

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
.webp)
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
El auge de los modelos lingüísticos de gran tamaño ha transformado la forma en que los equipos crean productos basados en la IA, pero también ha introducido nuevos desafíos. Los desarrolladores deben supervisar el rendimiento de los modelos, optimizar los costos, refinar las instrucciones y garantizar la confiabilidad a escala. La gestión de todas estas partes móviles requiere visibilidad y control sobre cada llamada y respuesta de la API.
Helicone surgió para resolver exactamente este problema. Proporciona una plataforma unificada para rastrear, analizar y optimizar las solicitudes a modelos lingüísticos como OpenAI o Anthropic, lo que ayuda a los equipos a depurar los errores más rápido y a reducir la sobrecarga operativa.
Sin embargo, a medida que las organizaciones evolucionan, sus requisitos suelen superar lo que ofrece Helicone. Algunas necesitan un análisis más profundo, una implementación local o un mayor control sobre la privacidad de los datos. Otros buscan herramientas con más flexibilidad o una lógica de enrutamiento avanzada.
Ahí es donde alternativas como True Foundry entra. Diseñado para operaciones empresariales de IA, TrueFoundry Puerta de enlace de IA y Puerta de enlace MCP proporcionan una visibilidad completa, enrutamiento multimodelo e infraestructura que prioriza el cumplimiento, lo que ayuda a los equipos a escalar el uso de los modelos de manera segura y eficiente.
En esta guía, analizaremos qué es Helicone, cómo funciona, por qué los equipos buscan alternativas y revisaremos las 5 principales alternativas de Helicone para ayudarlo a elegir la solución adecuada para su infraestructura de IA.
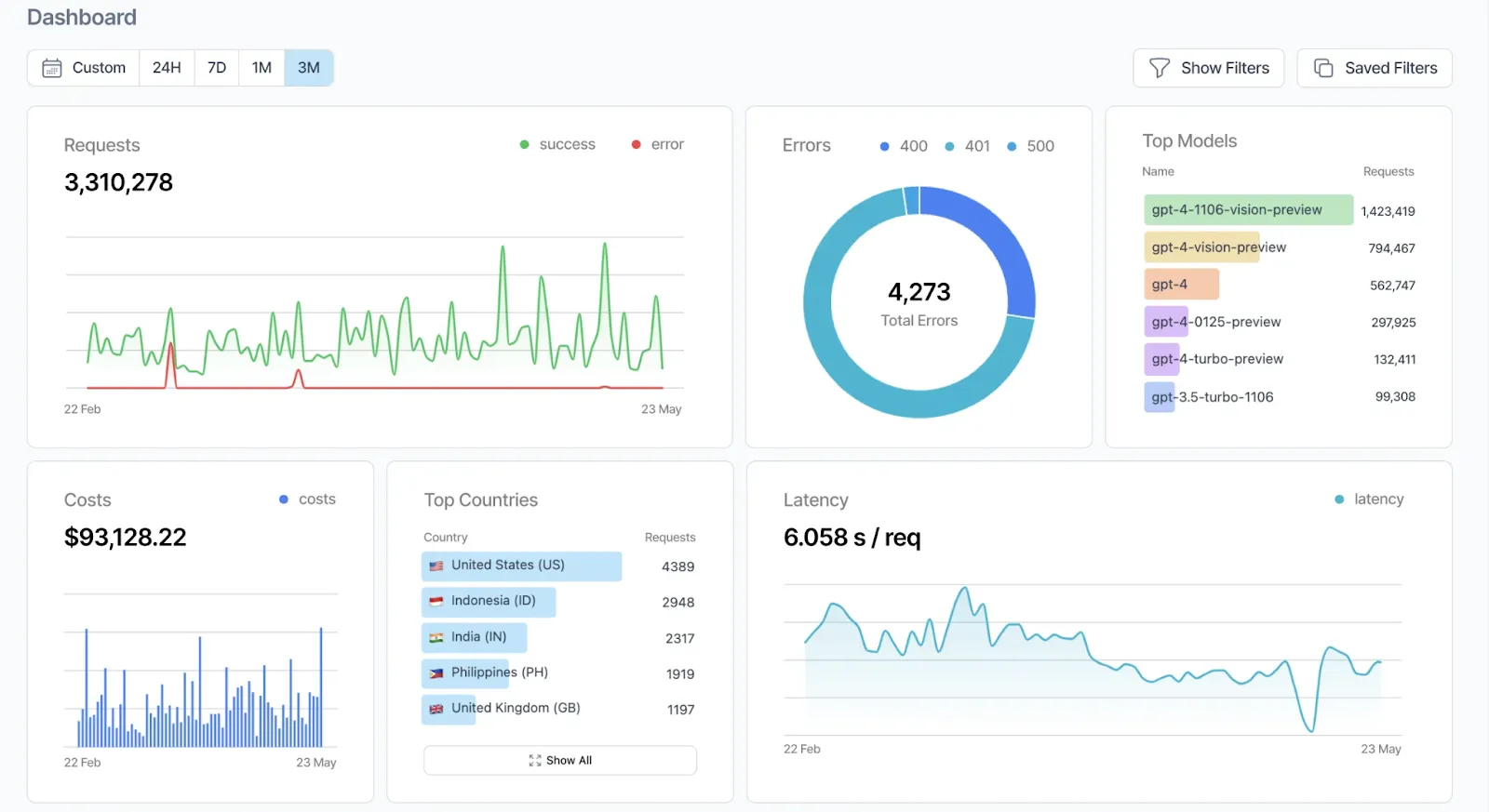
Helicone es una plataforma de observación y monitoreo de LLM de código abierto diseñada para brindar a los desarrolladores un control y una visibilidad totales sobre sus aplicaciones de IA. Sirve como una puerta de enlace de alto rendimiento que conecta su aplicación con los principales proveedores de modelos lingüísticos, como OpenAI, Anthropic, Google Gemini, Together AI y muchos otros, a través de una única interfaz unificada.
En un ecosistema de IA en rápida evolución, la visibilidad y la trazabilidad son fundamentales. Helicone simplifica las operaciones de LLM al capturar automáticamente todos los detalles de una solicitud, desde las indicaciones y las respuestas hasta el uso de los tokens, la latencia y el costo. Esta centralización elimina la necesidad de realizar un seguimiento manual de varias API y ayuda a los equipos a detectar problemas, mejorar el rendimiento y optimizar el comportamiento de los modelos con precisión.
Características principales de Helicone
Más allá de sus características principales, Helicone ha creado una sólida comunidad de código abierto. Con más de 4.000 estrellas en GitHub y contribuciones de cientos de desarrolladores, sigue creciendo rápidamente. El enfoque de la comunidad en la transparencia y la extensibilidad la convierte en una opción confiable para los ingenieros de inteligencia artificial que desean confiabilidad sin depender de un proveedor.
Ya sea que su objetivo sea mejorar la confiabilidad del modelo, reducir los costos operativos u obtener capacidad de observación en tiempo real en toda su pila de IA, Helicone proporciona la infraestructura necesaria para crear, monitorear y escalar aplicaciones inteligentes con confianza.
Helicone actúa como una puerta de enlace de API unificada que conecta su aplicación con más de 100 proveedores de modelos lingüísticos. Al enviar las solicitudes a través de Helicone, los desarrolladores pueden simplificar las integraciones, mejorar la observabilidad y optimizar el rendimiento del modelo sin realizar cambios importantes en el código.
Integración perfecta
La integración de Helicone es sencilla. Los desarrolladores pueden configurar sus OpenAI u otros SDK de LLM existentes para que apunten al punto final de la puerta de enlace de Helicone:
const client = new OpenAI({
apiKey: process.env.HELICONE_API_KEY,
baseURL: "https://ai-gateway.helicone.ai"
});
Este enfoque permite que las aplicaciones interactúen con varios proveedores de LLM mediante una interfaz uniforme, lo que reduce la complejidad de la administración de diversas API.
Observabilidad integral
Helicone registra automáticamente los metadatos detallados de cada solicitud, lo que brinda a los desarrolladores información en tiempo real sobre sus flujos de trabajo de IA. Los datos registrados incluyen:
Toda esta información está disponible a través de un panel centralizado, lo que permite a los equipos supervisar el rendimiento, identificar los cuellos de botella y analizar las tendencias de uso de manera eficiente.
Enrutamiento y conmutación por error inteligentes
Helicone incluye un motor de enrutamiento inteligente que optimiza la entrega de solicitudes. Las capacidades clave incluyen:
Este sistema de enrutamiento garantiza una alta confiabilidad y un rendimiento uniforme en diferentes escenarios de implementación.
Almacenamiento en caché perimetral para la optimización del rendimiento
Para reducir la latencia y los costos de API, Helicone ofrece almacenamiento en caché perimetral. Las respuestas solicitadas con frecuencia se almacenan en el borde, lo que permite una recuperación más rápida y minimiza las llamadas redundantes a la API, lo que mejora la velocidad y la rentabilidad.
Opciones de implementación flexibles
Helicone admite despliegues alojados en la nube y autohospedados:
Ambas opciones de implementación cumplen con los estándares de nivel empresarial, incluidos SOC 2 e HIPAA, lo que las hace adecuadas para entornos seguros y regulados.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Si bien Helicone proporciona observabilidad, enrutamiento y registro integrales para las aplicaciones de LLM, es posible que no cumpla con los requisitos específicos de cada organización. Los equipos suelen considerar alternativas para abordar las limitaciones en cuanto a la flexibilidad, la estructura de costos o las funciones especializadas, especialmente al evaluar las ventajas y desventajas que se analizan en helicone vs portkey comparaciones.
Una razón para explorar alternativas es la diversidad y el control de los modelos. Helicone admite más de 100 modelos, pero es posible que algunas organizaciones requieran integraciones nativas con LLM exclusivas o exclusivas que no son totalmente compatibles. Las alternativas pueden ofrecer una integración más fácil con estos modelos o una lógica de enrutamiento más avanzada.
Las consideraciones clave para explorar alternativas incluyen:
La flexibilidad de personalización e implementación es otro factor. Si bien Helicone admite el autohospedaje mediante gráficos de Helm, algunos equipos necesitan un mayor control sobre las estrategias de almacenamiento en caché, los formatos de registro o los despliegues en varias regiones. Las consideraciones de costo y escalabilidad también impulsan la evaluación. Helicone ofrece facturación automática, pero las empresas con un gran volumen de solicitudes o restricciones presupuestarias estrictas pueden beneficiarse de herramientas que optimicen aún más el uso.
Explorar las alternativas de Helicone ayuda a las organizaciones a encontrar soluciones mejor alineadas con sus necesidades técnicas, objetivos operativos y consideraciones de costos, al tiempo que mantiene una sólida observabilidad y confiabilidad de la LLM.
Si bien Helicone ofrece una potente capacidad de observación y enrutamiento para las aplicaciones de LLM, es posible que no se adapte a las necesidades específicas de cada equipo. Los desarrolladores suelen explorar alternativas para obtener más flexibilidad, mejorar los análisis o realizar integraciones especializadas.
Las siguientes cinco plataformas ofrecen opciones confiables para monitorear, rastrear y optimizar modelos lingüísticos de gran tamaño, cada una con puntos fuertes únicos que se adaptan a los diferentes flujos de trabajo.
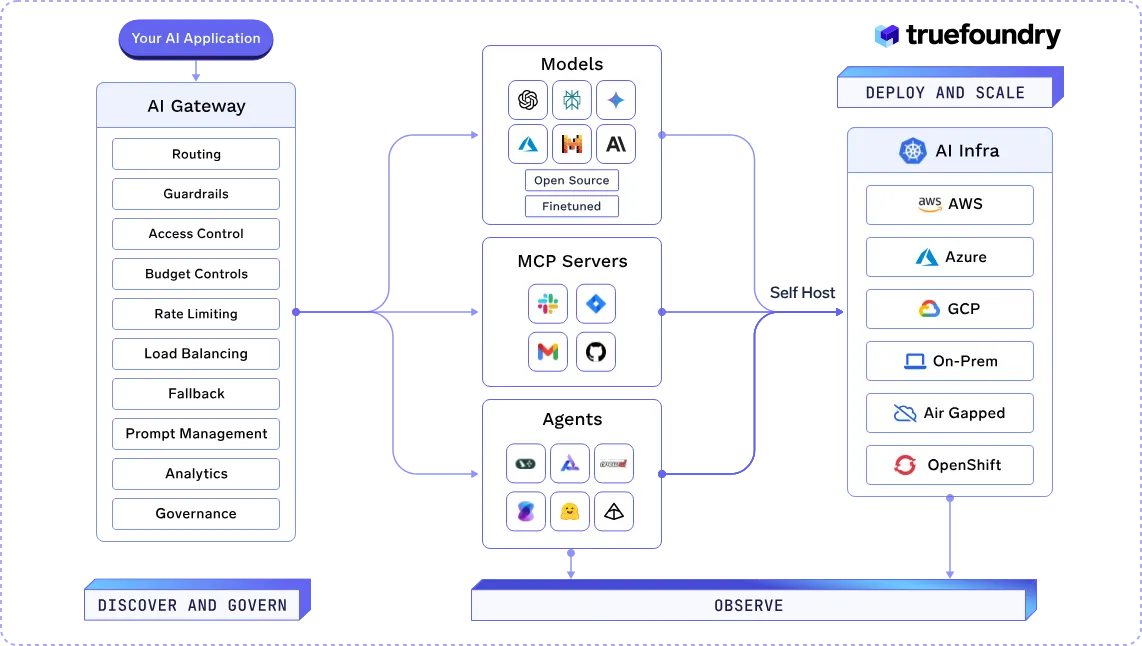
True Foundry proporciona una infraestructura unificada para crear, implementar y administrar aplicaciones de IA a escala. Ofrece herramientas para organizar los agentes de IA, gestionar las implementaciones de modelos y garantizar la seguridad y el cumplimiento en varios entornos.
Los componentes principales de la plataforma incluyen la puerta de enlace de IA, los servidores de protocolo de control modelo (MCP) y las capacidades de rastreo, cada uno diseñado para abordar desafíos específicos en el desarrollo y la implementación de aplicaciones de inteligencia artificial.
TrueFoundry es una plataforma empresarial líder porque unifica el despliegue, la observabilidad y la gobernanza de la IA en una solución escalable. Sus funciones avanzadas, como el AI Gateway, los servidores MCP y el rastreo de extremo a extremo, brindan a las organizaciones un control, una seguridad y una transparencia totales, lo que la hace ideal para administrar aplicaciones de IA complejas a escala.
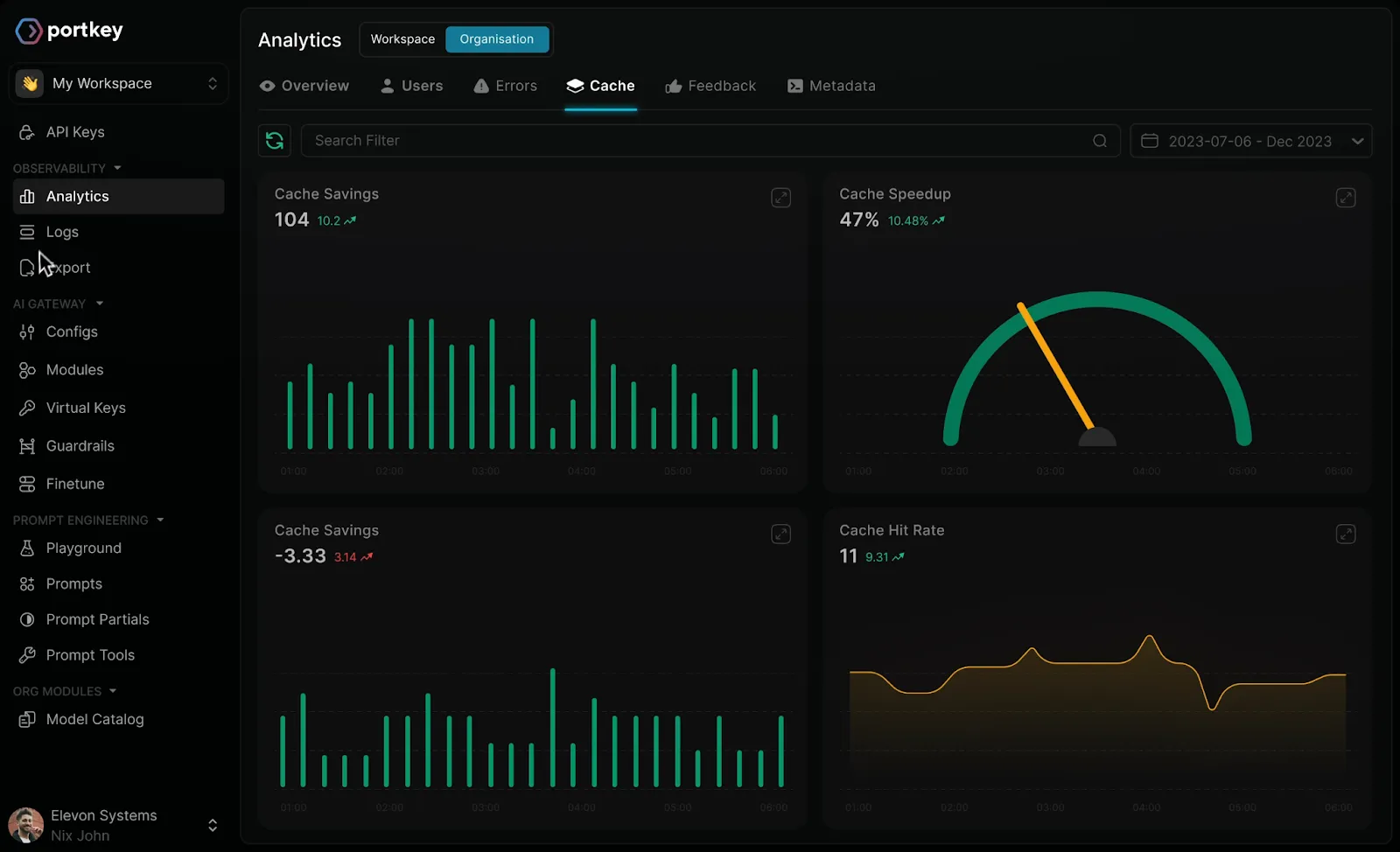
Portkey es una pasarela de IA de código abierto creada para simplificar la forma en que las organizaciones interactúan con modelos de varios idiomas. En lugar de administrar API independientes para cada proveedor, los desarrolladores pueden usar Portkey como una interfaz única para enviar solicitudes, monitorear el rendimiento y enrutar el tráfico de manera eficiente.
Esto simplifica los flujos de trabajo y reduce la sobrecarga de integrar y mantener varios modelos simultáneamente.
Más allá de la conectividad básica, Portkey ofrece funciones de enrutamiento inteligente que permiten que las solicitudes se dirijan automáticamente al modelo más adecuado en función del rendimiento, el costo o las reglas predefinidas. Esto se discute a menudo entre los equipos cuando comparan alternativas a Portkey. También admite mecanismos de respaldo y reintentos, lo que garantiza la confiabilidad incluso cuando algunos puntos finales experimentan latencia o tiempo de inactividad. La capacidad de observación está integrada en la plataforma, con métricas detalladas sobre las tasas de éxito de las solicitudes, la latencia y los patrones de uso.
Características principales:
Contras:
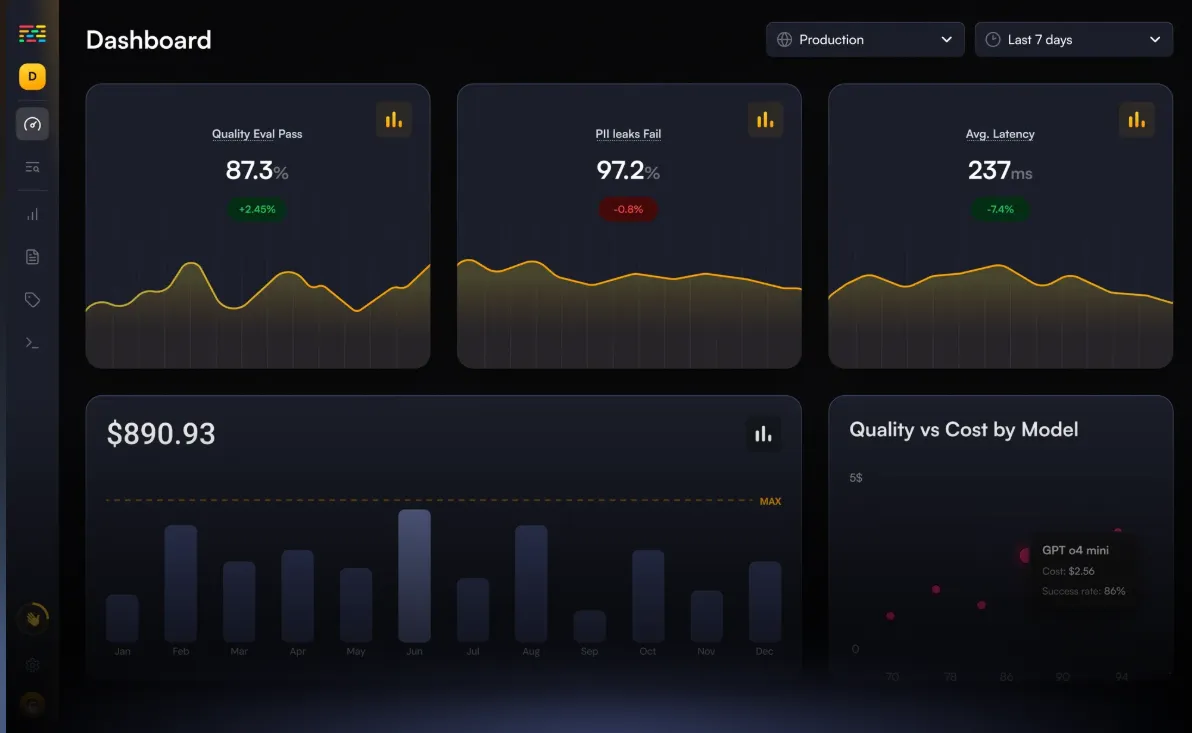
OpenLLMetry de Traceloop es un marco de observabilidad de código abierto basado en OpenTelemetry, diseñado para monitorear y depurar aplicaciones de modelos de lenguaje de gran tamaño. Proporciona información detallada sobre las interacciones y el rendimiento de los modelos, lo que facilita la optimización y la solución de problemas de forma eficaz.
Características principales:
Contras:
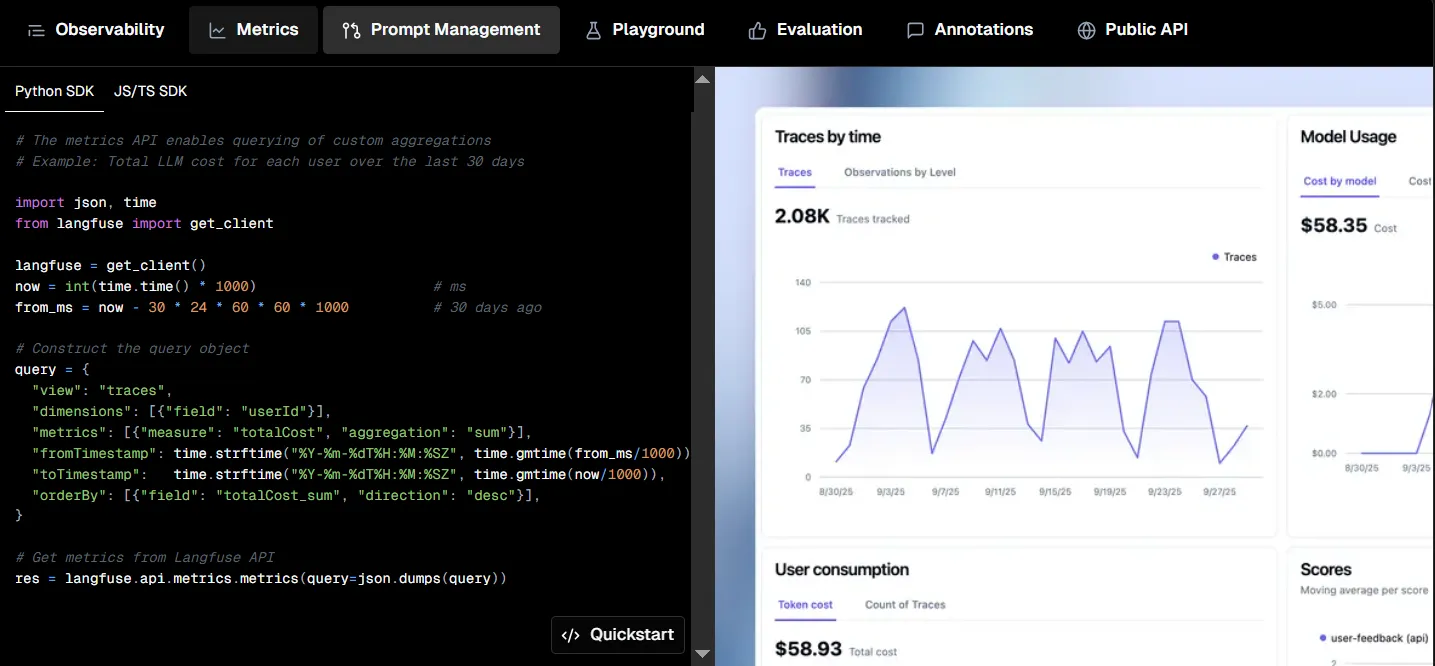
LangSmith, desarrollada por la comunidad LangChain, es una plataforma unificada de observabilidad y evaluación para aplicaciones de modelos lingüísticos de gran tamaño. Ofrece herramientas para rastrear, monitorear y analizar los flujos de trabajo de la IA, lo que mejora la depuración y la optimización del rendimiento.
Características principales:
Contras:
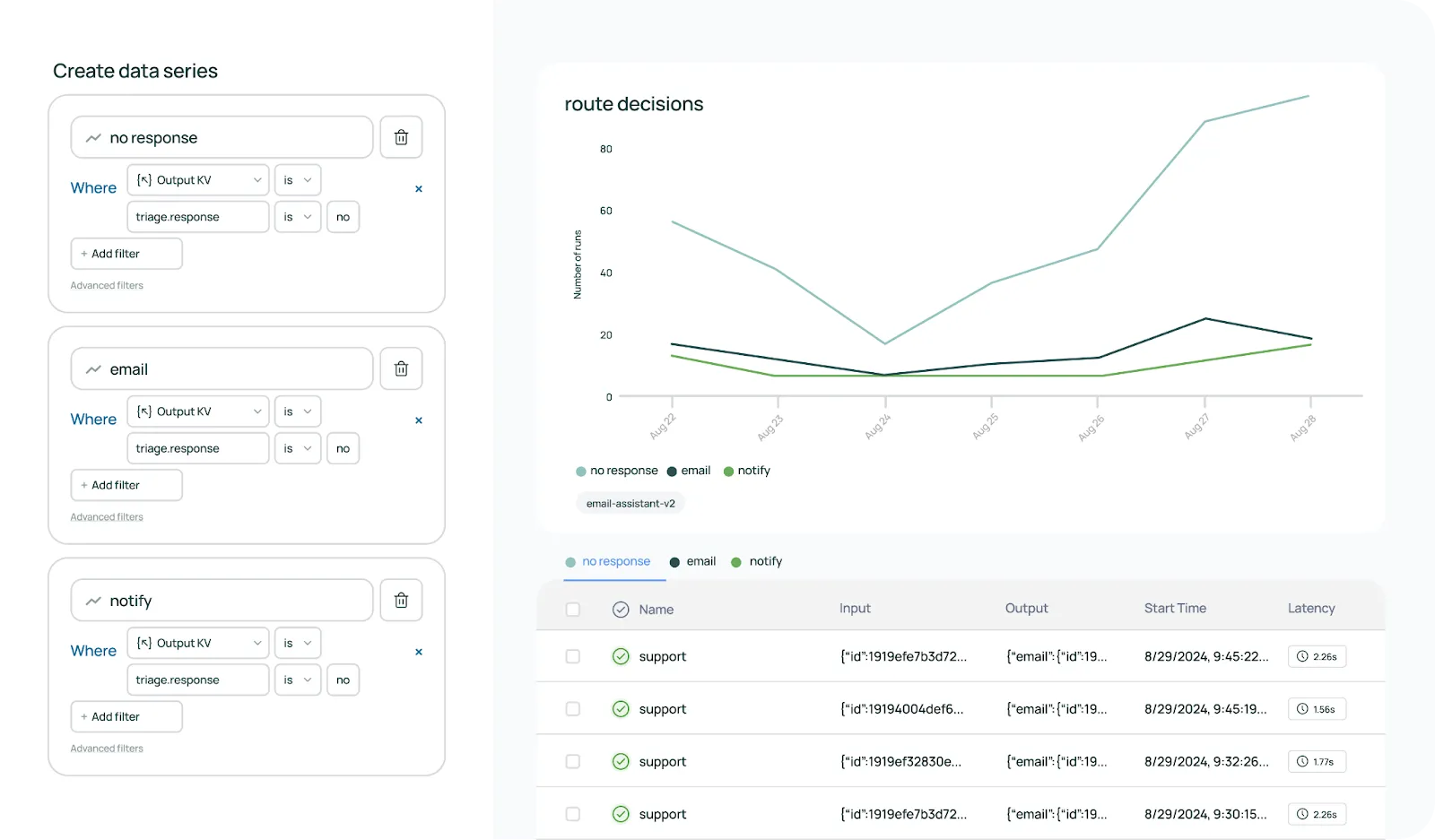
Langfuse es una plataforma de código abierto centrada en la observabilidad y el análisis para aplicaciones de modelos lingüísticos de gran tamaño. Permite a los equipos rastrear, analizar y optimizar los flujos de trabajo de inteligencia artificial, proporcionando información detallada sobre las interacciones y el rendimiento de los modelos.
Características principales:
Contras:
Helicone ofrece una potente plataforma de código abierto para la observabilidad, el enrutamiento y el análisis del LLM, lo que la convierte en una opción sólida para los equipos que buscan una supervisión integral de las aplicaciones de IA. Su capacidad para centralizar el registro, rastrear el uso de los tokens y proporcionar información sobre varios proveedores de modelos simplifica los desafíos operativos que implica crear sistemas confiables basados en la LLM.
Sin embargo, a medida que las aplicaciones de IA se vuelven más complejas, las organizaciones suelen necesitar soluciones que se adapten a flujos de trabajo, entornos de implementación o necesidades de integración específicos. Explorar las alternativas de Helicone permite a los equipos seleccionar plataformas que se ajusten mejor a sus requisitos técnicos y operativos. TrueFoundry, por ejemplo, proporciona orquestación, seguimiento y gobierno de nivel empresarial con capacidades avanzadas de AI Gateway y servidor MCP, lo que lo hace ideal para las organizaciones que priorizan la seguridad, el cumplimiento y la escalabilidad.
Portkey se destaca por el acceso unificado a las API y el enrutamiento en diversos modelos, mientras que Traceloop ofrece una observabilidad profunda a través del rastreo basado en OpenTelemetry. LangSmith ofrece evaluaciones y depuraciones específicas para las aplicaciones de LangChain, y Langfuse proporciona registros y análisis detallados para una observabilidad asincrónica.
La elección de la plataforma de observabilidad de LLM adecuada depende de factores como la flexibilidad de implementación, el soporte del modelo, la profundidad de monitoreo y la rentabilidad.
Al evaluar las características, los puntos fuertes y las limitaciones de cada opción, los equipos de desarrollo pueden implementar sistemas de IA sólidos, transparentes y escalables que mantengan el rendimiento, la seguridad y la confiabilidad en las cargas de trabajo de producción del mundo real.
Las mejores alternativas de Helicone para escala empresarial incluyen TrueFoundry, Portkey y Traceloop. Si bien Helicone se centra en una observabilidad ligera, TrueFoundry proporciona una infraestructura unificada con funciones de seguridad y puerta de enlace de inteligencia artificial integradas. Otras opciones notables, como Langfuse y Lunary, ofrecen un rastreo de código abierto para los equipos que requieren análisis profundos y herramientas de evaluación especializadas para las aplicaciones de producción.
Los equipos suelen cambiar cuando superan la supervisión básica de los proxies y requieren una gobernanza de nivel empresarial. Con frecuencia, Helicone se ve limitado por la falta de un RBAC sólido, un registro de auditorías y un soporte profundo para los flujos de trabajo de las agencias de varios pasos. El cambio a una plataforma como TrueFoundry permite la implementación dentro de una VPC privada y proporciona las políticas avanzadas de control de costos necesarias para administrar los sistemas de IA a escala de producción.
Sí, varias alternativas destacadas de código abierto incluyen Portkey, Langfuse y Traceloop. Estas plataformas permiten el autohospedaje y una integración más profunda con las canalizaciones de OpenTelemetry existentes. Para los desarrolladores que buscan un proxy simple basado en Python, LitellM es uno de los favoritos de la comunidad, ya que estandariza las llamadas a la API en cientos de modelos sin los gastos generales y los riesgos de datos propios de un proveedor de SaaS gestionado.
Sí, Helicone admite el enrutamiento multimodelo básico y la conmutación por error de proveedores a través de su API unificada. Sin embargo, carece de la lógica de enrutamiento sofisticada y compatible con los metadatos que se encuentra en las pasarelas empresariales. Plataformas como TrueFoundry amplían esta capacidad al permitir a los equipos definir cadenas alternativas complejas y cuotas a nivel de equipo, lo que garantiza una alta disponibilidad tanto en los proveedores de modelos comerciales como en los autohospedados.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


