



May 21, 2024
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Volvemos con otro episodio de True ML Talks. En este artículo, volvemos a profundizar en las aplicaciones MLOps y LLMS en GitLab y estamos hablando con Rayo Monmayuri.
Monmayuri lidera la vertical de investigación sobre IA en GitLab con mucho enfoque en los LLM durante el último año. Antes de eso, fue director de ingeniería en la división ModelOps de GitLab. También trabajó con otras empresas como Microsoft y eBay.
📌
Nuestras conversaciones con Monmayuri abordarán los siguientes aspectos:
- Casos de uso de ML y LLM en GitLab
- La evolución de la infraestructura de aprendizaje automático de GitLab para admitir modelos de lenguaje grandes (LLM)
- El viaje de GitLab con los LLM: del código abierto al ajuste
- Training of large language models in GitLab
- Triton frente a PyTorch, GPU ensambladas y procesamiento dinámico por lotes para la inferencia de LLM
- Desafíos e investigación en la evaluación del LLM en GitLab
- La arquitectura LLM de GitLab y el futuro de los LLM
El aprendizaje automático (ML) está transformando el ciclo de vida del desarrollo de software, y GitLab está a la vanguardia de esta innovación. GitLab utiliza el aprendizaje automático para ayudar a los desarrolladores a lo largo de todo su recorrido, desde la creación de problemas hasta la fusión de solicitudes y la implementación de aplicaciones.
Uno de los casos de uso más interesantes del aprendizaje automático en GitLab son los modelos de lenguaje grandes (LLM). GitLab utiliza LLM y GenAI para desarrollar nuevas funciones para sus productos, como completar el código y resumir los problemas.
GitLab ha estado a la vanguardia del uso de grandes modelos lingüísticos (LLM) para capacitar a los desarrolladores. Como resultado, GitLab ha tenido que evolucionar su infraestructura de aprendizaje automático para dar soporte a estos modelos complejos.
Para abordar los desafíos mencionados anteriormente, GitLab ha realizado una serie de cambios en su infraestructura de aprendizaje automático. Estos cambios se pueden clasificar en las siguientes áreas:
GitLab ha estado a la vanguardia del uso de grandes modelos lingüísticos (LLM) para capacitar a los desarrolladores. Al principio, GitLab comenzó a usar LLMs de código abierto, como la generación de código de Salesforce. Sin embargo, a medida que el panorama ha cambiado y los LLM se han vuelto más potentes, GitLab ha optado por ajustar sus propios LLM para casos de uso específicos, como la generación de código.
El perfeccionamiento de los LLM requiere una inversión significativa en infraestructura, ya que estos modelos son muy grandes y complejos. GitLab ha tenido que desarrollar nuevos canales de capacitación e implementación para los LLM, así como nuevas formas de administrar su infraestructura de aprendizaje automático en un entorno distribuido.
Uno de los principales desafíos a los que se ha enfrentado GitLab para ajustar los LLM es encontrar el equilibrio adecuado entre el costo y la latencia. Los LLM pueden ser muy costosos de entrenar e implementar, y también pueden tardar en generar resultados. GitLab ha tenido que experimentar con diferentes tamaños de clústeres, configuraciones de GPU y técnicas de procesamiento por lotes para encontrar el equilibrio adecuado para sus necesidades.
Otro desafío al que se ha enfrentado GitLab es garantizar que sus LLM sean precisos y confiables. Los LLM se pueden entrenar con conjuntos de datos masivos de texto y código, pero estos conjuntos de datos también pueden contener errores y sesgos. GitLab ha tenido que desarrollar nuevas técnicas para evaluar y depurar sus LLM.
A pesar de los desafíos, GitLab ha logrado avances significativos en el uso de LLM para capacitar a los desarrolladores. GitLab ahora puede capacitar e implementar LLM a escala, y está utilizando estos modelos para desarrollar nuevas funciones y productos que harán que el proceso de desarrollo de software sea más eficiente y agradable.
La formación de grandes modelos lingüísticos (LLM) es una tarea difícil que requiere una inversión significativa en infraestructura y recursos. GitLab ha estado a la vanguardia del uso de los LLM para capacitar a los desarrolladores, y la empresa ha aprendido mucho a lo largo del camino.
Estas son algunas ideas y lecciones aprendidas de la experiencia de GitLab en la formación de LLM:
Además de las ideas anteriores, GitLab también ha aprendido una serie de valiosas lecciones sobre la importancia de comprender bien el modelo base y los datos de entrenamiento. Por ejemplo, GitLab ha descubierto que es importante conocer la estructura del modelo base y cómo seleccionar los datos de entrenamiento para optimizarlos para el caso de uso deseado.
GitLab usa Triton para la inferencia de LLM porque es más adecuado para adaptarse al gran volumen de solicitudes que recibe GitLab. Triton también es más fácil de empaquetar y escalar que otros modelos de servidores, como los servidores PyTorch.
GitLab aún no ha experimentado con los servidores modelo TGI o VLLM de Hugging Face, ya que aún se encontraban en las primeras etapas de desarrollo cuando GitLab implementó por primera vez su canal de inferencia de LLM.
En lo que respecta al procesamiento dinámico por lotes, la estrategia de GitLab consiste en optimizarlo para el caso de uso específico, la carga, el nivel de consulta, el volumen y la cantidad de GPU disponibles. Por ejemplo, si GitLab tiene 500 GPU para un modelo de 7 GB, puede usar una estrategia de procesamiento por lotes diferente a la que utilizaría si solo tuviera unas pocas GPU para un modelo más pequeño.
GitLab también usa un conjunto de GPU para gestionar las solicitudes. Esto significa que GitLab usa una combinación de diferentes tipos de GPU, incluidas las GPU de alto rendimiento y las GPU de bajo rendimiento. GitLab equilibra la carga de las solicitudes en todo el conjunto de GPU para optimizar el rendimiento y el costo.
Estos son algunos consejos para diseñar una arquitectura que combine las GPU y optimice el equilibrio de carga:
Estos son algunos ejemplos específicos de cómo GitLab ha optimizado su arquitectura para las GPU ensambladas y el procesamiento dinámico por lotes:
Si sigue estos consejos, puede diseñar una arquitectura que pueda gestionar de manera eficiente grandes volúmenes de solicitudes de inferencia de LLM.
También hemos probado el streaming y creo que también estamos buscando streaming para nuestros terceros - Monmayuri
Evaluar el rendimiento de los modelos lingüísticos de gran tamaño (LLM) es una tarea difícil. GitLab ha estado trabajando en este problema y se ha enfrentado a varios desafíos, entre ellos:
GitLab aborda estos desafíos de la siguiente manera:
El objetivo de GitLab es desarrollar un enfoque escalable y basado en datos para evaluar los LLM. Este enfoque ayudará a GitLab a garantizar que sus LLM funcionen correctamente en producción y satisfagan las necesidades de sus usuarios.
GitLab también está investigando nuevas formas de evaluar los LLM. Algunas de las líneas de investigación que GitLab está explorando incluyen:
La investigación de GitLab sobre la evaluación de los LLM está en curso. GitLab se compromete a desarrollar formas nuevas e innovadoras de evaluar los LLM para garantizar que sus LLM satisfagan las necesidades de sus usuarios.
La arquitectura LLM de GitLab es un enfoque integral para la capacitación, la evaluación y implementación de LLM. La arquitectura está diseñada para ser flexible y escalable, de modo que GitLab pueda adoptar fácilmente nuevas tecnologías y satisfacer las necesidades de sus usuarios.
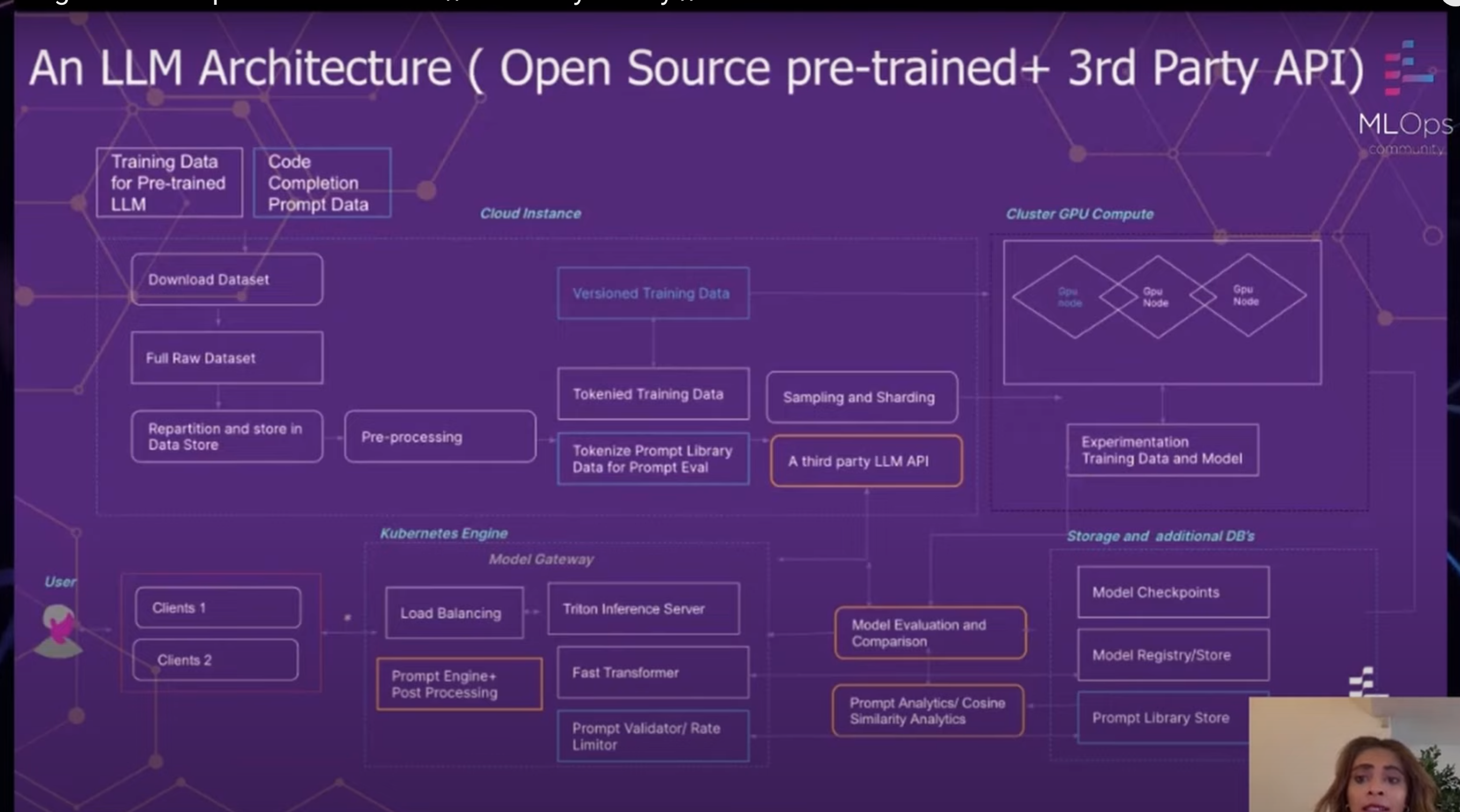
La arquitectura consta de varios componentes clave:
La arquitectura LLM de GitLab es una poderosa herramienta que permite a GitLab entrenar, evaluar e implementar LLM a escala. La arquitectura está diseñada para ser flexible y escalable, de modo que GitLab pueda adoptar fácilmente nuevas tecnologías y satisfacer las necesidades de sus usuarios.
Los LLM siguen siendo una tecnología relativamente nueva, pero tienen el potencial de revolucionar muchas industrias. GitLab cree que los LLM tendrán un impacto significativo en la industria del desarrollo de software.
GitLab ya utiliza LLMs para mejorar sus productos y servicios. Por ejemplo, GitLab utiliza los LLM para generar sugerencias de código, explicar las vulnerabilidades y mejorar la experiencia de usuario de sus productos.
GitLab cree que otras organizaciones también deberían invertir en LLM. Los LLM tienen el potencial de mejorar la productividad, la eficiencia y la calidad en muchos sectores.
GitLab recomienda que las organizaciones inviertan en las siguientes áreas para mantenerse a la vanguardia en el ámbito de la LLM:
Al invertir en estas áreas, las organizaciones pueden mantenerse a la vanguardia en el ámbito de la LLM y aprovechar los beneficios de esta poderosa tecnología.
Sigue viendo el TrueML youtube series leyendo el TrueML series de blogs.
True Foundry es un PaaS de implementación de aprendizaje automático sobre Kubernetes para acelerar los flujos de trabajo de los desarrolladores y, al mismo tiempo, permitirles una flexibilidad total a la hora de probar e implementar modelos, al tiempo que garantiza una seguridad y un control totales para el equipo de Infra. A través de nuestra plataforma, permitimos a los equipos de aprendizaje automático implementar y supervisar modela en 15 minutos con un 100% de confiabilidad, escalabilidad y la capacidad de revertirse en segundos, lo que les permite ahorrar costos y lanzar los modelos a la producción más rápido, lo que permite obtener un verdadero valor empresarial.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada






.png)

.webp)
.webp)
.webp)



.webp)
.webp)


