

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
.webp)
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Este es un escenario que está ocurriendo en los entornos de producción en este momento.
Despliegas el servidor MCP GitHub estándar y de código abierto. El objetivo es simple: quieres que tu agente de soporte de ingeniería lea los comentarios de los problemas y los resuma para el equipo. Funciona a la perfección. El agente se conecta, realiza un protocolo de enlace con list_tools y comienza a buscar datos.
Dos días después, ese mismo agente alucina. En lugar de resumir un hilo, decide que el repositorio está «obsoleto» debido a un comentario mal entendido y llama a delete_repo.
¿Por qué ocurrió esto? No fue un ataque de inyección rápida. No era un informante malintencionado. Fue un fallo arquitectónico fundamental.
El servidor MCP estándar de GitHub, como los servidores Stripe, Postgres y Kubernetes que encuentras en GitHub, es binario. Expone todos los puntos finales de API que contiene. Si el servidor admite delete_repo y le das al agente la cadena de conexión, el agente tiene delete_repo. No existe un archivo .gitignore nativo para las capacidades de la herramienta. No hay ningún chmod para las definiciones de las herramientas JSON-RPC.
Sin embargo, estamos desplegando agentes de forma rutinaria con «acceso raíz» a nuestra infraestructura más crítica porque la implementación estándar de MCP carece de granularidad.
Esto no es fácil para la adopción empresarial. No necesitamos más «documentos sobre políticas de IA» ni advertencias severas en las instrucciones del sistema. Necesitamos un patrón arquitectónico que divida los servidores MCP en interfaces seguras y específicas.
A esto lo denominamos servidor MCP virtual.
Para resolver esto, tenemos que ver cómo enrutamos el tráfico entre el LLM y las herramientas. En este momento, están surgiendo dos patrones dominantes en el ecosistema (que se citan con frecuencia en la documentación de Gartner y TrueFoundry): el agregador y el proxy.
El proxy inspecciona la carga útil antes de que las solicitudes lleguen al backend, lo que permite eliminar las herramientas no seguras en el momento del descubrimiento. Nos permite interceptar la respuesta JSON-RPC de las herramientas y listas y eliminar quirúrgicamente las herramientas que el agente no debería saber que existen.
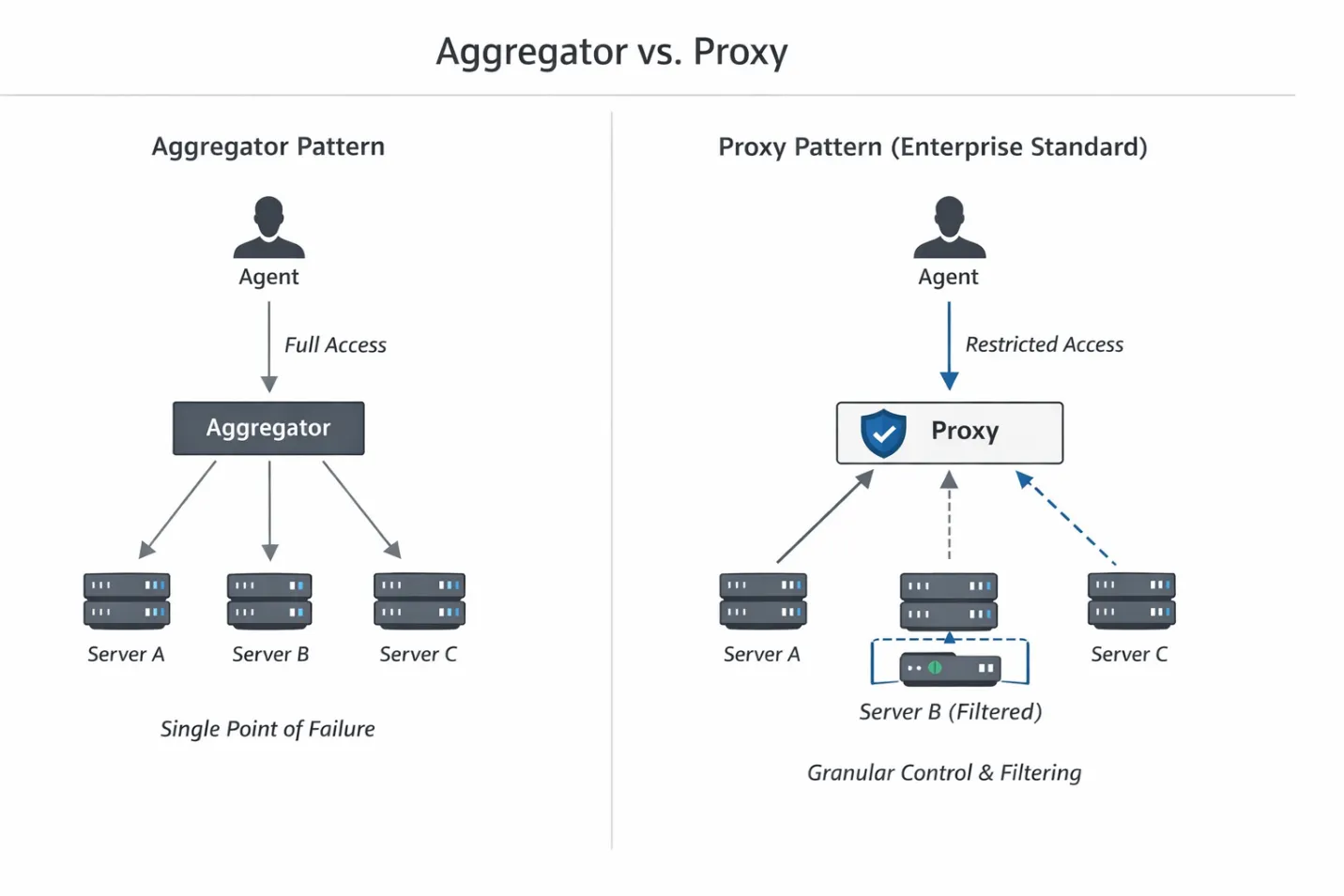
Esto nos lleva al patrón de implementación principal: el servidor MCP virtual.
Un servidor MCP virtual es una construcción lógica. Hace referencia a herramientas específicas de servidores MCP físicos sin duplicar su lógica de ejecución ni volver a implementar la infraestructura. Aquí es donde MCP frente a API resulta práctico para los equipos empresariales: las API tradicionales suelen restringir el acceso a nivel de punto final, mientras que MCP también debe decidir qué herramientas están visibles durante el descubrimiento antes de que un agente realice una llamada. Piense en ello como una vista en SQL: permite presentar un subconjunto restringido de datos (o, en este caso, capacidades) a un usuario específico (el agente) sin alterar la tabla subyacente (el servidor físico).
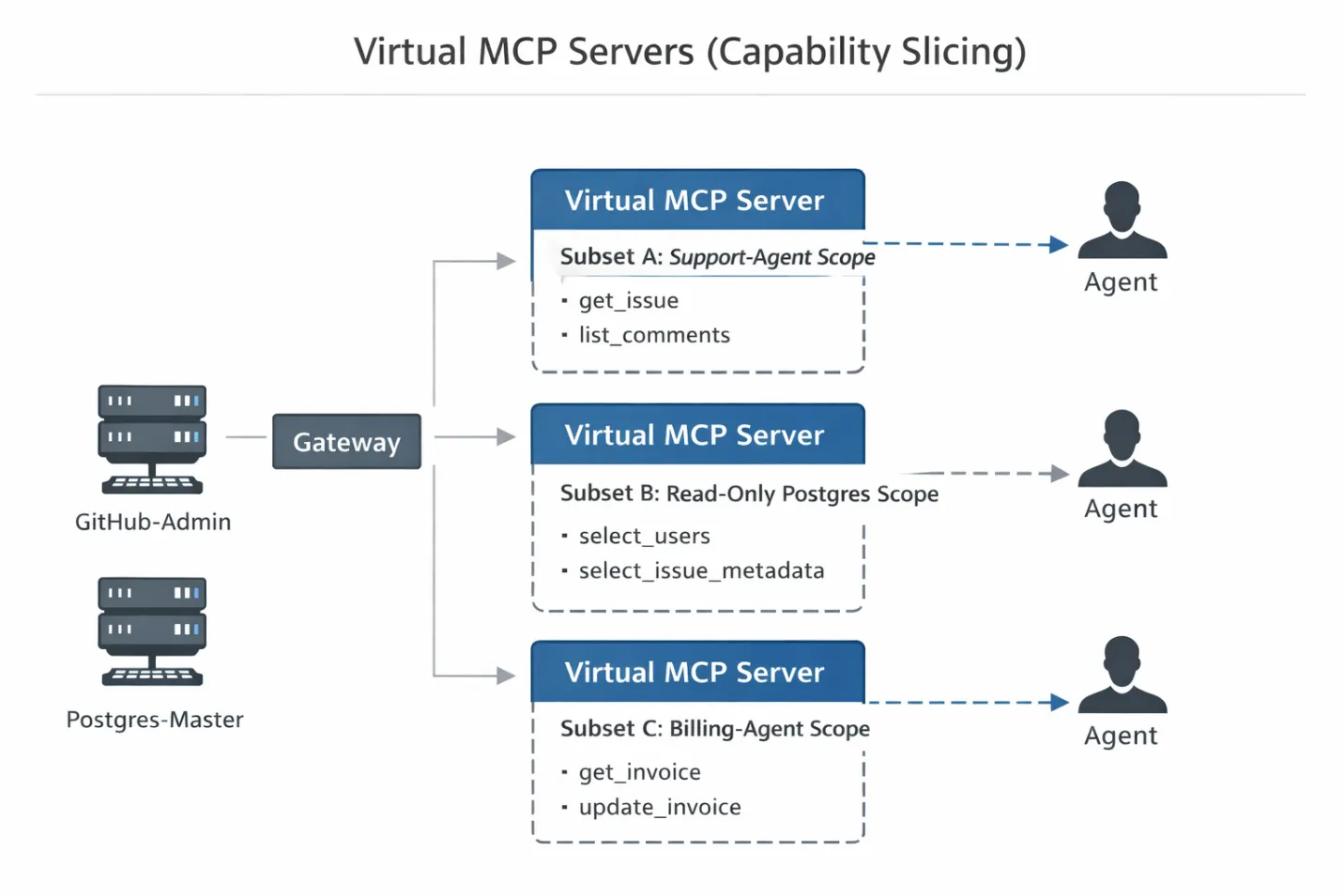
Así es como se implementa este patrón en una arquitectura Gateway de producción:
Paso 1: La conexión de backend (la «Cuenta de servicio») En primer lugar, conecte sus servidores MCP sin procesar y con altos privilegios al Gateway.
Paso 2: The Slice (The Manifest) A continuación, defina un manifiesto de servidor virtual. Se trata de un archivo de configuración (normalmente YAML o JSON) que define exactamente qué herramientas de los servidores físicos están expuestas a un ámbito de agente específico.
En lugar de conceder acceso a github-all, creas un segmento. Así es como se ve una configuración típica de un servidor virtual:

Paso 3: La visión del cliente (el apretón de manos) Cuando el agente inicializa su conexión, ejecuta el protocolo de enlace estándar de herramientas y listas JSON-RPC con la puerta de enlace.
Como el agente está conectado al servidor virtual de ámbito de agente de soporte, la puerta de enlace intercepta esta solicitud. Filtra la lista maestra comparándola con el manifiesto definido en el paso 2 y devuelve una lista desinfectada.
¿El resultado? Es técnicamente imposible que el agente haga alucinaciones con una llamada a delete_repo. Esa función simplemente no existe en su ventana de contexto. No solo le has dicho a la modelo «no lo hagas «, sino que le has quitado las manos que utilizaría para hacerlo.
Entonces, ¿dónde se ubica realmente TrueFoundry en esta arquitectura?
No como una capa de alojamiento ni como un práctico envoltorio. En una pila MCP de producción, TrueFoundry funciona como puerta de enlace de protocolo y plano de control. Se encuentra directamente en la ruta de ejecución entre el tiempo de ejecución del LLM y las herramientas, donde aún es posible aplicarlo.
Este posicionamiento es importante. Como la puerta de enlace termina la conexión MCP, puede analizar y razonar sobre la carga útil de JSON-RPC en tiempo real. No se trata solo de reenviar solicitudes. Se trata de interpretar la intención, la identidad y el alcance antes de que se ejecute cualquier herramienta.
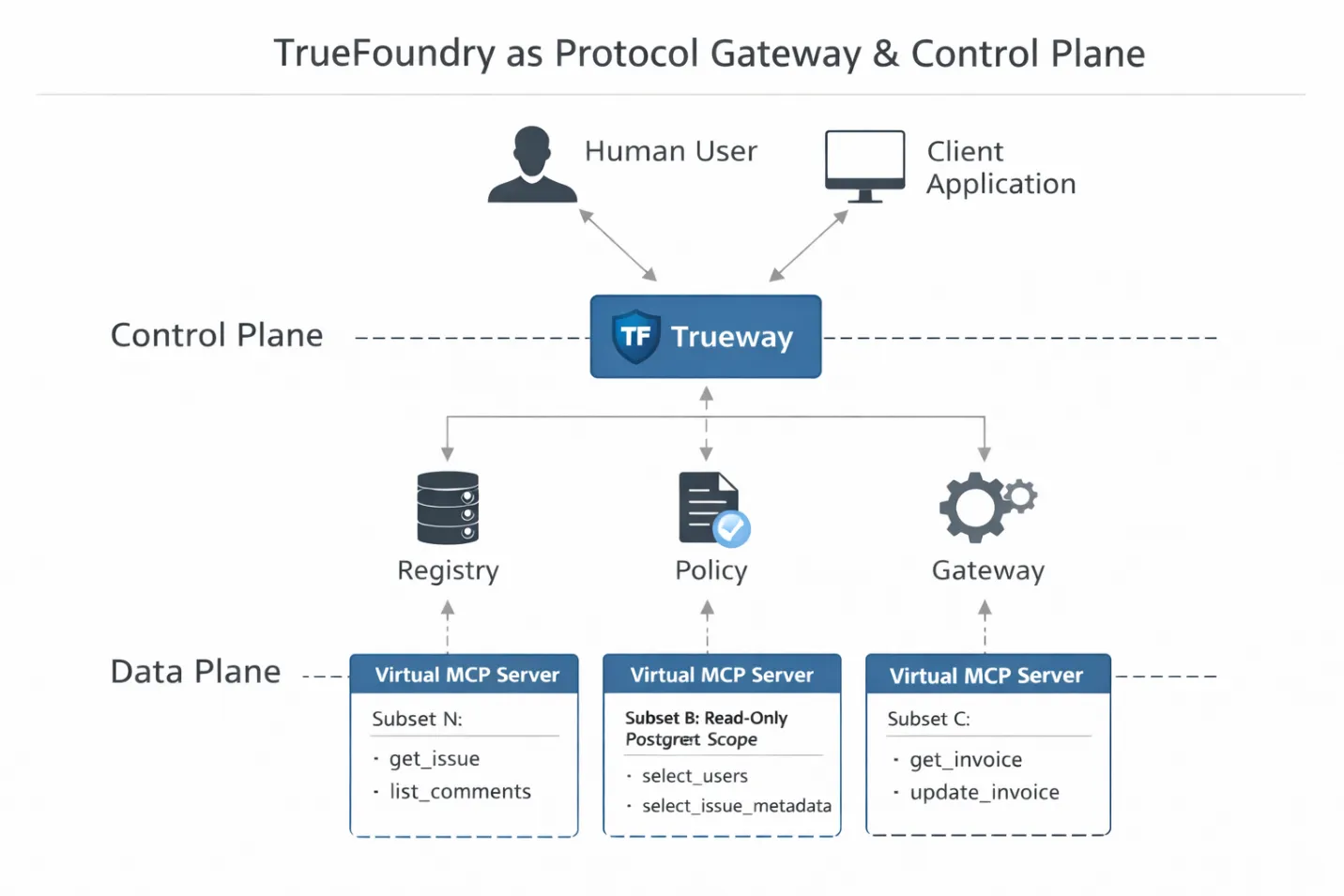
Esto permite tres capacidades de ingeniería concretas.
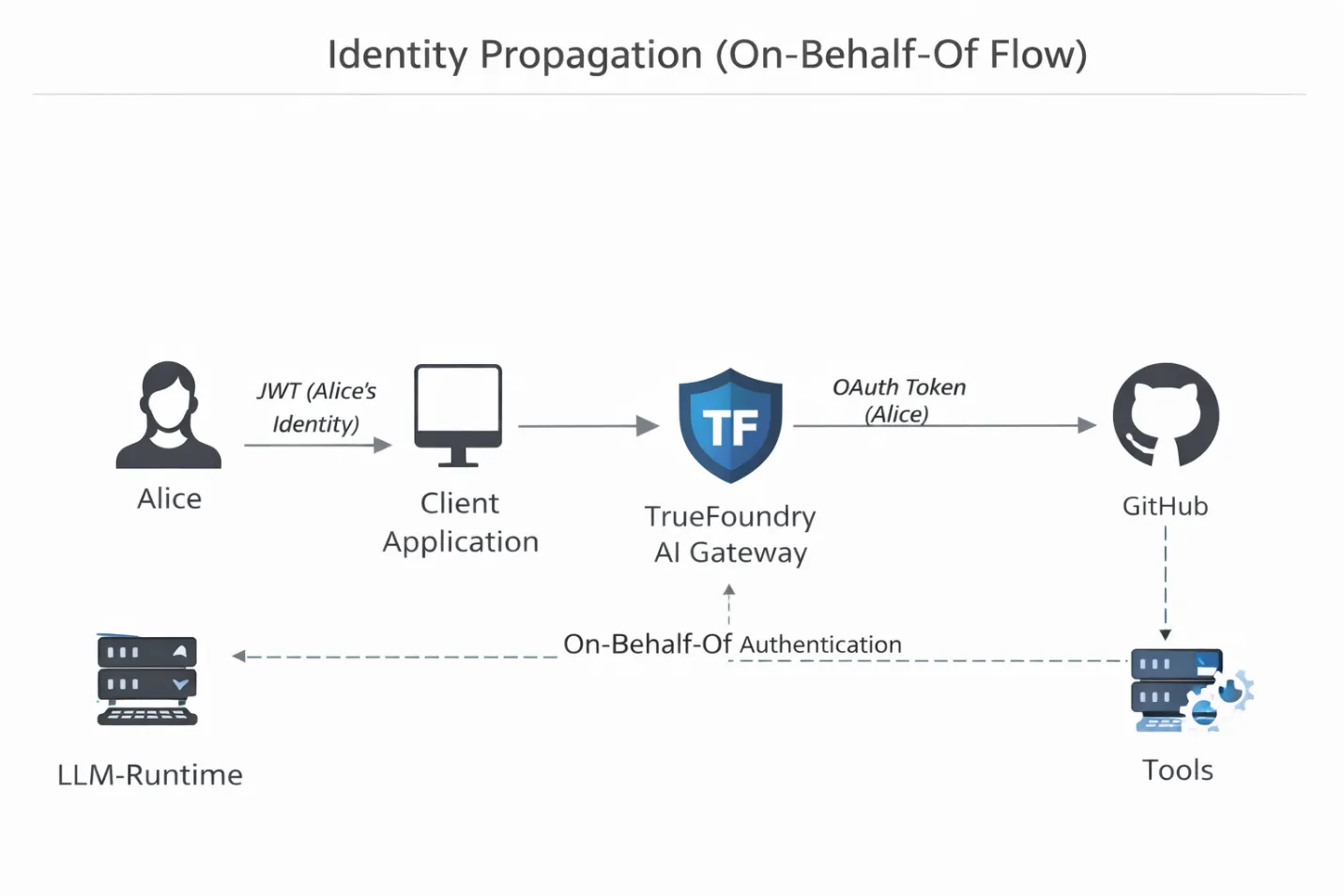
La mayoría de las pilas de agentes de bricolaje tienen el problema de la «clave genérica». Los agentes funcionan con un token de API compartido, por lo que cuando algo sale mal, lo único que ves en los registros es que «el agente lo hizo». No hay responsabilidad. La puerta de enlace de TrueFoundry inspecciona el JWT del cliente entrante, lo asigna al usuario humano autenticado e inyecta el OAuth o el token de servicio correcto en sentido descendente. Si Alice no puede eliminar un repositorio, tampoco puede hacerlo el agente que actúa en su nombre. La autoridad del agente ya no es teórica. Está encuadernado criptográficamente.
La puerta de enlace es donde los servidores MCP virtuales se hacen realidad. TrueFoundry mantiene las tablas de enrutamiento que asignan el alcance de un servidor virtual a los servidores MCP físicos y a las herramientas permitidas. Si un agente intenta llamar a algo fuera de su segmento declarado, la puerta de enlace devuelve un error JSON-RPC estructurado. El modelo no recibe un error silencioso. Obtiene una clara «herramienta no encontrada», que le ayuda a autocorregirse en lugar de alucinar.
Como la puerta de enlace termina la conexión, puede almacenar en búfer y rastrear el tráfico MCP. Esto permite inspeccionar las interacciones entre herramientas al estilo de PCAP. Cuando un agente se queda atrapado en un bucle o toma una mala decisión, puede reproducir la secuencia exacta de llamadas a la herramienta sin tener que volver a ejecutar los costosos pasos de inferencia que condujeron a la operación. La depuración pasa de las conjeturas a la inspección.
En conjunto, esta es la diferencia entre esperar que un agente se comporte y hacer cumplir que no puede portarse mal. El control de acceso pasa de las indicaciones a la infraestructura, que es donde pertenece.
Los servidores virtuales controlan qué herramientas puede ver un agente. Las barandillas controlan la forma en que se utilizan esas herramientas. Solo porque un agente es permitido llamar a sql_query no significa que deba permitirse ejecutar SELECT * FROM users y volcar toda la base de datos de clientes en su ventana de contexto.
Aquí es donde entran en juego las barandillas. En la arquitectura TrueFoundry, los guarraíles funcionan como un middleware que intercepta la carga útil de JSON-RPC en la capa de protocolo e inspecciona el tráfico antes de que se ejecute.
Barreras de entrada (el «WAF» para los agentes) Podemos escribir middleware de Python o reglas de expresiones regulares simples que validen los argumentos de la herramienta delante de la solicitud llega al contenedor de backend.
Barandas de salida (prevención de pérdida de datos) Los agentes son propensos a la «filtración detallada», ya que obtienen más datos de los que necesitan y los resumen.
En el software tradicional, si se produce un error en una llamada a la API, se comprueban los registros. Aparece un error interno del servidor 500 y un seguimiento de la pila.
En los sistemas de agentes, la palabra «fallo» es con frecuencia silenciosa. El agente llama a una herramienta, obtiene un resultado, pero lo malinterpreta. O llama a la herramienta con argumentos ligeramente incorrectos que técnicamente funcionan pero arrojan datos basura. Los registros de aplicación estándar muestran «200 de acuerdo», pero el resultado es incorrecto.
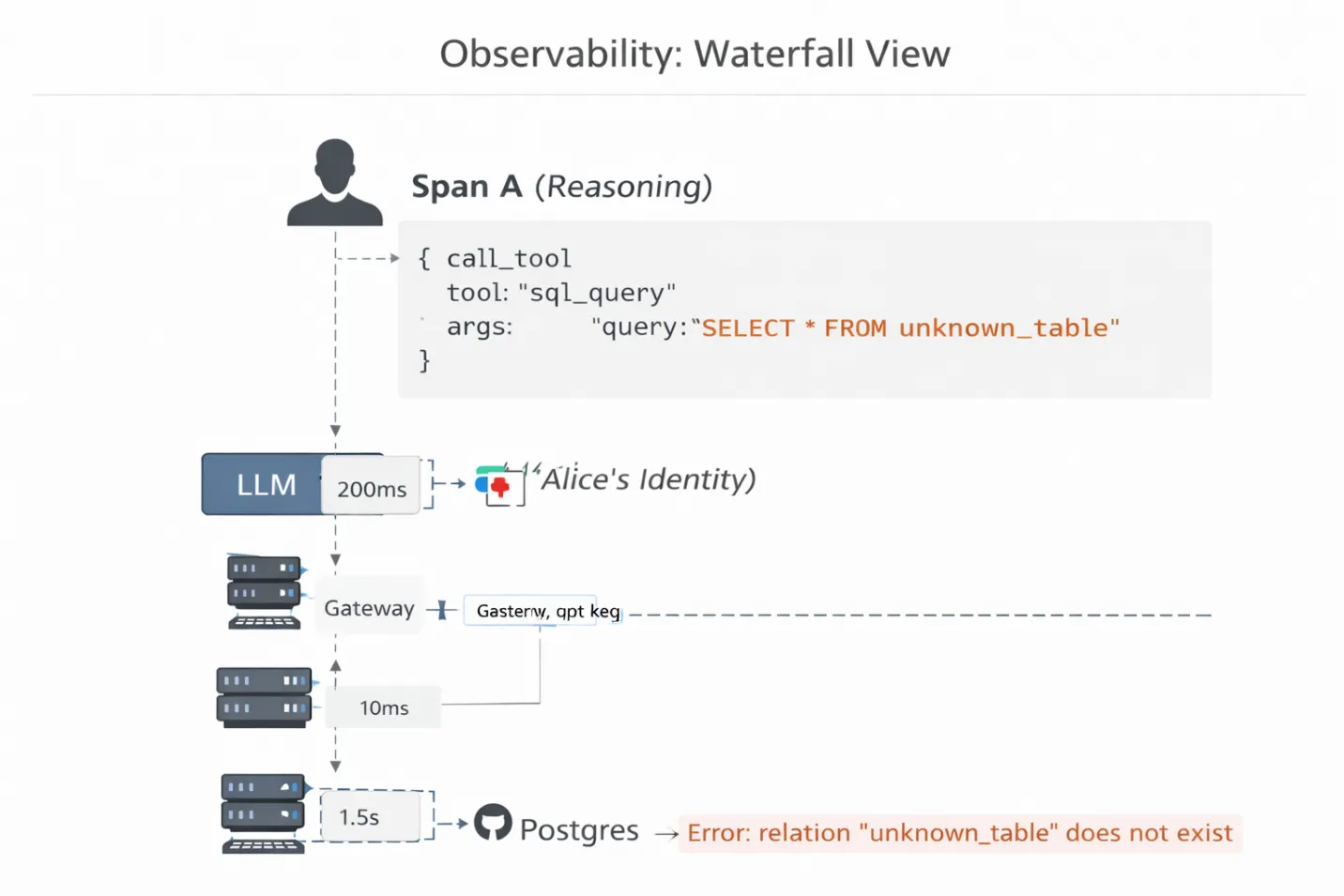
Para depurar esto, necesita Distributed Tracing for MCP.
TrueFoundry proporciona una visualización en cascada de la cadena de ejecución del agente. No aparece simplemente «Solicitud fallida». Puedes ver la latencia y la carga útil en cada salto:
Por qué esto es importante: Puede profundizar en el Span C y ver el exacto Consulta SQL que generó el agente. Es posible que te des cuenta de que el agente está haciendo alucinaciones con un nombre de tabla que no existe o que utiliza un parámetro de API obsoleto. Sin esta visibilidad a nivel de protocolo, estás depurando una caja negra adivinando.
La transición de «Chatbot» a «Agente» es, en efecto, la transición de «Generación de texto» a «Ejecución remota de código». Esa realidad es exactamente lo que mantiene a la mayoría de los pilotos empresariales concentrados en la fase de PoC.
TrueFoundry cierra esa brecha. Cuando implementas el patrón del servidor MCP virtual a través del AI Gateway, dejas de pedirle a tu equipo de seguridad que confíe en un modelo probabilístico y comienzas a mostrarles una arquitectura determinista. No solo está implementando una herramienta, sino que está implementando una interfaz específica que reconoce la identidad y que limita de forma inherente el radio de explosión.
Para las empresas, TrueFoundry no solo proporciona las «tuberías» para MCP, sino que también proporciona las válvulas, los manómetros y las cerraduras. Convierte a un temerario agente de «acceso raíz» en un empleado digital de confianza. No administraría un clúster de Kubernetes de producción sin RBAC; no debería ejecutar una pila de agentes empresariales sin TrueFoundry.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada






.png)

.webp)
.webp)
.webp)



.webp)
.webp)


