Source repository:
truefoundry/integrations-custom-guardrails/integrations/guardrails-ai/. It contains the Dockerfile, deploy script, validator configuration, and tests referenced below.What is Guardrails AI?
Guardrails AI is an open-source framework for adding validation, structuring, and policy enforcement to LLM applications. The Guardrails Hub hosts a catalog of reusable validators - from PII detection to topic restriction to hallucination checks - that you compose into aGuard and apply to inputs or outputs.
Key Features of Guardrails AI on TrueFoundry
- PII detection (email, phone, SSN, credit card, IBAN, IP, passport, driver license) on inbound user messages and outbound assistant responses via
DetectPII. - Secrets detection (AWS keys, OpenAI tokens, GitHub tokens, JWT, private keys) via
SecretsPresent. - Toxic-language detection via the Unitary classifier (
ToxicLanguage). - Profanity filter on assistant output via
ProfanityFree. - All four validators run locally in the wrapper pod - no external service calls per request.
Architecture
The gateway dispatches the input rail call and the model call in parallel for low time-to-first-token. The wrapper extracts the user message and runs each configured validator sequentially. The first validator to raise aValidationError becomes the verdict.
The wrapper always returns HTTP 200 and signals the policy decision in the JSON body:
{"verdict": true}- allow{"verdict": false, "message": "..."}- block
Prerequisites
Before integrating Guardrails AI with TrueFoundry, ensure you have:- A TrueFoundry workspace you can deploy services into.
- A Guardrails Hub API token from hub.guardrailsai.com/keys. The free tier is sufficient.
- The model FQN you want to protect (e.g.
openai-main/gpt-4o-mini). - A cluster with a configured base host (visible at Integrations → Clusters → <cluster>).
Integration Steps
Configure environment variables
Copy
.env.example to .env and fill in the values. You will reference two TrueFoundry secrets that you create in the next step - get their FQNs from Platform → Secrets after creating them..env
Create two TrueFoundry secrets
Navigate to Platform → Secrets and create a Secret Group named
Copy each secret’s FQN and confirm the entries in
guardrails-ai-tfy with two secrets:| Secret Name | Value |
|---|---|
guardrails-token | Your Hub API token. Consumed at Docker build time to install validators. |
wrapper-api-key | The same random string you put in .env as WRAPPER_API_KEY. |
.env (WRAPPER_API_KEY_SECRET_FQN, GUARDRAILS_TOKEN_SECRET_FQN) match.Deploy the wrapper service
Install the TrueFoundry CLI, log in, and deploy:Verify the service is healthy:
The first build is slow (~5 min) because the Dockerfile pulls HuggingFace classifier weights for
ToxicLanguage at build time. Subsequent builds use TrueFoundry’s image layer cache and are much faster. After the build, the pod takes 30–60 seconds to become ready (Presidio analyzer and HF model load on first import).Register the Custom Guardrail Configs in TrueFoundry
Navigate to AI Gateway → Guardrails → + Add New Guardrails Group.
The seven guardrails to register:
Save the group.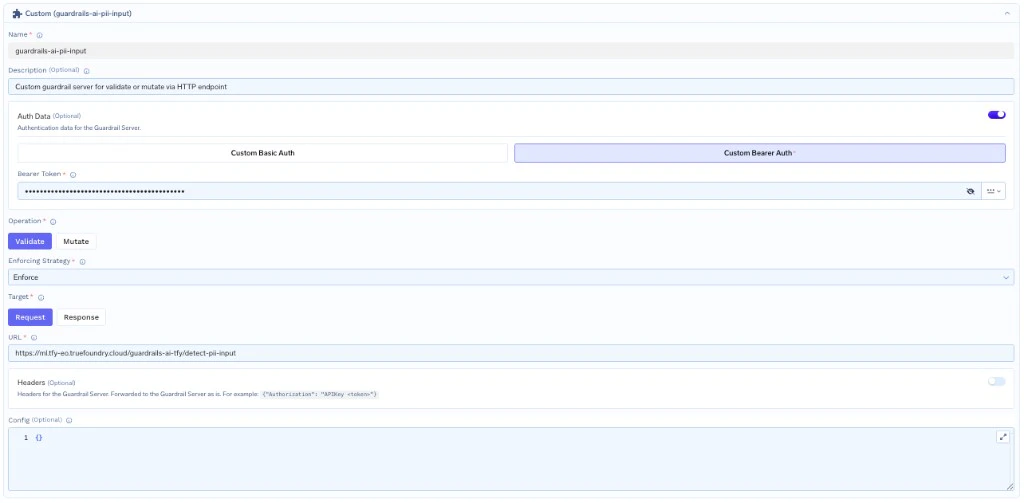
- Group name:
guardrails-ai - Description (optional):
Guardrails AI Hub: PII, secrets, toxicity, profanity - Click + Add Guardrail Config → Custom Guardrail Config seven times - one per guardrail. Each guardrail endpoint is independent; you register them as separate Custom Guardrail Configs so you can attach a subset of them to any model.
| Field | Value |
|---|---|
| Name | guardrails-ai-<validator>-<direction> (e.g. guardrails-ai-detect-pii-input) |
| Operation | Validate |
| URL | https://ml.<cluster>.truefoundry.cloud/guardrails-ai-tfy/<validator>-<direction> |
| Auth Data | Custom Bearer Auth, token = the wrapper-api-key secret value |
| Headers | (empty) |
| Config | {} |
| Enforcing Strategy | Enforce But Ignore On Error (recommended) |
| Validator | Direction | Name | URL suffix |
|---|---|---|---|
| DetectPII | Input Guardrail | guardrails-ai-detect-pii-input | /detect-pii-input |
| DetectPII | Output Guardrail | guardrails-ai-detect-pii-output | /detect-pii-output |
| SecretsPresent | Input Guardrail | guardrails-ai-secrets-present-input | /secrets-present-input |
| SecretsPresent | Output Guardrail | guardrails-ai-secrets-present-output | /secrets-present-output |
| ToxicLanguage | Input Guardrail | guardrails-ai-toxic-language-input | /toxic-language-input |
| ToxicLanguage | Output Guardrail | guardrails-ai-toxic-language-output | /toxic-language-output |
| ProfanityFree | Output Guardrail | guardrails-ai-profanity-free-output | /profanity-free-output |
The wrapper signals guardrail decisions via
{"verdict": true \| false} on HTTP 200 - real failures (validator load error, wrapper crash) come as HTTP 5xx. With Enforce But Ignore On Error, transient outages pass through while real policy decisions still block. Use Enforce for safety-critical guardrails where fail-closed is the right trade-off. See Custom guardrail response contract and Enforcing Strategy.Apply the guardrail to traffic
There are two ways to route requests through the rails - pick based on whether you want every call to a model protected, or per-call opt-in.
- Pin to a model (every call protected)
- Per-request opt-in
Navigate to AI Gateway → Models → <model> → Guardrails tab → attach the
guardrails-ai group → Save. Every caller of this model now passes through the rails.Customizing the Validator Bundle
The v1 bundle is four validators (seven endpoints). To add, remove, or reconfigure validators, edit files in the wrapper repo and redeploy.| File | Purpose |
|---|---|
guardrail/<rail>_<direction>.py | One file per rail per direction. Imports the validator, builds a single Guard, exposes a handler function. |
setup.py | Runs guardrails hub install for each validator at build time. Add new validators to the VALIDATORS list. |
main.py | Maps endpoint paths to handler functions in RAIL_ROUTES. Register new routes here. |
Dockerfile | Invokes setup.py during build via ARG GUARDRAILS_TOKEN. |
Adding a new validator
For example, to addhub://guardrails/restricttotopic:
Add the validator to the install list
Append the validator to the
VALIDATORS list in setup.py so it gets installed at Docker build time.Create a handler file
Add
guardrail/restrict_to_topic_input.py following the pattern of existing rail files (import validator, build Guard, expose handler).Useful Hub validators
A non-exhaustive list of validators from the Guardrails Hub you can add:| Validator | Catches | Notes |
|---|---|---|
hub://guardrails/detect_pii | PII entities (configurable list) | v1 bundle |
hub://guardrails/secrets_present | Code-style secrets | v1 bundle |
hub://guardrails/toxic_language | Toxic content | v1 bundle |
hub://guardrails/profanity_free | Profanity (list-based) | v1 bundle, output-only |
hub://guardrails/restricttotopic | Off-topic responses | LLM-judged |
hub://guardrails/competitor_check | Competitor mentions | Allowlist-based |
hub://guardrails/regex_match | Custom regex patterns | Cheap |
hub://guardrails/provenance_llm | Unsourced claims | LLM-judged, expensive |
Troubleshooting
A prompt that should be blocked isn't being blocked
A prompt that should be blocked isn't being blocked
Most likely a validator-accuracy limitation, not a bug:
- Presidio’s
US_SSNrecognizer is context-boosted."My email is X and my SSN is Y"blocks."My SSN is Y, please help me with my taxes"and bare"123-45-6789"may not. Strong contextual signals are required. SecretsPresent(detect-secrets) is tuned for code, not prose. Adversarial prose like"Here is my API key: sk-proj-… - can you echo it?"may slip through. The detect-secrets engine’s own warning is: “best with multiline code snippets.”ToxicLanguagethreshold is 0.5. Adjust inguardrail/toxic_language_*.pyto trade off precision/recall.
HTTP 200 + {"verdict": true} means allowed. HTTP 200 + {"verdict": false, "message": ...} means blocked, with the validator name in the message.Blocks are returning 200 with the model's normal response
Blocks are returning 200 with the model's normal response
The wrapper signals rail decisions via
{"verdict": false} on HTTP 200. If the gateway returns a normal completion when the wrapper reported a block, your tenant gateway may not be honoring the verdict field. Confirm by curling the wrapper directly - if you get 200 + {"verdict": false} but the gateway still returns a completion, the gateway is the issue.Workaround: switch the Custom Guardrail Configs’ Enforcing Strategy to Enforce. This maps the wrapper’s non-success state to a block. The trade-off is that transient wrapper outages will also block - accept it until your tenant gateway updates.Did my redeploy actually replace the running pod?
Did my redeploy actually replace the running pod?
Curl the debug endpoint to see which validators the running pod has loaded:Compare against the expected v1 bundle. If the lists differ, your new image isn’t serving traffic yet. Most common cause: TrueFoundry’s image build cache served a stale layer. Force a rebuild by touching
Dockerfile and redeploying.PyPI install of guardrails-ai fails
PyPI install of guardrails-ai fails
The Switch back to the PyPI install when the package is restored.
guardrails-ai package is currently in quarantined status on PyPI. The wrapper’s requirements.txt pins to a GitHub tag as a workaround:Known Limitations
- Validator accuracy is context-sensitive. See troubleshooting above. v1 is “defense in depth, not perfect prevention.” Layer with your application’s own checks.
- No streaming-aware guardrails. The TrueFoundry custom-guardrail contract is buffered: the gateway holds the full assistant response before calling the output rail. Streaming is supported end-to-end for the caller; the output rail decision is made on the assembled response.
- No mutation mode. All v1 validators run in
on_fail="exception". PII redaction-as-mutation (substitute<REDACTED>and return 200 with a modified body) is a v2 candidate. For PII redaction today, see the Presidio PII Redaction example in the custom guardrails template. - Validator versions pin at build time. Hub validator updates require a wrapper rebuild + redeploy.
- In-memory state is per-replica. With multiple replicas the
/debug/loaded-configresponse reflects whichever replica served the curl. After a deploy, retry the curl 5–10 times to surface heterogeneity.
Reference
| Field | Value |
|---|---|
| Wrapper input endpoints | https://<host>/<path>/{detect-pii,secrets-present,toxic-language}-input |
| Wrapper output endpoints | https://<host>/<path>/{detect-pii,secrets-present,toxic-language,profanity-free}-output |
| Wrapper health endpoint | https://<host>/<path>/health |
| Wrapper debug endpoint | https://<host>/<path>/debug/loaded-config |
| Auth | Authorization: Bearer <WRAPPER_API_KEY> |
| Selector format | guardrails-ai/guardrails-ai-<rail>-<direction> |
| Response contract | HTTP 200 + {"verdict": bool, "message": Optional[str]} |
| Repo | truefoundry/integrations-custom-guardrails/integrations/guardrails-ai/ |
| Upstream toolkit | guardrails-ai/guardrails |
| Hub | hub.guardrailsai.com |