






October 26, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Volvemos con otro episodio de True ML Talks. En este artículo, profundizamos en la API de recomendaciones de Slack, el GPT y el LLM de Slack y estamos hablando con Katrina Ni.
Katrina Ni es ingeniera sénior de aprendizaje automático y miembro principal del personal técnico de Slack. Ha estado al frente del equipo de aprendizaje automático y ha trabajado con la API recomendada, la detección de spam y todas las funcionalidades del producto.
📌
Nuestras conversaciones con Katrina abordarán los siguientes aspectos:
- Casos de uso de ML y Gen AI en Slack
- Infraestructura en Slack centrada en el aprendizaje automático
- Formación, validación, implementación y supervisión de la API de recomendación en Slack
- Medición del impacto empresarial para la API de recomendación
- Impacto de la privacidad del cliente en la infraestructura de formación
- La creación de la GPT en Slack y los desafíos de la formación del LLMS
- El futuro de la ingeniería rápida en los modelos lingüísticos
- Mantenerse actualizado con los avances en los LLM
Slack cuenta con equipos de ingeniería de datos cualificados y soluciones sólidas de almacenamiento de datos. Utilizan Airflow para programar trabajos y procesar macrodatos, lo que proporciona un apoyo vital para las tareas de aprendizaje automático.
La infraestructura de Slack se basa en Kubernetes y es compatible con su arquitectura de microservicios. Su equipo de nube desarrolló un marco basado en Kubernetes para facilitar la implementación de microservicios y ofrecer flexibilidad y escalabilidad.
Para satisfacer sus necesidades específicas, Slack desarrolló una tienda de funciones personalizadas en lugar de utilizar las soluciones existentes. Esta tienda personalizada administra y utiliza de manera eficiente las funciones de las aplicaciones de aprendizaje automático.
Un equipo especializado de Slack creó una capa de orquestación sobre Kubernetes, lo que agilizó la implementación de microservicios y la integración con servicios internos, como la consola. Si bien esto mejora el uso de Kubernetes, persisten los desafíos para las aplicaciones que dependen en gran medida de las bases de datos.
Durante los primeros días de Slack, se hicieron esfuerzos para desarrollar mecanismos efectivos de integración y facción. Esto implicaba procesar enormes cantidades de datos para comprender las interacciones de los usuarios y generar incrustaciones numéricas para los usuarios y los canales. Uno de los resultados fue un servicio de integración basado en las actividades de los usuarios y otro basado en los mensajes, aunque no se adoptó ampliamente en ese momento.
Más tarde, el enfoque pasó a centrarse en el uso de estas incrustaciones para crear un producto más fácil de usar. Surgió el concepto de recomendaciones, que identificaba las áreas en las que las sugerencias podían beneficiar a los usuarios, como recomendar canales o usuarios. Esto llevó al desarrollo de la API de recomendación, que se integró con varias partes de la plataforma de Slack y utilizó las incrustaciones existentes para obtener datos relevantes en función de las actividades de los usuarios. La API también incorporó la tienda de funciones, lo que enriqueció los datos con funciones adicionales y aplicó mecanismos de filtrado y puntuación.
A medida que avanzaba el desarrollo, la API de recomendación se integró en diferentes funciones de Slack, lo que permitió a la plataforma recomendar canales o usuarios relevantes a sus usuarios, lo que agilizó su experiencia y aumentó la participación.
Puedes leer más sobre SlackGPT en el blog que figura a continuación.
Esta es una imagen del mismo blog que ofrece una visión general muy buena de la infraestructura de API recomendadas de Slack
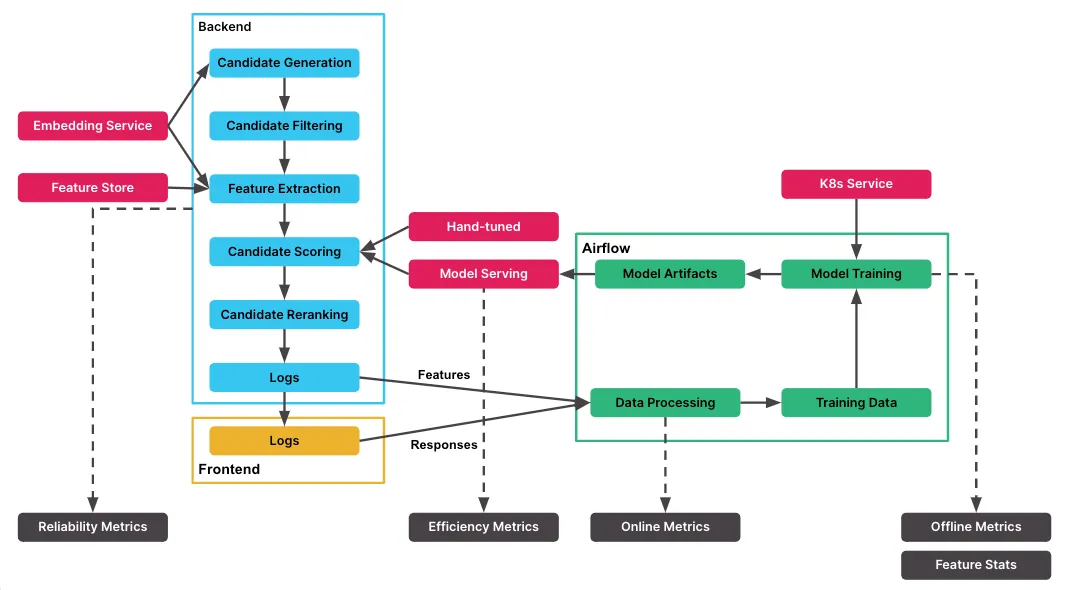
Al aprovechar Kubernetes, Airflow y un enfoque jerárquico para la formación y la validación, Slack garantiza que los modelos de la API de recomendación sean eficaces y fiables, y ofrece recomendaciones personalizadas a los usuarios. Las pruebas A/B garantizan una evaluación rigurosa del rendimiento del modelo en un entorno en línea antes de su implementación, lo que contribuye a crear en Slack un marco de operaciones de aprendizaje automático sólido y basado en datos.
1. Corpus jerárquico y casos de uso: El proceso de formación modelo en Slack sigue un enfoque jerárquico. Comienza con un corpus jerárquico compuesto por canales o usuarios, con múltiples casos de uso, como el resumen diario, el compositor o el navegador de canales, que se centran en funcionalidades específicas de Slack.
2. Selección y experimentación de modelos: Para cada caso de uso, se entrenan y experimentan varios modelos, comenzando con modelos de regresión grandes y explorando otros algoritmos como XGBoost o LightGBM. Los parámetros del modelo se ajustan con precisión y se experimentan diferentes variaciones de datos para identificar el modelo más adecuado.
3. Proceso de entrenamiento con Kubernetes y Airflow: El proceso de formación se organiza mediante Kubernetes y Airflow. Los clústeres de Kubernetes gestionan las tareas de entrenamiento de modelos de manera eficiente, y Airflow gestiona el flujo de trabajo, desde la recopilación de datos hasta el entrenamiento de varios modelos para diferentes casos de uso.
4. Métricas de registro y fuera de línea: Durante la capacitación, el equipo registra las métricas fuera de línea y los parámetros del modelo para la supervisión y el análisis futuros.
5. Adición y administración de modelos sin interrupciones: La arquitectura permite agregar sin problemas nuevas fuentes o modelos para el entrenamiento con cambios mínimos en el código.
6. Validación y pruebas A/B: Se lleva a cabo una validación rigurosa antes de implementar los modelos en producción, comparando las métricas fuera de línea, como el AUC, para los modelos de clasificación o clasificación. Las pruebas A/B se utilizan ampliamente para seleccionar modelos con mejores métricas en línea para su implementación.
7. Marco interno de pruebas AB: Slack tiene su marco interno de pruebas AB, que utilizan el equipo de aprendizaje automático y los equipos de productos al lanzar nuevas funciones. El marco permite tomar decisiones basadas en datos al comparar el rendimiento del modelo en función de varias métricas empresariales.
Los modelos de aprendizaje automático de Slack se implementan en clústeres de Kubernetes utilizando GRPC como interfaz para gestionar las solicitudes. El GRPC ofrece seguridad, eficiencia y un procesamiento más rápido en comparación con las API basadas en JSON, como FastAPI. A pesar de sus restricciones, el GRPC garantiza una comunicación sólida y eficiente entre la API y los modelos, lo que contribuye a un proceso de implementación fluido.
La estrategia de implementación incluye aprovechar las capacidades de escalado automático de Kubernetes, lo que permite a los modelos ajustar el uso de los recursos en función de la demanda. Con una amplia base de usuarios, Slack gestiona un número significativo de solicitudes, con un promedio de alrededor de 100 solicitudes por segundo.
La implementación del GRPC y la configuración del microservicio del clúster de servidores requirieron un esfuerzo concentrado, pero demostraron ser eficaces para gestionar la escala y optimizar el rendimiento del modelo.
1. Seguimiento de las métricas en línea y fuera de línea: El canal de monitoreo de modelos de Slack rastrea de manera eficiente las métricas en línea y fuera de línea. Las métricas offline, como la precisión, la F1 y el ROC, se registran, y los paneles dedicados permiten la visualización. Las métricas en línea, incluida la tasa de aceptación, también se supervisan a través de un panel de control independiente.
2. Detección de anomalías y deriva de funciones: Slack utiliza su propio marco de detección de anomalías para supervisar la desviación de las funciones. El reentrenamiento regular de los modelos (entrenamiento diario e implementaciones semanales) reduce el impacto de la falta de funciones, lo que hace que sea menos preocupante.
3. Canalización de readiestramiento automatizada: El proceso de reentrenamiento se automatiza mediante Airflow, lo que garantiza que los modelos se mantengan actualizados con los datos más recientes.
4. Paneles automatizados para la visualización: Los ingenieros de datos han desarrollado paneles fáciles de usar que visualizan el rendimiento y las métricas del modelo. Los paneles se actualizan automáticamente con nuevos datos, lo que facilita el seguimiento de los nuevos casos de uso.
5. Integración sencilla de nuevos casos de uso: Agregar nuevos casos de uso al proceso de monitoreo y reentrenamiento es sencillo, gracias al marco de integración automatizado establecido por los ingenieros de datos.
Al aprovechar la automatización y el reciclaje periódico, los modelos de aprendizaje automático de Slack se supervisan, optimizan y son fiables de forma continua durante la producción. El sólido marco de mLOps contribuye a la implementación eficiente y fluida de los modelos para la gran base de usuarios de Slack.
Slack emplea varias métricas para evaluar el impacto empresarial de la API de recomendación, lo que permite obtener información valiosa sobre su rendimiento y eficacia. Las métricas clave que se utilizan son las siguientes:
Al analizar estas métricas y optimizar la API de recomendación en función de los comentarios de los usuarios, Slack garantiza que la API mejore significativamente la experiencia del usuario, fomente las conexiones y genere resultados empresariales positivos dentro de la plataforma.
El compromiso de Slack con la privacidad de los clientes influye considerablemente en la arquitectura de la infraestructura de formación y en las prácticas de gestión de datos. El riguroso enfoque que se presta a la privacidad de los datos se refleja en varios aspectos del sistema de gestión multiusos, lo que garantiza un tratamiento seguro y conforme a las normas de la información confidencial. Así es como la privacidad de los clientes afecta a la infraestructura de formación de Slack:
Slack presentó Slack GPT, una potente IA de generación de idiomas para resumir con el fin de abordar la sobrecarga de información en la plataforma y mejorar la productividad de los usuarios.
La creación de Slack GPT presentó desafíos y requirió innovaciones de infraestructura para entrenar modelos lingüísticos de gran tamaño. Esto implicó la creación de clústeres, el uso de Kubernetes y la exploración de técnicas de procesamiento paralelo. Para mejorar la calidad de los resúmenes, el equipo implementó un ajuste rápido, elaborando cuidadosamente las indicaciones para influir en el comportamiento del modelo y generar resúmenes coherentes.
La evaluación sistemática de las indicaciones era crucial, y el equipo desarrolló herramientas para evaluar la eficacia inmediata, lo que permitió la experimentación con diferentes indicaciones. Reducir la brecha entre la evaluación offline y la online garantizó que la calidad observada durante la exploración offline se tradujera sin problemas en la experiencia del usuario online.
A medida que Slack invierte en capacidades de inteligencia artificial, los ingenieros de aprendizaje automático desempeñan un papel fundamental en la optimización de las experiencias de los usuarios mediante la exploración, la evaluación y la mejora sistemática de funciones impulsadas por la IA, como Slack GPT.
Puedes obtener más información sobre SlackGPT en el siguiente enlace.
La ingeniería rápida es crucial para los modelos lingüísticos, ya que afecta a la calidad de la respuesta. Por ahora, implica prueba y error y carece de un enfoque estandarizado. Las posibilidades futuras incluyen:
La ingeniería rápida es un área que se explora activamente, con el objetivo de lograr un equilibrio entre la intervención manual y la automatización, dando forma al futuro de la comunicación impulsada por la inteligencia artificial.
Para los científicos de datos y los ingenieros de aprendizaje automático es esencial mantenerse al día con los avances continuos en los modelos de lenguaje de gran tamaño (LLM).
Muchos profesionales de la comunidad de IA y PNL utilizan Twitter como una plataforma valiosa para acceder a información en tiempo real sobre nuevas investigaciones, lanzamientos de modelos y avances en el ámbito de la LLM. Seguir a investigadores y profesionales influyentes en Twitter les permite conocer rápidamente las últimas tendencias y actualizaciones en este campo.
Además, los profesionales se mantienen informados a través de las interacciones con sus colegas. Dentro de sus equipos, se comparten noticias importantes, como el lanzamiento de LLM como Llama-2 y su integración con plataformas como SageMaker, lo que crea un entorno de aprendizaje colaborativo.
Si bien algunos científicos de datos e ingenieros de aprendizaje automático pueden centrarse en leer artículos de investigación, otros dan prioridad a los casos de uso práctico. Están más inclinados a explorar cómo los nuevos desarrollos pueden afectar directamente a su trabajo y mejorar las aplicaciones de los LLM en escenarios del mundo real.
Sigue viendo el TrueML serie youtube y leyendo todo el TrueML serie de blogs.
True Foundry es un PaaS de implementación de aprendizaje automático sobre Kubernetes para acelerar los flujos de trabajo de los desarrolladores y, al mismo tiempo, permitirles una flexibilidad total a la hora de probar e implementar modelos, al tiempo que garantiza una seguridad y un control totales para el equipo de Infra. A través de nuestra plataforma, permitimos a los equipos de aprendizaje automático implementar y supervisar modela en 15 minutos con un 100% de confiabilidad, escalabilidad y la capacidad de revertirse en segundos, lo que les permite ahorrar costos y lanzar los modelos a la producción más rápido, lo que permite obtener un verdadero valor empresarial.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada






.png)

.webp)
.webp)
.webp)



.webp)
.webp)


