
TrueFoundry kündigt die Übernahme von Seldon AI an und erweitert damit seine Control Plane für Enterprise-KI. Vollständigen Bericht lesen →

Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.










KI-Lösung zur Bewertung und Verbesserung der Lesefähigkeiten von Kindern in unterversorgten Gemeinden
Wadhwani AI ist eine gemeinnützige Organisation, die an mehreren schlüsselfertigen KI-Lösungen für unterversorgte Bevölkerungsgruppen in Entwicklungsländern arbeitet.
Im Rahmen des Vachan Samiksha-Projekts entwickelt das Team eine maßgeschneiderte KI-Lösung, mit der Lehrer im ländlichen Indien die Lesefähigkeit der Schüler beurteilen und einen personalisierten Notfallplan entwickeln können, um die Lesefähigkeiten jedes einzelnen Schülers zu verbessern.
Das Team hatte die Lösung in Grundschulen zur Durchführung von Pilotprojekten eingesetzt. Das Team sah sich jedoch mit den folgenden Problemen konfrontiert, die gelöst werden mussten, bevor der Umfang des Projekts auf weitere Schulen und Schüler ausgedehnt wurde:
Das TrueFoundry-Team hat sich mit dem Team zusammengetan, um diese Probleme zu lösen. Mithilfe der TrueFoundry-Plattform war das Team in der Lage:
Wadhwani AI wurde von Romesh und Sunil Wadhwani gegründet (Teil der Times100 AI-Liste), um KI zur Lösung von Problemen zu nutzen, mit denen unterversorgte Gemeinschaften in Entwicklungsländern konfrontiert sind. Sie arbeiten mit Regierungen und globalen gemeinnützigen Organisationen auf der ganzen Welt zusammen, um durch die Lösung einen Mehrwert zu schaffen. Als gemeinnützige Organisation nutzt Wadhwani AI künstliche Intelligenz, um soziale Probleme unter anderem in den Bereichen Landwirtschaft, Bildung und Gesundheit zu lösen. Einige ihrer Projekte umfassen:
Wadhwani AI arbeitet auch mit Partnerorganisationen zusammen, um deren KI-Bereitschaft zu bewerten, d. h. ihre Fähigkeit, KI-Lösungen effektiv und nachhaltig zu entwickeln und zu nutzen. Die Arbeit von Wadhwani AI zielt darauf ab, KI für immer einzusetzen und das Leben von Milliarden von Menschen in Entwicklungsländern zu verbessern.
Lesefähigkeiten sind für die Bildungsgrundlage eines Kindes von grundlegender Bedeutung. Leider fehlt es vielen Schülern aus den ländlichen und benachteiligten Regionen Indiens und anderer Entwicklungsländer an diesen Fähigkeiten. Um dieses Problem auf einer grundlegenden Ebene zu lösen, hat das Wadhwani AI-Team ein KI-gestütztes Tool namens Vachan Samiksha entwickelt.
Das Tool setzt KI ein, um die Leseleistung jedes Kindes zu analysieren. Es richtet sich derzeit hauptsächlich an ländliche und halbstädtische Regionen des Landes und wird altersübergreifend eingesetzt. Um die Lösung für den Großteil des Landes verallgemeinerbar zu machen, hat das Team ein Modell entwickelt, das Akzente einbezieht, um Regionalsprachen und Englisch zu bewerten. Die manuelle Bewertung dieser Fähigkeiten hat ihre eigenen Vorurteile und ist oft ungenau.
Die Lösung wird den Benutzern (Lehrern der Zielschulen) über eine App zur Verfügung gestellt, die das in der Cloud bereitgestellte Modell aufruft. Der Schüler muss einen Absatz lesen, der von der Anwendung aufgezeichnet und an die Cloud gesendet wird. In der Cloud bewertet das Modell die Lesequalität, die Geschwindigkeit, das Verständnis und andere komplexe Lernverzögerungen, die bei einer normalen Bewertung übersehen werden könnten. Neben der Bewertung dieser Fähigkeiten erstellt die Anwendung auch einen personalisierten Lernplan für jeden Schüler, um ihnen das Lernen zu erleichtern, und erstellt auch demografische Berichte für Maßnahmen der Regierungsbehörden auf Makroebene. Das Team hatte das Modell für das Pilotprojekt zusammen mit dem verwalteten ML-Dienst des Cloud-Anbieters bereitgestellt
Als wir unsere Zusammenarbeit mit dem Vachan Samiksha-Team innerhalb von Wadhwani AI begannen, nutzte das Team den nativen MLOps-Stack seines Cloud-Anbieters, um das Modell für das Pilotprojekt mit dem Bildungsministerium von Gujarat bereitzustellen.
Ihre Infrastruktur war wie folgt eingerichtet:
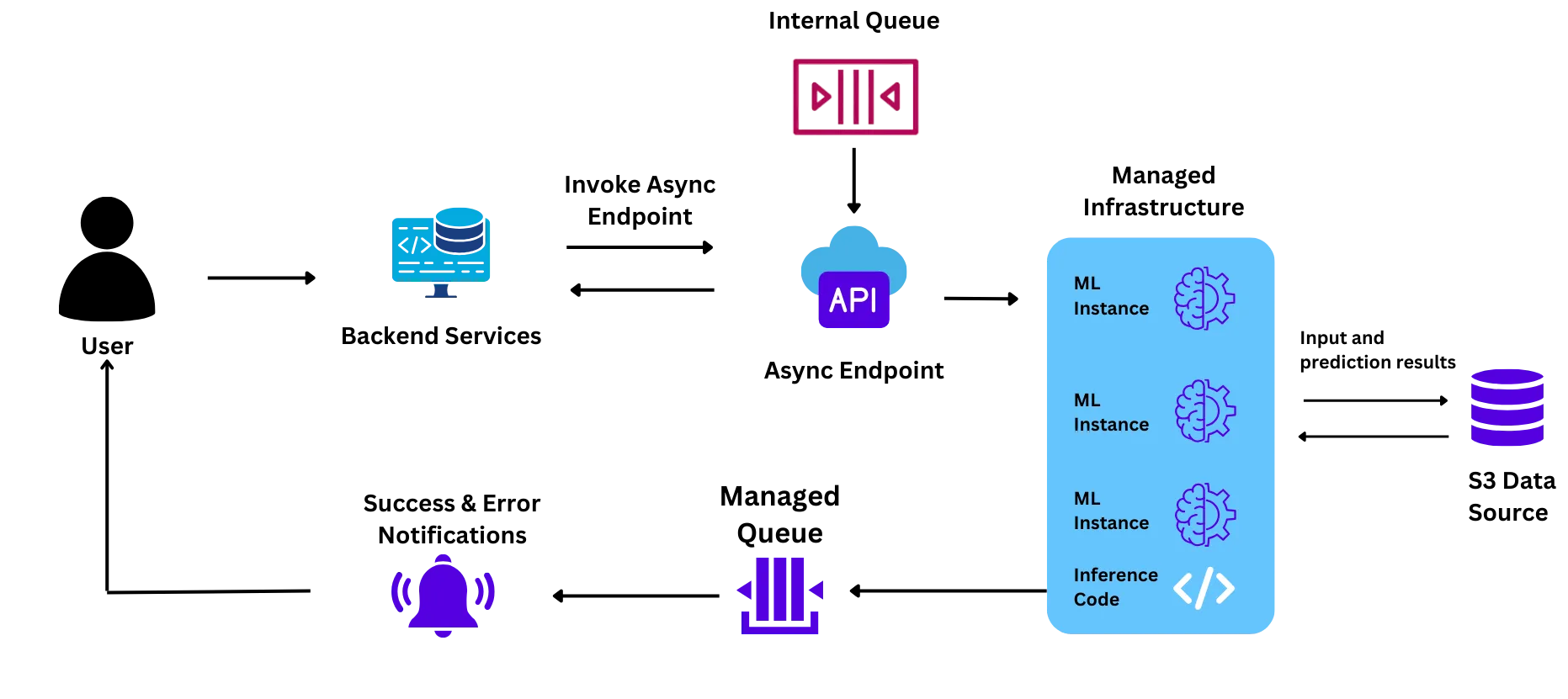
Das Team stand bei der Durchführung des ersten Pilotprojekts vor Herausforderungen mit diesem Aufbau, was es motivierte, andere Lösungen auszuprobieren:
Es wurde erwartet, dass das Pilotprojekt in großem Umfang durchgeführt wird (~6 Millionen Schüler in einem Monat). Das Team war sich jedoch nicht sicher, dass der verwaltete ML-Dienst in der Lage sein würde, diese Größenordnung zu unterstützen, und zwar aus folgenden Gründen:
Während des Pilotprojekts hatte das Team Probleme mit der Skalierungsgeschwindigkeit, und einige Pods kamen nicht wie erwartet zum Einsatz. Um das Problem zu lösen, kontaktierte das Team jedoch die Vertreter des Cloud-Anbieters, die sich dann an das technische Team wandten. Dies führte zu einer Verzögerung des Systems und zu einer Verzögerung des Pilotprojekts.
Als der Anforderungsverkehr während des Pilotprojekts zunahm, mussten die Pods horizontal skalieren (neue Knoten einrichten, die einige der Anfragen aus der Warteschlange aufnehmen und verarbeiten konnten). Dieser Vorgang dauerte für jeden neuen Pod, der gestartet wurde, ~9-10 Minuten, was zu verzögerten Antworten und einer schlechten Erfahrung für den Endbenutzer führte.
GPU-Instances sind aufgrund des weltweiten Chipmangels sehr teuer. Hinzu kommt der Aufschlag von 20-40% für ML-Instanzen, den der Cloud-Anbieter festlegt. Dadurch waren die Kosten für die Instanzen sehr hoch und für das Team in dem Umfang, in dem es das Projekt durchführen wollte, nicht durchführbar.
Als wir das Vachan Samiksha-Team trafen, befanden sie sich in der Zeit zwischen ihrem ersten und dem zweiten Piloten. Der Pilot war weniger als eine Woche entfernt und wir mussten:

In der Zeit vor dem Piloten:
Unser Team half dem Wadhwan AI Team bei der Installation der Plattform auf ihrem eigenen Roh-Kubernetes. Die Steuerungsebene und der Workload-Cluster wurden beide auf ihrer eigenen Infrastruktur installiert. Alle Daten, Benutzeroberflächenelemente für die Interaktion mit der Plattform und die Workload-Prozesse für das Trainieren/Bereitstellen der Modelle blieben in ihrer eigenen VPC. Die Plattform entsprach außerdem allen Sicherheitsregeln und -praktiken des Unternehmens.
Wir haben dem Team geholfen zu verstehen, wie die verschiedenen Komponenten während des Schulungs- und Onboarding-Prozesses zusammenwirken. Wir haben ihnen erklärt, wie Ressourcen eingerichtet, Autoscaling konfiguriert und das Modell bereitgestellt werden.
Das Wadhwani AI-Team war in der Lage, die Anwendung mit minimaler Hilfe des TrueFoundry-Teams selbstständig zu migrieren. Dies geschah in einem einstündigen Gespräch mit dem Team.
Nach der Bereitstellung der Anwendung begann das Team, die Auslastung der Anwendung auf Produktionsebene zu testen. Das Team skalierte die Anwendung unabhängig voneinander mithilfe eines einfachen Arguments auf der TrueFoundry-Benutzeroberfläche auf mehr als 100 Knoten, was dem Fünffachen der bisher höchsten erreichbaren Skala entspricht. Sie versuchten auch, die Geschwindigkeit der Node-Skalierung zu vergleichen, die viel (3-4 X) schneller war als die von ihnen angegebene.
Nachdem die Belastungstests abgeschlossen waren, stellte das Team die Pilotanwendung bereit und war darauf vorbereitet, sie in der zweiten Phase des Pilotprojekts einzuführen, das an 1000 Schulen, 9000 Lehrern und über 2 Lakh-Schülern eingeführt wurde.
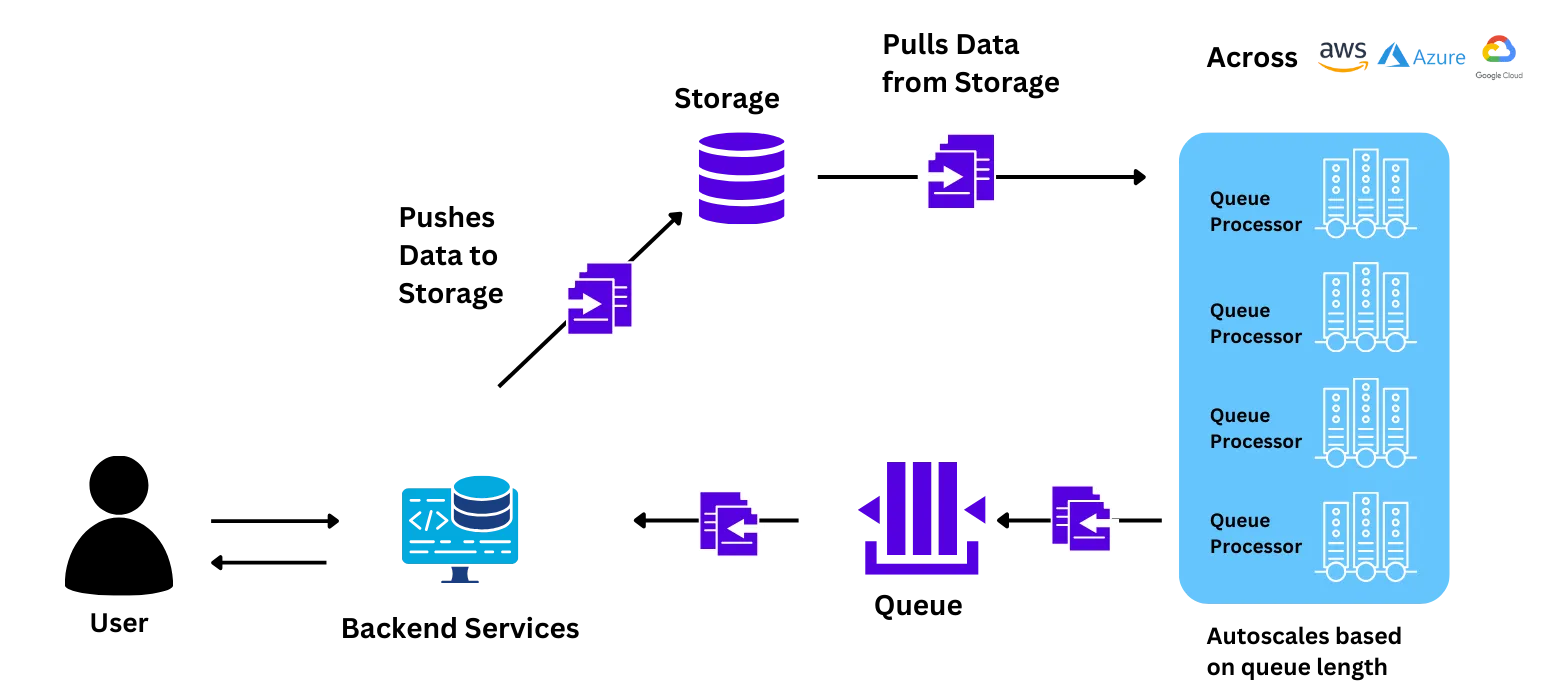
Mit einem minimalen Aufwand von weniger als 10 Stunden konnte das Wadhwani AI-Team eine deutliche Verbesserung in Bezug auf Geschwindigkeit, Kontrolle und Kosten erzielen. Einige der wichtigsten Änderungen, die sie feststellten, waren:
Die Data Scientists und Machine Learning Engineers waren in der Lage, mehrere Elemente zu konfigurieren, was für sie entweder über die Konsole des Cloud-Anbieters schwierig war oder sie sich auf das Engineering-Team verlassen mussten:
Basierend auf der Warteschlangenlänge und Erhöhung der maximalen Anzahl von Replikaten/Knoten auf 70 statt der vorherigen Grenze von 20
Da der Großteil des Pilotverkehrs während der Schulzeit einging, wenn die Lehrer mit den Schülern interagierten, gab es am Abend und am Abend kaum Anfragen, wenn überhaupt. Die Teamkonstante war in der Lage, einen Skalierungszeitplan aufzustellen, bei dem die Pods während der Ausfallzeiten (abends und nachts) auf ein Minimum herunterskaliert wurden. Dadurch konnten etwa 15-20% der Pilotkosten eingespart werden.
Das Team konnte den Traffic, die Ressourcenauslastung und die Antworten einfach direkt von der TrueFoundry-Benutzeroberfläche aus überwachen. Außerdem erhielten sie über die Plattform Vorschläge, wann immer es zu einer Über- oder Unterversorgung von Ressourcen kam
Um die Skalierung mit TrueFoundry zu testen, sendete das Team eine Reihe von 88 Anfragen an die Anwendung und verglich die Leistung des verwalteten ML-Dienstes des Cloud-Anbieters mit der von TrueFoundry. Alle Systemkonfigurationen wurden wie die Skalierungslogik beibehalten (basierend auf der Länge der Backlog-Warteschlange, der anfänglichen Anzahl der Knoten, dem Instanztyp usw.)
Wir haben festgestellt, dass TrueFoundry um 78% schneller skalieren kann als ein verwalteter ML-Dienst, wodurch der Benutzer viel schnellere Antworten erhielt. Die gesamte Zeit, die für die Beantwortung der Anfrage benötigt wurde, war mit TrueFoundry um 40% kürzer.
Die Kosten, die dem Team für das Pilotprojekt entstanden waren, wurden durch die Umstellung auf TrueFoundry um ~ 50% reduziert. Dies wurde durch die folgenden Faktoren ermöglicht:
Während Managed ML Service durch die Verfügbarkeit von GPU-Instanzen in derselben Region des Cloud-Anbieters eingeschränkt war, kann TrueFoundry dem System Worker-Knoten hinzufügen, die sich in jeder Region oder bei jedem Cloud-Anbieter befinden konnten.
Das bedeutet, dass:
TrueFoundry bietet eine nahtlose Integration mit jedem Tool, das das Team verwenden möchte. Beim Cloud-Anbieter war dies durch die Designentscheidungen des Anbieters und seine nativen Integrationen begrenzt. Zum Beispiel wollte das Team NATS verwenden, um Nachrichten zu veröffentlichen, was der native Dienst des Cloud-Anbieters derzeit nicht bot. Solche Entscheidungen zu treffen, wurde für das Wadhwani AI Team von TrueFoundry als trivial angesehen.







Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet



