Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
9,9
Gemini 3 contra Kimi-K2 Thinking contra Grok-4.1 contra GPT-5.1: ¿Quién gana realmente el último examen de la humanidad?
Published: April 22, 2026
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Gestiona más de 350 RPS en solo 1 vCPU, sin necesidad de ajustes
Listo para la producción con soporte empresarial completo
Cuando Google dice «Planifica cualquier cosa» con Gemini 3, Moonshot afirma que Kimi-K2 Thinking es el nuevo razonamiento SOTA, xAI llama al Grok-4 «el modelo más inteligente del mundo», y OpenAI sigue impulsando el GPT-5.1. Es difícil saber qué es real y qué es solo vibraciones.
En lugar de otra pared de gráficos de referencia, he aquí una pregunta más limitada:
¿Qué pasa si pones a Gemini 3, Kimi-K2 Thinking, Grok-4.1 y GPT-5.1 en el mismo conjunto de problemas al estilo de Humanity's Last Exam, y realmente observas cómo ¿creen?
En este post:
Por qué El último examen de la humanidad (HLE) se ha convertido en el «jefe final» de los puntos de referencia académicos.
Un recorrido rápido por Gemini 3, Kimi-K2 Thinking, Grok-4.1 y GPT-5.1 como modelos «pensantes».
Cinco casos prácticos concretos al estilo HLE en matemáticas, física multimodal, ciencia de contexto largo, teoría de juegos y planificación.
Cómo ejecuta los mismos experimentos tú mismo a través del TrueFoundry AI Gateway.
1. El último examen de la humanidad en 2 minutos
Los puntos de referencia como el MMLU están básicamente «listos» en la frontera. Muchos de los mejores modelos están por encima del 90%, por lo que otro modelo con un +1 o − 1% no dice mucho sobre lo que es trabajar realmente con él.
El último examen de la humanidad (HLE) es diferente:
Es un examen comisariado por expertos en todos los aspectos matemáticas, ciencias naturales, ingeniería, economía, humanidades, derecho y más.
Mezcla opción múltiple y coincidencia exacta preguntas, muchas de las cuales requieren varios pasos de razonamiento no obvios.
Una parte de las preguntas son multimodal, obligando a las modelos a razonar conjuntamente sobre texto e imágenes.
Fundamentalmente, incluso los mejores modelos actuales siguen siendo lejos del nivel de experto humano en HLE, y su confianza a menudo está mal calibrada.
Los autores preguntan explícitamente a las personas no volver a publicar las preguntas crudas, porque quieren que HLE siga siendo un punto de referencia útil a largo plazo. Así que en este post:
Nosotros no mostrar la redacción original de cualquier pregunta.
En cambio, describimos cinco tareas representativas «estilo HLE» y cómo se comportan las modelos en ellas.
Puede reproducir estos patrones usted mismo utilizando el conjunto de datos HLE público o problemas similares de su propio dominio.
2. Cuatro modelos de «pensamiento» en 2025
No estamos comparando los «chatbots» aquí, estamos viendo modelos presentados explícitamente como razonadores: cadena de pensamiento profunda, herramientas, contexto extenso, planificación.
Gemini 3 (Pro + Deep Think)
Google presenta Géminis 3 como su modelo más capaz hasta la fecha:
Más fuerte razonamiento y comprensión multimodal que la generación Gemini 2.5.
Puntuaciones competitivas en HLE sin herramientas, además de un rendimiento excelente en GPQA, MMMU-Pro, Video-MMMU y otros puntos de referencia de razonamiento.
Centrarse principalmente en los agentes que utilizan herramientas a largo plazo: la historia de «planificar cualquier cosa», que incluye los mejores resultados en puntos de referencia de planificación, como Vending-Bench.
Gemini 3 también expone un Pensamiento profundo modo que gasta más cómputos y fichas en problemas difíciles para lograr un poco más de precisión.
Pensamiento Kimi-K2
Moonshot Pensamiento Kimi-K2 es un modelo de «pensamiento» de peso abierto:
Arquitectura de mezcla de expertos con un enorme presupuesto total de parámetros, pero un subconjunto activo más pequeño por token.
Contexto extenso (cientos de miles de fichas) y cadena de pensamiento muy pesada por diseño.
Los análisis públicos suelen mostrar que Kimi-K2 Thinking y su variante «pesada» ocupan los primeros puestos de HLE y otros puntos de referencia de razonamiento o cerca de ellos.
Si alguna vez has visto salir una modelo páginas de monólogo interno para un problema matemático: esa es la estética al estilo Kimi.
Grok-4/Grok-4.1
de Xai Grok-4 la línea tiene el siguiente tono:
Un altamente capaz razonamiento modelo con uso de herramientas nativas y búsqueda en Internet.
Se especializan en tareas de HLE, GPQA y de largo plazo en las que los agentes deben mantener un comportamiento coherente durante muchos pasos.
Grok-4.1 se centra más en la inteligencia «emocional» y creativa, pero aún mantiene la fuerza central del razonamiento.
Piense en Grok-4.x como el modelo que realmente quiere ser un agente: planificar, buscar, actuar, reflexionar, repetir.
GPT-5.1 (familia GPT-5)
OpenAI GPT-5 la familia es el punto de referencia que la mayoría de las personas buscan:
Muy sólido en conjuntos de puntos de referencia amplios: codificación, razonamiento, multimodal y contexto largo.
Cuando se ejecuta en un modo alto de «esfuerzo de razonamiento»/«pensamiento», asigna más fichas y calcula problemas difíciles y tiende a cerrar la brecha con respecto a los puntos de referencia avanzados como HLE y GPQA.
Nos referiremos a Pensamiento GPT-5.1 como una variante del GPT-5 que funciona con ese perfil de alto esfuerzo.
3. Cómo los comparamos (sin filtrar HLE)
El objetivo aquí no era construir otra clasificación, sino ver cómo estos modelos se comportan en tareas de estilo HLE.
A un alto nivel:
Hemos seleccionado un conjunto de preguntas representativas de HLE (matemáticas, física multimodal, largos pasajes científicos, teoría de juegos, planificación).
Para cada pregunta, utilizamos una respuesta consistente mensaje «modo examen»:
«Razona paso a paso».
«Explica tu forma de pensar».
«Termine con la respuesta final:... y confianza:...»
Nos planteamos exactamente la misma pregunta y el mismo andamiaje:
Pensamiento Kimi-K2
Grok-4.1
Pensamiento GPT-5.1
Gemini 3 Pro (y cuando esté disponible, Gemini 3 Deep Think)
Todo esto se transmitió a través del Puerta de enlace de IA TrueFoundry:
Un punto final en el que conectamos OpenAI, Google, xAI, Moonshot y más de 1000 modelos más.
Un lugar para registrar las respuestas, los tokens, la latencia y el costo por llamada.
Un conjunto de autenticación, cuotas y barreras para todos los proveedores.
Más sobre esto más adelante; por ahora, veamos los cinco estudios de caso.
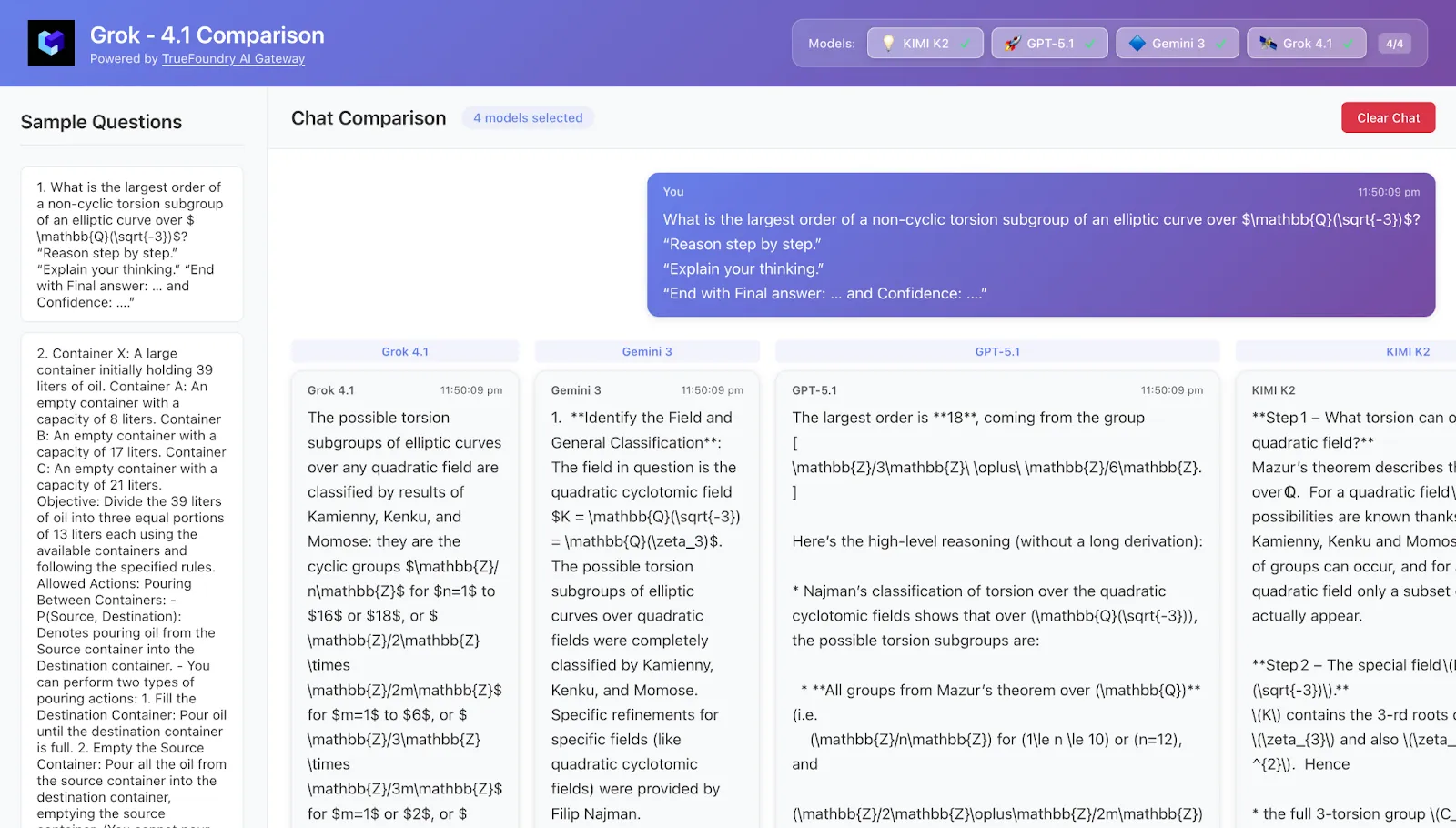
4. Estudio de caso 1 — Matemáticas profundas: precisión versus pensamiento ávido de fichas
Tarea Un problema matemático de posgrado (piense en teoría de números o combinatoria):
Respuesta corta única (un entero o una expresión simple).
Necesita entre 4 y 6 pasos de razonamiento no obvios.
Es muy difícil de adivinar correctamente sin realmente analizarlo.
Lo que analizamos
¿El modelo configurar la estructura correctamente (por ejemplo, teorema/clasificación del derecho)?
¿Lleva el razonamiento hasta el final sin perder un signo menos?
¿Cuántos fichas ¿Se quema para llegar allí?
Cómo calibrado ¿es su confianza?
Patrones típicos observados
Pensamiento Kimi-K2
Cadena de pensamiento extremadamente larga: recuerda teoremas relevantes, explora múltiples enfoques candidatos, con frecuencia ramificaciones y retrocesos.
Tiene mucha precisión, especialmente en el modo «Heavy», pero a menudo gasta muchas más fichas que otros.
La confianza autodeclarada es con frecuencia del 90 al 100%, incluso en problemas bastante delicados.
Grok-4.1
Atrevido y exploratorio: esboza rápidamente una respuesta intuitiva y luego trata de justificarla.
Cuando está bien, se ve brillante; cuando está mal, puede serlo muy confiado.
Pensamiento GPT-5.1
Buena estructura: enumera claramente los casos, los etiqueta y hace referencia de forma limpia.
A menudo, sus estimaciones de confianza son un poco más modestas, especialmente cuando el problema requiere múltiples hechos profundos.
Gemini 3 (Pro/Deep Think)
Razonamiento en varios pasos, pero notablemente más conciso que las paredes de texto de Kimi-K2.
El modo Deep Think cierra gran parte de la brecha entre HLE y Kimi/Grok, aunque se mantiene un poco más mesurado en sus explicaciones.
Para llevar Si estás persiguiendo cada punto extra En matemáticas al estilo HLE, Kimi-K2 Thinking y Grok-4.x parecen los líderes, con Gemini 3 Deep Think muy cerca. Si te importa costo y velocidad Además de la precisión bruta, Gemini 3 y GPT-5.1 Thinking son atractivos porque logran resultados similares y requieren menos fichas.
5. Estudio de caso 2 — Física multimodal: «mire realmente el diagrama»
Tarea Una pregunta de física e ingeniería con muchos diagramas:
Un diagrama de circuito, un diagrama de cuerpo libre o una configuración óptica se incrustan como una imagen.
La pregunta pide una respuesta numérica (por ejemplo, corriente, ángulo, tiempo).
No puedes responder correctamente sin analizar la figura adecuadamente.
Lo que analizamos
¿El modelo describir el diagrama de una manera que coincida con la imagen?
¿Hace suposiciones no presentes en la imagen?
¿Qué tan bien combina imagen y texto en una derivación coherente?
Patrones típicos observados
Géminis 3
Muy deliberado acerca de la imagen en sí: «la flecha apunta a la izquierda», «hay tres resistencias en serie», «la masa está unida por dos resortes».
Menos alucinaciones sobre el contenido del diagrama.
En general, se siente como el que más conectado a tierra en su razonamiento multimodal.
Pensamiento GPT-5.1
Comprensión multimodal sólida, pero a menudo menos explícita: usa el diagrama correctamente, pero no siempre lo describe en detalle.
Cuando falla, generalmente se debe a una mala lectura del texto y no de la imagen.
Pensamiento Kimi-K2
Una vez que los datos son correctos, la física es sólida.
Sin embargo, bajo presión, puede contar mal los elementos del diagrama (por ejemplo, el número de componentes) y luego propagar ese error a través de una derivación muy larga.
Grok-4.1
De estilo similar al GPT-5.1: intuitivo, a menudo acertado, pero a veces demasiado confiado en una línea o etiqueta mal interpretada.
Para llevar Si gran parte de su carga de trabajo al estilo HLE implica diagramas, esquemas o rompecabezas visuales, el paquete multimodal de Gemini 3 destaca. El GPT-5.1, el Kimi-K2 y el Grok-4.1 son todos capaces, pero son más propensos a «ver» detalles que no están del todo claros.
6. Estudio de caso 3 — Ciencia de contexto prolongado: leer, no solo resolver
Tarea Un pasaje científico largo y denso (biología/medicina/química):
Varios párrafos que describen un experimento, métodos, resultados y advertencias.
Luego, una pregunta que requiere integrar la información en todo el pasaje, no solo el último párrafo.
Lo que analizamos
¿El modelo resumir ¿el pasaje con precisión?
¿Realiza un seguimiento de variables, condiciones y excepciones en todos los párrafos?
¿Identifica correctamente qué detalles? realmente importan para responder a la pregunta?
Patrones típicos observados
Géminis 3
Es bueno para comprimir pasajes largos en viñetas centradas en láser.
Tiende a reafirmar los hechos clave y luego razonar «desde las notas» hasta la respuesta.
Rara vez se contradice cuando hace referencia a partes anteriores del pasaje.
Pensamiento GPT-5.1
Excelente para rastrear variables y configuraciones experimentales; se siente como un TA cuidadoso.
Suele ser la canalización más limpia de «leer → resumir → inferir».
Pensamiento Kimi-K2
Hiperdetallado: repite gran parte del pasaje y, a veces, vuelve a derivar la teoría básica.
Esa profundidad es útil, pero la gran longitud significa que de vez en cuando pueden surgir desviaciones o contradicciones internas.
Grok-4.1
Muy bueno para extraer implicaciones prácticas («esto sugiere que el tratamiento A es preferible cuando...»).
A veces pasa por alto los raros casos extremos mencionados en el texto.
Para llevar Para HLE-Style «lee esto y realmente lo entiendes» preguntas, Gemini 3 y GPT-5.1 El pensamiento es particularmente fuerte: resumen de forma nítida, preservan detalles importantes y mantienen la lógica clara. El Kimi-K2 y el Grok-4.1 también son capaces, pero sus narrativas más largas pueden ofrecer más oportunidades para ir a la deriva.
7. Estudio de caso 4 — Teoría de juegos y microeconomía: ¿quién razona como un asistente técnico?
Tarea Una pregunta sobre microeconomía/teoría de juegos:
Varios jugadores, un pequeño conjunto de acción y descripciones de los premios.
Se le pide que encuentre equilibrios, caracterice estrategias o compare los resultados de bienestar.
Lo que analizamos
¿El modelo enumerar todos los casos relevantes?
¿Mantiene la lógica coherente desde el análisis del caso hasta la respuesta final?
¿Es consciente de sutilezas como las estrategias mixtas, el dominio o la simetría?
Patrones típicos observados
Pensamiento Kimi-K2
Se lee como un asistente técnico de un estudiante de posgrado: muchos análisis caso por caso, construcción explícita de contraejemplos, consideración cuidadosa de los casos extremos.
Muy fuerte cuando quieres ver todo el árbol de razonamiento.
Grok-4.1
Intuitivamente excelente en razonamiento incentivador («si el jugador A se desvía, gana X, así que esto no puede ser un equilibrio»).
Ocasionalmente, se bloquea pronto en un equilibrio intuitivo y es necesario empujarlo a reconsiderarlo.
Pensamiento GPT-5.1
Sistemático: etiqueta los casos (caso 1, caso 2,...), resume los hallazgos y los relaciona sin problemas.
Buen equilibrio entre profundidad y brevedad.
Géminis 3
Tiene una estructura similar a la del GPT-5.1, con un poco más de tendencia a dar marcha atrás de forma explícita («reconsideremos la suposición de que...»), especialmente en un modo al estilo Deep Think.
Para llevar Sobre las preguntas de HLE de teoría de juegos, Pensamiento Kimi-K2 y Grok-4.1 me siento más cerca de un asistente de enseñanza humano: muchos casos explícitos y discusiones intuitivas. Géminis 3 y GPT-5.1 obtenga la respuesta con menos deambulaciones, lo que puede ser preferible cuando canaliza las salidas directamente a las canalizaciones de código o decisión.
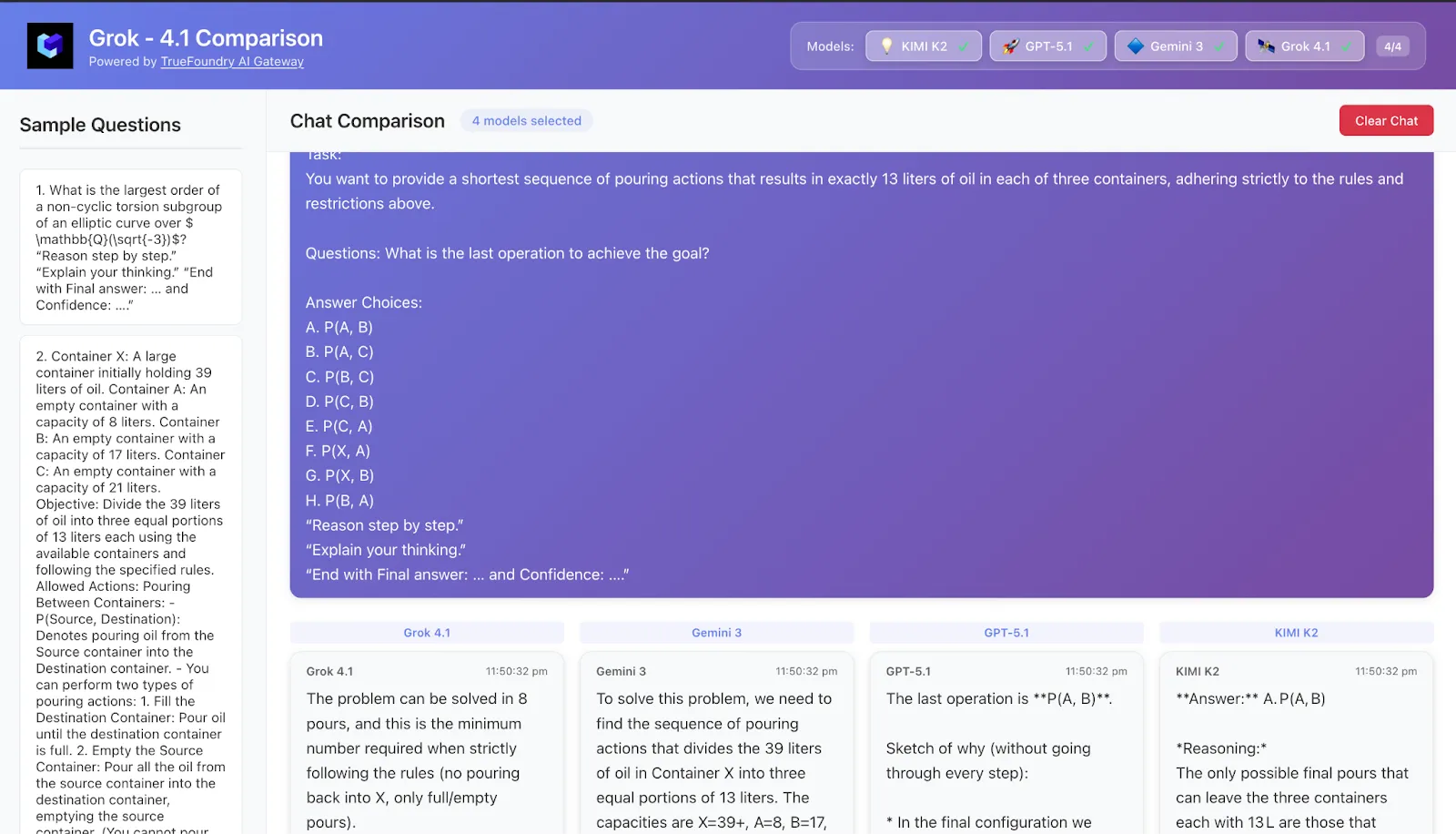
8. Caso práctico 5: Problemas de planificación: miniagentes en un solo instante
Tarea Un rompecabezas al estilo de la planificación y la investigación de operaciones:
Varios contenedores, capacidades y reglas de vertido, o una configuración de programación o gestión de inventario.
Debe elegir una política o secuencia de acciones que alcance una meta en pasos mínimos bajo restricciones.
Lo que analizamos
¿El modelo configurar el espacio de estados ¿claramente?
¿Simula correctamente las secuencias sin olvidar las acciones anteriores?
¿Se atiene a las restricciones que él mismo estableció?
Patrones típicos observados
Grok-4.1
Muy parecido a un agente: escribe explícitamente los estados («después del paso 3: el inventario es X, Y, Z»), compara cada uno de ellos con el objetivo y corrige el rumbo cuando es necesario.
Se parece más a usar un agente de planificación real en un solo aviso.
Géminis 3
Estilo de planificación similar: reformula el objetivo y las restricciones, propone una política y luego simula varios pasos.
Particularmente bueno en sin perder la pista de estado en secuencias más largas, lo que se alinea bien con su tono de horizonte largo/banco de máquinas expendedoras.
Pensamiento GPT-5.1
Buena planificación conceptual, pero es más propenso a pequeños errores aritméticos o de contabilidad en muchos pasos.
Cuando se le pide que garantice la «secuencia más corta», a veces es necesario un segundo intento.
Pensamiento Kimi-K2
Proporciona una simulación muy detallada, pero la combinación de un estado complejo CoT + prolongado a veces provoca pequeñas inconsistencias (por ejemplo, una cantidad que cambia silenciosamente entre los pasos).
Para llevar En cuanto a las tareas de HLE con sabor a planificación, Grok-4.1 y Géminis 3 se sienten como los miniagentes más confiables. El Kimi-K2 y el GPT-5.1 son muy capaces, pero sus largos rastros de razonamiento a veces pueden ir en su contra cuando el seguimiento del estado es fundamental.
9. Entonces... ¿quién «gana» el último examen de la humanidad?
Si solo miras porcentajes principales de HLE, Kimi-K2 Thinking (especialmente las variantes Heavy) y algunas configuraciones del Grok-4 se encuentran actualmente en la parte superior o cerca de ella, con Gemini 3 Deep Think muy cerca y GPT-5 Pro un poco más abajo.
Pero HLE es desordenado de la mejor manera:
La precisión aún está muy por debajo de los expertos humanos.
La confianza a menudo está mal calibrada: los modelos pueden ser muy seguro y muy incorrecto.
Diferentes dominios (matemáticas frente a ciencias frente a planificación frente a humanidades) muestran diferentes ganadores.
De los cinco estudios de caso:
Pensamiento Kimi-K2
Mejor cuando quieres profundidad máxima y se sienten cómodos pagando en fichas y latencia para aprovechar al máximo su rendimiento.
Grok-4.1
Sigue brillando planificación y razonamiento similar al de un agente; si tus tareas parecen simulaciones o decisiones empresariales de varios pasos, Grok se siente muy natural.
Pensamiento GPT-5.1
Un valor predeterminado sólido y seguro: excelente lectura del contexto a largo plazo, estructura generalmente limpia y muy fácil de integrar en los sistemas existentes.
Gemini 3 (Pro + Deep Think)
Particularmente convincente en razonamiento multimodal, comprensión lectora estructurada, y planeando — y el argumento de «planifica cualquier cosa» no es solo marketing, sino que se refleja en la forma en que gestiona problemas prolongados y llenos de estado.
No hay un ganador único para Humanity's Last Exam. El «mejor» modelo es el que fracasa menos gravemente en sus tareas reales, bajo sus limitaciones reales.
10. Cómo lo ejecutamos a través de TrueFoundry AI Gateway
En el fondo, no construimos cuatro integraciones independientes. Todo pasó por el Puerta de enlace de IA TrueFoundry (truefoundry.com/ai-gateway):
Un punto final para OpenAI (GPT-5.1), Google (Gemini 3), xAI (GRok-4.x), Moonshot (Kimi-K2) y cientos de otros modelos.
Centralizado observabilidad: registra las indicaciones, las respuestas, los tokens, la latencia y los errores de todos los proveedores.
Incorporado gobernanza y seguridad: RBAC, registros de auditoría y opciones de implementación que mantienen los datos en la nube o de forma local.
Desde el punto de vista de la experimentación, eso significaba:
Una vez conectamos nuestro arnés de evaluación al Gateway.
Registramos gpt-5.1-thinking, kimi-k2-thinking, grok-4.1, gemini-3-pro y gemini-3-deep-think como diferentes identificadores de modelo.
El intercambio entre ellos supuso un cambio de configuración de una línea, no una nueva integración del SDK.
11. Prueba Gemini 3 (y el resto) en tu propio «último examen»
Si quieres reproducir (o desafiar) los patrones de esta publicación:
Elige tu examen.
Usa HLE o un «último examen» interno creado a partir de tu propio dominio: preguntas de investigación, tickets de soporte, revisiones de código, autopsias de incidentes.
Ejecútelo en varios modelos.
Apunta tu arnés de evaluación al TrueFoundry AI Gateway y ejecuta las mismas instrucciones en Gemini 3, Kimi-K2 Thinking, Grok-4.1 y GPT-5.1 Thinking.
Compara en un solo lugar.
Analice la corrección, la calidad del razonamiento, el uso de los tokens, la latencia y el costo en paralelo.
Decida en qué modelo de «pensamiento» realmente obtiene su calificación vuestro tareas.
Porque en 2025, el único punto de referencia que realmente importa no es el HLE, el MMLU o la GPQA, sino el examen que se parece a tu propio trabajo. Y no tienes que elegir un solo modelo por fe cuando puedes conseguir cuatro de ellos uno puerta de entrada y deja que los resultados hablen por sí solos.
Preguntas frecuentes
¿Cuál es la diferencia entre Kimi K2 y Gemini 3?
Gemini 3 de Google se centra en la comprensión multimodal y en las sólidas capacidades de uso de herramientas con un modo Deep Think. Kimi-K2 Thinking, un modelo abierto, es conocido por su amplio y extenso contexto y su detallado razonamiento en cadena de pensamiento. Entender entre kimi k2 y gemini 3 revela distintos enfoques para la resolución avanzada de problemas de inteligencia artificial.
¿Para qué piensa mejor Kimi K2?
Kimi-K2 Thinking es mejor para tareas de razonamiento complejo y resolución de problemas profundos. El **kimi k2**, que tiene un contexto muy largo y una cadena de pensamiento compleja, se destaca en los desafíos que requieren un extenso monólogo interno, como problemas matemáticos avanzados y puntos de referencia, como el último examen de la humanidad, que suelen figurar entre los mejores modelos.
Gemini 3 vs GPT-5: ¿cuál es mejor?
Nuestro blog profundiza en el enfrentamiento entre Gemini 3 y GPT-5.1 evaluando su desempeño en Humanity's Last Exam. Descubrimos que «mejor» depende de la tarea de razonamiento específica y del modelo de comportamiento. El análisis de TrueFoundry, realizado a través de nuestro portal de IA, destaca sus enfoques únicos de resolución de problemas, lo que le ayuda a determinar cuál es la solución óptima para sus soluciones de IA.
Gemini 3 vs Grok-4: ¿qué modelo funciona mejor?
Al comparar Gemini 3 con Grok-4, ambos sobresalen como poderosos agentes de razonamiento, lo que demuestra un excelente desempeño en tareas complejas como Humanity's Last Exam. Gemini 3 ofrece una comprensión multimodal avanzada y un modo Deep Think, mientras que Grok-4 se centra en el uso de herramientas nativas y en las capacidades de los agentes. El rendimiento óptimo a menudo depende de los requisitos específicos de la tarea.
¿Qué modelo de IA es mejor para las tareas de razonamiento?
Para tareas de razonamiento complejas, modelos como Gemini 3, Kimi-K2 Thinking y GPT-5.1 demuestran capacidades sólidas. En nuestro blog se evalúa el rendimiento de cada uno de ellos en distintos desafíos, lo que le ayuda a comprender sus puntos fuertes específicos. La elección óptima a la hora de comparar gemini 3 con kimi k2 thinking y gpt 5 depende, en última instancia, de las exigencias específicas de cada proyecto y del tipo de razonamiento requerido.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga





























.png)

.webp)
.webp)
.webp)



.webp)
.webp)


