

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Versión corta: Kimi-K2 Thinking (Moonshot AI) es un modelo de «pensamiento» abierto y consciente de las herramientas que impulsa el razonamiento en varios pasos, la orquestación de herramientas a largo plazo y las enormes ventanas de contexto. En Humanity's Last Exam (HLE) y en varios puntos de referencia entre agencias, publica las mejores cifras en los estados (especialmente cuando se permite el acceso a las herramientas), lo que demuestra que la próxima gran frontera en los LLM es pensamiento + herramientas + contexto largo, no solo recuentos de parámetros sin procesar.
Utilice Puerta de enlace de IA de Truefoundry para probarlo ahora mismo.
Los puntos de referencia como MMLU, las pruebas de codificación y los puntos de referencia de chat nos han dicho mucho, pero no miden completamente el razonamiento en varios pasos, la orquestación de herramientas o la planificación a largo plazo. Una nueva clase de modelos de «pensamiento» capacita de manera explícita para esas habilidades: el modelo debe intercalar el razonamiento interno paso a paso con las herramientas externas (búsqueda, intérpretes de código, navegación web) y mantener la coherencia durante muchos pasos secuenciales.
Kimi-K2 Thinking es un ejemplo emblemático de esta tendencia. Está diseñado como un sistema de agencias: razona, decide recurrir a las herramientas, absorbe los resultados de las herramientas y continúa razonando, todo ello sin dejar de mantener el contexto a lo largo de cientos de pasos. El resultado: avances sustanciales en comparación con puntos de referencia «bien pensados», como HLE y BrowseComp.
Aspectos técnicos clave de la tarjeta modelo oficial:
Estos elementos (la escala del MoE, el enorme contexto, la orquestación explícita de herramientas y la inferencia eficiente de bits bajos) son los componentes básicos que permiten a Kimi-K2 actuar como un agente más que como un transformador conversacional.
El último examen de la humanidad (HLE) pretende ser un punto de referencia muy desafiante al estilo de un examen que haga hincapié en el razonamiento genuino, no en la recuperación o los atajos. Contiene problemas complejos de matemáticas, ciencias, ingeniería y otras materias, que suelen tener varios pasos. Como los problemas de HLE suelen requerir un razonamiento de varios pasos y, en algunos casos, búsquedas o cálculos externos, es una excelente prueba de esfuerzo para los agentes de contexto extenso con capacidad de usar herramientas. El desarrollo de Kimi-K2 hizo hincapié en el HLE y otros puntos de referencia entre agencias. La tarjeta modelo destaca el HLE como uno de sus principales objetivos de evaluación.
Según los resultados de la evaluación publicados por Moonshot AI:
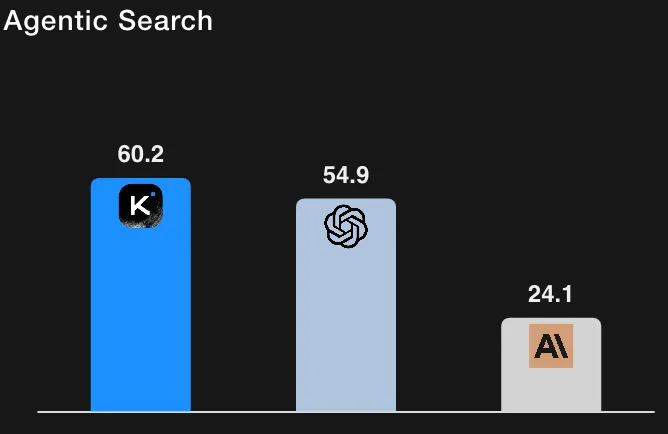
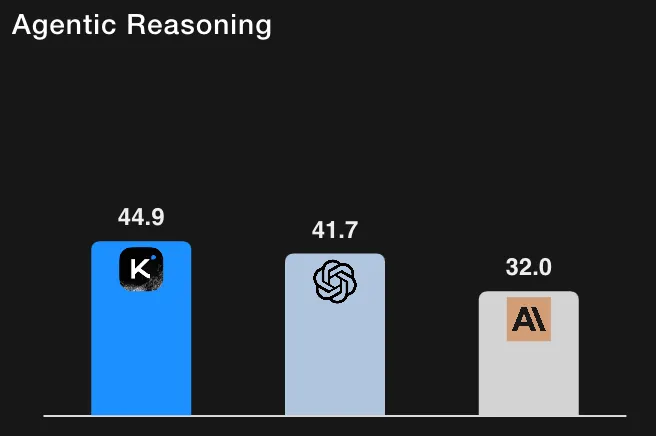
Por contexto, el GPT-5 (alto) se sitúa en ~ el 41,7% en HLE con herramientas (sus repeticiones internas) y el Claude Sonnet 4.5, en ~ el 32,0% (modo de pensamiento). Por lo tanto, los resultados de Kimi-K2 lo sitúan por delante de los valores de referencia reportados en las ejecuciones de HLE con herramientas. (Todos los números están tomados de la tabla de evaluación y de las notas a pie de página de Moonshot AI).
Matiz importante: la tarjeta modelo documenta cuidadosamente cómo se manejó el acceso a las herramientas, la configuración de los jueces, los presupuestos simbólicos y los límites de contexto; los autores también señalan que algunos números de referencia se tomaron de publicaciones oficiales, mientras que otros se volvieron a probar internamente. En resumen: se trata de señales fuertes, pero los lectores deben tener en cuenta que las informa Moonshot AI y están condicionadas al protocolo de evaluación detallado que se describe junto con los resultados.
Tomamos muestras de 50 filas de datos de HLE y aquí están los resultados
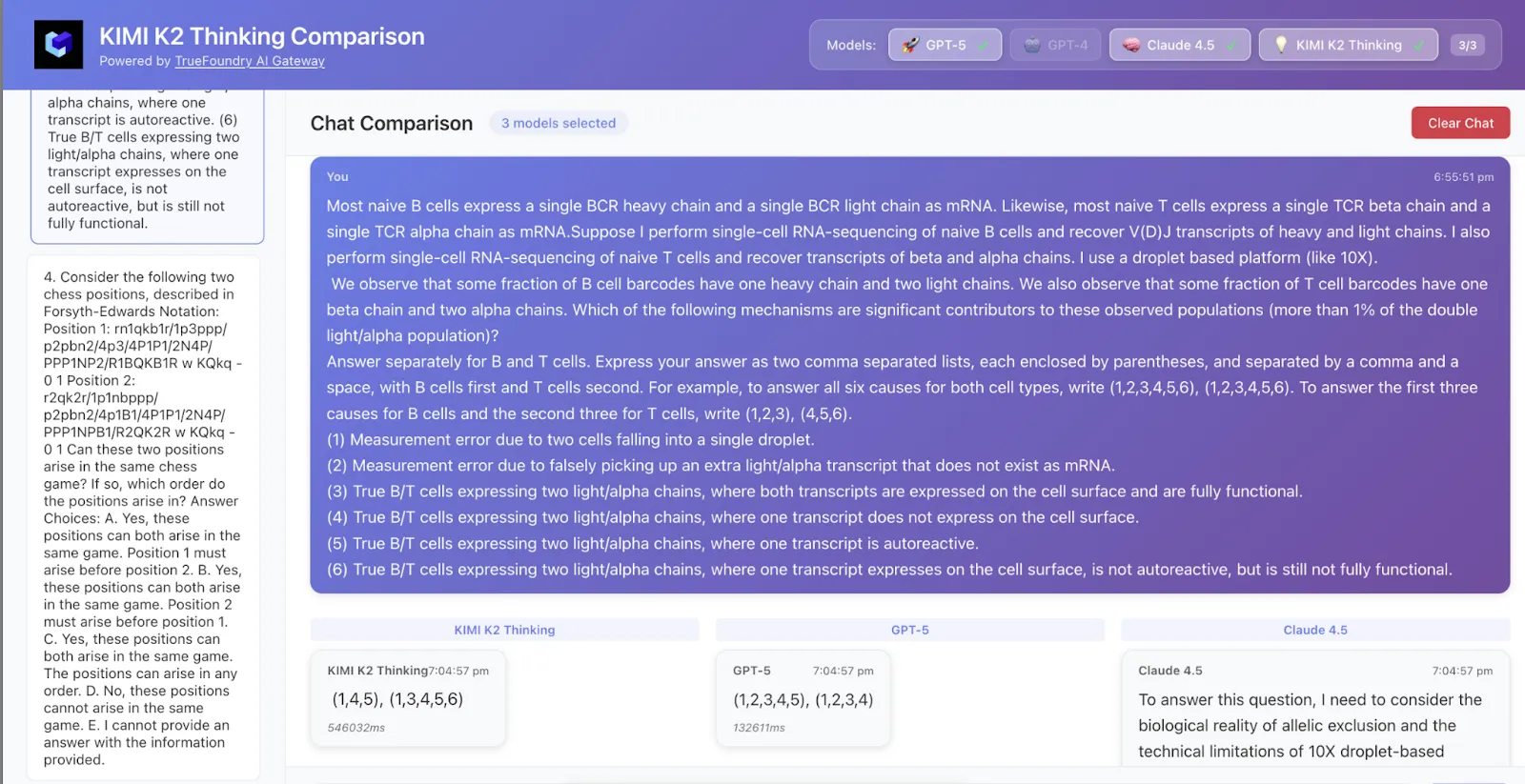
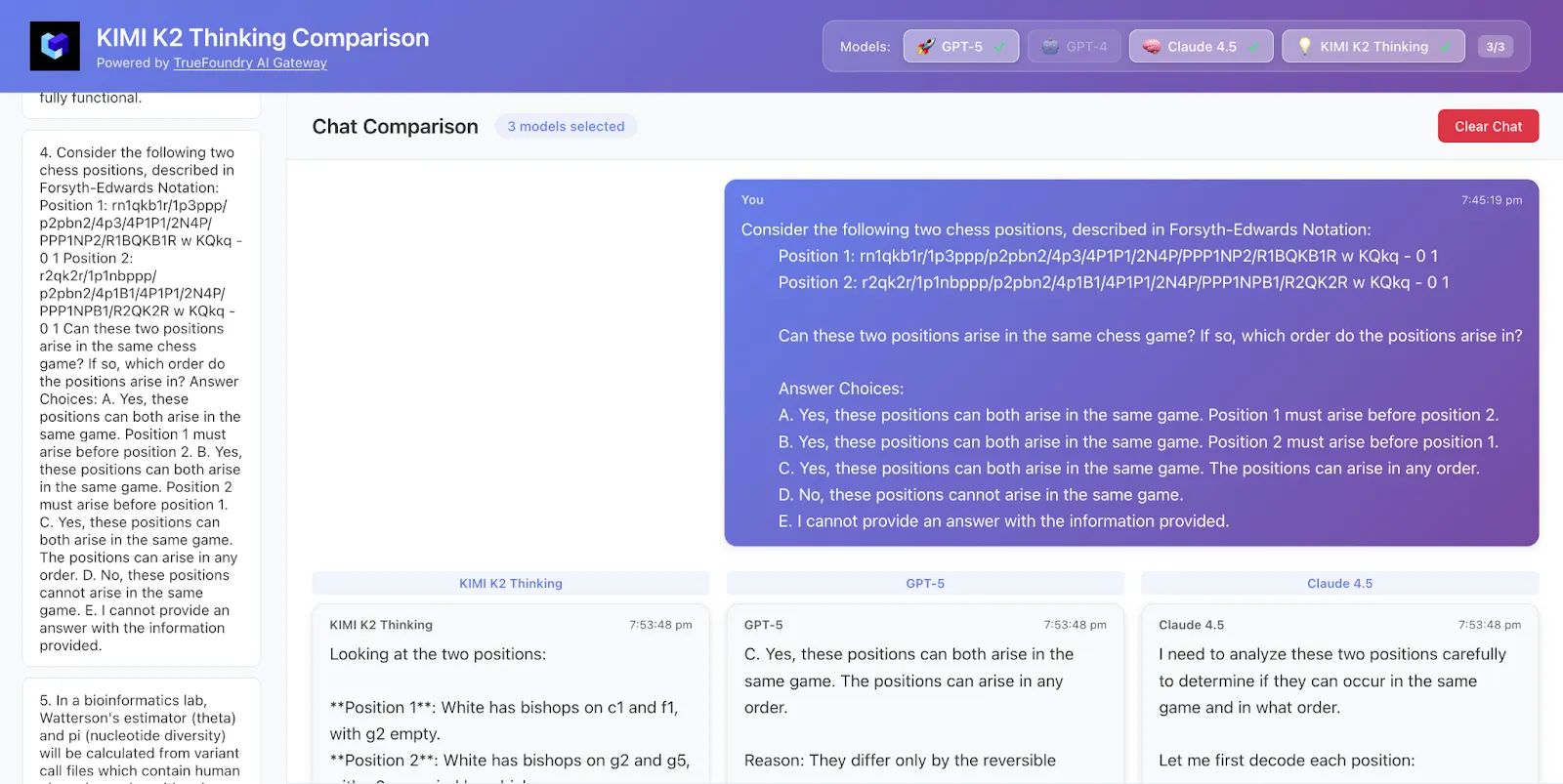
Kimi K2 acertó tanto en la respuesta como en la lógica, mientras que GPT-5 solo obtuvo la respuesta correcta y Claude no tenía razón.
Kimi-K2 es más o menos duplicando del rendimiento de HLE sin herramientas → con herramientas (≈ 24 → 45%) demuestra un punto crucial:
En pocas palabras: los logros de la HLE sugieren que el problema central es cómo un modelo razona y usa herramientas, no solo el tamaño del modelo sin procesar.
Más allá de los puntos de referencia, lo más emocionante es lo accesible que se está volviendo este tipo de capacidad. No tienes que esperar meses para experimentar: puedes probarlo tú mismo. Puerta de enlace de IA TrueFoundry facilita el acceso directo a Kimi-K2 Thinking y a otros modelos vanguardistas, compararlos con sus propios datos o integrarlos en los flujos de trabajo.
Si quieres una ayuda más personalizada, reserve una demostración — el equipo puede explicarle el rendimiento, las opciones de implementación, el costo y cómo evaluar estos modelos en sus tareas. Nos mantenemos al día con el mercado y nos aseguramos de que los nuevos modelos estén disponibles para su consumo lo antes posible.
En pocas palabras: Kimi-K2 Thinking no es solo otro LLM, es una visión visible del futuro de los agentes capaces de razonar: abiertos, eficientes, conscientes de las herramientas y preparados para la resolución de problemas en varios pasos. Pruébelo, compárelo con sus propios problemas y compruebe la diferencia que supone la orquestación de herramientas por agencia en tareas reales.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


