














June 29, 2026
|
5 min read

Published: November 24, 2025

Blazingly fast way to build, track and deploy your models!
Short version: Kimi-K2 Thinking (Moonshot AI) is an open-weight, tool-aware “thinking” model that pushes multi-step reasoning, long-horizon tool orchestration, and massive context windows. On Humanity’s Last Exam (HLE) and several agentic benchmarks it posts state-leading numbers (particularly when tool access is enabled), making a strong case that the next big frontier in LLMs is thinking + tools + long context, not just raw parameter counts.
Use Truefoundry AI Gateway to try it right now.
Benchmarks like MMLU, coding tests, and chat benchmarks have told us a lot, but they don’t fully measure multi-step reasoning, tool orchestration, or long-horizon planning. A new class of “thinking” models explicitly trains for those abilities: the model must interleave internal step-by-step reasoning with external tool calls (search, code interpreters, web browsing), and maintain coherence for many sequential steps.
Kimi-K2 Thinking is a flagship example of this trend. It’s designed as an agentic system: it reasons, decides to call tools, ingests tool outputs, and continues reasoning — all while keeping context across hundreds of steps. The result: substantial gains on hard “thinking” benchmarks such as HLE and BrowseComp.
Key technical highlights from the official model card:
These elements — MoE scale, huge context, explicit tool orchestration, and efficient low-bit inference — are the building blocks that let Kimi-K2 act like an agent more than a conversational transformer.
Humanity’s Last Exam (HLE) is intended to be a very challenging exam-style benchmark that stresses genuine reasoning, not retrieval or shortcuts. It contains domain-heavy, often multi-step problems across math, science, engineering, and other subjects. Because HLE’s problems typically require multi-step reasoning and, in some cases, external lookup or computation, it’s an excellent stress test for tool-capable, long-context agents. Kimi-K2’s development emphasized HLE and other agentic benchmarks — the model card highlights HLE as one of its core evaluation targets.
According to Moonshot AI’s published evaluation results:
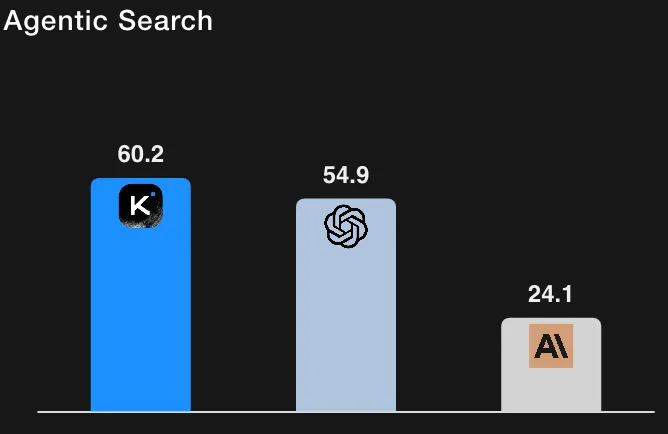
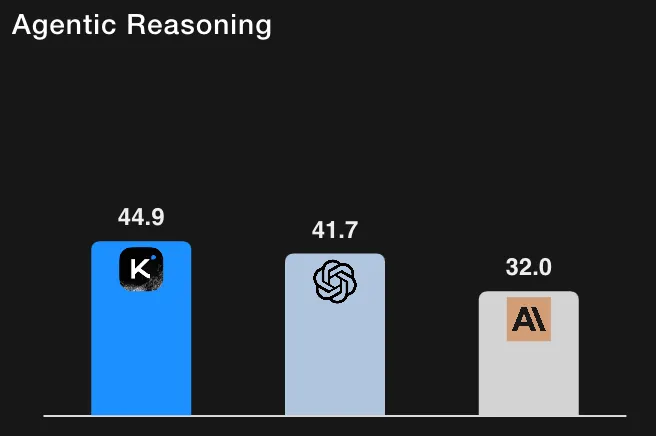
For context, GPT-5 (High) at ~41.7% on HLE with tools (their internal re-runs) and Claude Sonnet 4.5 at ~32.0% (thinking mode). The Kimi-K2 results therefore place it ahead of the reported baselines on tool-enabled HLE runs. (All numbers are taken from Moonshot AI’s evaluation table and footnotes.)
Important nuance: the model card carefully documents how tool access, judge settings, token budgets, and context limits were handled; the authors also note that some baseline numbers were taken from official posts while others were re-tested internally. In short: these are strong signals but readers should note they are reported by Moonshot AI and conditioned on the detailed evaluation protocol described with the results.
We sampled 50 data rows from HLE and here are the results
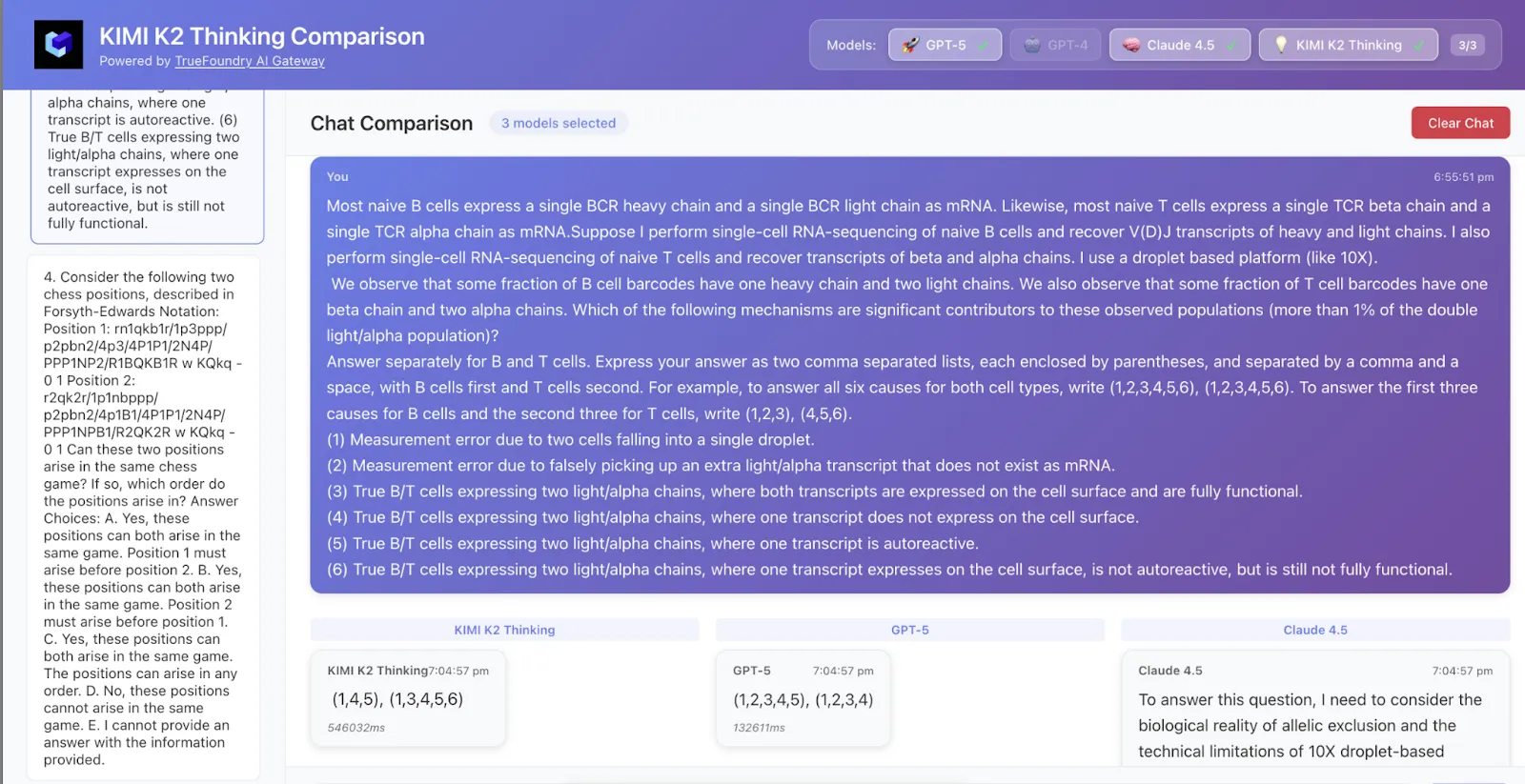
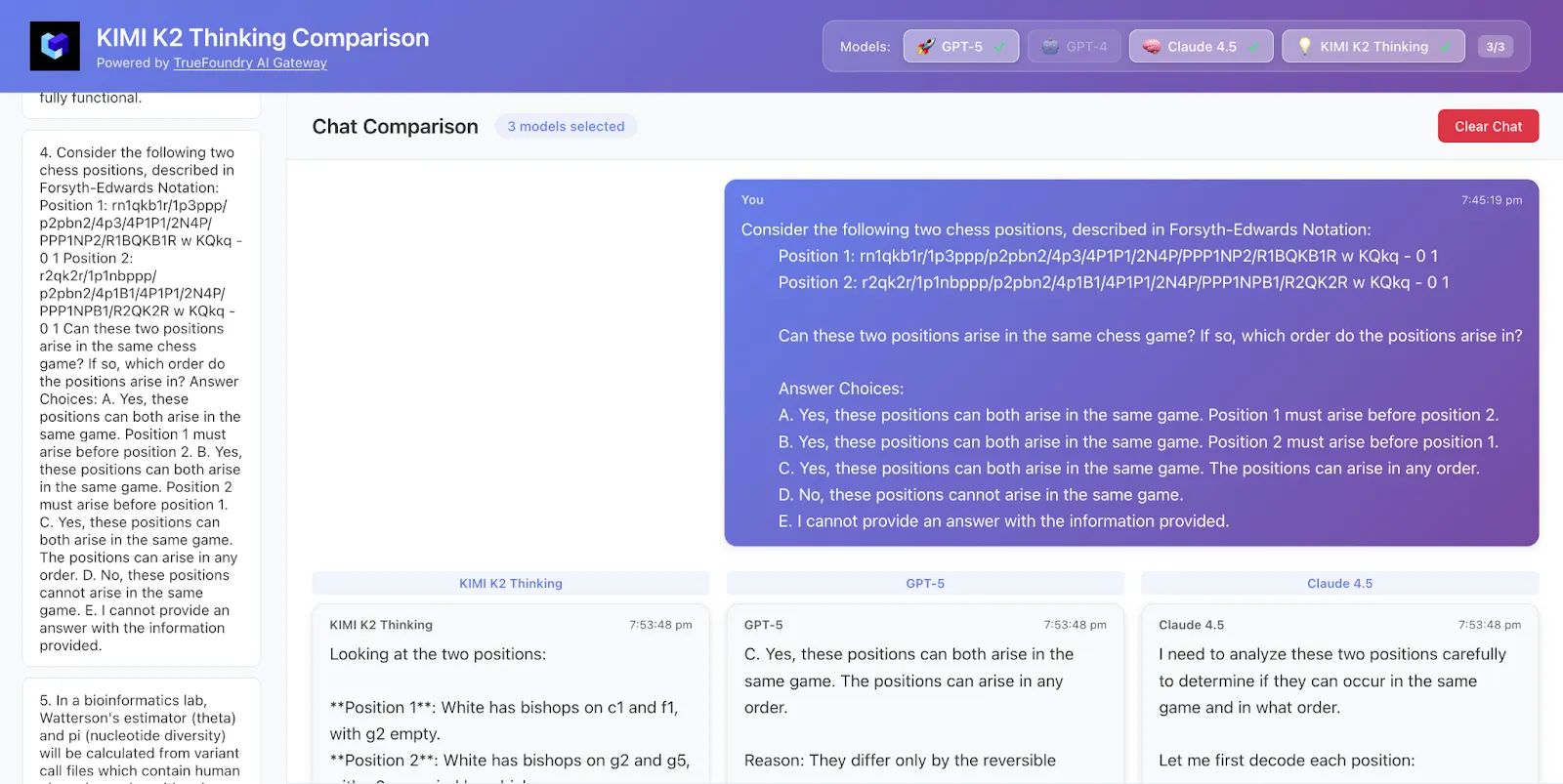
Kimi K2 got both the answer and logic correct while GPT-5 got only the answer correct and Claude was not correct.
Kimi-K2’s roughly doubling of HLE performance from no-tools → with-tools (≈24→45%) demonstrates a crucial point:
Put simply: the HLE gains suggest that the core problem is how a model reasons and uses tools, not just raw model size.
Beyond benchmarks, what’s most exciting is how accessible this kind of capability is becoming. You don’t have to wait months to experiment — you can try it yourself. TrueFoundry AI Gateway makes it easy to access Kimi-K2 Thinking and other cutting-edge models directly, benchmark them on your own data, or integrate them into workflows.
If you want more personalized help, book a demo — the team can walk you through performance, deployment options, cost, and how to evaluate these models on your tasks. We stay current with the market and make sure new models are available for your consumption as fast as possible.
Bottom line: Kimi-K2 Thinking isn’t just another LLM — it’s a visible glimpse at the future of reasoning-capable agents: open, efficient, tool-aware, and tuned for multi-step problem solving. Try it, compare it on your own problems, and see how much difference agentic tool orchestration makes on real tasks.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.



.webp)


.webp)
.webp)
.webp)
.png)






.webp)
.webp)