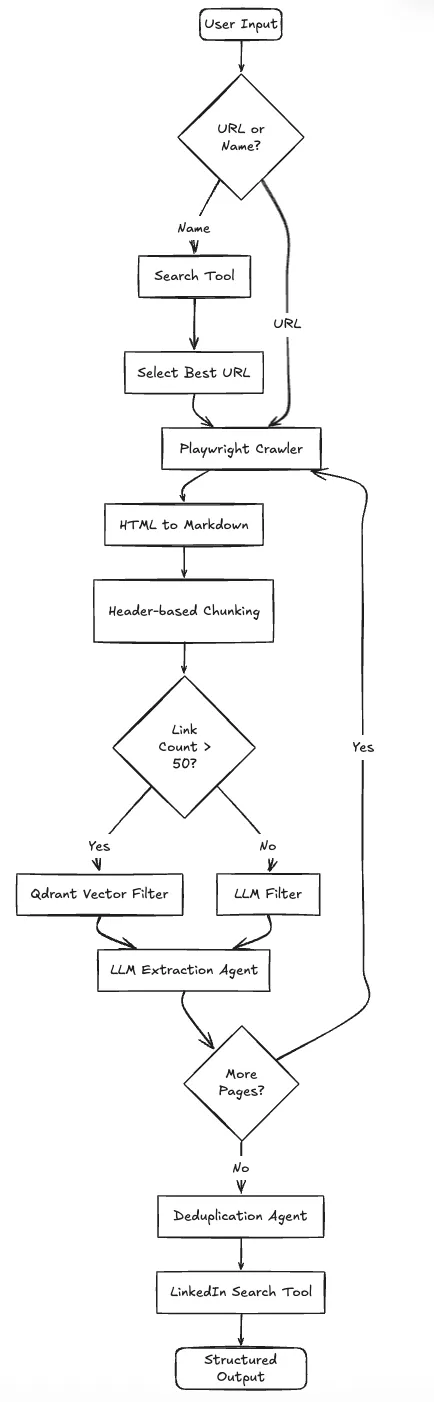
Nous avons construit le Profil Crawler accélérateur pour arrêter ce cycle. Il s'agit d'un agent autonome qui navigue sur les sites Web et extrait les données en fonction de ce que dit la page, et non de la structure du code HTML.
Voici comment nous avons conçu la solution en utilisant LangGraph pour l'orchestration, Playwright pour l'interaction et TrueFoundry pour gérer l'infrastructure.
La principale raison pour laquelle les scripts de scraping échouent est leur dépendance au Document Object Model (DOM). Si vous demandez à un script de rechercher div.content-wrapper > h2.title, il s'interrompt dès qu'un développeur modifie le nom d'une classe.
Nous sommes passés à une approche agentique. Nous ne le disons pas au bot où les données sont localisées au pixel près. Au lieu de cela, nous transmettons le code HTML rendu (converti en Markdown) à un LLM. Le modèle lit le texte comme le ferait un humain. Il comprend qu'une section intitulée « Conférenciers principaux » contient les données que nous voulons, quelles que soient les balises sous-jacentes.
Nous avions besoin d'un système capable de gérer la prise de décisions, et pas simplement d'un script linéaire. L'application doit décider : Cette entrée est-elle une URL ou simplement le nom d'une entreprise ? Avons-nous trouvé un captcha ? Cette page est-elle une liste de personnes ou une biographie unique ?
Nous avons choisi LangGraph pour modéliser ce flux de travail en tant que machine à états, en particulier lorsque Langflow et LangGraph les décisions favorisent une orchestration dynamique.
Le système fonctionne en boucle plutôt qu'en ligne droite :
Voici l'architecture du système :
L'exécution de navigateurs headless et d'agents LLM en production entraîne des problèmes opérationnels : fuites de mémoire provenant de Chromium, limites de débit des API LLM et nécessité d'isoler les processus.
Nous l'avons déployé sur True Foundry pour gérer ces contraintes spécifiques.
Cette application utilise largement les LLM pour les décisions de navigation. Sans gouvernance, les coûts grimpent rapidement en flèche. Nous acheminons tous les modèles d'appels via Passerelle TrueFoundry AI.
Nous avons structuré l'application à l'aide du Protocole de contexte modèle (MCP). Le « Crawler » n'est pas simplement une fonction Python ; c'est un serveur MCP. Cela nous permet de mettre en sandbox l'environnement du navigateur. Si le navigateur tombe en panne (ce qui arrive souvent sur les sites JavaScript lourds), il ne supprime pas la logique principale de l'application.
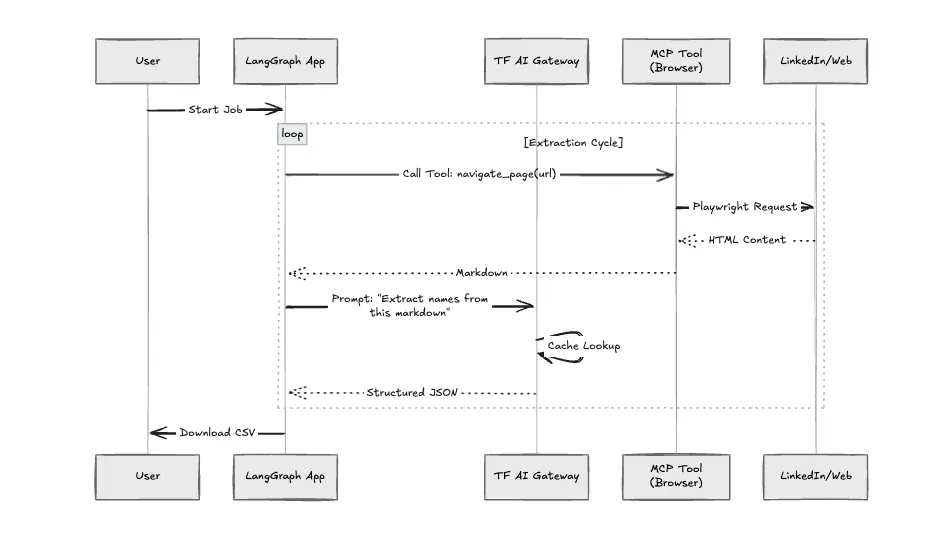
Nous avons comparé l'approche de script Python standard à cette architecture.
Il est facile de construire le chemin du bonheur. Pour le rendre fiable, il a fallu résoudre trois problèmes d'ingénierie spécifiques :
Cette architecture résout le « dernier kilomètre » de l'acquisition de données en remplaçant les scripts fragiles par des agents adaptatifs. En l'exécutant sur TrueFoundry, nous nous assurons que le système est observable, maîtrisé les coûts et évolutif.
Vous pouvez déployer cette architecture exacte, y compris la configuration Gateway et les agents Dockerisés, à partir de la bibliothèque d'applications TrueFoundry dès aujourd'hui.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


