

August 27, 2025
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
El panorama de la infraestructura de aprendizaje automático está repleto de algunas de las soluciones más impresionantes que existen para simplificar el proceso de aprendizaje automático. TrueFoundry puede ser una solución si te refieres a algunos de los problemas que se mencionan a continuación:
La razón principal por la que hemos descubierto los retrasos en los plazos es la dependencia entre los equipos y la falta de habilidades con diferentes personajes. TrueFoundry facilita a los científicos de datos la formación y el despliegue en Kubernetes mediante Python. También permite a los equipos de infraestructura configurar las restricciones de seguridad y los presupuestos de costos. En la mayoría de las empresas con las que hemos hablado, el flujo de implementación es el siguiente:
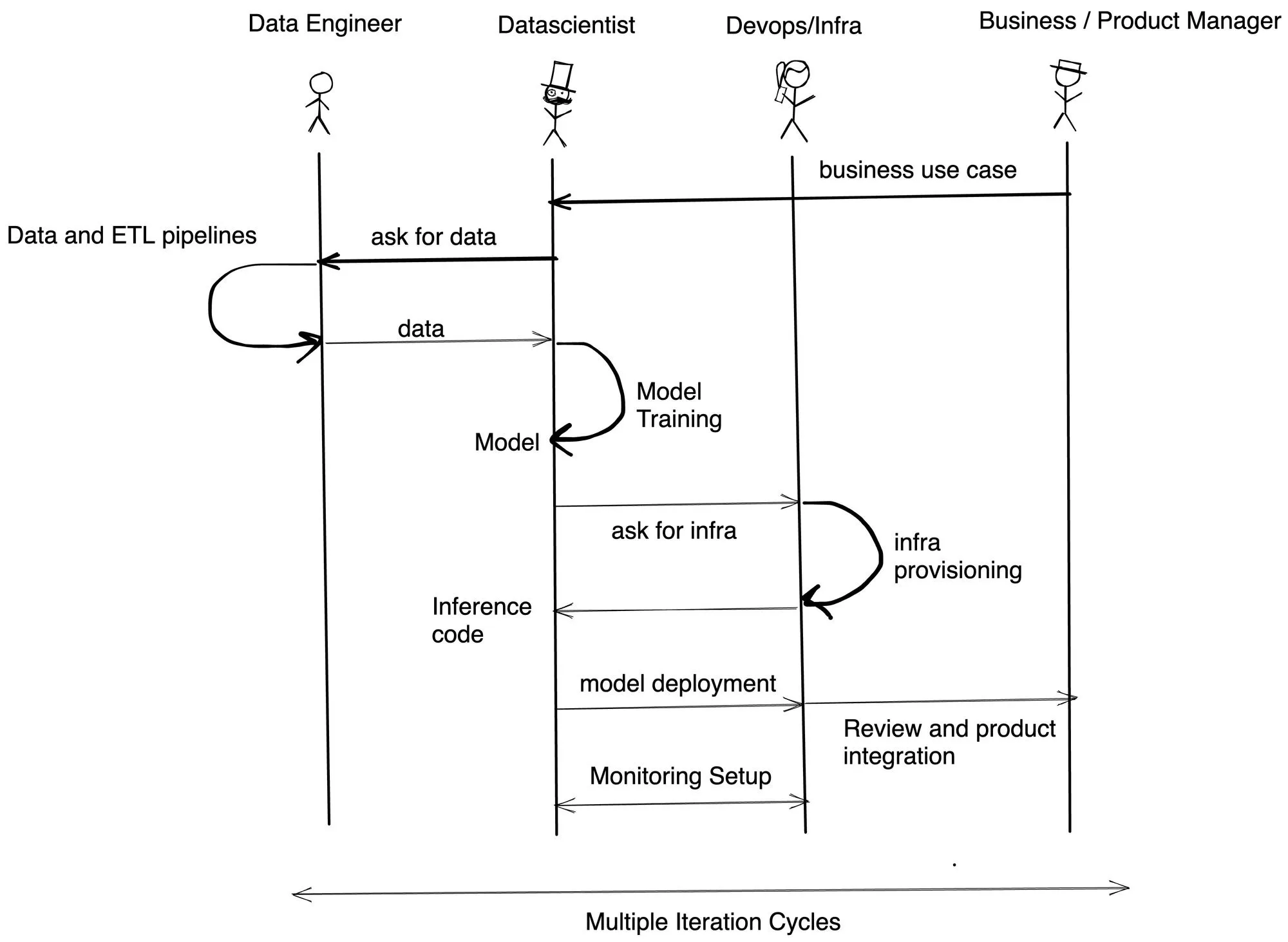
TrueFoundry le ayuda a reducir el tiempo de desarrollo al menos entre 3 y 4 veces al permitir a los científicos de datos implementar y evaluar el modelo por su cuenta sin depender del equipo de Infra/DevOps.
Con TrueFoundry, el flujo es similar al siguiente:
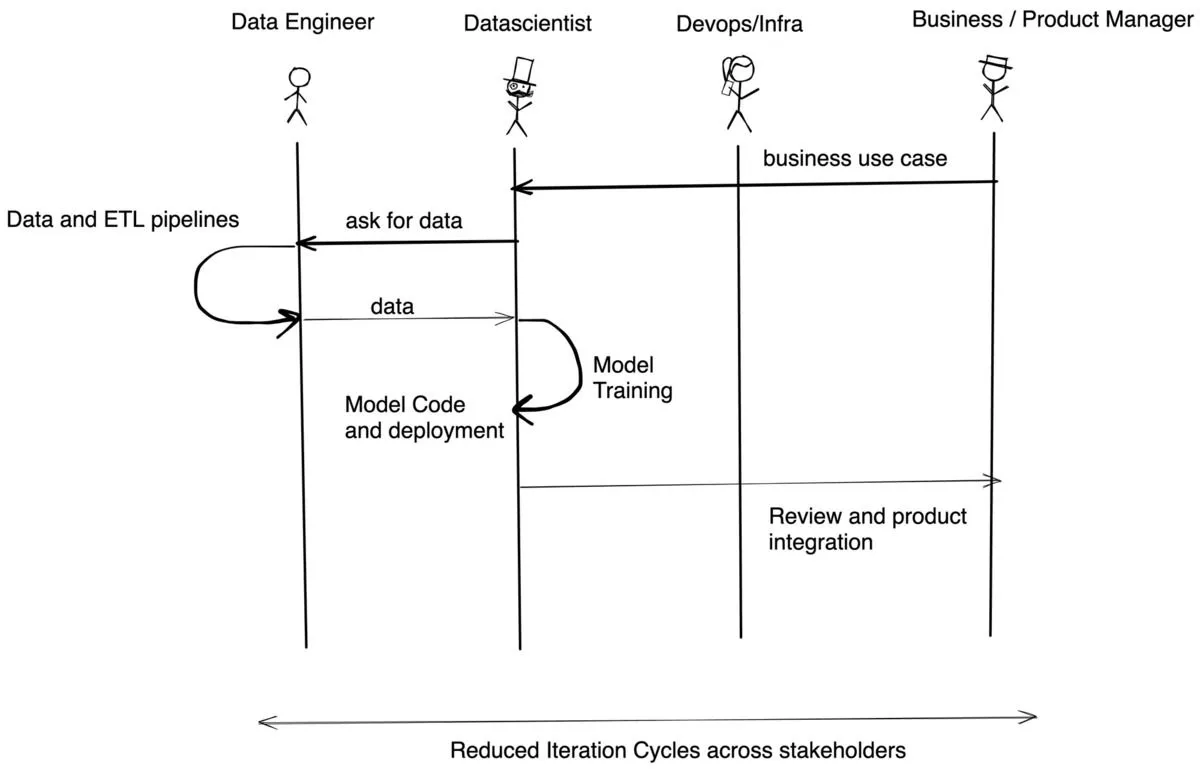
TrueFoundry es nativo de Kubernetes y funciona con clústeres de EKS, AKS, GKE (clústeres estándar y de piloto automático) o clústeres locales. El aprendizaje automático requiere algunas cosas personalizadas en comparación con la infraestructura de software estándar, como el aprovisionamiento dinámico de nodos, el soporte de GPU, los volúmenes para un acceso más rápido, la presupuestación de costos y la autonomía de los desarrolladores. Nos ocupamos de todos los detalles esenciales de los clústeres para que pueda centrarse en crear las mejores aplicaciones en una infraestructura de última generación.
Proporcionamos las API de Python, por lo que nunca tendrás que interactuar con YAML. También ofrecemos soporte para YAML si quieres usarlo en tus canalizaciones de CI/CD. Por ejemplo, al usar TrueFoundry, puedes implementar una API de inferencia usando el siguiente código:
servicio = Servicio (
nombre = «fastapi»,
image=construir (
build_spec=PythonBuild (
command="uvicorn app:app --port 8000 --host 0.0.0.0",
requirements_path=» requirements.txt «,
)
),
puertos= [
Puerto (
puerto=8000,
<Provide a host value based on your configured domain>anfitrión=»»
)
],
resources=Recursos (
cpu_request=0.5,
límite de cpu=1,
memory_request=1000,
límite de memoria = 1500
),
env= {
«UVICORN_WEB_CONCURRENCY»: «1",
«MEDIO AMBIENTE»: «dev»
}
)
service.deploy (workspace_fqn="tfy-cluster/my-workspace»)
TrueFoundry se implementa completamente en su propio clúster de Kubernetes. Los datos permanecen en tu propia VPC, las imágenes de Docker se guardan en tu propio registro de Docker y todos los modelos permanecen en tu propio sistema de almacenamiento de blobs. Puedes obtener más información sobre la arquitectura TrueFoundry aquí.
Kubernetes suele admitir el escalado automático mediante HPA en función de la CPU y la memoria. Sin embargo, en el caso de las cargas de trabajo de aprendizaje automático, el escalado automático en función del recuento de solicitudes es mucho mejor en muchos casos. Otro desafío del escalado automático puede ser el elevado tiempo de arranque de los modelos, debido al gran tamaño de las imágenes y a los tiempos de descarga de los modelos. Truefoundry resuelve estos problemas al proporcionar un tiempo de inicio del contenedor en segundos, almacenar en caché los modelos para una carga más rápida y proporcionar tiempos de inferencia más rápidos.
¿Podemos usar algunos modelos de LLM de código abierto?
TrueFoundry le permite implementar y ajustar los LLM de código abierto en su propia infraestructura. Ya hemos descubierto la mejor configuración para los modelos de código abierto más comunes para que pueda entrenarlos e implementarlos con la configuración óptima y al menor costo.
Organizamos un campo interno de LLM donde puedes decidir qué LLM quieres incluir en la lista blanca para los desarrolladores de la empresa, incluidos los alojados internamente, y diferentes desarrolladores pueden experimentar con los datos internos. He aquí un breve vídeo sobre el mismo tema:
Los cuadernos Jupyter son esenciales para el ciclo de desarrollo diario de los científicos de datos. Ejecutar Jupyter Notebooks localmente en la propia máquina no siempre es una opción por las siguientes razones:
Nos hemos esforzado mucho para ejecutar Jupyter Notebooks sin problemas en Kubernetes. Los cuadernos Jupyter en TrueFoundry ofrecen las siguientes ventajas en comparación con los cuadernos JupyterLab o Kubeflow:
TrueFoundry proporciona un registro de modelos que puede rastrear qué modelos se encuentran en qué etapa y el esquema y la API de todos los modelos del registro.
TrueFoundry permite dividir o reflejar el tráfico de un modelo a otro. Esto es especialmente útil cuando quieres probar una nueva versión del modelo en tráfico en vivo durante algún tiempo antes de pasarla a producción. Truefoundry también admite estrategias de despliegue canarias y azul-verdes en la implementación de modelos.
Nos hemos esforzado mucho para asegurarnos de eliminar las diferencias esenciales de los clústeres de Kubernetes en las nubes. Los desarrolladores pueden escribir e implementar el mismo código en cualquier entorno sin preocuparse por la infraestructura subyacente. Nos encargamos de comprobar si los componentes subyacentes de Kubernetes están instalados, comprobar las migraciones incompatibles e informar a los desarrolladores al respecto.
Exponemos la visibilidad de los costos de los servicios a los desarrolladores y proporcionamos información para reducir el costo. Todos nuestros clientes actuales han conseguido una reducción de costes de al menos un 30% tras adoptar Truefoundry.
True Foundry es una implementación de aprendizaje automático (PaaS sobre Kubernetes) diseñada para simplificar Despliegue del modelo de IA, acelere los flujos de trabajo de los desarrolladores y mantenga un control total de la infraestructura. A través de nuestra plataforma, permitimos a los equipos de aprendizaje automático implementar y supervisar modela en 15 minutos con un 100% de confiabilidad, escalabilidad y la capacidad de revertirse en segundos, lo que les permite ahorrar costos y lanzar los modelos a la producción más rápido, lo que permite obtener un verdadero valor empresarial.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada





.png)

.webp)
.webp)
.webp)



.webp)
.webp)


