











Erstellen, Bereitstellen und Skala GenAI in Produktion


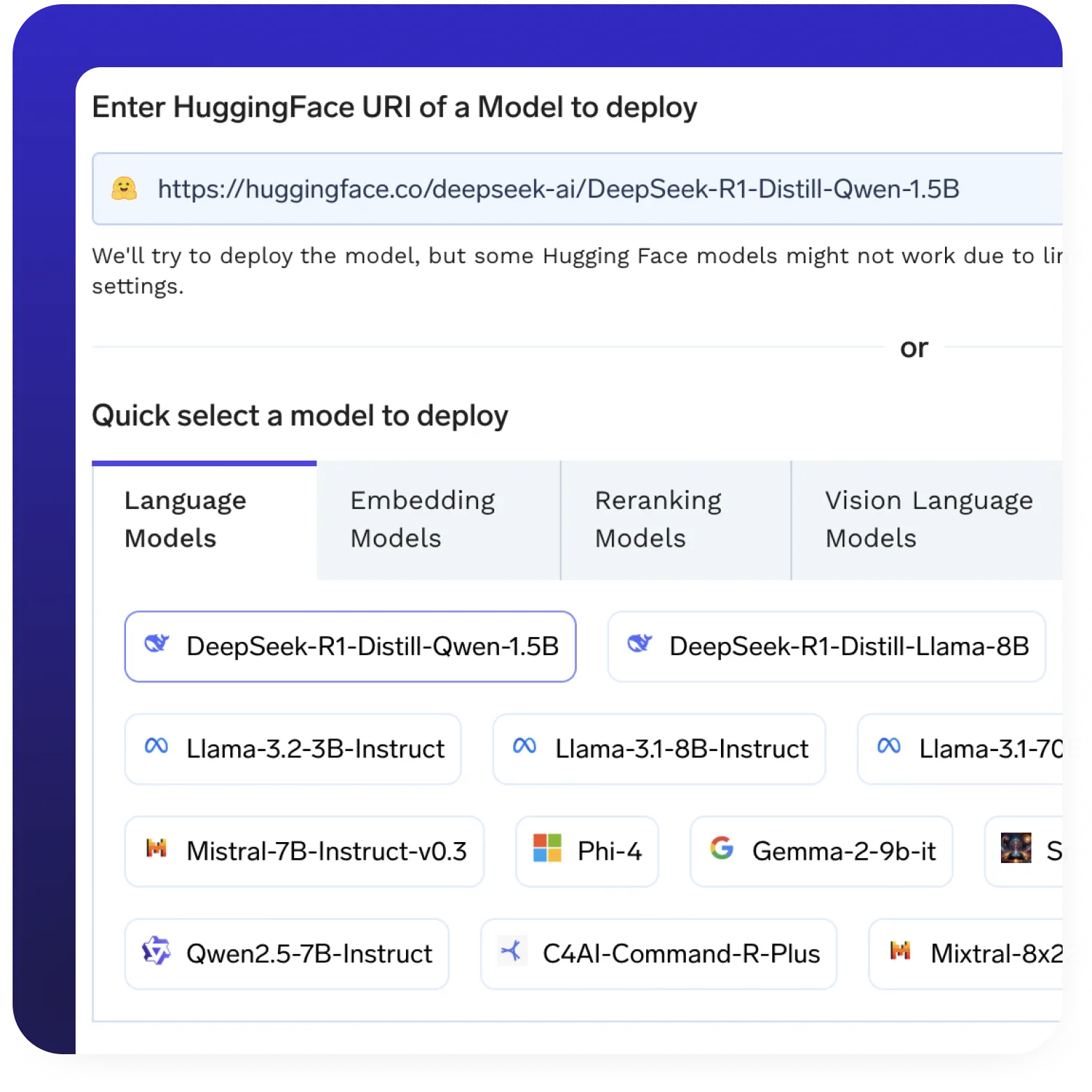
Modellbereitstellung und Inferenz
- Mühelos Stellen Sie jedes Open-Source-LLM bereit mit vorkonfigurierten Optimierungen.
- Stellen Sie mühelos eine Verbindung zu Hugging Face oder Ihrer bevorzugten Modelregistrierung her.
- Nutzen Sie erstklassige Modellserver wie vLLM und sGLang für leistungsstarke Inferenz.
- Automatische Skalierung und intelligente Infrastrukturbereitstellung
Probiere es jetzt
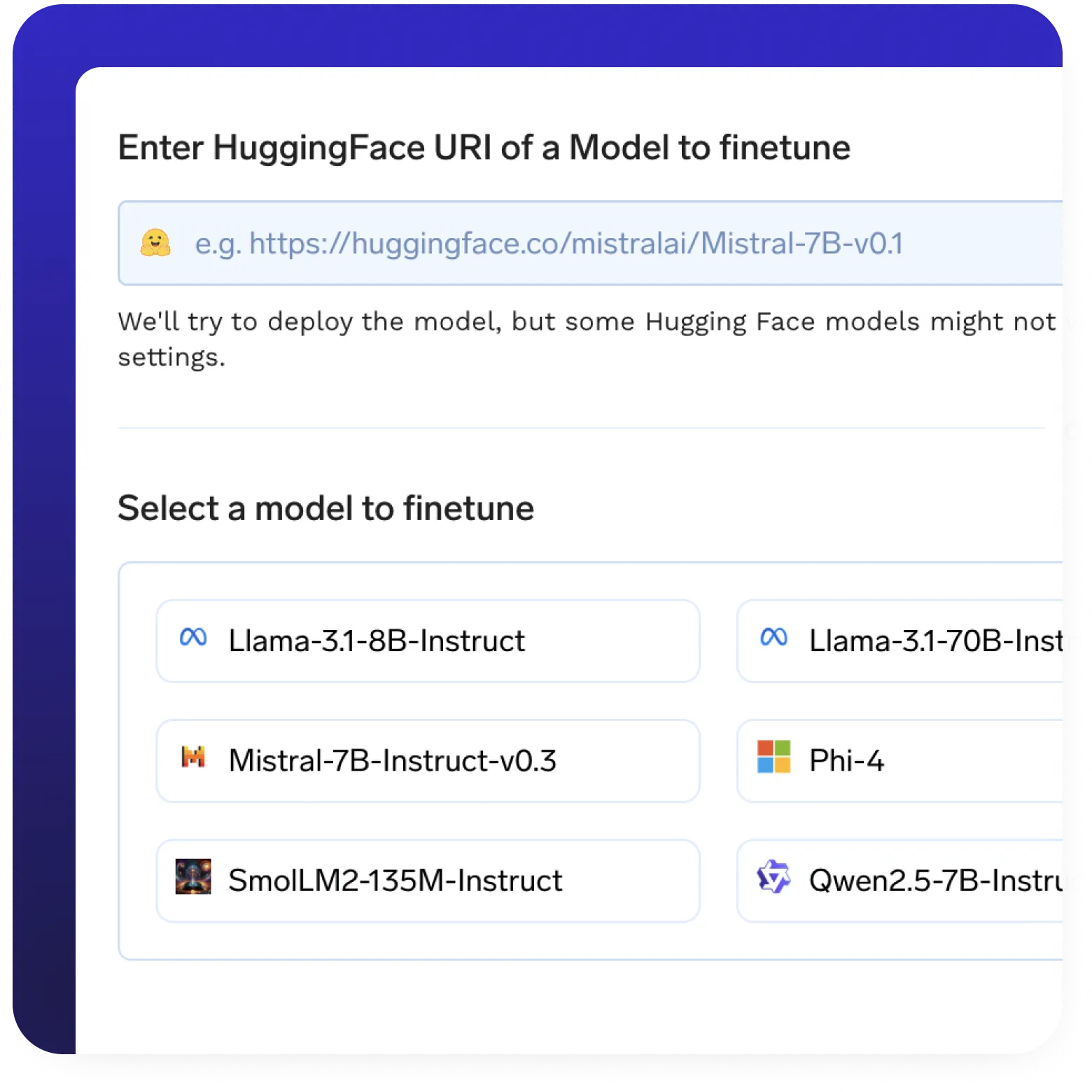
Modell-Finetuning
- Unterstützung für die Feinabstimmung ohne Code und mit vollem Code für benutzerdefinierte Datensätze.
- LoRa und QLora für eine effiziente Low-Rank-Anpassung.
- Checkpointing Unterstützung für eine reibungslose Wiederaufnahme des Trainings.
- Bereitstellung fein abgestimmter Modelle mit einem Klick mit erstklassigen Modellservern.
- Automatisierte Trainingspipelines mit integriertem Verfolgen von Experimenten.
- Verteilte Trainingsunterstützung für eine schnellere, groß angelegte Modelloptimierung.
Probiere es jetzt
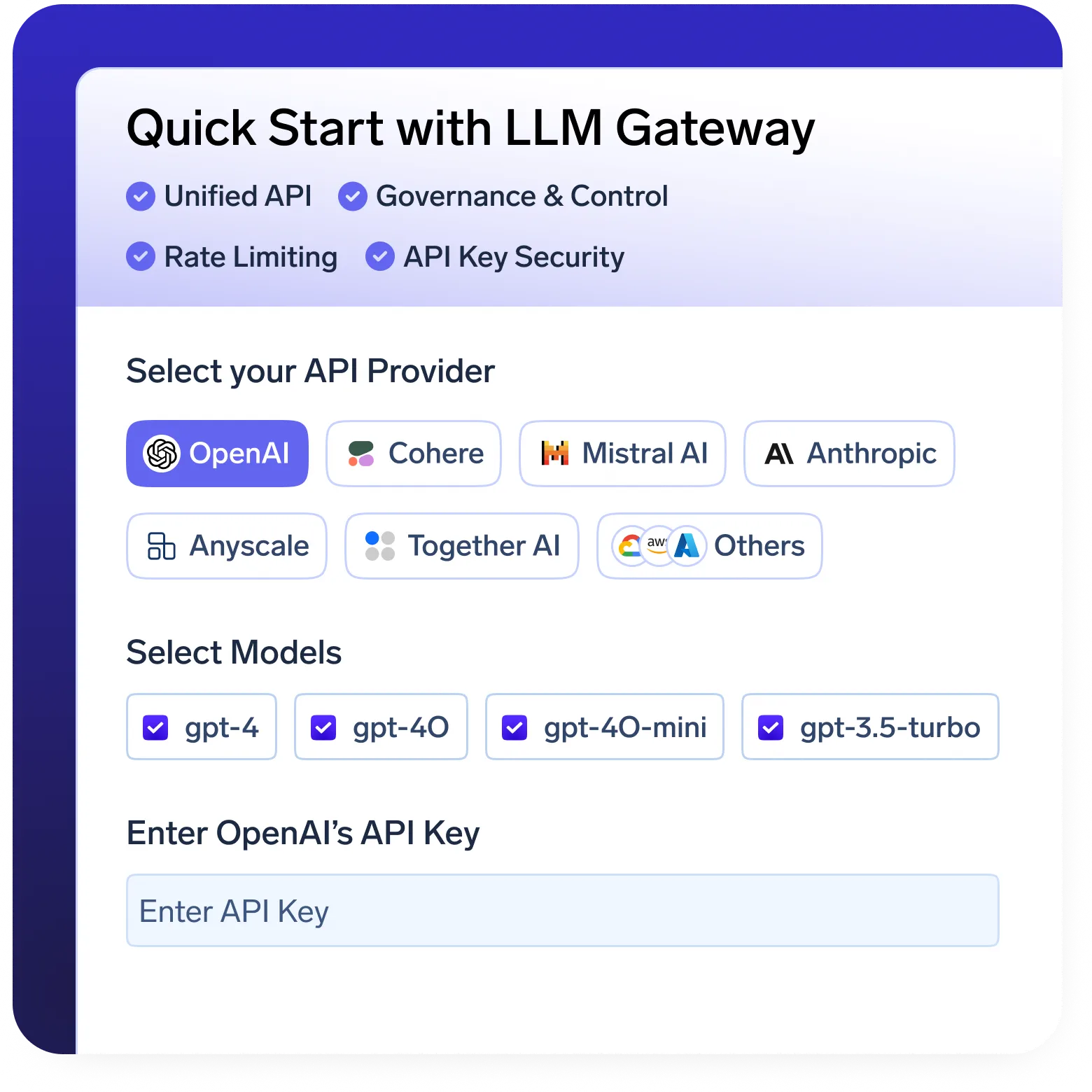
KI-Gateway
- Einheitliche API-Ebene zur Bereitstellung und Verwaltung von Modellen in OpenAI, Llama, Gemini usw.
- Integrierte Ratenbegrenzung und Zugriffskontrolle zur sicheren Verwaltung der Nutzung.
- Nutzungs- und Kostenmetriken in Echtzeit für eine bessere Überwachung und Optimierung.
- Fallback und automatische Wiederholungsversuche sorgen für hohe Verfügbarkeit und Zuverlässigkeit.
Probiere es jetzt
Prompte Verwaltung
- Experimentieren und iterieren Sie anhand von Eingabeaufforderungen mit einem strukturierten Test-Framework
- Versionskontrolliertes Prompt-Engineering
Probiere es jetzt


Spurensuche und Leitplanken
- Erfassen und analysieren Sie jede Aufforderung, Antwort und Token-Nutzung, um Transparenz und Rückverfolgbarkeit zu gewährleisten.
- Protokollieren Sie Latenz, Abschlussraten und API-Aufrufe, um die Modellleistung zu optimieren.
- Integrieren Sie benutzerdefinierte Leitplanken oder externe Tools für die Erkennung von personenbezogenen Daten, die Moderation von Inhalten usw.
Probiere es jetzt
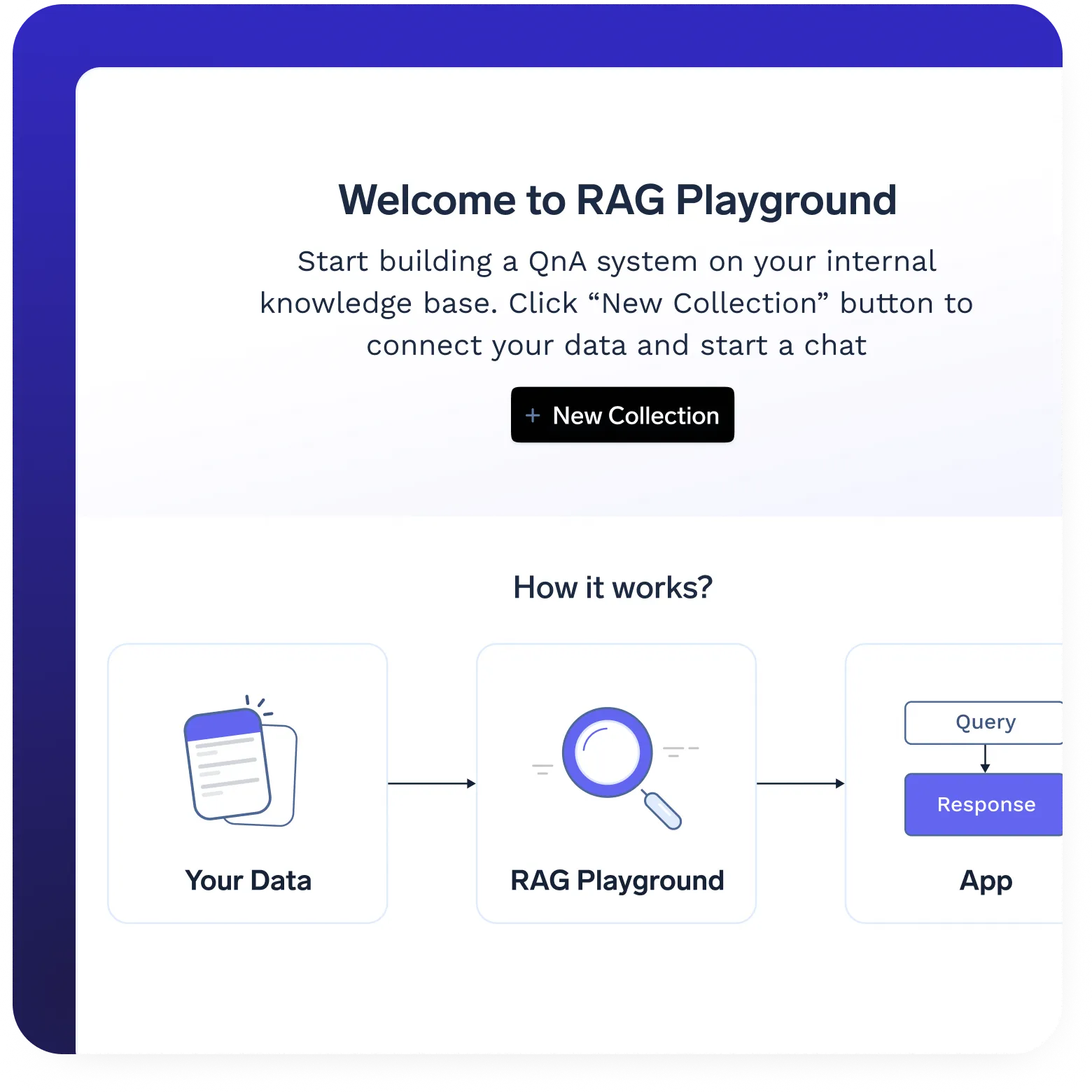
RAG-Bereitstellung mit einem Klick
- Stellt alle RAG-Komponenten mit einem einzigen Klick bereit, einschließlich VectorDB, Einbettungsmodelle, Frontend und Backend.
- Konfigurierbare Infrastruktur zur Optimierung der Speicherung, des Abrufs und der Abfrageverarbeitung.
- Skalierbare Architektur zur Unterstützung dynamischer und wachsender Wissensdatenbanken.
Probiere es jetzt

Stellen Sie ein beliebiges Agent-Framework bereit
- Implementieren und verwalten Sie KI-Agenten in mehreren Frameworks, darunter LangChain, AutoGen, CrewAI und maßgeschneiderte Agenten.
- Framework-unabhängige Bereitstellung, die die Kompatibilität mit jeder agentenbasierten Architektur gewährleistet.
- Unterstützung für die Zusammenarbeit mehrerer Agenten, sodass Agenten interagieren, Kontext austauschen und Aufgaben autonom ausführen können.
Probiere es jetzt
Bereit für Unternehmen
Ihre Daten und Modelle sind sicher in Ihrer Cloud-/On-Prem-Infrastruktur untergebracht.

Vollständig modulare Systeme
Integriert und ergänzt Ihren bestehenden StackEchte Konformität
SOC 2-, HIPAA- und DSGVO-Standards zur Gewährleistung eines robusten DatenschutzesVon vornweg sicher
Flexible rollenbasierte Zugriffskontrolle und Audit-TrailsAuthentifizierung nach Industriestandard
SSO-Integration über OIDC oder SAML
Unterstützt von erstklassigen Investoren

.webp)
.webp)


Testimonials TrueFoundry macht Ihr ML-Team 10x schneller
.webp)
Deepanshi S
Leitender Datenwissenschaftler
TrueFoundry vereinfacht die Bereitstellung komplexer ML-Modelle mit einer benutzerfreundlichen Benutzeroberfläche und befreit Datenwissenschaftler von Infrastrukturproblemen. Es verbessert die Effizienz, optimiert die Kosten und löst mühelos DevOps-Herausforderungen, was für uns von unschätzbarem Wert ist.



Matthieu Perrinel
Leiter ML
Die Einsparungen bei den Computerkosten, die wir durch die Einführung von TrueFoundry erzielt haben, waren höher als die Kosten für den Service (und das ohne die Zeit und die Kopfschmerzen zu berücksichtigen, die uns das erspart).


Soma Dhavala
Direktor für maschinelles Lernen
TrueFoundry hat uns geholfen, 40-50% der Cloud-Kosten einzusparen. Die meisten Unternehmen geben Ihnen ein Tool und verlassen Sie, aber TrueFoundry hat uns hervorragend unterstützt, wann immer wir es brauchten.


Rajesh Chaganti
CTO
Mithilfe der TrueFoundry-Plattform konnten wir unsere Cloud-Kosten erheblich senken. Wir konnten innerhalb weniger Wochen nahtlos von einem AMI-basierten System auf eine Docker-Kubernetes-basierte Architektur umsteigen.


Summit Rao
AVP für Datenwissenschaft
TrueFoundry war in unseren Anwendungsfällen für maschinelles Lernen von entscheidender Bedeutung. Sie haben unserem Team geholfen, den Wert des maschinellen Lernens schneller zu nutzen.


Vivek Suyambu
Leitender Softwareingenieur
TrueFoundry macht die Open-Source-LLM-Bereitstellung und Feinabstimmung mühelos. Die intuitive Plattform, die mit einem funktionsreichen Dashboard für das Modellmanagement angereichert ist, wird durch ein Support-Team ergänzt, das sich ins Zeug legt.

9,9
Qualität des Supports


GenAI infra- einfach, schneller, günstiger
Mehr als 30 Unternehmen und Fortune-500-Unternehmen vertrauen darauf








