













.webp)
June 23, 2026
|
5 min read

Published: May 9, 2026

Blazingly fast way to build, track and deploy your models!
50 Questions to Ask Every Vendor in 2026
Enterprise AI platform evaluations fail in predictable ways. The vendor's demo runs against a curated test prompt. Their pricing slide uses 5,000-token-per-call assumptions that don't match your actual workload. The security architecture diagram they show is for a deployment mode you haven't asked about. The MCP capability they claim is available “in our next release.” Six weeks later you're signing a contract for a product that's a 70 percent fit, and your platform team spends the contract term filling the other 30 percent with custom work.
A scored RFP changes the dynamic. Every vendor answers the same questions, in writing, before any demo runs. Their non-answers (a question dodged, a capability that “requires our integration partner,” a compliance claim that doesn't survive a scope question) surface in the written record where they can't be re-spun in a follow-up call. The same record holds the vendor accountable when post-signature reality starts diverging from the pre-signature pitch, which is the single most common procurement complaint at year-one renewal.
Three things push this template beyond what generic enterprise procurement frameworks already cover. MCP governance, the protocol stack your AI agents will use to talk to tools, where most AI gateway products are still bolting on access control they didn't design for. Agentic AI controls, the trace correlation, cost attribution, and isolation boundaries that turn a multi-step agent task into a debuggable, billable, governable unit instead of a fog of disconnected LLM calls. AI-specific compliance, including audit log field parity between LLM and tool invocations, structured data-residency answers that account for model-provider routing across regions, and the BAA architectural controls that make HIPAA enforcement real rather than paperwork.
Use this as a starting point. Adjust the weights to your environment. Send the same document to every vendor on your shortlist. TrueFoundry's solutions team is set up to answer all 50 questions in writing with evidence as part of the formal enterprise evaluation.
Now to the questions themselves.

Figure 1. Split-plane reference architecture: control plane and compute plane separated by a metadata-only boundary, with one IdP feeding identity into both.
The order of operations matters more than the questions themselves. Most failed evaluations skip step one: getting written answers to the full template before any vendor is allowed to demo. Demos are for verification of written claims, not for discovery. If a vendor's first communication of a feature comes from a slide, you've handed them control of the evaluation narrative.
Send the template to every vendor on your shortlist simultaneously, with a written response deadline two weeks out. Use the responses to score against a weighted rubric. Only after scoring do you book demos, and in those demos your platform team's job is to verify that what's in writing matches what's running. Treat any claim that surfaces in the demo but wasn't in the written response as a discovery to investigate, not a feature to score positively.
A few specifics on running this well:
If you've ever sat through a security review where the vendor's compliance scope only covered the SaaS option you weren't planning to use, you know the cost of skipping the rubric step. A scored RFP forces that detail out before the contract.
Security and compliance is where most AI platform evaluations fall apart in the second meeting. Not because vendors lack certifications. Most have SOC 2 Type II somewhere. The failure mode is alignment: the certification scope, the architectural controls implementing it, and the deployment mode you're actually buying don't match. A SOC 2 covering the vendor's marketing portal does nothing for an AI gateway processing PHI on-prem. A BAA that exists in template form but doesn't describe how PHI is isolated in the data plane is paperwork, not a control. The questions below force the alignment between certification scope and architectural reality that prevents “we're certified” answers from carrying weight they shouldn't.
The other failure mode worth naming early: vendors who answer security questions in the abstract because their concrete architecture is split between two products with different control postures. Their on-prem version is feature-thin and not separately certified. Their SaaS version has the certifications but doesn't fit your environment. Spot this by asking the same question twice with the deployment mode specified each time. If the answers differ, you're looking at two products marketed as one.
Score this section ruthlessly.
A split-plane deployment where the data plane (the proxy that handles prompts, model responses, embeddings, MCP tool invocations) runs entirely in the customer's VPC and never opens an outbound connection to vendor infrastructure for request payloads. The control plane (configuration, RBAC settings, dashboards) may run in vendor infrastructure or customer infrastructure depending on the deployment mode, but exchanges only metadata. Audit logs, prompt-response data, and embeddings land in customer-controlled blob storage (S3, GCS, Azure Blob), not vendor-managed databases. If the vendor's “VPC deployment” still ships prompts to a vendor-managed log aggregator, that's a SaaS deployment in a different wrapper.
Check the System Description section for explicit naming of the deployment modes covered. Look for language like “the multi-tenant SaaS environment hosted in [cloud]” versus “the customer-deployed gateway and control plane components.” If the description names only one, the certification covers only one. Check the Trust Services Criteria covered. Security is the baseline, but Availability, Confidentiality, and Processing Integrity matter for AI workloads handling regulated data. A SOC 2 covering only Security is half the story.
The platform pulls model provider keys from the customer's Vault or Secrets Manager at gateway startup or on-demand using a customer-managed IAM role, with key references (not key values) stored in platform configuration. Rotation is a Vault operation: rewrite the key in Vault, the gateway picks up the new value on next read or on a configurable refresh interval. The platform never persists provider keys at rest. If the vendor's answer is “you upload keys into our admin UI and we store them encrypted,” that's a different (and weaker) security model. The keys are now in vendor infrastructure even in a “VPC” deployment.
{
"event_type": "llm_inference",
"timestamp": "2026-04-28T14:22:31.482Z",
"request_id": "req_01H8X2YZ...",
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"user": {
"id": "u_4821",
"email": "ana@company.com",
"team": "applied-ml"
},
"application": {
"id": "app_chat_support",
"env": "prod"
},
"model": {
"provider": "anthropic",
"id": "claude-sonnet-4-6",
"version": "20260217"
},
"tokens": {
"input": 1842,
"output": 619,
"cached": 1200
},
"latency_ms": {
"ttft": 312,
"total": 2180
},
"cost_usd": 0.01443,
"policy": {
"guardrails_evaluated": [
"pii",
"content_filter"
],
"decision": "allow"
},
"status": "success"
}The MCP tool invocation log should have field parity for the shared dimensions (timestamp, request_id, trace_id, user, application, latency_ms, status, policy decision) plus the tool-specific fields:
{
"event_type": "mcp_tool_invocation",
"timestamp": "2026-04-28T14:22:32.014Z",
"request_id": "req_01H8X2YZ...",
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"user": {
"id": "u_4821",
"email": "ana@company.com",
"team": "applied-ml"
},
"application": {
"id": "app_chat_support",
"env": "prod"
},
"mcp_server": {
"id": "github-prod",
"version": "1.4.2"
},
"tool": {
"name": "github.create_issue",
"schema_version": "v2"
},
"parameters_hash": "sha256:7c8b...a31e",
"response_size_bytes": 412,
"latency_ms": 528,
"policy": {
"rules_evaluated": [
"repo_allowlist",
"rate_limit"
],
"decision": "allow"
},
"status": "success"
}Notice the same trace_id on both: the LLM call and the MCP invocation correlate to one user request, which is the answer to Section 4 question 8 made concrete. Hash the parameters rather than logging them raw. Full parameter logging is a data-leakage risk in regulated environments. If the vendor's sample MCP log is missing policy.decision, trace_id, or user attribution, MCP governance is post-hoc reporting, not enforcement.

Figure 2. Audit log data flow: field parity between LLM inference events and MCP tool invocation events, both correlated by one trace_id.
“Encrypted at rest” is universal. Whose key is doing the encrypting is the actual control. In a self-hosted deployment, customer-controlled keys are achievable because the data stores are in the customer's account; in a SaaS deployment, customer-controlled keys are a vendor-side capability that has to be designed in. Ask the question with the deployment mode specified.
For self-hosted deployments, “patch availability” means a tagged release the customer's platform team can deploy. “Customer-applied window” is the SLA the customer signs up for internally. If the vendor proposes a 30-day customer window for critical CVEs, that's a long time to be exposed; push back.
Most enterprise procurement falls apart in deployment. The platform looks great in the SaaS demo, then the security review surfaces three things that block it: outbound connectivity to vendor infrastructure for telemetry, a configuration database hosted in vendor cloud, and a control plane that's tightly coupled to a specific cloud region. By the time those constraints are visible you've already negotiated pricing on the wrong product, and the path forward is either renegotiating from a position of sunk cost or accepting a deployment that creates compliance debt.
This section surfaces deployment constraints upfront. The vendors who can answer it cleanly are the ones who've already deployed in environments like yours. The vendors who need a discovery call to answer Section 2 haven't, and you'll be doing the integration engineering on the discovery call you're paying them for.
Watch the answers carefully.
┌──────────────────────────────────────────────────────┐
│ Customer VPC (one region, two AZs for HA) │
│ │
│ [ALB / NLB] │
│ │ │
│ ├──> Gateway pods (3+ replicas, HPA enabled) │
│ │ ↕ reads keys from │
│ │ [Secrets Manager / Vault] │
│ │ ↕ writes audit + metrics to │
│ │ [S3 / GCS / Azure Blob] │
│ │ ↕ reads config from │
│ │ [Postgres (HA, multi-AZ)] │
│ │ │
│ └──> egress to: model provider APIs, │
│ MCP servers (in-VPC or │
│ allowlisted external) │
│ │
│ [Control plane endpoint] ──> metadata only, │
│ (vendor or self-hosted) no payload data │
└──────────────────────────────────────────────────────────┘
Order-of-magnitude sizing for ~500 RPS sustained: 3 to 4 gateway replicas at 2 vCPU / 4 GB RAM each, Postgres at 4 vCPU / 16 GB RAM with 100 GB SSD, blob storage scaled with retention (a 90-day retention at 10 KB/log entry and 500 RPS is roughly 1.2 TB). The vendor should produce numbers like these in writing before signing, not “depends on workload.”

Figure 3. One control plane managing compute planes across AWS, Azure, GCP, and on-prem Kubernetes simultaneously, each with its own data residency boundary.
Anything worse than this for a multi-region production setup should come with a written explanation. “We don't support multi-region” is acceptable from a small vendor; “we support it but won't commit to RTO” is not.
Every AI gateway product page reads the same: unified API, intelligent routing, cost controls, observability. The specifics behind those words are what separates a gateway you can run in production from a thin proxy with a marketing site. “Intelligent routing” can mean anything from a static round-robin between two models to a real cascading policy with cost ceilings, capability matching, and fallback chains. “Cost controls” can mean a dashboard that shows you yesterday's bill, or it can mean hard token budgets that actually return a 429 to the application when a team hits its limit.
The questions in this section force the specifics out. Reject responses that restate the marketing copy back to you. The vendor who says “we support intelligent routing” without describing the rule language, the cascade behavior, the failure handling, and the budget integration doesn't have routing. They have a config flag.
Make them prove the architecture exists.
route: chat-support
match:
application: app_chat_support
team: applied-ml
strategy: cascade
cascade:
- model: claude-sonnet-4-6
provider: anthropic
conditions: { max_input_tokens: 1000000 }
- model: gpt-5.5
provider: openai
conditions: { fallback_on: ["rate_limit", "5xx"] }
- model: claude-haiku-4-5
provider: anthropic
conditions: { fallback_on: ["all_above_failed"] }
guardrails: [pii, content_filter]
budget_ref: budget_applied_ml_q2
The application sends a standard OpenAI-compatible request. The gateway picks the provider based on the rule, falls down the cascade on failure, attaches the budget reference for cost attribution, and applies guardrails inline. No application code changes when the route is reconfigured. If the vendor's “intelligent routing” requires application-level changes for every variant, that's not gateway-level routing. It's a wrapper.
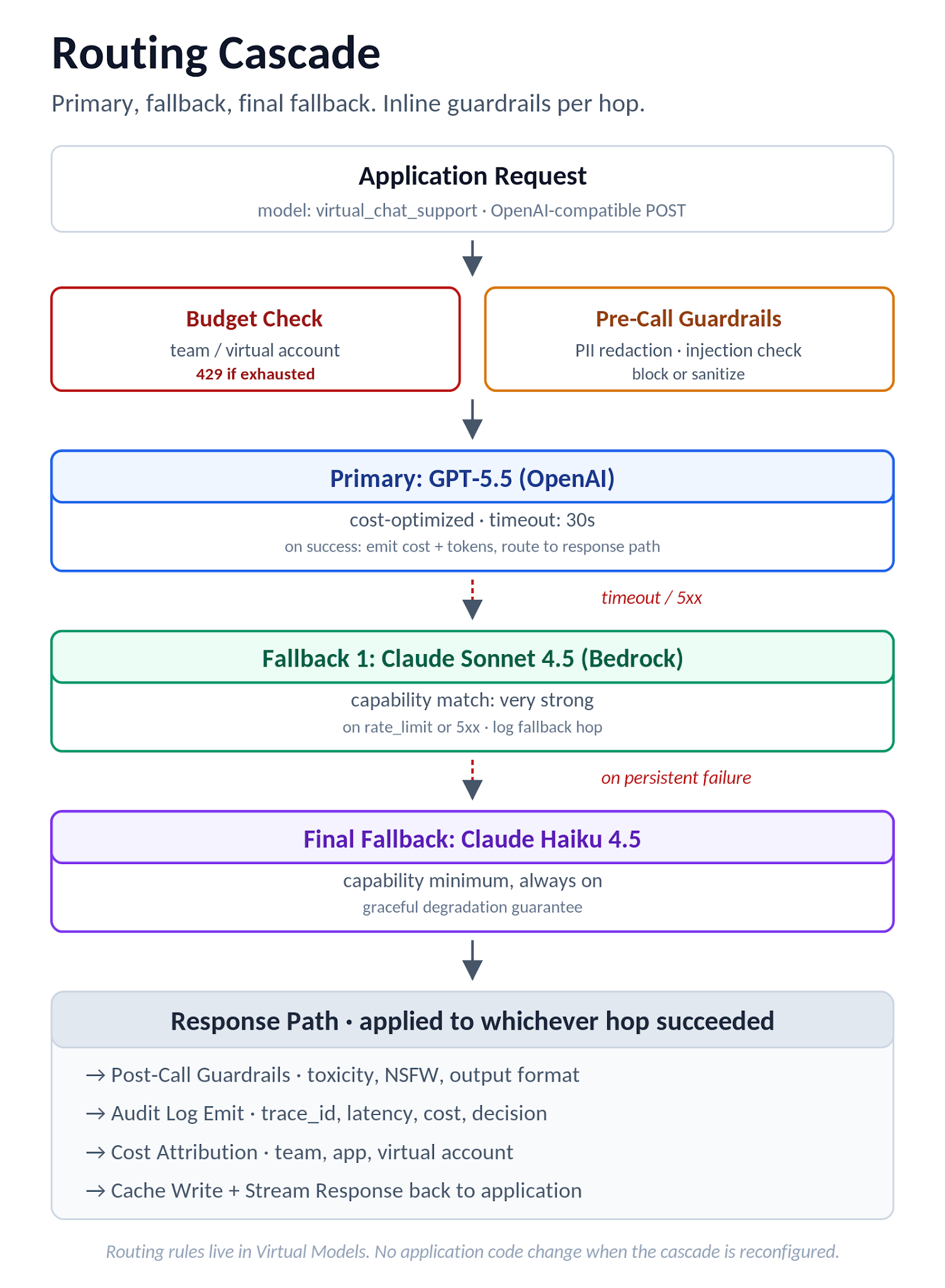
Figure 4. Routing cascade flow: budget check, pre-call guardrails, primary model attempt, fallback chain, and a unified response path with audit, cost, and cache.
This section is where most AI gateway products will struggle, because most of them were designed for the LLM-call era and predate the moment MCP started showing up in real enterprise environments. MCP isn't “more observability for tool calls.” It's a separate governance plane: a registry of approved servers, an enforcement point for which tools each role can invoke, audit logs that match the LLM call logs in field coverage, and a policy engine that runs at invocation time rather than as a post-hoc report. Vendors who don't have this plane will try to answer Section 4 questions with descriptions of LLM observability. Watch for the substitution. The more direct the answer, the more real the capability.
The pattern to expect: a strong AI gateway vendor will describe the MCP gateway as a separate product surface with its own registry, its own RBAC mapping, its own audit log schema, and its own policy language. A weaker vendor will describe it as “extended observability” over their existing LLM observability stack, which is the giveaway that the governance is sparse. Score Section 4 specifically; do not roll it into Section 3.
Read each answer for direct enforcement language.
policy: github-write-restriction
applies_to:
mcp_server: github-prod
tool_pattern: "github.*"
rules:
- match:
tool: github.delete_repo
action: deny
reason: "Destructive operations require change-management ticket"
- match:
tool: github.create_pr
user.team: ["junior-engineers"]
parameters.target_branch: "main"
action: deny
reason: "Direct-to-main PRs require senior-engineer approval"
- match: {tool: "github.*"}
action: allow
log_level: full
Updates to this rule should propagate to the gateway in seconds (configuration push, not redeploy). If the vendor's answer is “policies are evaluated by the MCP server itself,” that's not a gateway-enforced policy. It's a server-enforced one, and you'll need to maintain policy parity across every MCP server in the catalog. Different problem.
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01
└─ trace-id (32 hex) └─ span-id (16 hex)
The gateway preserves the trace-id across every downstream call (LLM provider, MCP server, secondary gateway hop) by injecting it into outbound headers, and emits each call as a span under the same trace-id. In Datadog, Grafana Tempo, or Jaeger, the result is a single waterfall showing: user request → LLM call (claude-sonnet-4-6, 2.1s) → tool call (github.create_issue, 528ms) → LLM call (output formatter, 380ms) → response. Without this, the same flow shows up as four unrelated entries and root-cause analysis becomes guesswork.

Figure 5. MCP Gateway architecture: one endpoint for developer tools and agents, with auth, registry, policy, and logging layers between clients and MCP servers.
The difference between an AI platform that monitors well and one that observes well shows up in the questions your finance team asks at month-end. Monitoring tells you the bill is up 40 percent. Observability tells you the marketing team's chatbot started looping on a context-window edge case three weeks ago, that 70 percent of the increase is from a single application, and that the runaway requests have a specific signature you can route to a cheaper model. The first answer makes finance angry. The second answer makes finance an ally.
The same distinction shows up in agent debugging. Monitoring tells you that an agent task failed. Observability tells you which LLM call returned a malformed response, which downstream tool invocation timed out as a result, and which user request the failure rolled up to. Without correlated tracing across the LLM and MCP planes (Section 4 question 8), every agent failure is a forensic exercise. The questions below force the vendor to describe what's actually captured per call, how it's queryable, and how the data exits the platform when your finance system needs it.
Specifics matter here.
agent_task: trace_id 4bf92f35...
user: ana@company.com (team: applied-ml)
initiating_request: app_chat_support, 2026-04-28 14:22:31
duration: 4.8s
components:
- llm: claude-sonnet-4-6 | tokens 1842 in / 619 out | $0.0144
- tool: github.create_issue | latency 528ms | n/a
- llm: claude-haiku-4-5 | tokens 412 in / 87 out | $0.0011
total_cost_usd: $0.0155
total_tokens: 2960
This is what makes “agent cost attribution” a finance-grade signal rather than a technical curiosity.

Figure 6. Trace waterfall view of a single agent task: LLM call, MCP tool call, and second LLM call, all under one trace_id with cost rolled up across spans.
The cost of an integration gap is rarely visible at procurement. It surfaces six months in, when a terminated employee's access takes 48 hours to revoke because SCIM isn't real, when a P1 outage at 2am gets a “we'll respond during business hours” auto-reply because the SLA is aspirational, when an Okta group rename breaks role assignments because the platform's SSO integration was never tested with group lifecycle events. Each of those is a finite engineering cost, but they accumulate into the operational tax that makes platform teams quietly migrate off otherwise capable products at year-three renewal.
Section 6 surfaces the operational realities. Two diagnostic patterns: any “yes” answer to a protocol-support question deserves a follow-up about which customers run that protocol in production today versus which customers will be the first to try it. And any SLA commitment without explicit credits attached should be treated as a marketing target. Contractual SLAs come with credits because vendors price the risk of missing them; aspirational SLAs are written by marketing and don't.
Get the credits in writing.
If the platform can only consume one fixed claim format, integration with anything but Okta/Azure AD becomes painful. The flexibility above is a one-time configuration cost; without it, every IdP onboarding becomes a custom engagement.
POST /scim/v2/Users
Authorization: Bearer <scim-token>
Content-Type: application/scim+json
{
"schemas": ["urn:ietf:params:scim:schemas:core:2.0:User"],
"userName": "ana@company.com",
"name": {"givenName": "Ana", "familyName": "Ruiz"},
"emails": [{"value": "ana@company.com", "primary": true}],
"groups": [{"value": "applied-ml"}, {"value": "ai-platform-developer"}],
"active": true
}When the user is deprovisioned in the IdP, the same endpoint receives a PATCH that flips active to false, and the platform should revoke the user's access promptly rather than at next login attempt. Test this in the proof-of-concept: deprovision a test user in the IdP, then attempt to use a still-valid platform token, and confirm the deprovisioning lifecycle works end-to-end. If the platform only honors deprovisioning at next user login, that's a compliance gap worth surfacing in writing.
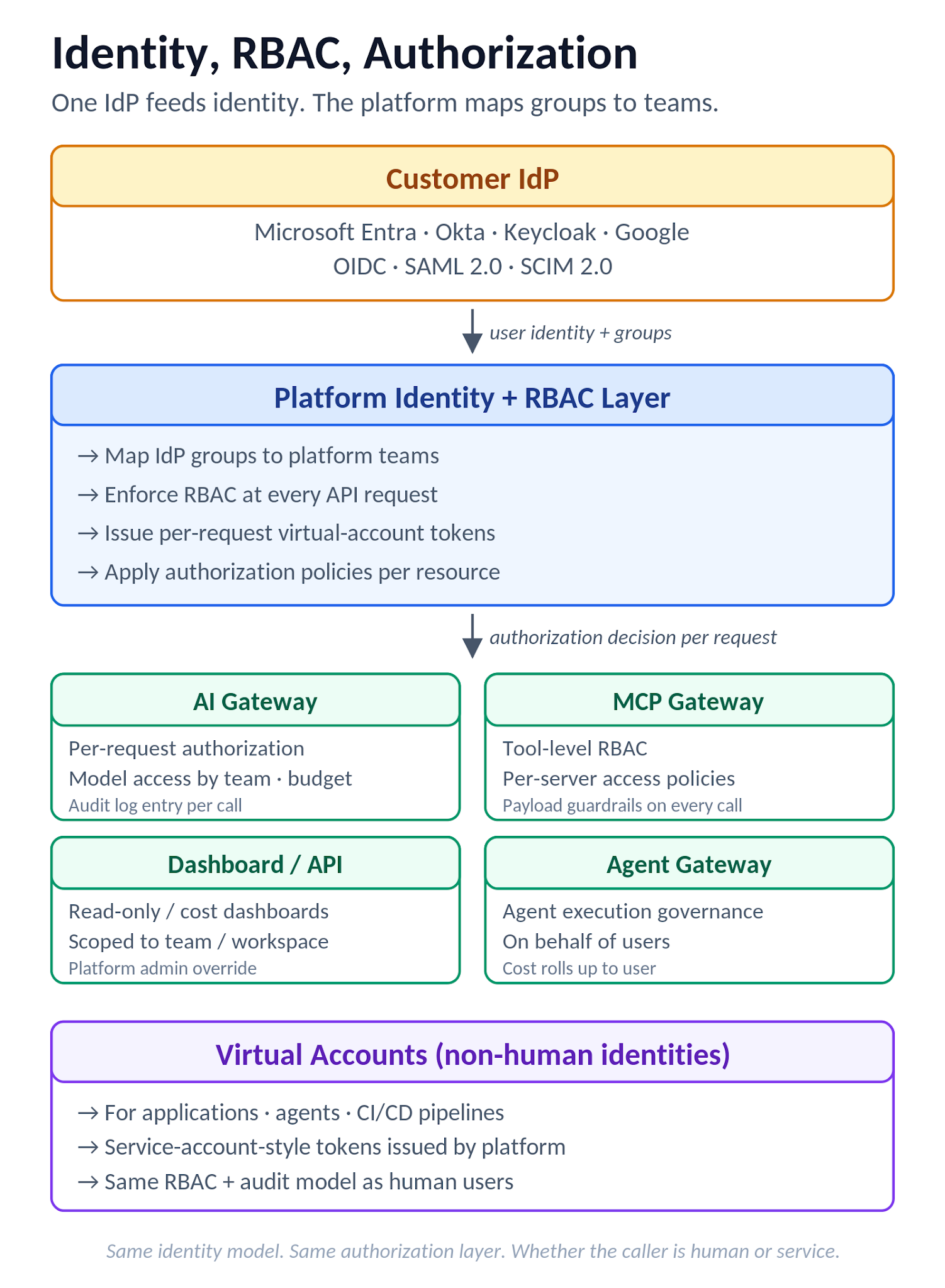
Figure 7. Identity and RBAC flow: IdP feeds identity, the platform maps groups to teams and Virtual Accounts, with enforcement at AI Gateway, MCP Gateway, dashboard, and Agent Gateway.
Watch for “response time” defined as “an automated email saying we received your ticket.” That's not response. Real response is an engineer engaging on the issue. And the credit clause is the test: contractual SLAs come with credits, marketing SLAs don't.
TrueFoundry's solutions team treats this RFP as the formal evaluation, not a sales artifact. Every question gets a written response with evidence: SOC 2 Type II reports, BAA documentation for healthcare deployments, penetration test summaries, reference architectures, sample audit logs, customer references. The output is a document your security, procurement, and platform teams use to make a decision without needing a discovery call to fill in the gaps.
The architecture under the answers maps directly to the section structure of this template, which is why most of the questions resolve cleanly. Walking through it:
The deployment model is split-plane. The control plane is the orchestration brain, hosting configuration, RBAC, and dashboards. Compute planes connect back through an agent and host the actual workloads, including the AI Gateway, MCP Gateway, and any deployed applications or self-hosted models. Compute planes can run in customer cloud accounts (AWS, GCP, Azure) or on-prem Kubernetes, and multiple compute planes attach to one control plane to enable multi-environment operations under a single control surface. AI Gateway can be self-hosted inside customer infrastructure (the deployment options are documented separately) for data residency and sovereignty controls. Audit logs and tracing data are stored using Gateway request logging and tracing projects, with RBAC governing access to traces and logs. The split-plane architecture is what makes the same data residency posture available across SaaS, single-cloud, multi-cloud, and self-hosted deployments rather than treating each as a separate product with separate control postures.
Data sovereignty is the architecture, not a marketing line.
Authentication uses enterprise SSO over OIDC or SAML 2.0 with optional IdP-token validation directly at the AI Gateway for API access control. Common IdPs (Microsoft Entra ID, Okta, Keycloak, Google) are supported, with identity claims and group memberships mapped from the IdP into TrueFoundry teams to drive RBAC at scale. SCIM provisioning is supported on all SSO configurations — both OIDC and SAML — so deprovisioning in the IdP propagates rather than waiting for next user login. RBAC operates at the Tenant level (Admin/Member roles) plus custom roles with scoped permissions across users, teams, clusters, workspaces, deployments, AI Gateway provider accounts, MCP servers, and tracing projects. Non-human identities (applications, agents) get Virtual Accounts with service-account-style tokens, and per-request authorization at AI Gateway boundaries (models, agents, MCP servers and tools) supports least-privilege patterns. Provider keys integrate with customer-managed secret stores; gateway authentication is layered on top of the IdP rather than replacing it, so MFA and conditional access stay enforced by the customer's IdP.
The AI gateway routes across 1,000+ LLMs through a single OpenAI-compatible endpoint: OpenAI, Anthropic (direct and via AWS Bedrock), Azure OpenAI, GCP Vertex AI, Groq, Mistral, and self-hosted models served through vLLM, TGI, or Triton. Routing is configured through Virtual Models, which expose one model interface and load-balance or fail over across multiple underlying providers and models. TrueFailover layers outage- and degradation-aware routing on top, with multi-region and multi-cloud resilience built in. Hard token and request limits per user, team, or Virtual Account return a structured rejection when a team hits its budget rather than a soft alert with the request still going through. Provider fallback is automatic and the latency penalty is captured as a separate metric on the call rather than buried in total latency. Semantic caching uses embeddings and cosine similarity with configurable threshold and TTL; the docs cite up to ~20x latency improvement for repeated or similar queries. Guardrails are rule-based (target by model, user, or metadata), each can Validate (block) or Mutate (rewrite/redact), and Bring-Your-Own Guardrail is supported through a custom guardrail server using a FastAPI template.
Routing here is the product, not a config flag.
The MCP and agentic stack is the differentiator. TrueFoundry runs a native MCP Gateway and MCP Registry that centrally register, discover, and securely connect MCP servers and tools through governed access controls and enterprise auth flows. Modern MCP transports including streamable HTTP for proxy connections are supported, and the protocol layer uses standard JSON-RPC messaging per the MCP specification. Authentication is layered: gateway authentication, access control to MCP servers, and per-server or per-tool auth (including OAuth-based patterns documented for enterprise MCP servers). Centralized configuration means developer tools talk to one gateway endpoint instead of each developer wiring up their own MCP connections, which is the shadow-tooling pattern the registry is designed to prevent. Agent Hub provides organizational cataloging and orchestration for complex agents and pre-existing agents, and Agent Gateway provides the enterprise governance layer (secure tool access, observability, cost controls) for running those agents in production. The same identity that governs LLM access governs tool access, so authorization for both lives in one IdP configuration. And the same trace context that ties together a multi-step LLM agent task ties together the MCP invocations under it, which is what makes per-task cost rollup and end-to-end debugging tractable instead of theoretical.
Observability uses Gateway request logging with traces. Token counts, costs, latency (TTFT and total), guardrail decisions, policy decisions, and team and application attribution are captured per call, stored as traces, and accessible through tracing projects with their own RBAC. Telemetry export is standards-based: OpenTelemetry data export plus log and trace export to external systems including Grafana, Datadog, and Prometheus, so customers integrate with existing observability stacks rather than learning a proprietary one. Cost dashboards are real-time and shareable to team leads through read-only RBAC. The same logging/trace store is what creates the auditable dataset of prompt injection attempts, policy hits, and abuse patterns that customers can mine for guardrail tuning over time.
Your existing observability stack stays your existing observability stack.
The throughput evidence behind all of this: 10 billion requests per month processed across the customer base, 1,000+ Kubernetes clusters managed by the platform, gateway-side overhead under 10ms p95 (TTFT) and 350+ RPS sustained on a single vCPU. Customers running in production include Resmed, Siemens Healthineers, Automation Anywhere, Zscaler, and Nvidia. The Series A was led by Intel Capital in February 2025, bringing total funding to approximately $21 million with Peak XV Partners (Surge), Eniac Ventures, and Jump Capital participating.
Production scale, not pilot scale.
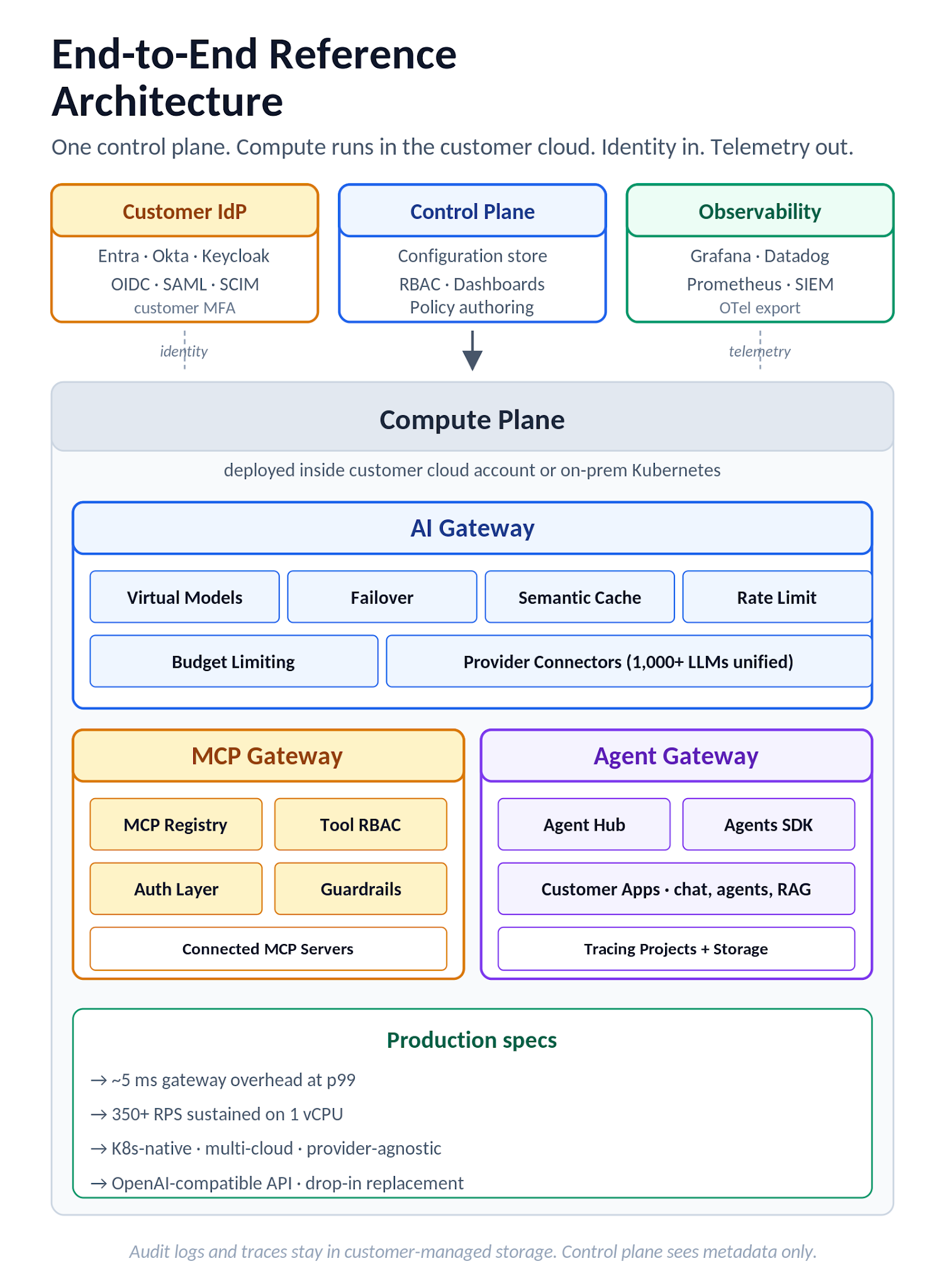
Figure 8. TrueFoundry end-to-end reference architecture: control plane, compute plane (with AI Gateway, MCP Gateway, Agent Gateway and Customer Apps), customer IdP, and observability targets.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.




.webp)







.webp)
.webp)
.webp)
.webp)
.webp)

.webp)
