


Unternehmenstaugliches KI-Gateway und Agentic Deployment Platform — sicher, skalierbar, gesteuert.
Lokal, VPC, Hybrid oder Public Cloud


Steuern, implementieren, skalieren und verfolgen Sie agentische KI auf einer einheitlichen Plattform
.svg)
%201%20(1).avif)
Orchestrieren Sie Agentic AI mit AI Gateway
Ermöglichen Sie intelligentes mehrstufiges Denken, Werkzeugnutzung und Gedächtnis mit voller Kontrolle und Transparenz über Ihre KI-Agenten und Workflows.
KI-Gateway
Managen Sie den Agentenspeicher, die Tool-Orchestrierung und die Aktionsplanung über ein zentralisiertes Protokoll, das komplexe, kontextsensitive Workflows unterstützt.

MCP- und Agentenregister
Pflegen Sie eine strukturierte, auffindbare Registrierung von Tools und APIs, auf die Agenten zugreifen können, einschließlich Schemavalidierung und Zugriffskontrolle.
.webp)
Schnelles Lebenszyklusmanagement
Versionieren, verwalten und überwachen Sie Eingabeaufforderungen, um ein qualitativ hochwertiges, wiederholbares Verhalten aller Agenten und Anwendungsfälle sicherzustellen.
Bereitstellung und Skalierung beliebiger agentischer KI-Workloads
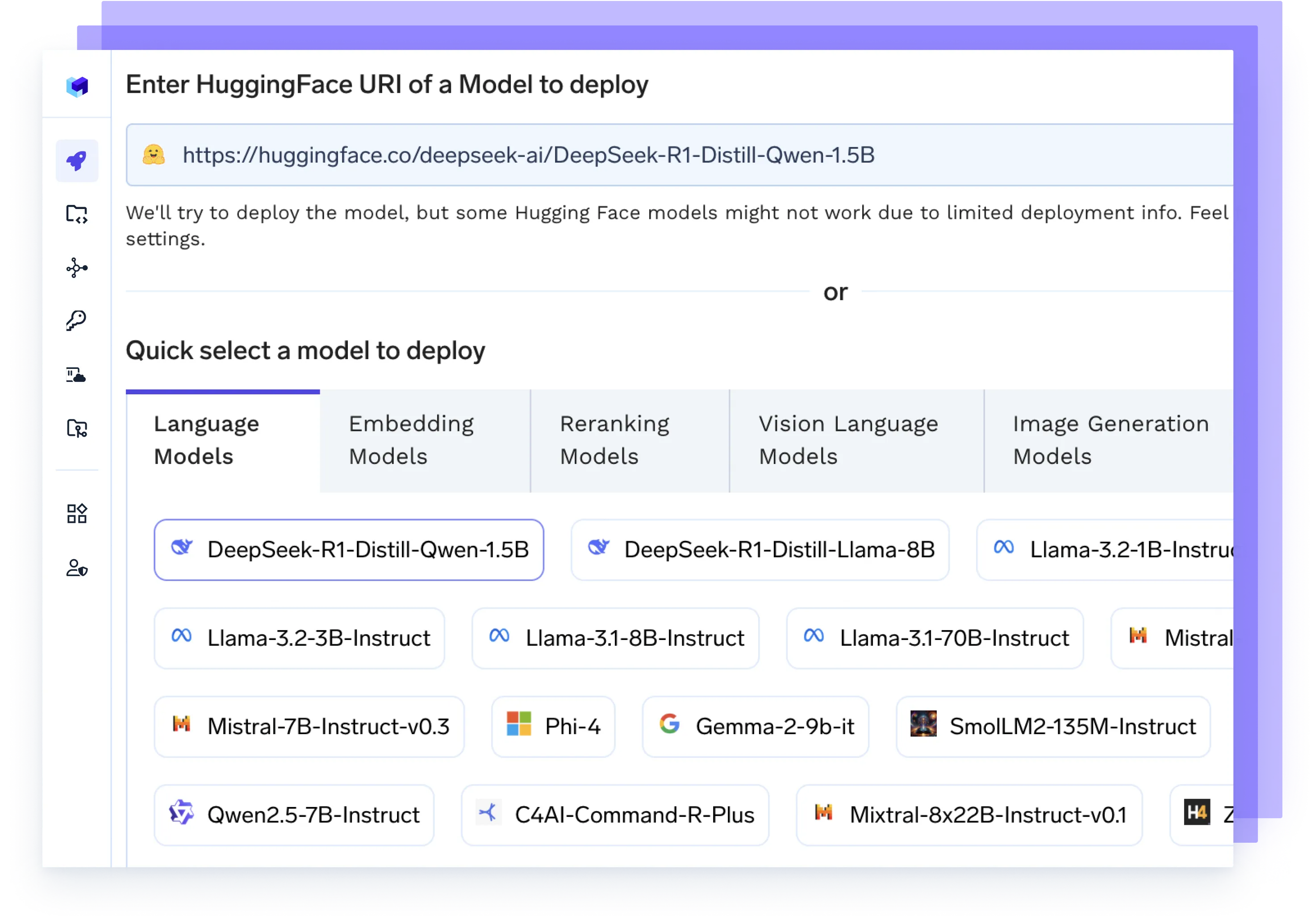
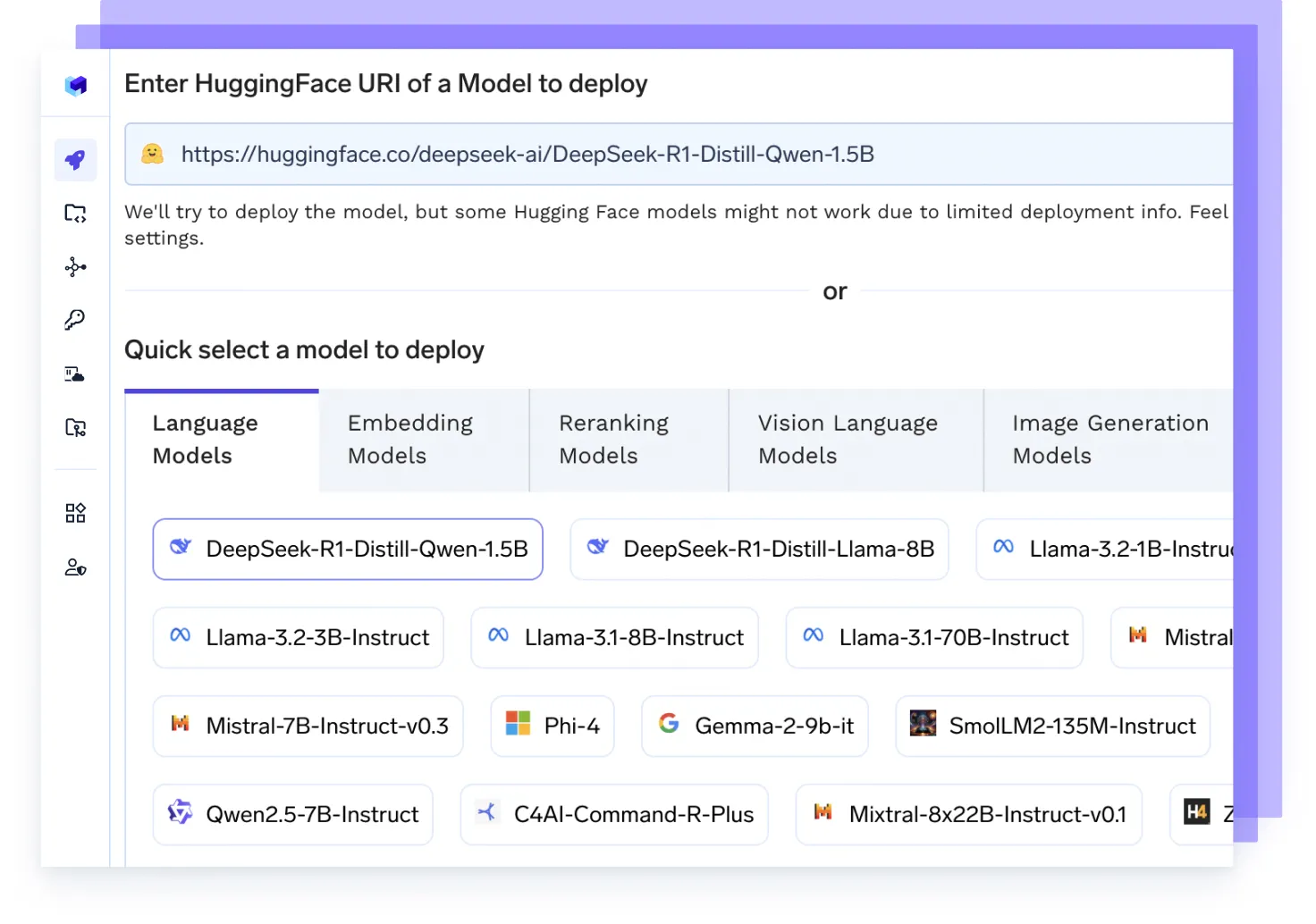
Hosten Sie ein beliebiges KI-Modell
Führen Sie jedes LLM-, Einbettungsmodell oder benutzerdefinierte Modelle mit leistungsstarken Backends wie vLLM, TGI oder Triton aus — optimiert für Geschwindigkeit und Skalierung.
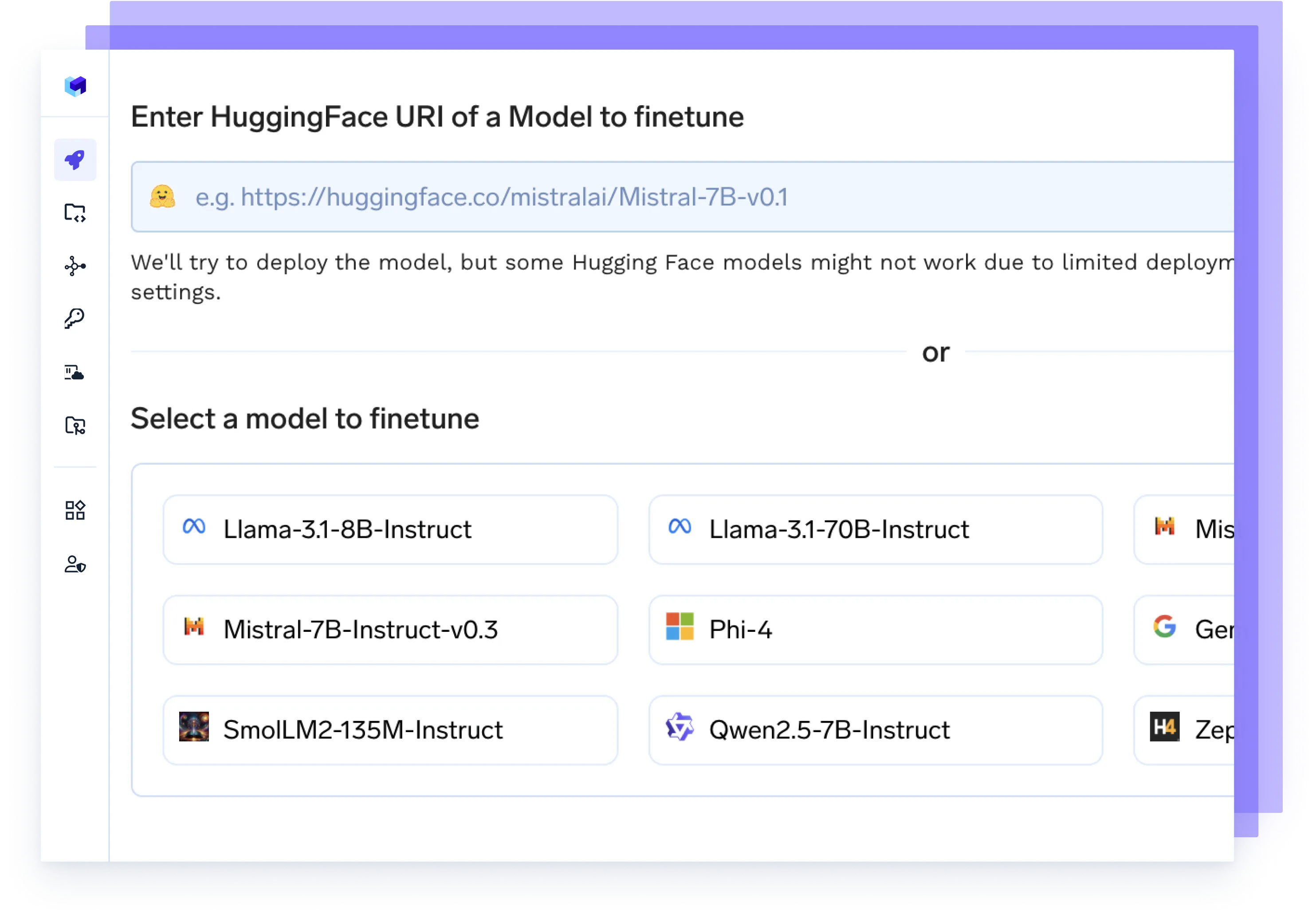
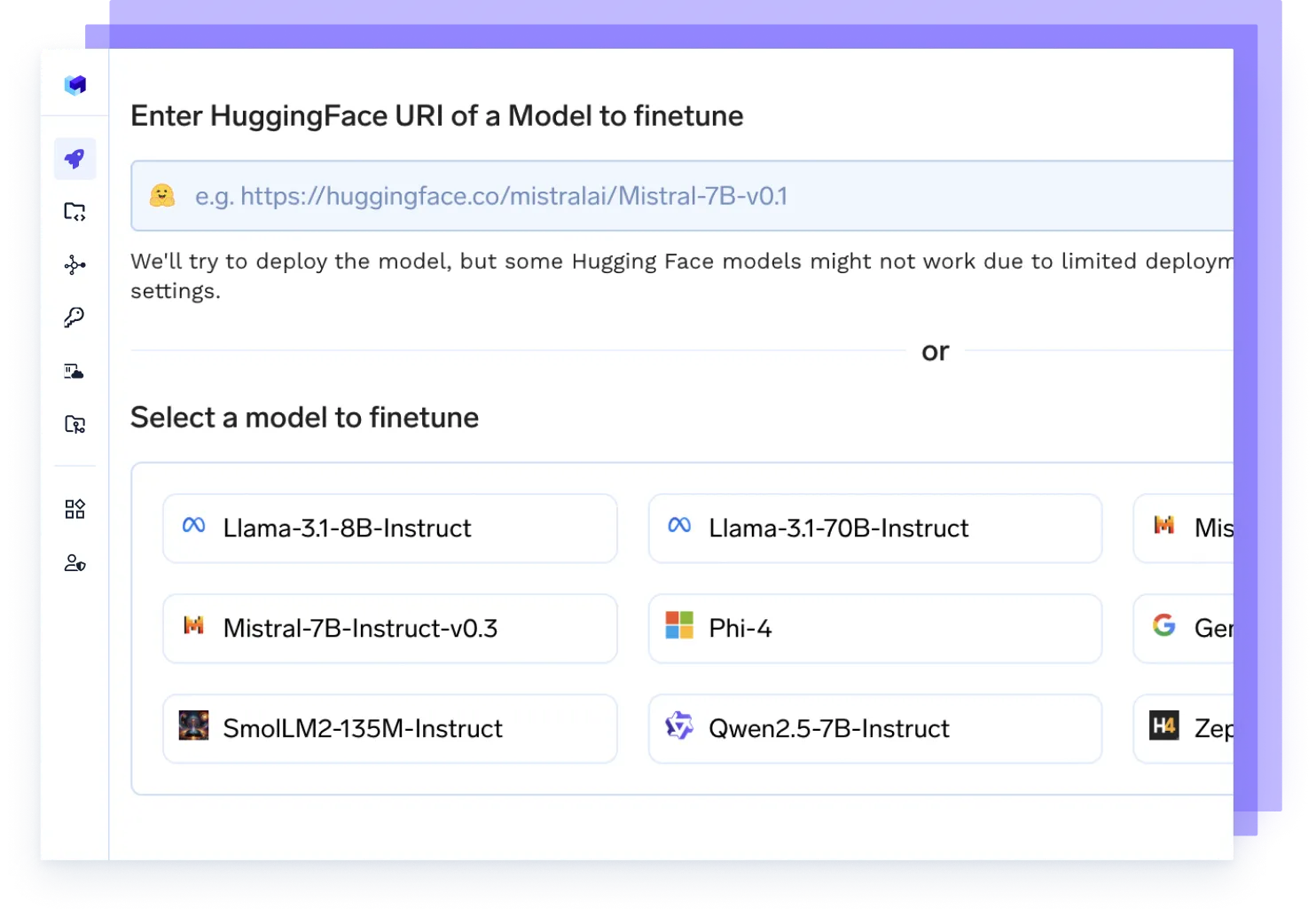
Finetune jedes Modell
Starten Sie Feinabstimmungsaufträge an Ihren Daten, verfolgen Sie Experimente und stellen Sie aktualisierte Checkpoints direkt in der Produktion bereit — alles in einem Arbeitsablauf.
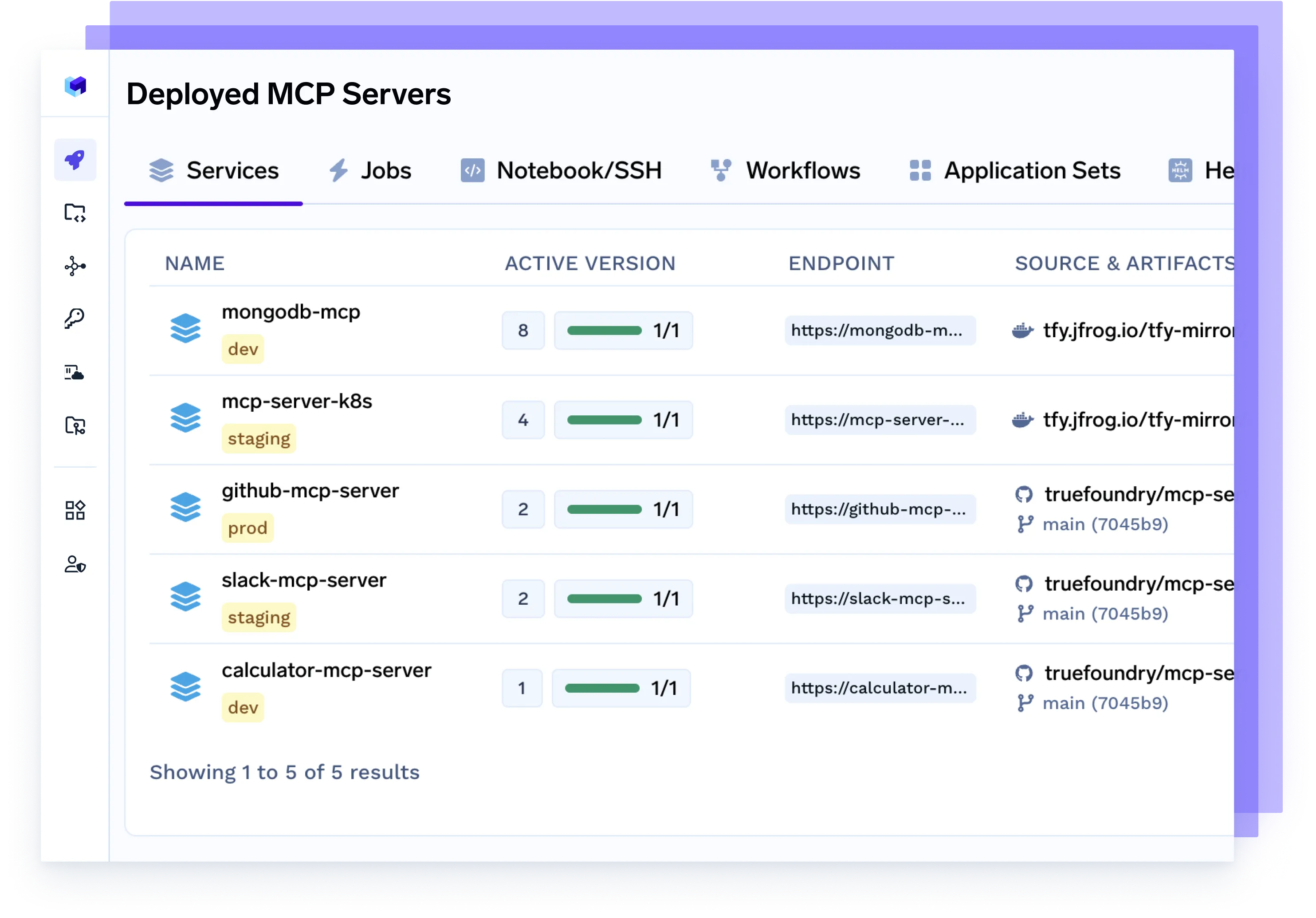
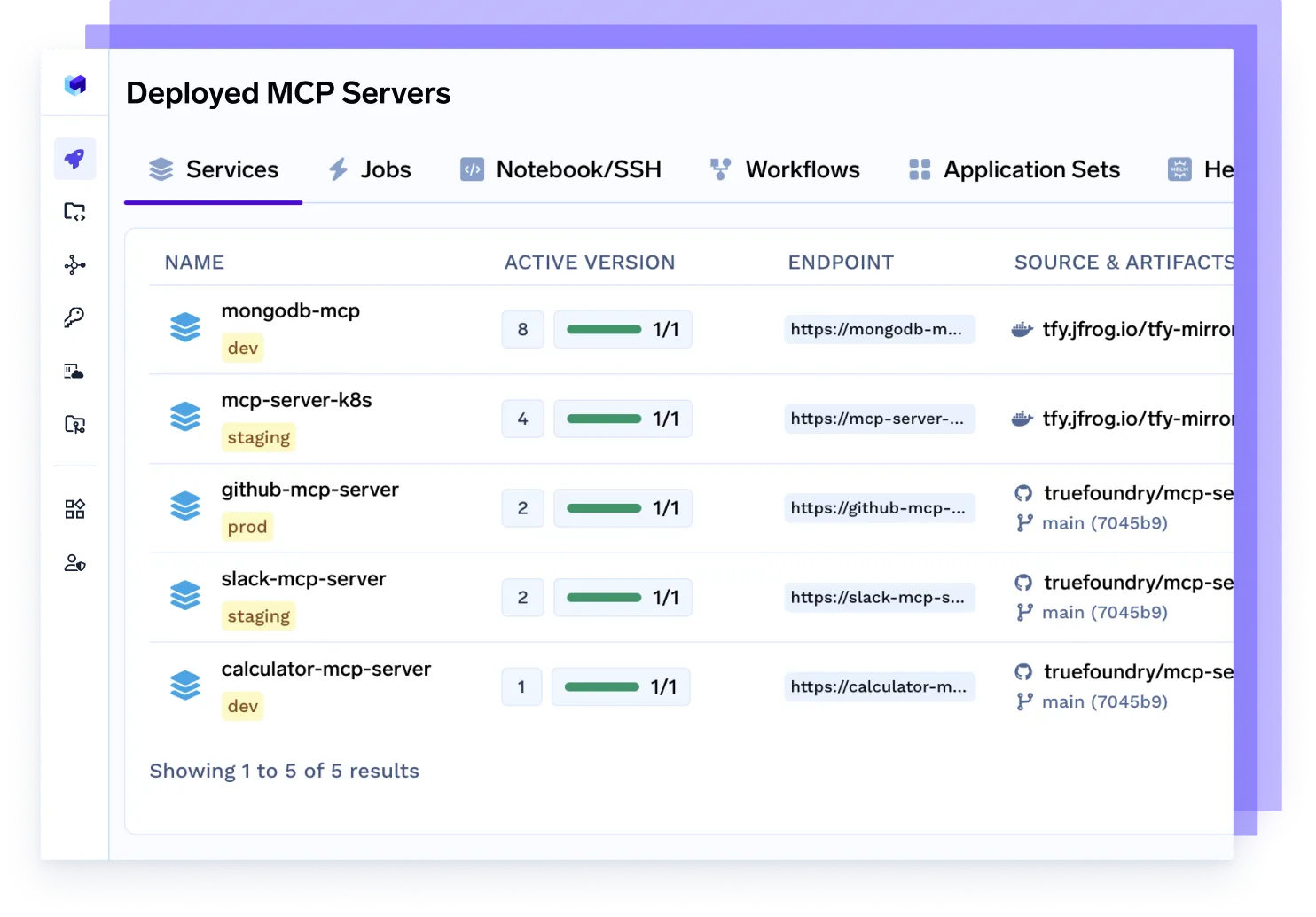
MCP-Server bereitstellen
Stellen Sie dedizierte Model Control Protocol (MCP) -Server bereit, um den Agentenverkehr zu verwalten, den Modellzugriff zu skalieren, Ratenbeschränkungen durchzusetzen und Workloads nach Team oder Projekt zu isolieren.
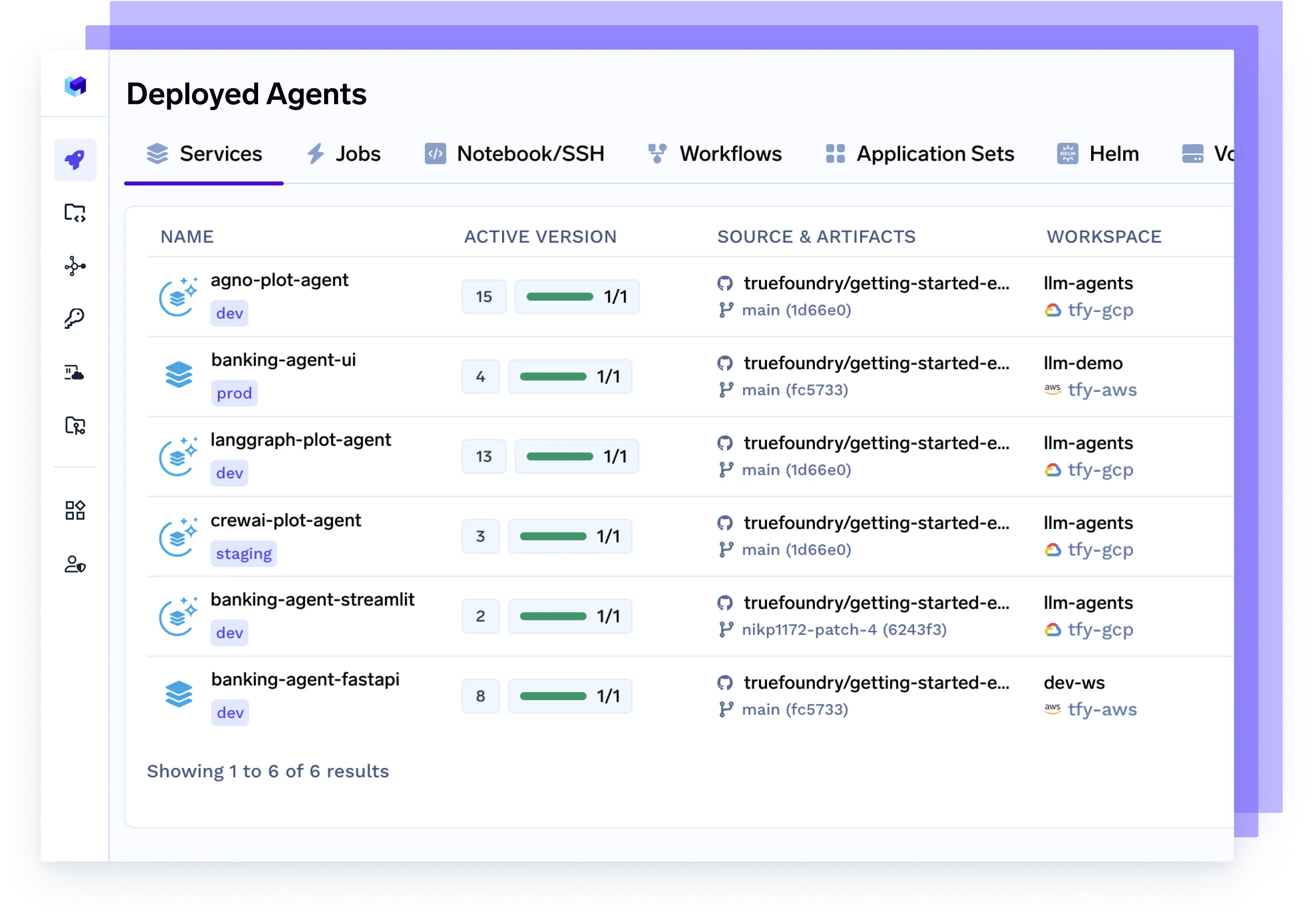
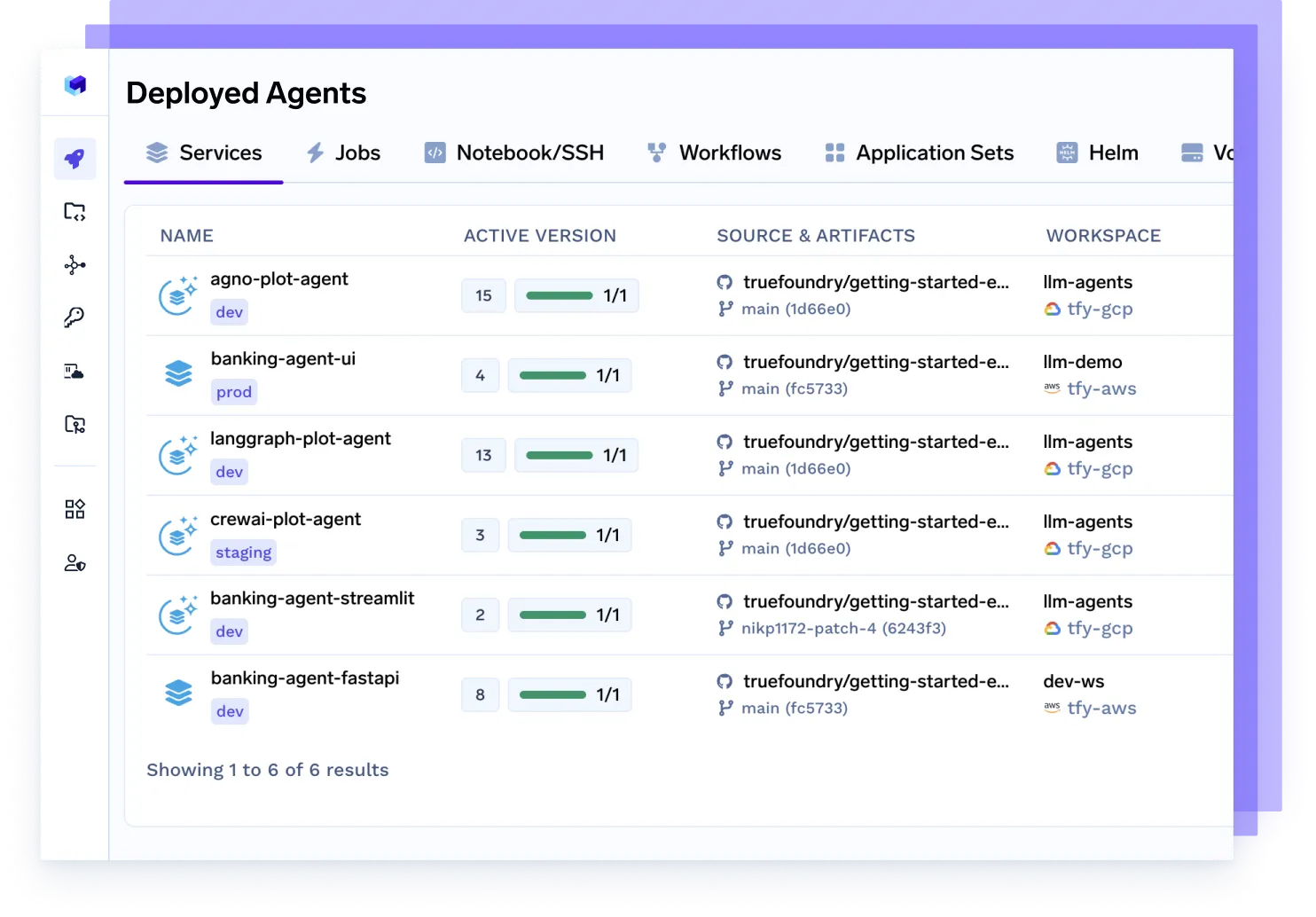
Stellen Sie jeden Agenten und jedes Framework bereit
Bedienen Sie Agenten, die mit Langgraph, CrewAI, AutoGen oder Ihrer eigenen Orchestrierung erstellt wurden, nahtlos — vollständig containerisiert, beobachtbar und produktionsbereit.
VPC, vor Ort, Airgapped oder über mehrere Clouds hinweg.
Keine Daten verlassen Ihre Domain. Genießen Sie vollständige Souveränität, Isolierung und Compliance auf Unternehmensebene, wo auch immer TrueFoundry ausgeführt wird.


.avif)
Bereit für Unternehmen
Ihre Daten und Modelle sind sicher untergebracht innerhalb Ihrer Cloud-/On-Prem-Infrastruktur


Einhaltung von Vorschriften und Sicherheit
SOC 2-, HIPAA- und DSGVO-Standards um einen robusten Datenschutz zu gewährleistenVerwaltung und Zugriffskontrolle
SSO + Rollenbasierte Zugriffskontrolle (RBAC) und AuditprotokollierungSupport und Zuverlässigkeit für Unternehmen
Support rund um die Uhr mit SLA-Unterstützung Antwort-SLAs
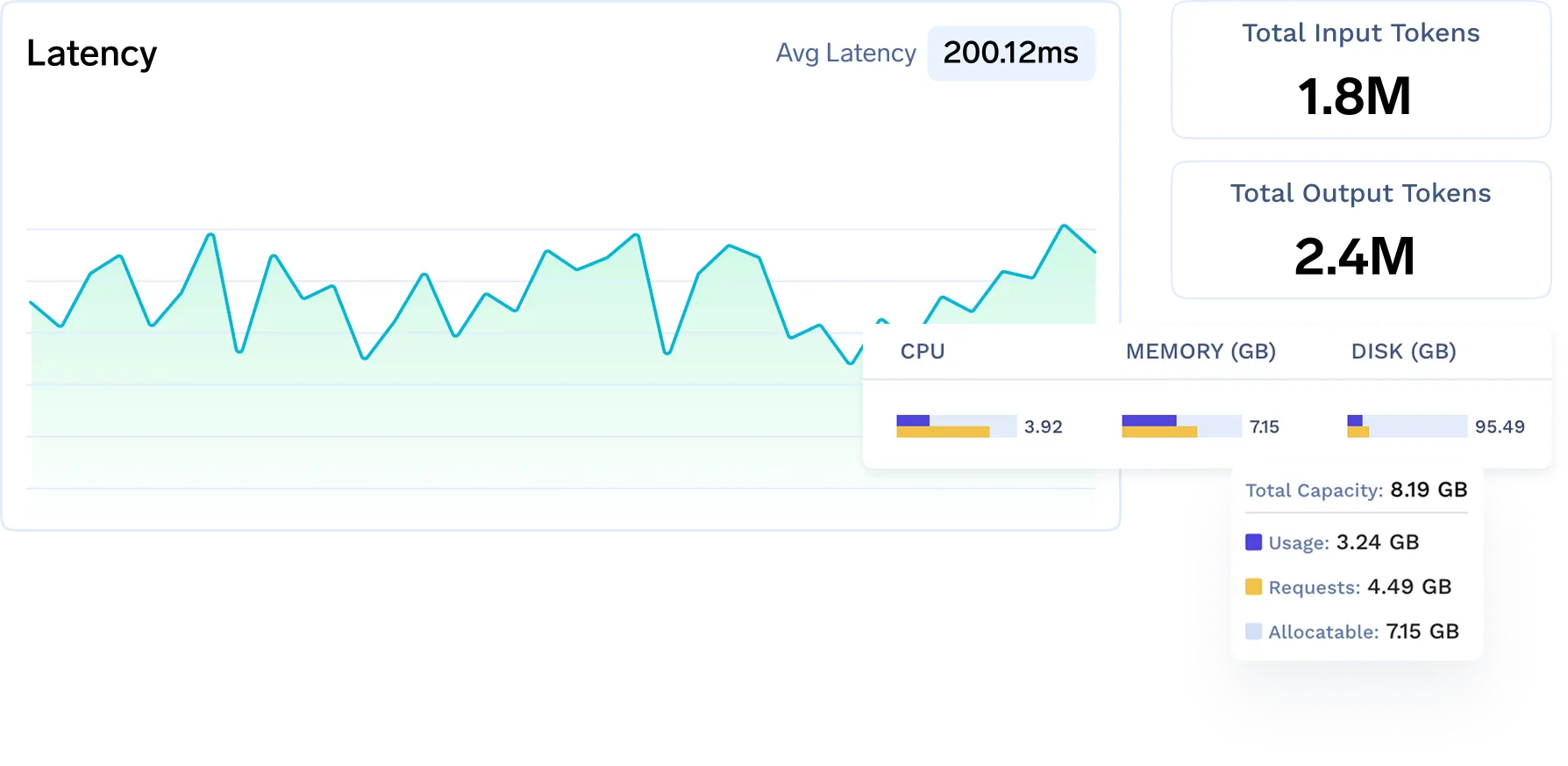
Beobachten Sie die Agenten und die zugrunde liegende Infrastruktur
Framework-unabhängiges Tracing für alles, von der prompten Ausführung bis zur GPU-Leistung.
Vollständige Beobachtbarkeit durch Agenten
Verfolgen Sie jeden Schritt von der Aufforderung bis zur Ausführung des Tools/Modells mit Metriken, Latenz und Ergebnissen
.webp)
Nahtlose Integration mit internen Tools
OpenTelemetry-konform; schließen Sie es an Grafana, Datadog, Prometheus oder Ihren bevorzugten Observability-Stack an




Beobachtbarkeit der Infrastruktur (GPU, CPU, Cluster)
Überwachen Sie die Ressourcennutzung in der Cloud/On-Premise — einschließlich GPU-Speicher, Node-Zustand und Skalierungsverhalten
.webp)
Steuern und durchsetzen Sie die Einhaltung von Vorschriften für unternehmensweite KI
Sorgen Sie für Vertrauen und Betriebsdisziplin mit robusten Zugriffskontrollen, der Durchsetzung von Richtlinien und umfassender Beobachtbarkeit — vom ersten Tag an nativ integriert.
.webp)
Granulare rollenbasierte Zugriffskontrolle (RBAC)
Steuern Sie präzise, wer auf Modelle, Umgebungen oder APIs zugreifen kann, basierend auf Teams, Rollen und Funktionen.
.webp)
Unveränderliche Auditprotokollierung
Zeichnen Sie alle Aktivitäten auf, einschließlich Modellnutzung, Benutzerzugriff und Konfigurationsänderungen, um eine vollständige Auditbereitschaft sicherzustellen.

Compliance-fähige Architektur
Entwickelt, um die höchsten Sicherheits- und Compliance-Standards zu erfüllen, einschließlich SOC 2, HIPAA und GDPR.
Einheitliche Überwachung und Alarmierung
Verfolgen Sie Latenz, Durchsatz, Token-Nutzung, Kosten und GPU-Auslastung in Ihrem gesamten KI-Stack über zentrale Dashboards und Benachrichtigungen.

Durchsetzung von Richtlinien in Echtzeit
Setzen Sie Richtlinien in Bezug auf Datenspeicherort, Nutzungskontingente, Ratenbegrenzungen und Kostenkontrolle dynamisch durch, während die Workloads ausgeführt werden.
Wir stellen uns eine KI-optimierte und verwaltungsfreie KI-Infrastruktur vor
Automatisierte Ressourcenoptimierung ohne Betriebsaufwand
GPU-Orchestrierung und Autoscaling
Planen und skalieren Sie GPU-Workloads automatisch entsprechend der Nachfrage und optimieren Sie so die Leistung ohne Überversorgung.
Fraktionierte GPU-Unterstützung
(MIG und Time Slicing)
Ermöglichen Sie die kostengünstige gemeinsame Nutzung von GPU-Ressourcen für mehrere Workloads mithilfe von NVIDIA MIG und Time Slicing.
Ressource in Echtzeit
Optimierung
Passen Sie die CPU- und Speicherzuweisungen kontinuierlich an die tatsächlichen Datenverkehrs- und Rechenanforderungen an.
Automatisierte Anpassung der Infrastruktur
Erkennen und korrigieren Sie überlastete Infrastrukturen, um Cloud-Verschwendung zu reduzieren und gleichzeitig die SLAs und die Modellleistung aufrechtzuerhalten.
Echte Ergebnisse bei TrueFoundry
Warum sich Unternehmen für TrueFoundry entscheiden






3 x
schnellere Amortisierungszeit mit autonomen LLM-Agenten
80%
höhere GPU-Cluster-Auslastung nach automatisierter Agentenoptimierung

Aaron Erickson
Gründer von Applied AI Lab
TrueFoundry hat unsere GPU-Flotte in eine autonome, sich selbst optimierende Engine verwandelt, die 80% mehr Auslastung ermöglicht und uns Millionen an ungenutzter Rechenleistung erspart.
5x
schnellere Produktionszeit der internen KI/ML-Plattform
50%
geringere Cloud-Ausgaben nach der Migration von Workloads zu TrueFoundry

Pratik Agrawal
Leitender Direktor, Datenwissenschaft und KI-Innovation
TrueFoundry hat uns geholfen, in Rekordzeit vom Experimentieren zur Produktion überzugehen. Was über ein Jahr gedauert hätte, war in Monaten erledigt — bei besserer Akzeptanz durch Entwickler.
80%
Verkürzung der Produktionszeit von Modellen
35%
Cloud-Kosteneinsparungen im Vergleich zum vorherigen SageMaker-Setup
.webp)
Vibhas Geji
Mitarbeiter ML Engineer
Wir haben die DevOps-Belastung reduziert und die produktiven Rollouts teamübergreifend vereinfacht. TrueFoundry beschleunigte die ML-Bereitstellung mit einer Infrastruktur, die von Experimenten bis hin zu robusten Services skaliert werden kann.
50%
schnellere RAG-/Agent-Stack-Bereitstellung
60%
Reduzierung des Wartungsaufwands für RAG-/Agent-Pipelines
.webp)
Indronel G.
Intelligenter Prozessführer
TrueFoundry half uns dabei, einen vollständigen RAG-Stack — einschließlich Pipelines, Vektor-DBs, APIs und UI — doppelt so schnell bereitzustellen und dabei die volle Kontrolle über die selbst gehostete Infrastruktur zu haben.
60%
schnellere KI-Bereitstellungen
~ 40-50%
Effektive Kostenreduzierung in allen Entwicklungsumgebungen
.webp)
Nilav Ghosh
Leitender Direktor, KI
Mit TrueFoundry haben wir die Bereitstellungszeiten um mehr als die Hälfte reduziert und den Infrastrukturaufwand durch eine einheitliche MLOps-Schnittstelle gesenkt — was die Wertschöpfung beschleunigt hat.
<2
Wochen, um alle Produktionsmodelle zu migrieren
75%
Verkürzung des Zeitaufwands für die Koordination von Datenwissenschaften, Beschleunigung von Modellaktualisierungen und Feature-Rollouts
.webp)
Rajat Bansal
CTO
Wir haben viel an Infrastrukturkosten gespart und die DS-Koordinationszeit um 75% reduziert. TrueFoundry hat die Geschwindigkeit unserer Modellbereitstellung in allen Teams erhöht.
Integrationen
Framework-unabhängige Integrationen für alles, von Low-Code-Agent-Buildern bis hin zur Leistungsbewertung auf GPU-Ebene.


GenAI infra- einfach, schneller, günstiger
Top-Teams vertrauen uns bei der Skalierung von GenAI
- © 2022 ENSEMBLE Technologies






Abonnieren Sie unseren Newsletter
Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2025 Alle Rechte vorbehalten.


