self_check_input and self_check_output rails inside a small wrapper service that you deploy on TrueFoundry. The gateway invokes the wrapper through its Custom Guardrail interface - there are no native NeMo SDK calls from the gateway and no client SDK changes in your applications.
Source repository:
truefoundry/integrations-custom-guardrails/integrations/nemo/. It contains the Dockerfile, deploy script, prompt templates, and tests referenced below.What is NVIDIA NeMo Guardrails?
NVIDIA NeMo Guardrails is an open-source toolkit for adding programmable safety rails to LLM applications. It uses a small judge LLM plus a domain-specific language (Colang) to evaluate inbound prompts and outbound responses against policies you define.Key Features of NeMo Guardrails on TrueFoundry
- Jailbreak and prompt-injection detection on inbound user messages via NeMo’s
self_check_inputrail. - Output safety review on the model response before it returns to the caller via
self_check_output. - Unified audit trail: NeMo’s rail-judge LLM calls are routed back through your TrueFoundry gateway, so guardrail token spend, latency, and user attribution appear in the same dashboards as your inference traffic.
- Customizable rail bundle: extend the rails using NeMo’s Colang DSL and YAML - add Llama Guard, hallucination detection, or topical rails by editing
config/in the wrapper repo and redeploying.
Architecture
The gateway dispatches the input rail call and the model call in parallel for low time-to-first-token. The wrapper extracts the user message, runs NeMo’sself_check_input flow (which calls a judge LLM through the same TrueFoundry gateway), and returns a verdict.
The wrapper always returns HTTP 200 and signals the policy decision in the JSON body:
{"verdict": true}- allow{"verdict": false, "message": "..."}- block
Prerequisites
Before integrating NeMo Guardrails with TrueFoundry, ensure you have:- A TrueFoundry workspace you can deploy services into.
- A TrueFoundry API key with access to the model you want NeMo’s rail judge to use.
openai-main/gpt-4o-miniworks well;openai-main/gpt-4oif you want stricter classification. - The model FQN you want to protect (e.g.
openai-main/gpt-4o-mini). - A cluster with a configured base host (visible at Integrations → Clusters → <cluster>).
Integration Steps
Configure environment variables
Copy
.env.example to .env and fill in the values. You will reference two TrueFoundry secrets that you create in the next step - get their FQNs from Platform → Secrets after creating them..env
Create two TrueFoundry secrets
Navigate to Platform → Secrets and create a Secret Group named
Copy each secret’s FQN and confirm the entries in
nemo-guardrails-tfy with two secrets:| Secret Name | Value |
|---|---|
tfy-api-key | A TFY API key the wrapper uses to call your gateway as the rail judge. |
wrapper-api-key | The same random string you put in .env as WRAPPER_API_KEY. |
.env (TFY_API_KEY_SECRET_FQN, WRAPPER_API_KEY_SECRET_FQN) match.Deploy the wrapper service
Install the TrueFoundry CLI, log in, and deploy:Verify the service is healthy:
Register the Custom Guardrail Config in TrueFoundry
Navigate to AI Gateway → Guardrails → + Add New Guardrails Group.
Save the group.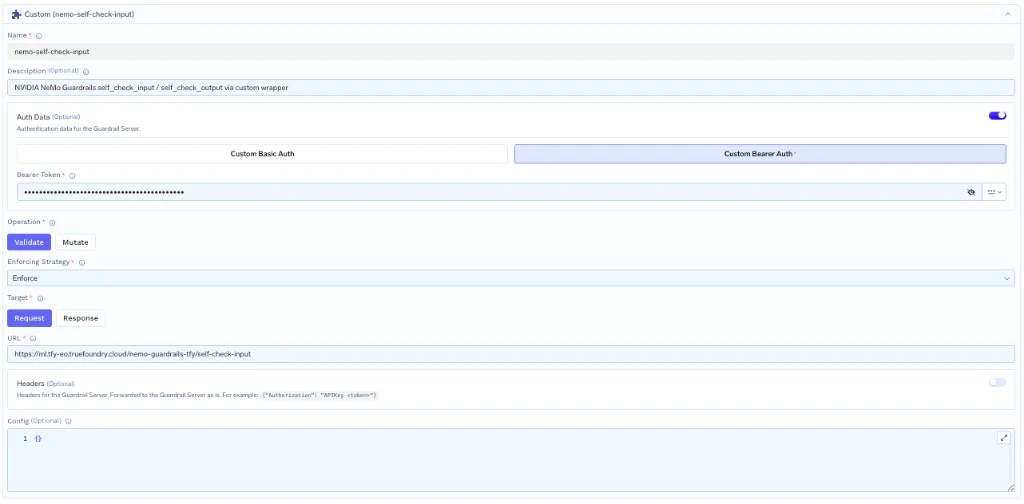
- Group name:
nemo-self-check - Description (optional):
NVIDIA NeMo Guardrails self_check_input / self_check_output - Click + Add Guardrail Config → Custom Guardrail Config twice - once for input, once for output.
- Input Guardrail
- Output Guardrail
| Field | Value |
|---|---|
| Name | nemo-self-check-input |
| Operation | Validate |
| URL | https://ml.<cluster>.truefoundry.cloud/nemo-guardrails-tfy/self-check-input |
| Auth Data | Custom Bearer Auth, token = the wrapper-api-key secret value |
| Headers | (empty) |
| Config | {} |
| Enforcing Strategy | Enforce But Ignore On Error (recommended) |
The wrapper signals rail decisions via
{"verdict": true \| false} on HTTP 200 - real failures (judge LLM unreachable, wrapper crash) come as HTTP 5xx. With Enforce But Ignore On Error, transient outages pass through while real policy decisions still block. Use Enforce for safety-critical rails where fail-closed is the right trade-off. See Custom guardrail response contract and Enforcing Strategy.Apply the guardrail to traffic
There are two ways to route requests through the rails - pick based on whether you want every call to a model protected, or per-call opt-in.
- Pin to a model (every call protected)
- Per-request opt-in
Navigate to AI Gateway → Models → <model> → Guardrails tab → attach the
nemo-self-check group → Save. Every caller of this model now passes through the rails.Customizing the Rail Bundle
The v1 bundle ships two rails. To add or change rails, edit files in the wrapper repo and redeploy.| File | Purpose |
|---|---|
config/config.yml | Registers which rails run on input and output. Default: self check input and self check output. |
config/prompts.yml | Prompts for the self-check flows. The few-shot examples in v1 explicitly catch DAN-style role-play, “ignore previous instructions”, system-prompt extraction, and policy-bypass markers. Tighten or relax to match your policy. |
config/rails/*.co | Optional Colang flows for custom rails beyond the built-in self-checks. See the NeMo Guardrails Colang docs. |
JUDGE_MODEL in .env and redeploy:
Troubleshooting
Blocks are returning 200 with the model's normal response
Blocks are returning 200 with the model's normal response
The wrapper signals rail decisions via
{"verdict": false} on HTTP 200. If the gateway returns a normal completion when the wrapper reported a block, your tenant gateway may not be honoring the verdict field. Two ways to confirm:- Check the wrapper pod logs while running the blocking test prompt. If you see
rail verdict=blockfromguardrail._nemo_runnerbut the gateway still returns a normal completion, the gateway isn’t honoring the verdict. - Call the wrapper directly to bypass the gateway (see the next accordion). If it returns
200 + {"verdict": false}, the wrapper is fine and the gateway is the issue.
Enforce. This maps the wrapper’s non-success state to a block. The trade-off is that transient wrapper outages will also block - accept it until your tenant gateway updates.The wrapper is being called but returns the wrong shape
The wrapper is being called but returns the wrong shape
Call Non-200 responses indicate real errors (judge LLM unreachable, NeMo init crash, missing bearer token).
/self-check-input and /self-check-output directly to bypass the gateway. The wrapper always returns HTTP 200 with:{"verdict": true, "message": null}→ pass{"verdict": false, "message": "<refusal text>"}→ block
I get 401s from the gateway calling the wrapper
I get 401s from the gateway calling the wrapper
The
Authorization: Bearer … value the gateway sends doesn’t match the wrapper’s WRAPPER_API_KEY env var. Three places must agree:- The TFY secret
wrapper-api-keyvalue. - The wrapper’s
WRAPPER_API_KEYenv var (resolved from the secret FQN at deploy time). - The Custom Guardrail Config’s Auth Data → Custom Bearer Auth field value.
The rail allows requests it should block
The rail allows requests it should block
The rail’s verdict is produced by the judge LLM. Check the wrapper’s pod logs:If you see
allow on a prompt that should block:- Try a stronger judge model:
JUDGE_MODEL=openai-main/gpt-4o. - Tighten the prompt in
config/prompts.yml- add a few-shot example matching the exact attack pattern that slipped through. - Redeploy with
python deploy.py --wait. The pod loadsRailsConfigonce at module import, so YAML changes only take effect after a fresh deploy.
Known Limitations
- No streaming-aware guardrails. The TrueFoundry custom-guardrail contract is buffered: the gateway holds the full response before calling the output rail. Streaming is supported end-to-end for the caller, but the output rail decision is made after the full response is generated.
- In-memory state is per-replica. The
/debug/loaded-configendpoint reflects the replica that served the curl. With multiple replicas, all should have identical config after a successful deploy. - Judge LLM cost. Every guarded request adds one or two LLM calls (one per direction). Watch
JUDGE_MODELtoken spend in your model usage dashboard. Using a smaller judge model (e.g.gpt-4o-minior a Haiku-class model) keeps this in check.
Reference
| Field | Value |
|---|---|
| Wrapper endpoint (input) | https://<host>/<path>/self-check-input |
| Wrapper endpoint (output) | https://<host>/<path>/self-check-output |
| Wrapper health endpoint | https://<host>/<path>/health |
| Wrapper debug endpoint | https://<host>/<path>/debug/loaded-config |
| Auth | Authorization: Bearer <WRAPPER_API_KEY> |
| Default selector format | nemo-self-check/nemo-self-check-input, nemo-self-check/nemo-self-check-output |
| Response contract | HTTP 200 + {"verdict": bool, "message": Optional[str]} |
| Repo | truefoundry/integrations-custom-guardrails/integrations/nemo/ |
| Upstream toolkit | NVIDIA/NeMo-Guardrails |