Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
As organizations roll out more LLM-powered applications across teams, a new layer of infrastructure is emerging as essential: the AI gateway. An AI gateway sits between your applications and the underlying AI services or models, acting as a central control plane for AI traffic. It provides unified access to dozens or hundreds of models while enforcing enterprise policies on security, cost, and observability. This is increasingly important as usage scales: by 2026, over 80% of enterprises are expected to use generative AI, and Gartner predicts that by 2028, 70% of engineering teams building multimodel apps will rely on AI gateways to improve reliability and control costs. Without a gateway, each AI client call must be managed individually – leading to unmanaged token spending, fragmented logging, and security gaps. In this environment, a well-designed AI gateway becomes the new control layer for enterprise AI, providing consistency, governance, and efficiency that traditional API gateways lack.
What Is an AI Gateway and Why It Matters
An AI gateway is a specialized middleware layer that manages traffic between applications and AI models. Unlike conventional API gateways, it is built specifically for AI workloads. It handles AI-specific concerns such as token-level rate limiting, streaming responses, and prompt security checks, which normal HTTP gateways don’t address. In practice, an application submits every AI request to the gateway first: the gateway then authenticates the request, applies any content filters or guardrails, routes it to the appropriate model, and finally returns the response (possibly with its own post-processing) back to the app. This centralized layer enables features like model orchestration (balancing or failing over between different AI providers) and unified billing.
Gartner has identified four foundational tasks that an AI gateway must perform in modern enterprises: routing, security/guardrails, cost control, and observability.
Routing: It directs requests to the most suitable model or provider based on policies (for example choosing between faster but expensive models or cheaper ones).
Security: It enforces authentication, key management, and content filtering from a single control point. This includes preventing issues like prompt injection or sensitive data leakage by applying centralized guardrails on inputs and outputs.
Cost Control: It tracks token usage per request and enforces budgets or quotas to prevent cost overruns. For instance, it can cache duplicate requests to save tokens and re-route requests if a model exceeds budget.
Observability: It logs every AI call and exposes metrics/traces so teams can monitor performance, usage trends, and detect anomalies across all models and applications.
By integrating these functions, an AI gateway turns AI traffic into a programmable policy plane – much as Kubernetes did for containers. This solves key problems when moving from AI experiments to production: without a gateway, it’s easy to lose visibility into token spend, to apply inconsistent security controls, and to have fragmented performance data. A gateway ensures that every AI request is governed and measurable. As one analyst guide notes, “without this layer, organizations struggle to control costs, maintain security, and monitor performance at scale”. In short, an AI gateway makes AI usage enterprise-ready by adding the controls and telemetry that large teams require.
When Does an Organization Need an AI Gateway?
Not every small AI project needs a full gateway, but as soon as multiple teams, models, or usage patterns emerge, a gateway becomes valuable. You likely need an AI gateway when:
You use multiple AI providers or models. When your applications call more than one LLM API (for example, combining OpenAI, Azure, or custom models), a gateway lets you access them through a single, consistent interface. This prevents each team from reinventing access logic and ensures uniform security policies.
Usage is scaling or cross-team. If dozens of developers across departments are integrating LLMs, you risk “shadow AI” — uncontrolled usage on various accounts. An AI gateway unifies that traffic, giving visibility into who is calling which model. Gartner predicts that usage of gateways will jump significantly as multimodel applications spread.
Costs and budgets matter. Every AI request consumes tokens that cost money. A single prompt can use thousands of tokens. As usage climbs, it becomes easy to blow the budget with no one noticing. An AI gateway tracks token usage per request and can enforce per-team or per-project budgets, preventing runaway costs. If your finance or platform team complains about unpredictable AI spend, it’s time for a gateway.
Security and compliance are required. For regulated industries (finance, healthcare, etc.), you need central auditing of AI interactions, strict access controls, and content safety checks. An AI gateway provides exactly that: for example, it can block PII in outputs or enforce sanitization of inputs. If you need HIPAA/SOC2 compliance or must integrate with SIEM systems, a gateway with enterprise-grade security is essential.
You have multi-tenant or agentic workloads. If multiple business units or clients use the same AI infrastructure, you need workload isolation. True multi-tenant support (separate workspaces, RBAC, API keys) comes with a gateway. Similarly, if you deploy AI agents (which use protocols like MCP/Model Context Protocol), a gateway designed for agents can manage those tool/model calls centrally.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Key Features to Look for in an AI Gateway
When comparing AI gateway solutions, focus on features that ensure scalability, security, observability, and cost-effectiveness. Important capabilities include:
Unified Multi-Model API: The gateway should present a single, OpenAI-compatible endpoint for calling models, even if they come from different vendors. This means it can translate your requests to providers like OpenAI, Azure OpenAI, Amazon Bedrock, Gemini, Groq, or even self-hosted models using a standard v1/chat/completions interface. Broad model coverage is critical: verify support for leading models out-of-the-box and an easy way to onboard new or custom models. Ideally, you should be able to switch models via headers or config changes without touching your application code. This unified interface simplifies development and lets you experiment with different models seamlessly.
High Performance & Scalability: Since the gateway proxies every production AI call, it must be fast and scalable. Look for minimal latency overhead (optimally just a few milliseconds added per request). The gateway should support high RPS (requests per second) even on modest resources; for example, a well-designed gateway can handle hundreds of RPS per CPU core. Autoscaling and multi-region deployment are also key – the gateway should be able to spin up additional pods or instances on demand and operate across zones/regions to reduce latency for global teams. Architecturally, many gateways implement in-memory rate-limit and load-balance checks (no external calls in the request path) to achieve sub-50ms latencies. Confirm the vendor’s benchmark claims (e.g. X RPS per pod) and test under your expected load.
Routing, Load Balancing & Reliability: The gateway must intelligently distribute traffic. Key features include weighted or latency-based load balancing across model replicas/providers, automatic retries and model fallbacks on failure, and semantically aware caching of prompts. Strong LLM load balancing capabilities ensure traffic is intelligently distributed across providers to maintain performance, reduce latency spikes, and improve production reliability. You should be able to define rate limits per user or team to prevent abuse, and have quotas or budgets (token or dollar-based) per project. Support for advanced routing policies (for example, sending high-priority traffic to premium models or routing based on request timeouts) is a plus. Overall, ensure the gateway can serve as a resilient proxy so that a downstream API outage or spike doesn’t crash your application.
Robust Observability: Every request through the gateway should generate detailed logs and metrics. Essential observability features include request tracing with rich metadata (prompt text, model used, input/output tokens, user identity, latency, etc.) and real-time or historical dashboards showing usage and performance trends. The gateway should expose integration hooks for your monitoring stack – for example, OpenTelemetry compatibility and easy export of logs/metrics to Grafana, Prometheus, Datadog, etc.. Key questions: Can you filter logs/metrics by user, team, or model? Can you drill down into errors (4xx/5xx) or fallback events? True enterprise solutions let you slice cost and usage data any way you need (per model, per department, etc.) so you can allocate budgets accurately. The evaluation checklist suggests verifying that cost metrics and performance metrics (like time-to-first-token) are available at granular levels.
Security, Guardrails, and Access Governance: Security must be baked in. Look for built-in support for prompt and content filtering (keyword lists, regex rules, context-aware policies) to prevent unsafe or unwanted outputs. The gateway should be able to integrate with external content filters or TRiSM tools (e.g. AWS Content Moderation, AI guardrail providers). All API requests should be logged with full audit trails, and you should be able to assign fine-grained permissions: for example, limiting which teams or users can call which models. Role-Based Access Control (RBAC) is a must – ensure the gateway supports integration with your SSO/IdP (SAML, OIDC, etc.) and that roles and policies can be synced from it. Check for encryption of data at rest/in transit and compliance certifications (like SOC2, GDPR, HIPAA if you need them) on the vendor’s SaaS or on-prem solution.
Cost Management: In addition to raw token tracking, advanced cost controls are critical. The gateway should maintain pricing tables (or allow custom pricing) for major providers so that it can compute the dollar cost of each request. It should enforce spending policies – for instance, sending alerts or blocking requests when a team hits 80% of its budget. Some gateways let you pre-set custom rates for enterprise plans or self-hosted models, and apply those to calculate costs. Semantic caching of responses (e.g. via embeddings) can also drastically reduce usage, so this is a nice-to-have for cost savings. Ultimately, look for the ability to generate cost reports by user or project and to see token spend in real time.
Developer Experience & Integrations: A good gateway feels seamless to developers. It should be compatible with common AI frameworks and agents – for example, supporting LangChain, LlamaIndex, or popular no-code tools (n8n, Flowise) via its API. Check if it offers a unified prompt playground or versioning tool to manage prompts centrally. Multi-modal support (handling text, images, audio, and embeddings) through the same interface is valuable if your use cases involve more than just chat. Finally, the gateway should provide a clear REST API or SDKs for management: e.g. creating API keys, configuring models, setting budgets, etc. The TrueFoundry gateway, for example, offers a prompt playground, API key management, and works out-of-the-box with all major LLM frameworks.
Deployment Flexibility: Depending on your security posture, you may need the gateway as a SaaS or self-hosted solution. Verify whether the gateway can run in your cloud or on-premises (TrueFoundry supports both) and what infrastructure it requires (Kubernetes, etc.). Consider how configuration is managed – look for Terraform/Helm support and GitOps integration if you use those practices. Also check for edge or regional deployment capabilities to minimize latency for global teams. For example, TrueFoundry’s SaaS is globally distributed and its on-prem gateway can be placed in any cloud region, keeping response times below ~5ms in practice.
In summary, your evaluation should cover routing/orchestration, performance, observability, security, cost control, and deployment. As a practical step, use a structured checklist to score each gateway against these dimensions.
TrueFoundry’s Approach to AI Gateway Design
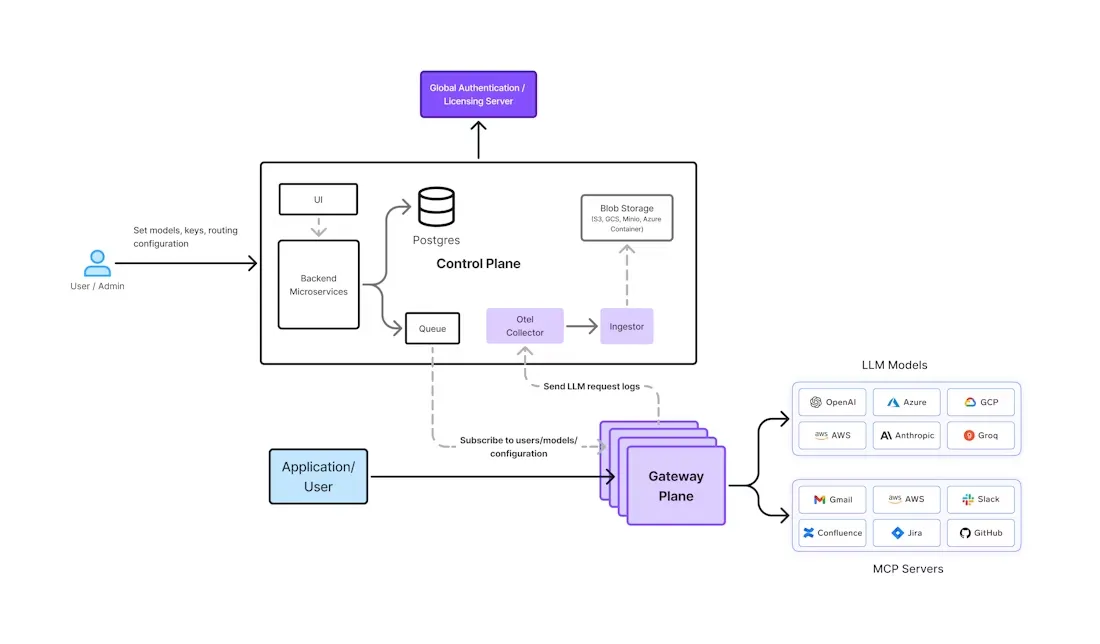
TrueFoundry’s own AI Gateway was built from the ground up with these enterprise requirements in mind. It provides a unified interface to 1000+ LLMs (OpenAI, Anthropic, Gemini, Bedrock, open-source models and more) while embedding security, observability, and governance at its core. The architecture separates control-plane functions (UI, policy database, etc.) from stateless gateway pods that handle inference traffic (see figure below).
Figure 1: Architecture of TrueFoundry’s AI Gateway. A central control plane (left) pushes configuration to globally distributed gateway pods (right). All policy checks (auth, rate limits, routing) occur in-memory on each pod.
TrueFoundry’s gateway pods subscribe to a NATS message stream from the control plane. Policy changes (like new user permissions, model configurations, or balancing rules) are published into NATS and immediately available to every pod. When a request arrives at a gateway pod, all critical checks occur in-memory with no extra network hops – this includes JWT authentication, RBAC checks, rate-limit enforcement, and model load-balancing decisions. As a result, TrueFoundry’s tests show latency overheads on the order of just a few milliseconds per request. Even under full tracing (logging each prompt and token count), modern hardware handles hundreds of requests per second per pod, and the system scales linearly by adding more pods.
Behind the scenes, approved requests are routed to the chosen AI provider or model endpoint. If a response is successful, it is immediately sent back to the client. Simultaneously, metadata from the request and response (tokens used, latency, user, model) is asynchronously published to the message queue. A backend analytics service ingests these events into ClickHouse (via blob storage) to compute usage and cost metrics. This async pipeline means that logging and analytics never block the live traffic path. Dashboard and API clients can then query the aggregated telemetry (via OpenTelemetry standards) to track usage by model, team, or time period.
Security is enforced throughout. TrueFoundry’s gateway uses fine-grainedRBAC so that teams see and invoke only the models they are permitted to use. All API keys and tokens can be managed centrally, and detailed audit logs capture every action (timestamps, user IDs, model used, etc.). Custom content guardrails can be defined in the portal (for example, keyword filters or context-aware rules), and the gateway will block or flag any responses that violate policy. TrueFoundry also integrates with enterprise identity providers, so you can sync roles from your IdP (SSO via SAML/OIDC) and automatically apply those to gateway permissions.
Other capabilities include multi-modal support (the same API handles text, images, audio, and embeddings seamlessly) and a built-in prompt management system. The gateway offers a Prompt Playgroundfor versioning and testing prompts centrally, which is especially useful for teams iterating on production prompts. It also provides global budget and rate-limit controls: for example, you can set a monthly dollar quota per team or enforce token-based budgets per project. In practice, organizations using TrueFoundry’s gateway gain immediate visibility into token spend (even broken down by provider and model) and can automatically halt or notify users when budgets are exceeded.
Deployment flexibility is a hallmark of TrueFoundry’s design. The AI Gateway can run as a managed SaaS (with nodes in multiple cloud regions for low latency and high availability) or be installed in your own cloud/on-premises environment. In both cases, the performance impact is minimal – a recent FAQ notes that TrueFoundry’s SaaS adds less than ~5ms of overhead per request. Because it can be deployed in any Kubernetes cluster (or even at the edge), you can place gateway pods close to your applications or data sources to further reduce round-trip time. TrueFoundry also supports secure on-prem operation: the only data sent to the cloud licensing server are anonymized usage metrics, and full control-plane deployment can stay behind your firewall if needed.
Choosing the Right Gateway for Your Use Case
No single AI gateway is perfect for every scenario, so align your choice with your priorities:
Cost-sensitive use cases: If tight budget control is critical, prioritize gateways with built-in spending policies. Ensure it can apply custom pricing (e.g. reflecting your enterprise discounts) and trigger alerts at budget thresholds. TrueFoundry, for example, lets you preload public provider rates and define custom rates for your contracts or self-hosted models, with automated notifications as thresholds approach.
High-security/compliance requirements: In regulated industries, look for features like full auditability (tamper-proof logs), granular RBAC, and encryption key management. TrueFoundry’s gateway supports SOC2 and HIPAA workflows out of the box (via on-prem options and secure key storage) and can integrate with SIEM tools. Features like PII detection and data redaction can be decisive if you handle sensitive data.
Extremely high throughput/low latency: For real-time applications (e.g. customer chatbots or trading systems), the gateway’s performance is paramount. Check the vendor’s benchmarks or run a pilot: TrueFoundry’s architecture can serve 250+ RPS per pod with minimal added latency, and easily scale to many thousands with more replicas. If you need ultra-low latency, deploying gateway pods in the same region (or even edge zones) as your users is important – TrueFoundry’s multi-region SaaS or on-prem option allows this.
Multi-cloud or hybrid environments: If you use multiple cloud providers or have strict data residency requirements, choose a gateway that can run across them. TrueFoundry supports deployment on any cloud or on-prem infrastructure, and can synchronize policies globally. This means one control plane can manage gateways deployed in different regions or clouds.
Multi-modal or agentic applications: If your use case involves agents (tools, actions) via the MCP/A2A protocols, or if you need seamless support for images and audio, verify that the gateway has those capabilities. TrueFoundry is actively extending its gateway to virtualize MCP servers and unify AI tools under one API. Already today it offers “virtual MCP servers” where you can combine tools and models from multiple agents into one interface (coming soon in GA). For multi-modal, TrueFoundry supports text, image, audio, and embedding models uniformly.
Developer and ecosystem fit: Consider what your dev teams use. If they rely on LangChain or LLM frameworks, pick a gateway known to work with them out-of-the-box. The ease of onboarding (API docs, client SDKs) matters for adoption. TrueFoundry provides open APIs and client libraries in multiple languages, and its unified API means existing OpenAI-based code often works unchanged. Also check if the gateway integrates with CI/CD or infrastructure tools you use (for example, Terraform support in TrueFoundry).
In all cases, map these requirements against your evaluation checklist. Assign weights to criteria based on what’s most critical for your project (security vs. cost vs. features). TrueFoundry’s evaluation framework can be customized (it’s available as a public CSV) so you can score vendors side by side on the exact features you need. The goal is to pick the gateway that not only meets today’s needs but can grow with your AI initiatives.
Conclusion
As AI adoption grows, a purpose-built gateway is rapidly becoming a must-have control layer. It brings order to what would otherwise be a chaotic mix of APIs, costs, and security risks. By handling routing, observability, budgeting, and compliance in one place, an AI gateway turns AI infrastructure into a reliable, governed platform. TrueFoundry’s AI Gateway is built on these principles – offering a unified interface to hundreds of models with enterprise-grade security, monitoring, and policy controls.
When choosing a gateway, use a structured approach: understand your workloads, consult the evaluation checklist, and compare how each option stacks up on routing flexibility, performance, observability, cost controls, and governance features. By doing so, you can select the solution that will serve as the “AI control plane” for your organization’s LLM and agent-based applications. A robust gateway not only protects budgets and data but also accelerates development by providing a consistent, scalable foundation for all AI services. Ultimately, investing in the right AI gateway paves the way for safely taking your AI use cases from experiment to enterprise-scale reality.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.




























.webp)
.webp)
.webp)
.webp)







.png)
.webp)